少用33%數據,模型性能不變,陳丹琦團隊用元數據來做降本增效
機器之心報導
編輯:杜偉
除了提升數據效率之外,本文方法 MeCo 保證了計算開銷與複雜性也幾乎不會增加。
普林斯頓大學計算機科學系助理教授陳丹琦團隊又有了新論文,這次將重點放在了「使用元數據來加速預訓練」上來。
我們知道,語言模型通過在大量網絡語料庫上進行訓練來實現卓越的通用能力。多樣性訓練數據凸顯了一個根本性挑戰:人們自然地根據數據源來調整他們的理解,與之不同,語言模型將所有內容作為等效樣本來處理。
這種以相同方式處理異構源數據的做法會帶來兩個問題:一是忽略了有助於理解的重要上下文信號,二是在專門的下遊任務中阻礙模型可靠地展示適當的行為,比如幽默或事實。
面對以上這些挑戰,並為了提供每個文檔來源的更多信息,陳丹琦團隊在本文中提出通過在每個文檔之前添加廣泛可用的源 URL,從而在預訓練期間使用文檔相應的元數據進行調節。並且為了確保模型在推理過程中無論有無元數據都能高效地運行,在最後 10% 的訓練中實施了冷卻(cooldown)。他們將這種預訓練方法稱為 Metadata Conditioning then Cooldown(MeCo)。
先前的工作中已經有人使用元數據條件來引導模型生成並提高模型對惡意提示的穩健性,但研究者通過關鍵的兩點確認了所提方法的通用實用性。首先,他們證明這一範式可以直接加速語言模型的預訓練並提高下遊任務性能。其次,MeCo 的冷卻階段確保模型在沒有元數據的情況下可以執行推理,這點與以往的方法不同。
本文的主要貢獻包括如下:
一、MeCo 大大加速了預訓練過程。研究者證明,MeCo 使得 1.6B 的模型在少用 33%訓練數據的情況下,實現與標準預訓練模型相同的平均下遊性能。MeCo 在模型規模(600M、1.6B、3B 和 8B)和數據源(C4、RefinedWeb 和 DCLM)表現出了一致的增益。
二、MeCo 開闢了一種引導模型的新方法。在推理過程中,在提示之前添加合適的真實或合成 URL 可以誘導期望的模型行為。舉個例子,使用「factquizmaster.com」(並非真實 URL)可以增強常識知識任務的性能,比如零樣本常識問題絕對性能可以提升 6%。相反,使用「wikipedia.org」(真實 URL)可以將有毒生成的可能性比標準無條件推理降低數倍。
三、MeCo 設計選擇的消融實驗表明,它能與不同類型的元數據兼容。使用散列 URL 和模型生成主題的消融實驗表明,元數據的主要作用是按照來源對文檔進行分組。因此,即使沒有 URL,MeCo 也可以有效地合併不同類型的元數據,包括更細粒度的選項。
研究結果表明,MeCo 可以顯著提高語言模型的數據效率,同時幾乎不會增加預訓練過程的計算開銷和複雜性。此外,MeCo 提供了增強可控性,有望創建更可控的語言模型,並且它與更細粒度和創造性的元數據的普遍兼容性值得進一步探索。
總之,作為一種簡單、靈活、有效的訓練範式,MeCo 可以同時提高語言模型的實用性和可控性。

-
論文標題:Metadata Conditioning Accelerates Language Model Pre-training
-
論文地址:https://arxiv.org/pdf/2501.01956v1
-
代碼地址:https://github.com/princeton-pli/MeCo
論文一作高天宇(Tianyu Gao)還在評論區與讀者展開了互動,並回答了一個問題「MeCo 是否需要平衡過擬合和欠擬合」。他表示,本文的一個假設是 MeCo 進行隱式數據混合優化(DoReMi、ADO)並上采樣欠擬合和更多有用域。
OpenAI 一位研究人員 Lucas Beyer 表示,他很久之前就對視覺語言模型(VLM)做過類似的研究,很有趣,但最終用處不大。
方法概覽
本文方法包括以下兩個訓練階段,如下圖 1 所示。

使用元數據條件進行預訓練(前 90%):模型在串接的元數據和文檔上進行訓練,並遵循以下模板「URL:en.wikipedia.org\n\n[document]」。使用其他類型的元數據時,URL替換為相應的元數據名稱。研究者僅計算文檔token的交叉熵損失,而忽略出自模板或元數據的token。他們在初步實驗中發現:使用這些token訓練會損害下遊任務性能。
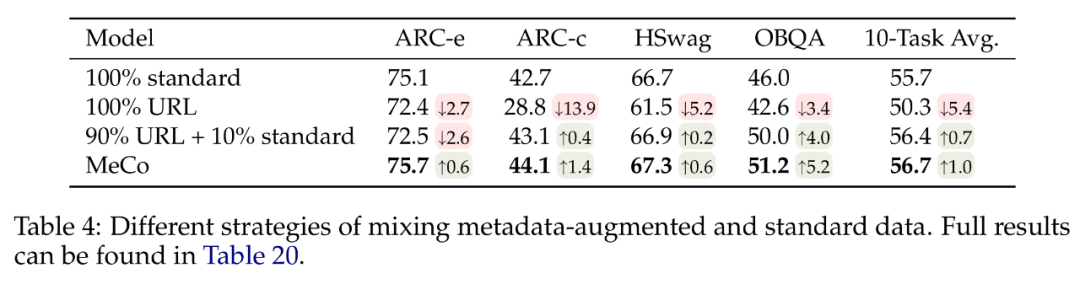
使用標準數據進行冷卻(後 10%):對於僅使用元數據增強的數據進行訓練的模型,在沒有元數據的情況下性能會下降(具體可見下表 4)。為了確保通用性,研究者在冷卻階段,使用了沒有任何元數據的標準預訓練文檔來訓練模型,該階段涵蓋了預訓練過程最後 10% 的步驟。
冷卻階段繼承了來自元數據條件階段的學習率計劃和優化器狀態,即它從上一個階段的最後一個檢查點初始化學習率、模型參數和優化器狀態,並繼續根據計劃來調整學習率。
研究者還在所有實驗中採用了以下兩項技術,並且初步實驗表明它們提高了基線預訓練模型的性能:
-
禁用了跨文檔注意力,此舉既加快了訓練速度(1.6B 模型的速度提升了 25%),又提高了下遊任務的性能;
-
將多個文檔打包成一個序列時,確保每個序列都從一個新文檔開始,而不是從一個文檔的中間開始,這可能會導致在將文檔打包為一個固定長度時丟棄一些數據,但被證明有利於提高下遊任務性能。
實驗結果
研究者在所有實驗中使用了 Llama 系列模型使用的 Transformer 架構和 Llama-3tokenizer,使用了四種規模的模型大小,分別是 600M、1.6B、3B 和 8B。他們對語言模型採用了標準優化設置,即 AdamW 優化器和餘弦學習率計劃。
少用 33% 數據,MeCo 性能與標準預訓練方法相當
下表 1 顯示了研究者在 DCLM 上的 160B token 上,對 1.6B 語言模型進行預訓練的主要結果。他們首先觀察到,在大多數任務中,MeCo 的性能顯著優於標準預訓練方法。MeCo 還超越了數據挑選基線。並且與數據挑選方法不同的是,MeCo 不會產生任何計算開銷,它利用了預訓練數據中隨時可用的 URL 信息。
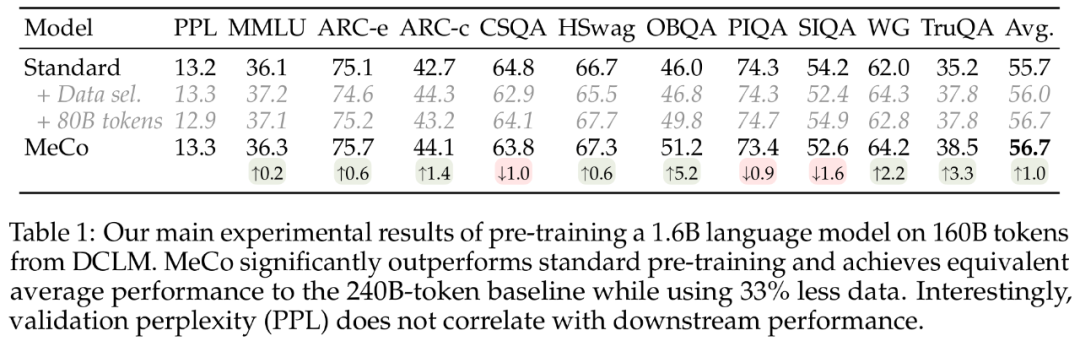
更重要的是,MeCo 實現了與標準預訓練方法相當的性能,同時使用的數據和計算量減少了 33%,代表了數據效率的顯著提高。
下表 1 為困惑度指標,表明了驗證困惑度與下遊性能無關。值得注意的是,當將 240B 基線模型與 160B MeCo 模型比較時,由於數據量較大,基線模型表現出的困惑度要低得多,但這兩個模型實現了類似的平均性能。
研究者在下圖 2 中展示了整個預訓練過程中下遊任務的性能變化。對於 MeCo,圖中的每個檢查點都包含使用 16B token(佔總訓練 token 的 10%)的冷卻階段。例如,80B 檢查點包含了 64B token 的條件訓練和 16B token 的冷卻。他們觀察到,MeCo 始終超越了基線模型,尤其是在訓練後期。
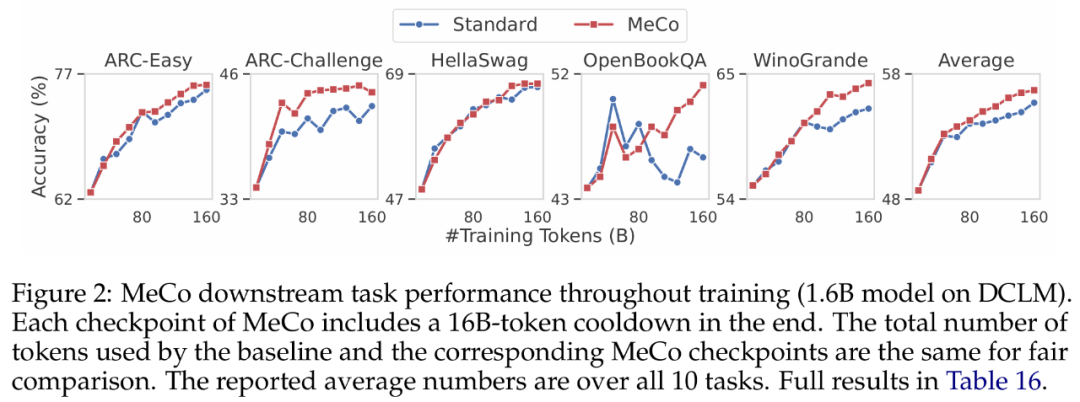
MeCo 在所有模型規模下均提升了性能
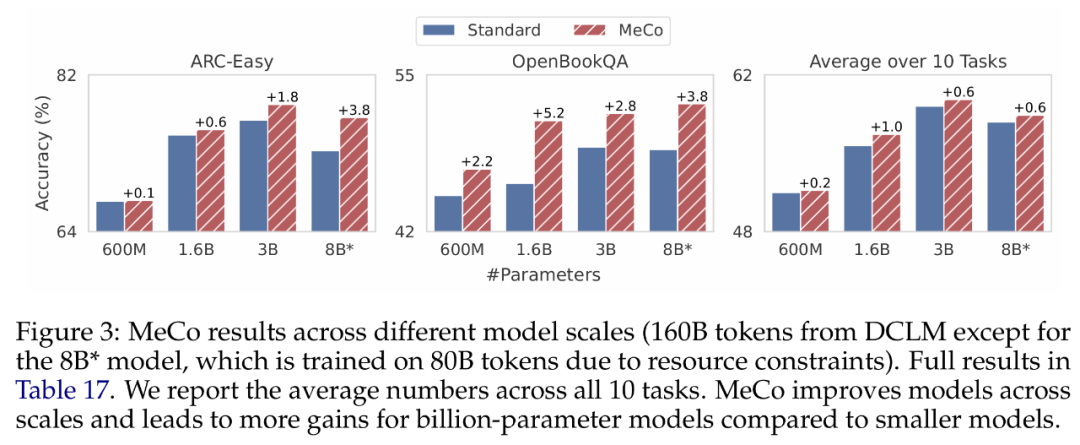
下圖 3 顯示了不同模型規模(600 M、1.6B、3B 和 8B)的結果。研究者使用相同的優化超參數和相同的數據量(DCLM 上的 160B)來訓練所有模型,其中 8B 模型是個個例,它使用 80B token 進行訓練,由於資源限制和訓練不穩定而導致學習率較低。
研究者觀察到,MeCo 在所有規模下均提升了模型性能。並且 MeCo 看起來可以為更大的模型帶來更多的改進,十億級參數的模型與 600M 相比顯示出更顯著的收益。不過需要注意,這是一個定性觀察,與預訓練損失相比,下遊任務性能的擴展不太平穩。
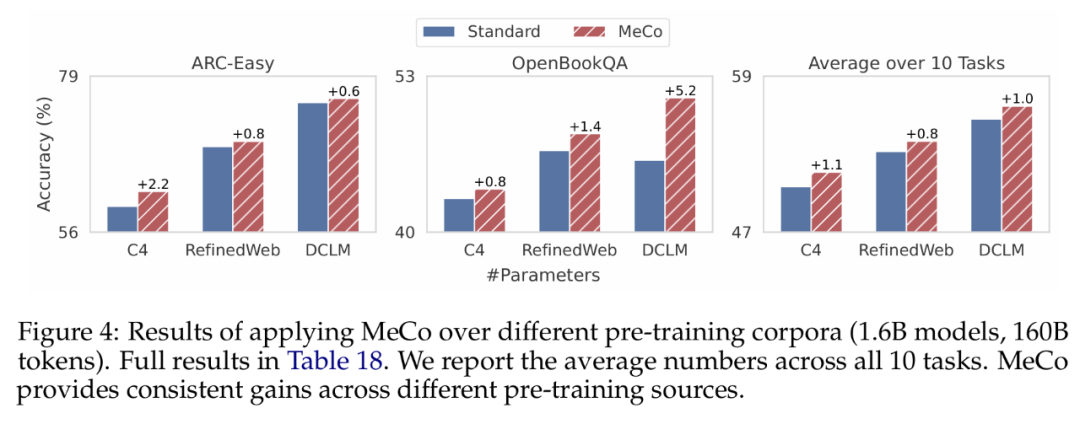
MeCo 提升了不同訓練語料庫的性能
研究者基於三個不同的數據源(C4、RefinedWeb 和 DCLM),在 160B token 上訓練了 1.6B 模型,結果如下圖 4 所示。如果將平均下遊性能作為數據質量指標,三個數據源的排序為 DCLM > RefinedWeb > C4。他們觀察到,MeCo 在不同數據源上實現了一致且顯著的增益,平均準確率和單個任務均是如此。
更多技術細節請參閱原論文。