劍指專業領域零部件級3D生成!Meta聯手牛津推出全新多視圖擴散模型
新智元報導
編輯:alan
【新智元導讀】對於專業應用和創意工作流來說,除了高質量的形狀和紋理,更需要可以獨立操作的「零部件級3D模型」。為此,Meta與牛津大學的研究人員推出了全新的多視圖擴散模型。
當前AI生成的3D模型,已經擁有相當高的質量。
但這些生成結果通常只是單個物體的某種表示(比如隱式神經場、高斯混合或網格),而不包含結構信息。
對於專業應用和創意工作流來說,除了高質量的形狀和紋理,更需要可以獨立操作的「零部件級3D模型」。
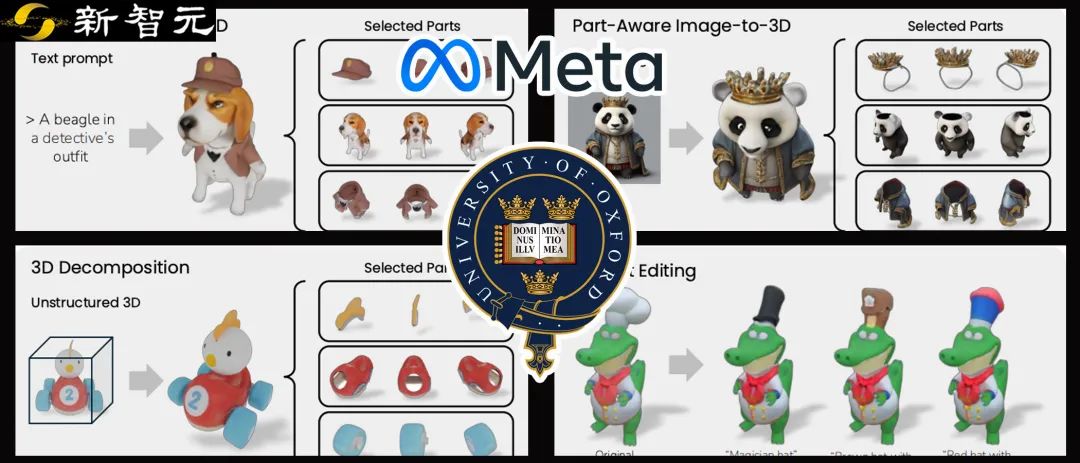
比如上圖中的幾個例子,3D模型應該由多個有意義的部分組成,可以分離、組合與編輯。
而上圖中的效果,正是出自Meta與牛津大學的研究人員推出的全新多視圖擴散模型——PartGen。
 論文地址:https://arxiv.org/pdf/2412.18608
論文地址:https://arxiv.org/pdf/2412.18608項目地址:https://silent-chen.github.io/PartGen
PartGen可以使用文本、圖像或非結構化3D對象作為輸入,生成上面說的「子結構可分離」的3D模型。
同一些SOTA生成工作流類似,PartGen也採用兩階段方案,以消除零部件分割和重建的歧義:
首先,多視圖生成器根據給定條件,生成3D對象的多個視圖,由第一個多視圖擴散模型提取一組合理且視圖一致的部分分割,將對象劃分為多個部分。
然後,第二個多視圖擴散模型將每個部分分開,填充遮擋並饋送到3D重建網絡,對這些補充完整的視圖進行3D重建。
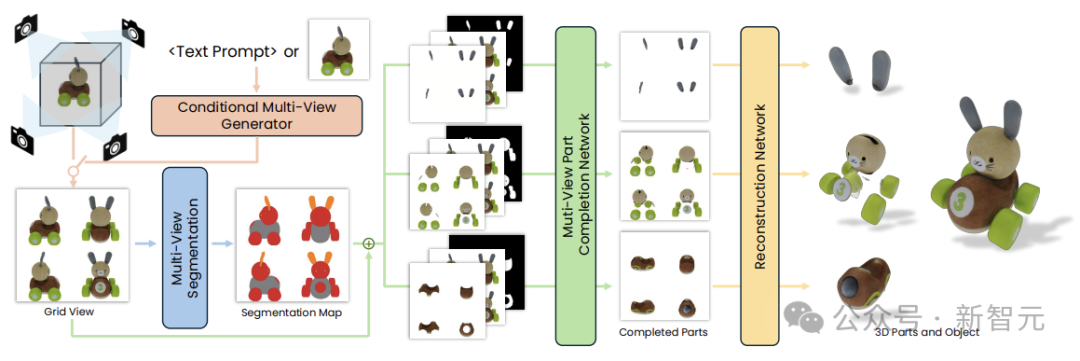
PartGen在生成過程中考慮了整個對象的上下文,以確保各部分緊密集成。這種生成式補全模型可以彌補由於遮擋而丟失的信息,還原出完全不可見的部分。

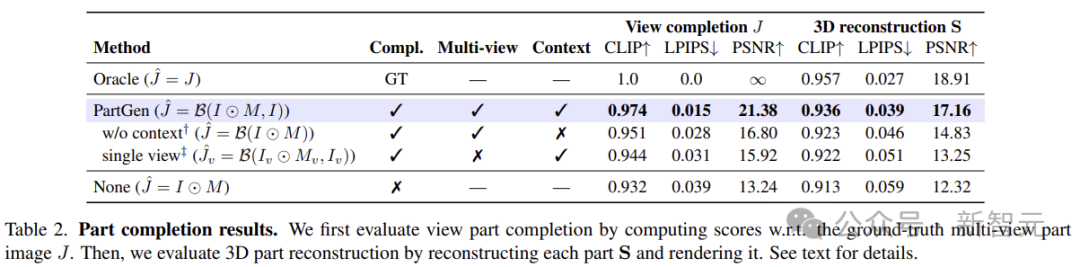
作者在合成以及真實的3D資產上評估了PartGen,如圖所示,其性能大大優於之前的類似方法。
作者還將PartGen部署到真實的下遊應用程序,例如3D零件編輯,以證明模型的實力。
零部件級3D生成
零件很重要,因為零件可以支持重用、編輯或者動畫。
人類藝術家在製作3D模型時,會自然地以這種角度考慮。
比如一個人的模型可以分解成衣服和配飾,以及各種解剖特徵(頭髮、眼睛、牙齒、四肢等)。
零件承載的信息和功能也很重要,比如不同的部分可能具有不同的動畫或不同的材質。
零件還可以單獨替換、刪除或編輯。比如在影片遊戲中,角色更換武器或衣服。
另外,由於其語義意義,零部件對於機器人、具身人工智能和空間智能等3D理解和應用也很重要。
PartGen將現有3D生成方法從非結構化,升級為零部件組合的方法,從而解決了兩個關鍵問題:
1)如何自動將3D對象分割成多個部分;
2)如何提取高質量、完整的3D零部件,即使是在外觀部分遮擋、或者根本看不到的情況下。
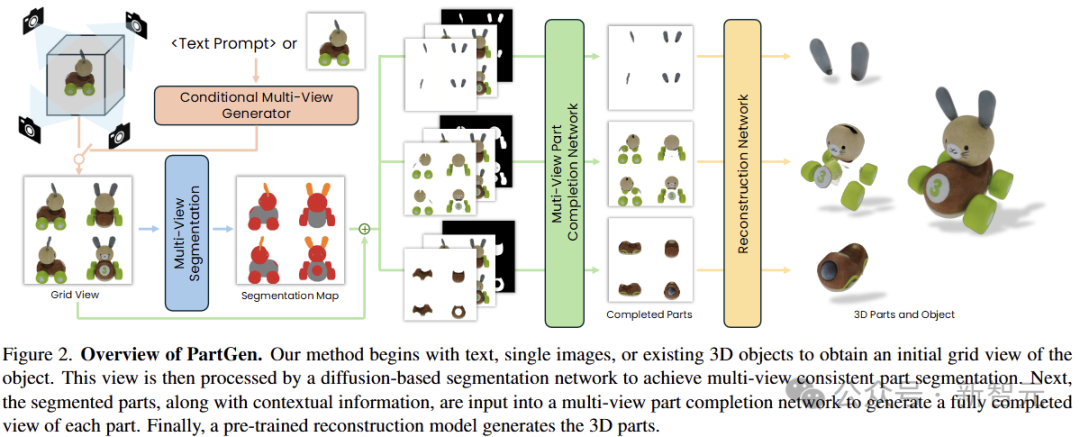
多視圖零部件分割
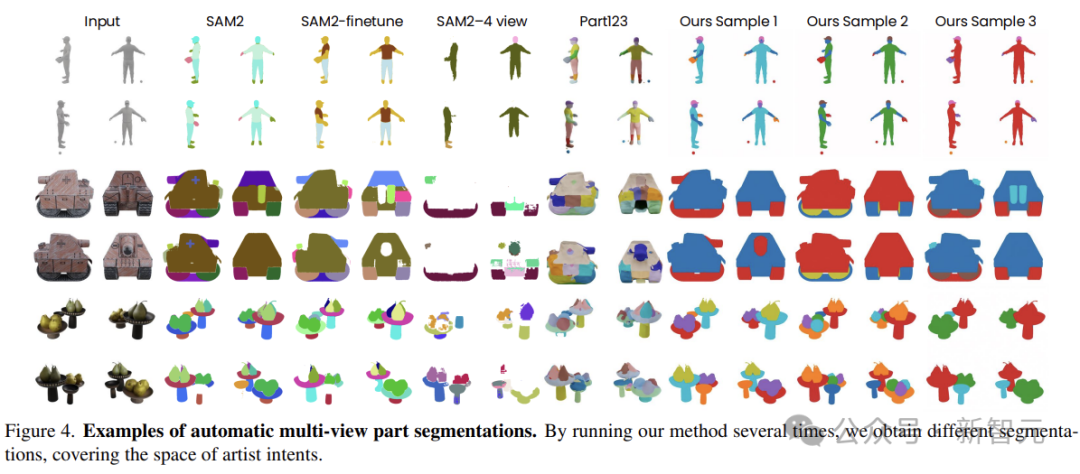
3D對象分割並沒有所謂的「黃金標準」。因此,分割方法應該對合理的部分分割的分佈進行建模,而不是對單個分割進行建模。
可以使用概率擴散模型來學習這項任務,從而有效地捕捉和建模這種模糊性。
作為整個生成流程的第一階段,研究人員將零件分割轉換為隨機多視圖一致性著色問題(stochastic multi-view-consistent colouring problem),利用經過微調的多視圖圖像生成器,在3D對象的多個視圖中生成顏色編碼的分割圖。
作者不假設任何確定性的零件分類法——分割模型從藝術家創建的大量數據中學習,如何將對象分解為多個部分。
考慮將多數圖圖像作為輸入,模型的任務就是預測多個部分的mask。給定一個映射,將分割圖渲染為多視圖RGB圖像,然後對預訓練模型進行微調。
作者使用VAE將多視圖圖像編碼到潛在空間中,並將其與噪聲潛在空間堆疊起來,作為擴散網絡的輸入。
這種方法有兩個優勢:首先是利用了預訓練的圖像生成器,保證了天生具有視圖一致性;其次,生成方法允許簡單地從模型中重新采樣來進行多個合理的分割。
上下文部分補全
對於第二個問題,即在3D中重建分割的零件,普遍的方法是在現有的對象視圖中屏蔽零件,然後使用3D重建網絡進行恢復。
然而,當零件被嚴重遮擋時,這項任務相當於非模態重建,是高度模糊的,確定性重構網絡無法很好地解決。
本文建議微調另一個多視圖生成器來補全部分的視圖,同時考慮整個對象的上下文。
類似於上一個階段,研究人員將預訓練的VAE分別應用於蒙版圖像和上下文圖像,產生2 × 8個通道,並將它們與8D噪聲圖像和未編碼的部分掩碼堆疊在一起,獲得擴散模型的25通道輸入。

通過這種方式,即使零件在原始輸入視圖中僅部分可見,甚至不可見,也可以可靠地重建這些零件。此外,生成的部分可以很好地組合在一起,形成一個連貫的3D對象。
最後一步是在3D中重建零件。因為零件視圖已經是完整且一致的,所以可以簡單地使用重建網絡來生成預測,此階段的模型不需要特殊的微調。
訓練數據
為了訓練模型,研究人員從140k 3D藝術家生成的資產集合中構建了數據集(商業來源獲得AI訓練許可)。數據集中的示例對象如圖3所示。

對於方法中涉及微調的三個模型,每個模型的數據預處理方式都不同。
為了訓練多視圖生成器模型,首先必須將目標多視圖圖像(4個視圖組成)渲染到完整對象。
作者從正交方位角和20度仰角對4個視圖進行著色,並將它們排列在2 × 2網格中。
在文本條件下,訓練數據由多視圖圖像對及其文本標題組成,選擇10k最高質量的資產,並使用類似CAP3D的工作流生成它們的文本標題。
在圖像條件下,使用所有140k模型數據,設置隨機采樣以單個渲染的形式出現。
為了訓練零件分割和補全網絡,還需要渲染多視圖零件圖像及其深度圖。
由於不同的創作者對部分分解有不同的想法,因此作者過濾掉數據集中可能缺乏語義的過於精細的部分(首先剔除佔用對象體積小於5%的部分,然後刪除具有10個以上部分或由單個整體組成的資產)。
最終的數據集包含45k個對象(210k個零部件)。
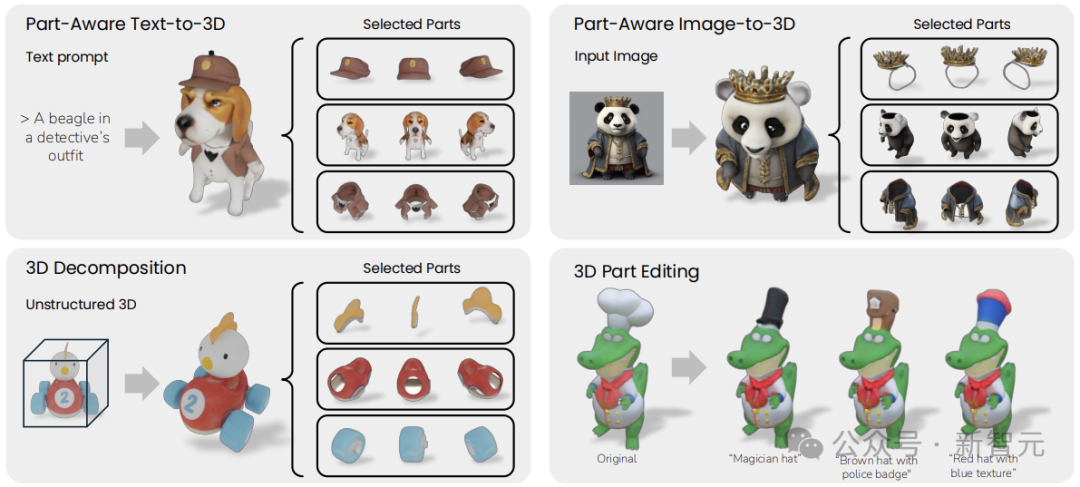
下遊應用
下圖給出了幾個應用示例:部件感知文本到3D生成、部件感知圖像到3D生成,以及真實世界的3D對象分解。
如圖所示,PartGen可以有效地生成具有不同部件的3D對象,即使在嚴重重疊的情況下,例如小熊軟糖。
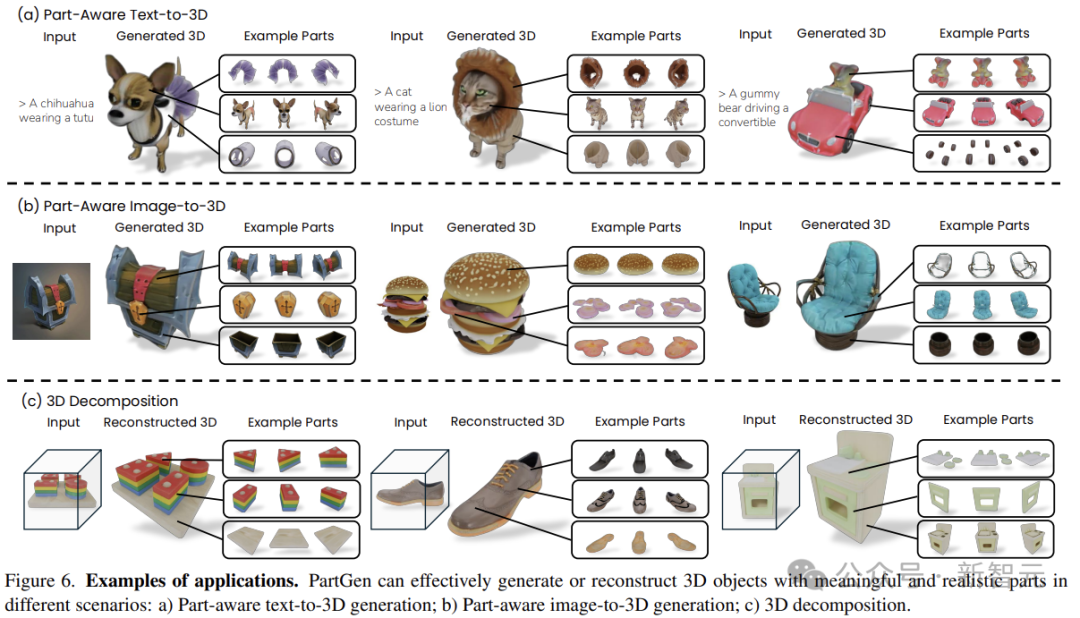
給定一個來自GSO(Google Scanned Objects)的3D對象,渲染不同的視圖以獲得圖像網格,圖6的最後一行顯示,PartGen可以有效地分解現實世界的3D對象。

當3D對象被分解之後,它們就可以通過文本輸入進一步修改。如圖7所示,PartGen可以根據文本提示有效地編輯零件的形狀和紋理。
參考資料:
https://x.com/MinghaoChen23/status/1871809184620323279



















