黃仁勳圈重點的世界模型平台是個什麼?技術報告全解析,華人貢獻中堅力量
AI 的下一個前沿是物理。在昨天的 CES 發佈會上,英偉達 CEO 黃仁勳通過一個名為「Cosmos」的平台點明了這一主題。
簡單來說,Cosmos 是一個世界模型平台,上面有一系列開源、開放權重的影片世界模型,參數量從 4B 到 14B 不等。這些模型的作用非常明確,就是為機器人、自動駕駛汽車等在物理世界中運行的 AI 系統生成大量照片級真實、基於物理的合成數據,以解決該領域數據嚴重不足的問題。
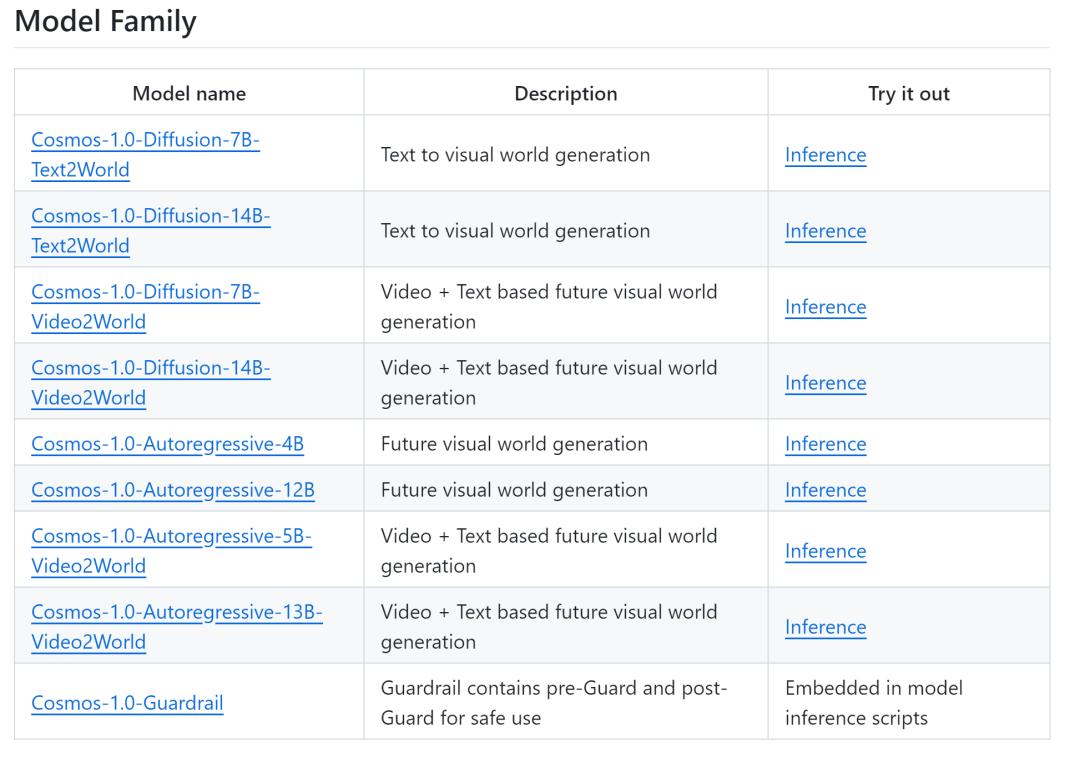 英偉達的 Cosmos 平台一次發佈了 8 個模型。
英偉達的 Cosmos 平台一次發佈了 8 個模型。 這些模型在 2000 萬小時的影片數據上進行訓練,分為擴散(連續 token)和自回歸(離散 token)模型兩類,支持文本生成影片和文本 + 影片生成影片兩種生成方式。
生成效果如下:

英偉達表示,已經有許多領先的機器人和汽車公司成為 Cosmos 的首批用戶,包括 1X、Agile Robots、Agility、Uber 等等。
黃仁勳表示:「機器人技術的 ChatGPT 時刻即將到來。與大型語言模型一樣,世界基礎模型對於推動機器人和自動駕駛汽車開發至關重要,但並非所有開發者都具備訓練自己的世界模型的專業知識和資源。我們創建 Cosmos 是為了讓物理 AI 普及化,讓每個開發者都能用上通用機器人技術。」
Cosmos 模型已經公開發佈,下面是相關地址:
英偉達 API 目錄:https://build.nvidia.com/explore/simulation
Hugging Face:https://huggingface.co/collections/nvidia/cosmos-6751e884dc10e013a0a0d8e6
除了模型,英偉達還公開了 Cosmos 的技術報告。從貢獻者名單來看,華人學者承擔了該項目的大量工作,有些小組(比如 Prompt Upsampler)甚至出現了全員華人的現象(文末可見完整名單)。

技術報告地址:https://d1qx31qr3h6wln.cloudfront.net/publications/NVIDIA%20Cosmos_4.pdf
以下是技術報告的核心內容。
技術報告概覽
技術報告主要介紹了用於構建物理 AI 的 Cosmos 世界基礎模型(WFM)平台。作者主要關注的是視覺世界基礎模型。在這種模型中,觀察結果以影片形式呈現,擾動可以以各種形式存在。
如圖 2 所示,作者提出了一個預訓練,然後後訓練的範式,將 WFM 分成預訓練 WFM 和後訓練 WFM。為了建立預訓練 WFM,他們利用大規模的影片訓練數據集,讓模型接觸到各種不同的視覺體驗,使其成為一個通才。
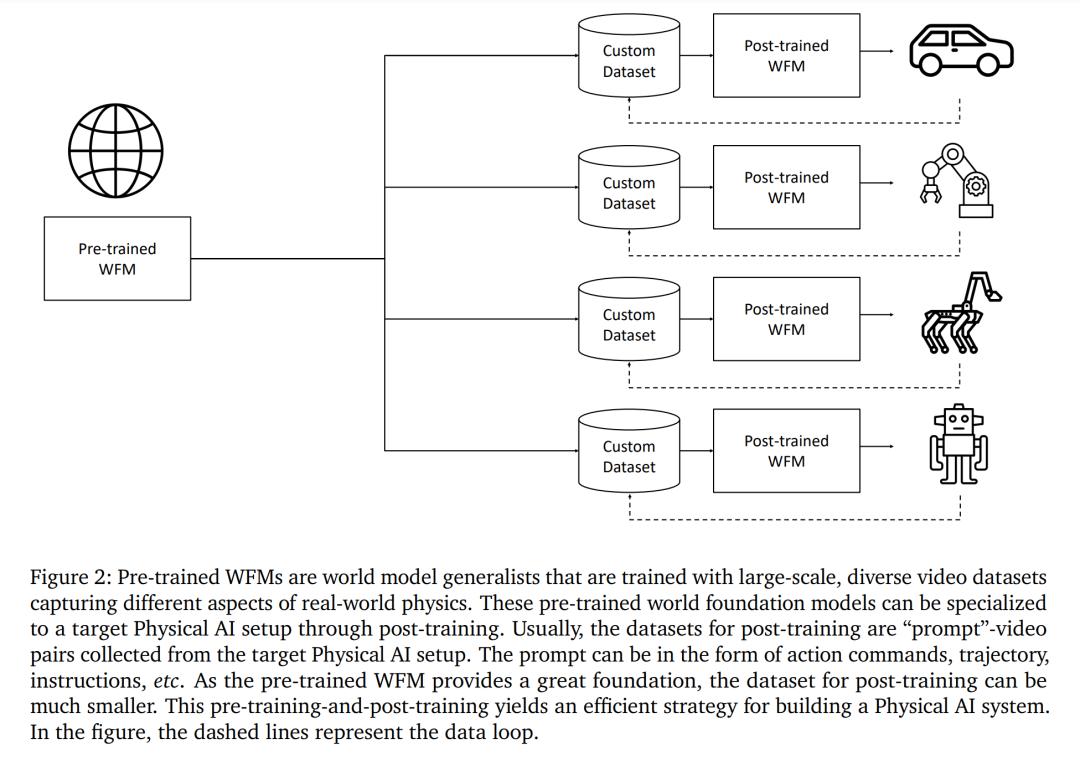
為了建立後訓練 WFM,他們使用從特定物理 AI 環境中收集的數據集,對預訓練 WFM 進行微調,以建立專門的 WFM,用於目標明確的專門物理 AI 設置。圖 1 展示了預訓練和後訓練 WFM 的結果示例。


數據決定了 AI 模型的上限。為了構建一個高上限的預訓練 WFM,作者開發了一個影片數據整理 pipeline。他們用它來定位具有豐富動態效果和高視覺質量的影片部分,以促進模型學習編碼在視覺內容中的物理知識。
作者使用該 pipeline 從長達 2000 萬小時的影片集合中提取了約 1 億個影片片段,片段長度從 2 秒到 60 秒不等。對於每個片段,他們使用視覺語言模型(VLM)為每 256 幀提供一個影片描述。影片處理是計算密集型工作。作者利用現代 GPU 硬件實現的 H.264 影片編碼器和解碼器進行解碼和轉碼。這個影片數據整理 pipeline 利用了許多預訓練的圖像 / 影片理解模型。這些模型具有不同的吞吐量。為了最大限度地提高生成可訓練影片數據的總體吞吐量,作者構建了一個基於 Ray 的協調 pipeline。
在報告中,作者探討了兩種用於構建預訓練 WFM 的可擴展方法。這兩種方法是基於 transformer 的擴散模型和自回歸模型。擴散模型通過逐步去除高斯噪聲影片中的噪聲來生成影片。自回歸模型基於之前的生成內容,按照預設順序逐段生成影片。
這兩種方法都能將困難的影片生成問題分解為更容易解決的子問題,從而使問題更加容易解決。作者利用 SOTA transformer 架構來提高其可擴展性。在第 5.1 節中,他們介紹了一種基於 Transformer 的擴散模型設計,它具有強大的世界生成能力。在第 5.2 節中,他們介紹了一種基於 Transformer 的自回歸模型設計,用於生成世界。
基於 Transformer 的擴散模型和基於 Transformer 的自回歸模型都使用 token 來表示影片,前者使用向量形式的連續 token,後者使用整數形式的離散 token。作者注意到,影片 token 化 —— 一個將影片轉換為 token 集的過程 —— 是一個非常複雜的過程。影片包含豐富的視覺世界信息。然而,為了便於學習世界基礎模型,我們需要將影片壓縮為緊湊的 token 序列,同時最大限度地保留影片中的原始內容,因為世界基礎模型訓練的計算複雜度會隨著 token 數量的增加而增加。在很多方面,構建影片 tokenizer 與構建影片編解碼器類似。作者開發了一種基於注意力的編碼器 – 解碼器架構,用於學習連續和離散 token 的影片 token 化(見第 4 章)。
在第 6 章中,作者對預訓練的 WFM 進行微調,以獲得適用於各種物理 AI 任務的後訓練 WFM。在第 6.1 節中,作者對預訓練的擴散 WFM 進行微調,使其成為相機姿態條件。這種後訓練創建了一個可導航的虛擬世界,用戶可以通過移動虛擬視點來探索所創建的世界。在第 6.2 節中,他們在由影片動作序列組成的各種機器人任務中對 WFM 進行微調。結果表明,通過利用預訓練的 WFM,可以根據機器人採取的行動更好地預測世界的未來狀態。在第 6.3 節中,作者演示了如何針對各種自動駕駛相關任務對預訓練的 WFM 進行微調。
英偉達開發的 WFM 的預期用途是物理 AI 構建者。為了在使用 WFM 時更好地保護開發人員,作者開發了一個功能強大的防護系統,其中包括一個用於阻止有害輸入的前置防護系統和一個用於阻止有害輸出的後置防護系統。詳情見第 7 章。
英偉達的目標是建立一個世界基礎模型平台,幫助物理 AI 構建者推進他們的系統。為了實現這一目標,他們根據 NVIDIA 開放模型許可,分別在 NVIDIA Cosmos 和 NVIDIA Cosmos Tokenizer 目錄下提供預訓練的世界基礎模型和 tokenizer。預訓練腳本和後訓練腳本將與影片數據整理 pipeline 一起在 NVIDIA Nemo Framework 目錄下提供,以幫助構建者製作微調數據集。
NVIDIA Cosmos:https://github.com/NVIDIA/Cosmos
NVIDIA Cosmos Tokenizer:https://github.com/NVIDIA/Cosmos-Tokenizer
NVIDIA Nemo Framework:https://github.com/NVIDIA/Nemo
世界基礎模型平台
設𝑥_0:𝑡為從時間 0 到𝑡對現實世界的一系列視覺觀察,𝑐_𝑡為世界的擾動。如圖 3 所示,WFM 是一個為 W 的模型,它基於過去的觀察
, 和當前的擾動 c_t 來預測時間 t+1 的未來觀察
。 在示例中,𝑥_0:𝑡 是 RGB 影片,而 𝑐_𝑡 是一種可以採取多種形式的擾動。 它可以是物理 AI 採取的動作、隨機擾動、擾動的文本描述等。

圖 4 直觀地展示了 Cosmos WFM 平台中可用的功能,包括影片 curator、影片 tokenization、世界基礎模型預訓練、世界基礎模型後訓練和護欄(guardrail)。
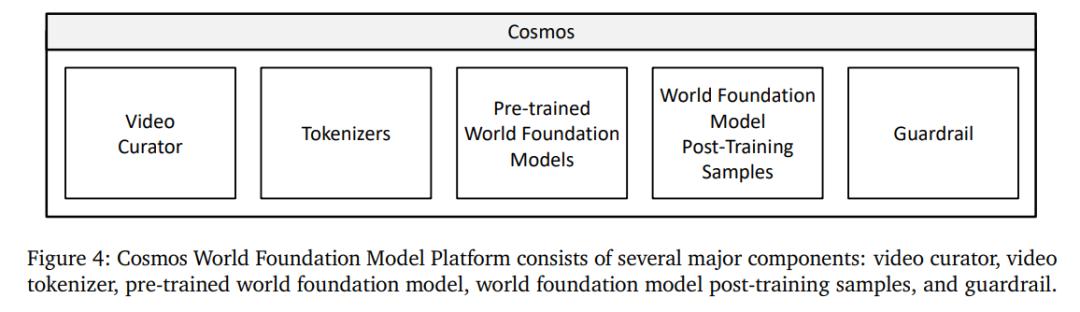
具體而言:
影片 curator。 本文開發了一個可擴展的影片數據 pipeline。每個影片被分割成沒有場景變化的獨立鏡頭。隨後,對這些片段應用一系列過濾步驟,以篩選出高質量且富含動態信息的子集用於訓練。這些高質量鏡頭隨後使用視覺語言模型(VLM)進行標註。接著執行語義去重,以構建一個多樣但緊湊的數據集。
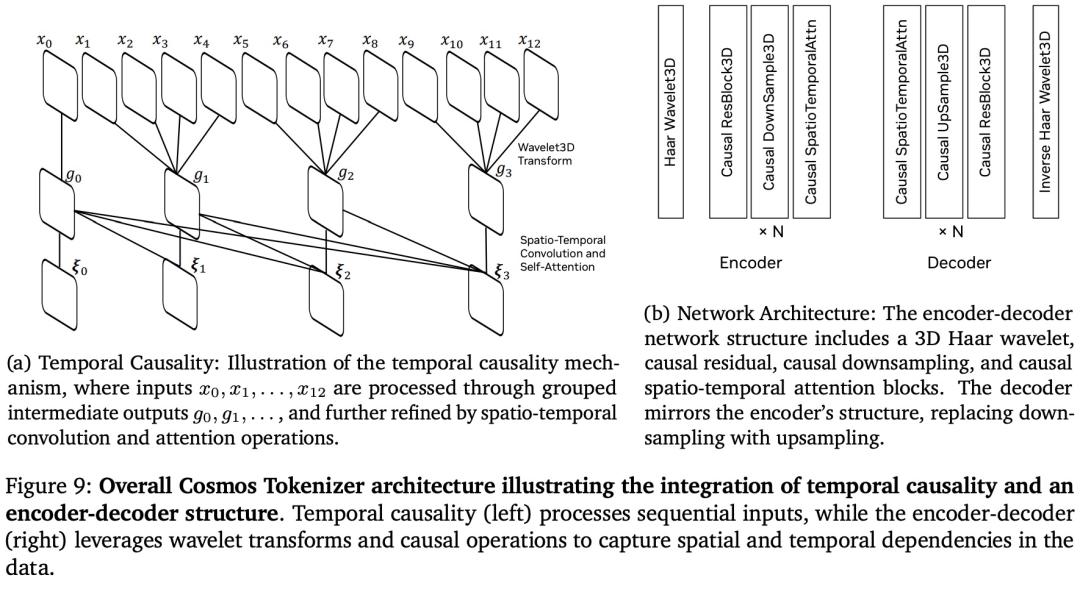
影片 tokenization。 本文開發了一系列具有不同壓縮比的影片 tokenizer。這些 tokenizer 是因果性的,當前幀的 token 計算不依賴於未來的觀測。這種因果設計有幾個優點。在訓練方面,它使得聯合圖像和影片訓練成為可能,因為當輸入是單張圖像時,因果影片 tokenizer 也可以作為圖像 tokenizer 使用。這對於影片模型利用圖像數據集進行訓練非常重要,因為圖像數據集包含了豐富的世界外觀信息,並且往往更加多樣化。
WFM 預訓練。 本文探索了兩種可擴展的方法來構建預訓練的世界基礎模型 —— 擴散模型和自回歸模型。
對於基於擴散的 WFM,預訓練包括兩個步驟:1)Text2World 生成的預訓練,以及 2)Video2World 生成的預訓練;
對於基於自回歸的 WFM,預訓練包括兩個步驟:1)基礎的下一 token 生成,以及 2)文本 – 條件 Video2World 生成。
世界模型後訓練。 本文展示了經過預訓練的 WFM 在多個下遊物理 AI 應用中的應用。本文以相機姿態作為輸入提示對預訓練的 WFM 進行微調,因而模型能夠在創建的世界中自由導航。此外,本文還展示了如何針對人形機器人和自動駕駛任務對預訓練 WFM 進行微調。
護欄。 為了安全使用所開發的世界基礎模型,本文開發了一個護欄系統,用於阻止有害的輸入和輸出。
Tokenizer
tokenizer 是現代大模型的基本構建塊,能將原始數據轉換為更有效的表徵。具體來說,視覺 tokenizer 將原始和冗餘的視覺數據(例如圖像和影片)映射為緊湊的語義 token,這使得它們對於處理高維視覺數據至關重要。這種能力不僅能夠有效訓練大規模 Transformer 模型,而且還使有限計算資源上的推理民主化。
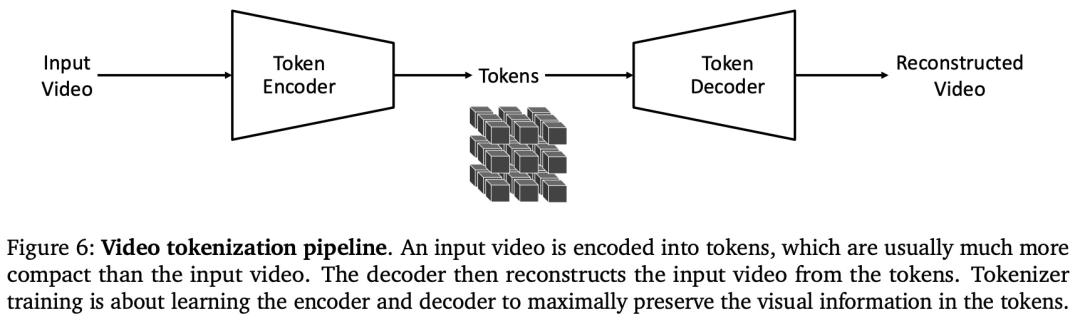
tokenizer 有兩種類型:連續型和離散型。連續型 tokenizer 將視覺數據編碼為連續的潛在嵌入,如 Stable Diffusion 或 VideoLDM 等潛在擴散模型。這些嵌入適用於通過從連續分佈中采樣生成數據的模型。離散 tokenizer 將視覺數據編碼為離散潛在編碼,將其映射為量化索引,如 VideoPoet 等自回歸 transformer。這種離散表徵對於像 GPT 這樣用交叉熵損失訓練的模型來說是必要的。
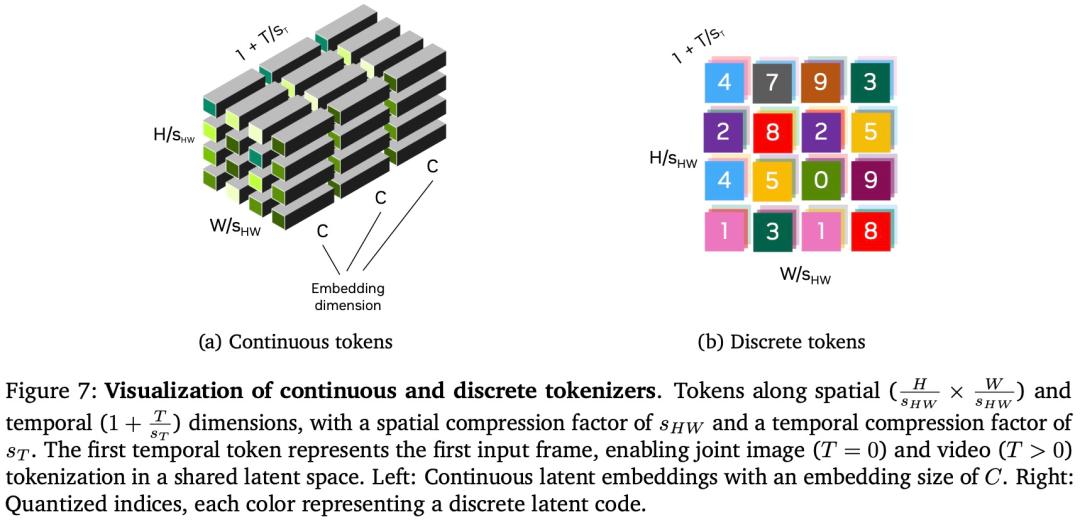
tokenizer 的成功在很大程度上依賴於它們提供高壓縮率而不影響後續視覺重建質量的能力。一方面,高壓縮減少了存儲和計算需求。另一方面,過度壓縮可能會導致重要視覺細節丟失。這種權衡對 tokenizer 的設計提出了重大挑戰。
英偉達推出了 Cosmos Tokenizer,這是一組視覺 tokenizer,其中包括用於圖像和影片的連續和離散 tokenizer。Cosmos Tokenizer 提供卓越的視覺重建質量和推理效率。並提供一系列壓縮率來適應不同的計算限制和應用程序需求。

英偉達使用輕量級且計算高效的架構和時間因果機制來設計 Cosmos Tokenizer。具體來說,Cosmos Tokenizer 採用因果時間卷積層和因果時間注意力層來保留影片幀的自然時間順序,確保使用單一統一網絡架構對圖像和影片進行無縫 tokenization。
 如圖 8 所示,評估結果表明,Cosmos Tokenizer 的性能明顯優於現有 tokenizer:
如圖 8 所示,評估結果表明,Cosmos Tokenizer 的性能明顯優於現有 tokenizer: 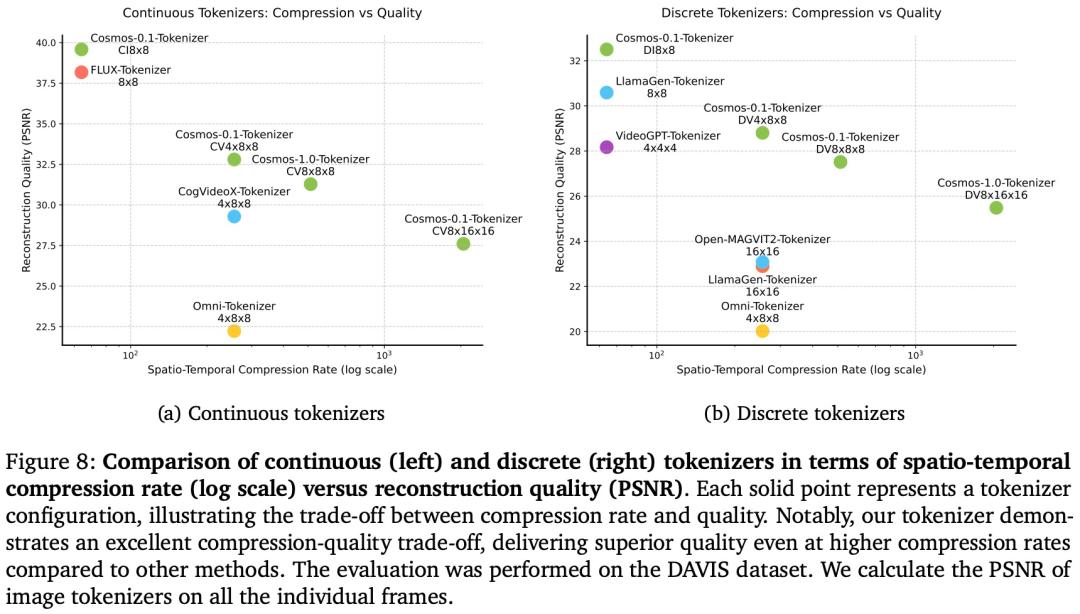
世界基礎模型預訓練
經過預訓練的 WFM 是通才模型,可以捕捉現實世界物理和自然行為的一般知識。本文利用兩種不同的可擴展深度學習範式 —— 擴散模型和自回歸模型,構建了兩類 WFM。
擴散模型和自回歸模型都將複雜的生成問題分解為一系列更簡單的子問題,並極大地推動了生成模型的發展。
對於擴散模型,複雜的生成問題被分解為一系列去噪問題;而對於自回歸模型,複雜的生成問題則被分解為一系列下一個 token 預測問題。
本文在三個月的時間內,使用一個由 10,000 個 NVIDIA H100 GPU 組成的集群,訓練了論文中報告的所有 WFM。
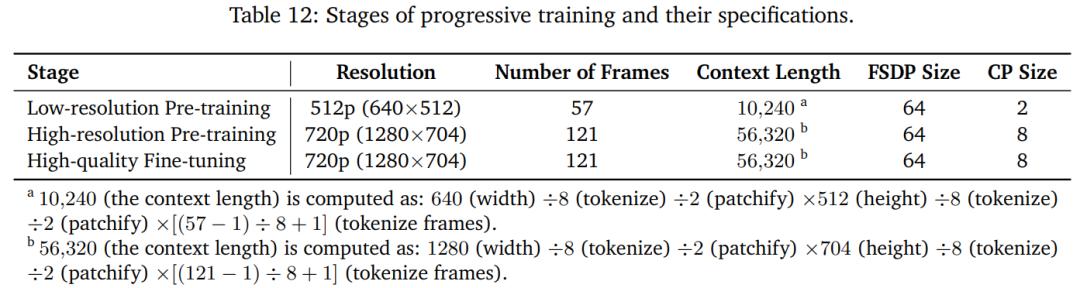
表 10 展示了預訓練 WFM 及其配套模型的概覽。
對於基於擴散的 WFM 家族,本文首先構建了兩個 Text2World 模型,分別為 7B 和 14B 參數,分別命名為 Cosmos-1.0-Diffusion-7B-Text2World 和 Cosmos-1.0-Diffusion-14B-Text2World。
對於基於自回歸的 WFM 家族,本文首先構建了兩個基礎模型,分別為 4B 和 12B 參數,命名為 Cosmos-1.0-Autoregressive-4B 和 Cosmos-1.0-Autoregressive-12B。這些模型純粹基於當前影片觀測預測未來影片。
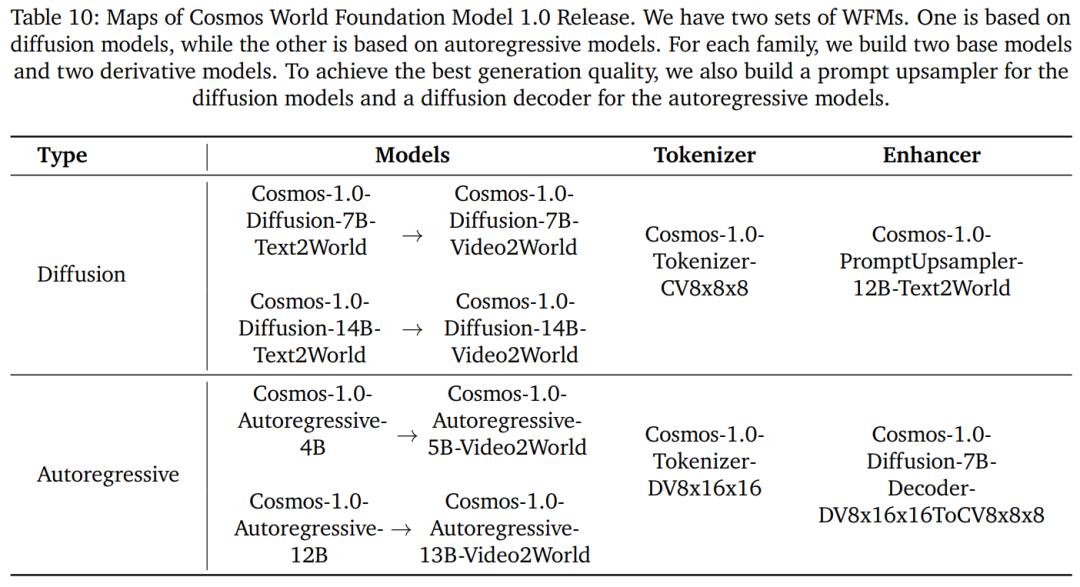
Cosmos-1.0-Diffusion WFM 的整體架構:
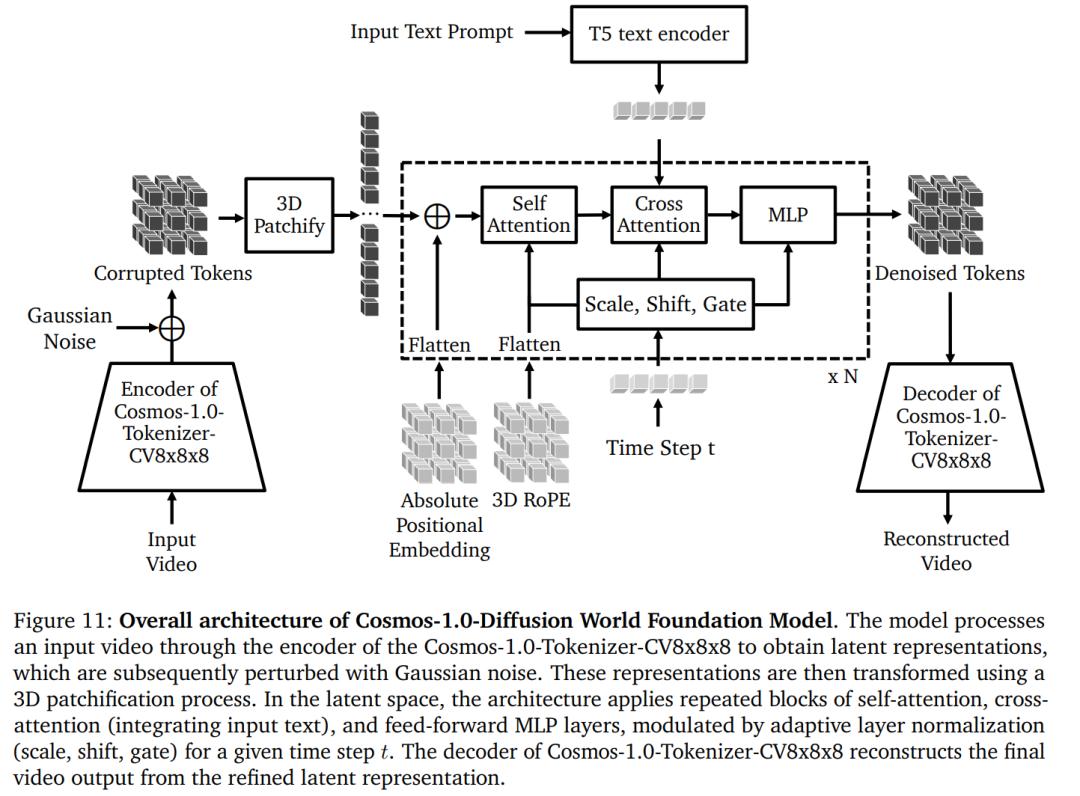
Cosmos-1.0-Diffusion 模型的配置細節。
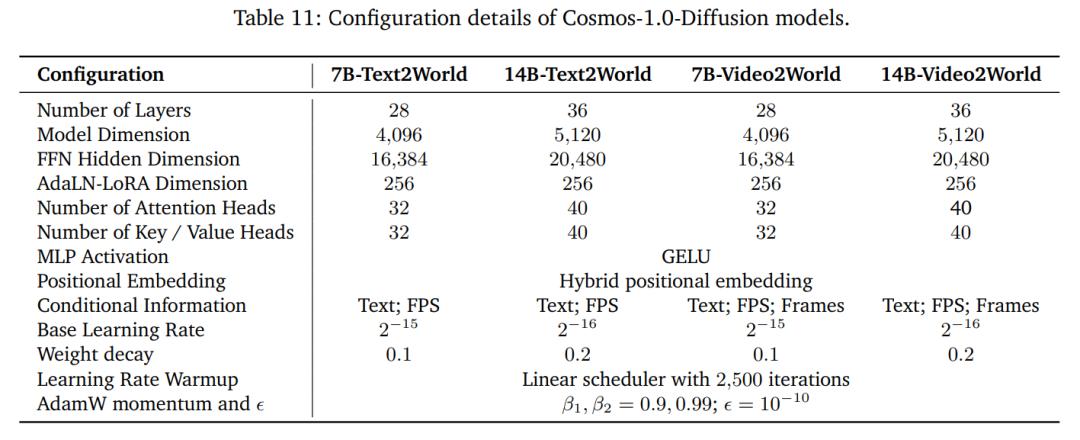
本文採用漸進式訓練策略,每個階段的具體情況見表 12:
基於自回歸的 WFM 架構如圖 14 所示。本文對標準的 Transformer 模型架構進行了幾項修改,以適應影片生成任務,包括添加了:1)3D 感知的位置嵌入,2)交叉注意力機制以支持文本輸入,從而實現更好的控制,以及 3)QK-Normalization。
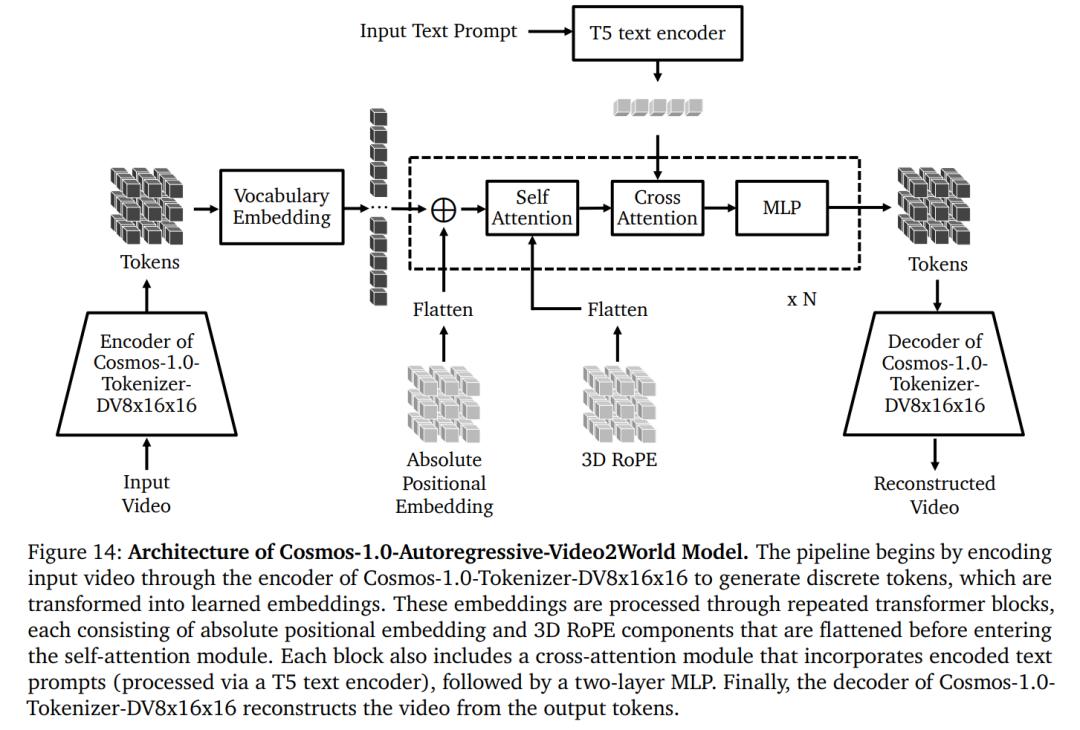
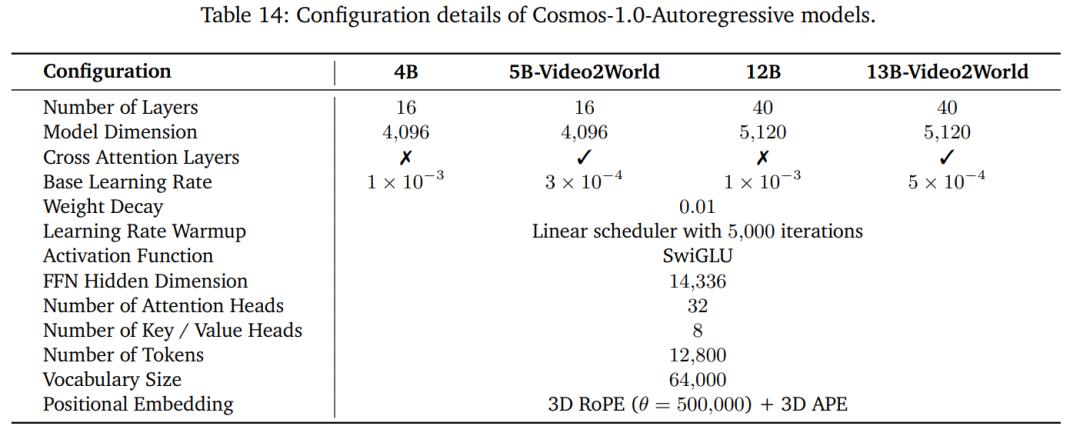
Cosmos-1.0-Autoregressive 模型配置細節。
技術報告演示了如何微調 Cosmos WFM 以支持不同的物理 AI 應用,包括:

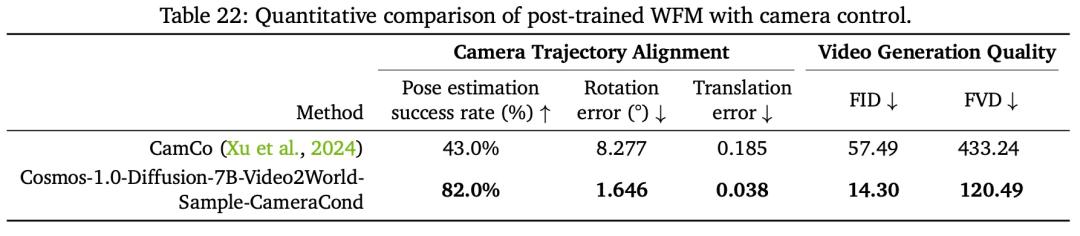
以用於相機控制的後訓練 WFM 為例,通過相機姿態調節,英偉達將相機控制集成到 Cosmos-1.0-Diffusion-7B-Video2World 中,使其成為有效的 3D 世界模擬器。訓練後的 WFM 結果被稱為 Cosmos-1.0-Diffusion-7BVideo2World-Sample-CameraCond。

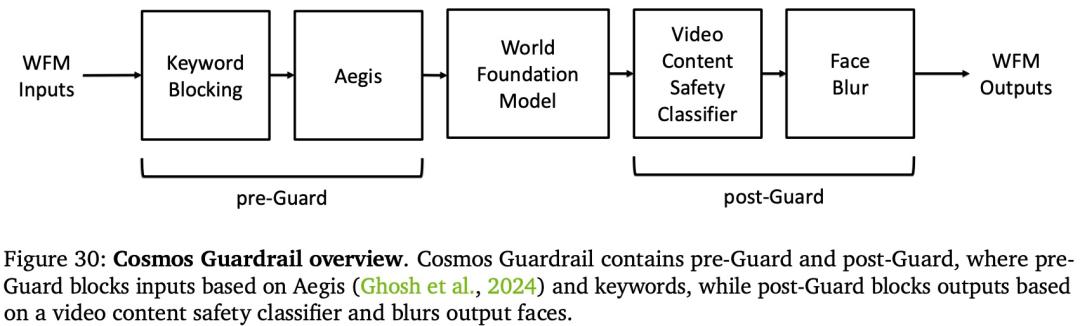
為了安全使用 WFM,英偉達還開發了一套全面的安全系統(護欄)。它由兩個階段組成:Pre-Guard 階段和 Post-Guard 階段。Pre-Guard 階段利用 Aegis(Ghosh 等人,2024)和關鍵字列表來阻止有害提示。Post-Guard 階段使用影片內容安全分類器和麵部模糊過濾器來阻止有害的視覺輸出。
核心貢獻者
論文最後還列出了貢獻者名單,佔據了整整一頁的篇幅。
名單分為核心貢獻者和貢獻者,粗略看下來,華人學者幾乎佔據了半壁江山。在這份名單中,我們看到了許多熟悉的研究者,比如:
平台架構唯一貢獻者 Ming-Yu Liu,他是 NVIDIA 的研究副總裁和 IEEE Fellow。他現在領導 NVIDIA 的深度想像研究(Deep Imagination Research)團隊,專注於深度生成模型及其在內容創作中的應用。
多次出現名字的淩歡,是 Nvidia Toronto AI Lab 的人工智能科學家。博士畢業於多倫多大學 PhD,博士期間師從 Sanja Fidler 教授。他的研究方向主攻大規模圖像視屏生成模型,和生成模型在計算機視覺領域的應用。
完整名單如下所示,裡面有你熟悉的學者嗎?

本文來自微信公眾號「機器之心」,36氪經授權發佈。



















