超越KL!大連理工發佈Wasserstein距離知識蒸餾新方法|NeurIPS 2024

新智元報導
編輯:LRST
【新智元導讀】大連理工大學的研究人員提出了一種基於Wasserstein距離的知識蒸餾方法,克服了傳統KL散度在Logit和Feature知識遷移中的局限性,在圖像分類和目標檢測任務上表現更好。
自Hinton等人的開創性工作以來,基於Kullback-Leibler散度(KL-Div)的知識蒸餾一直佔主導地位。
然而,KL-Div僅比較教師和學生在相應類別上的概率,缺乏跨類別比較的機制,應用於中間層蒸餾時存在問題,其無法處理不重疊的分佈且無法感知底層流形的幾何結構。
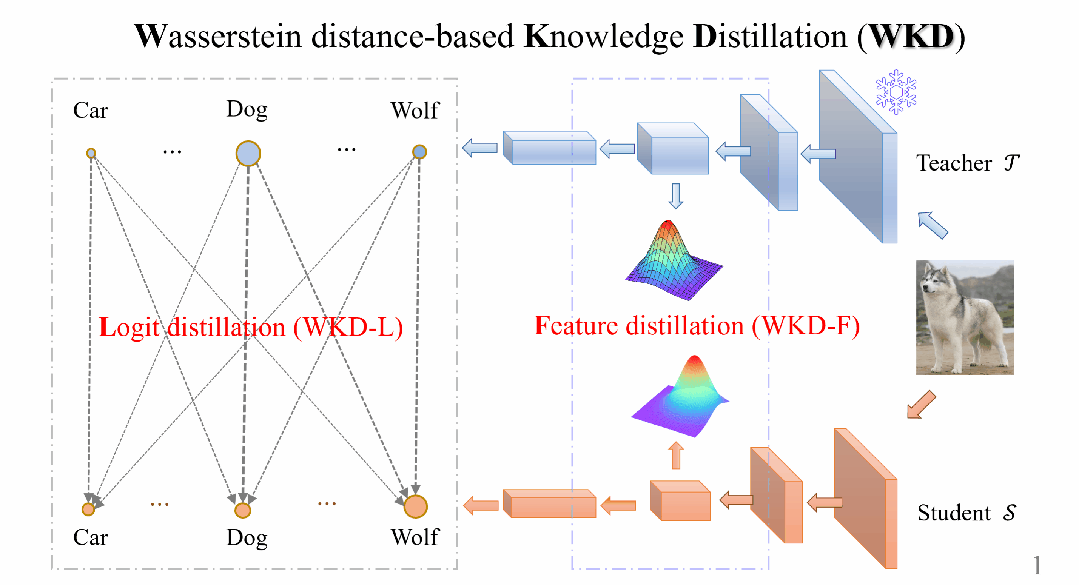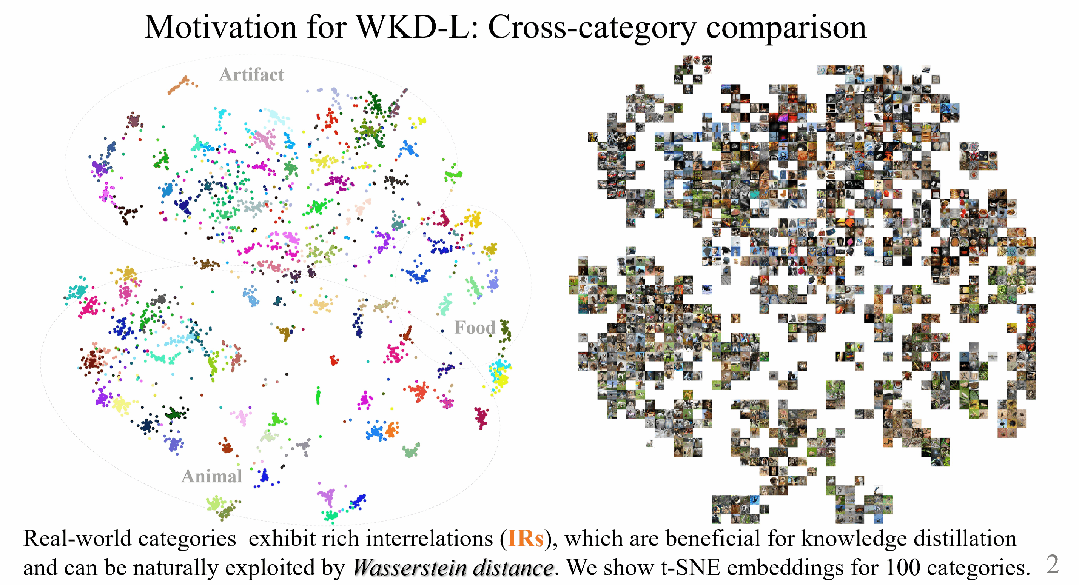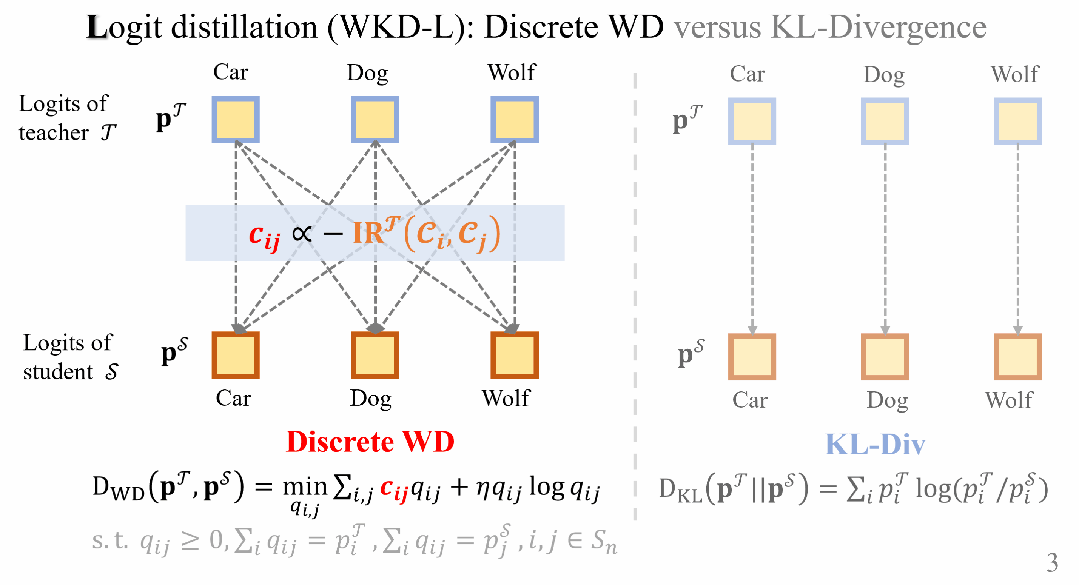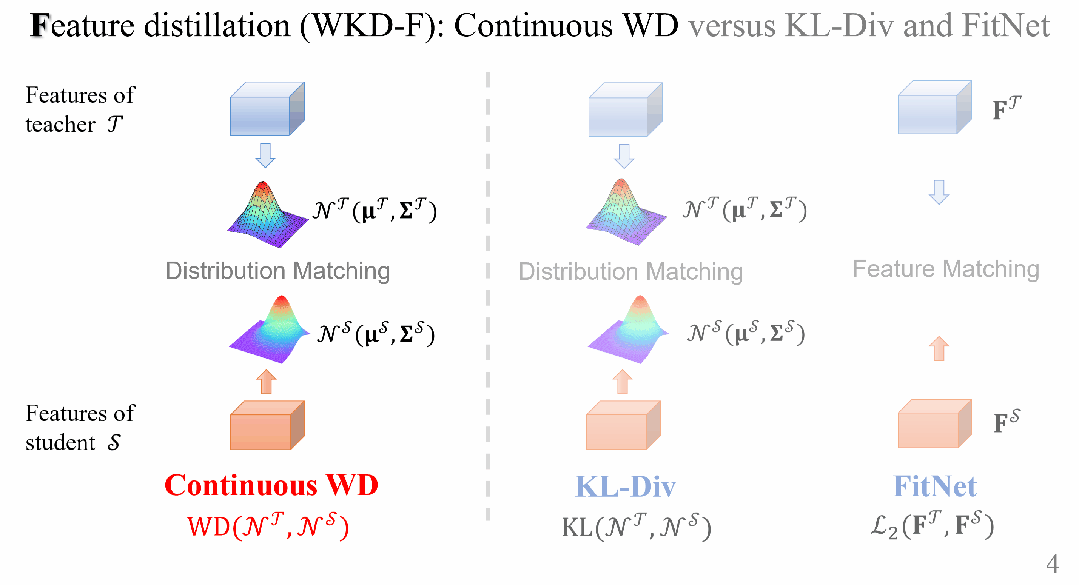
為瞭解決這些問題,大連理工大學的研究人員提出了一種基於Wasserstein距離(WD)的知識蒸餾方法。所提出方法在圖像分類和目標檢測任務上均取得了當前最好的性能,論文已被NeurIPS 2024接受為Poster

論文地址:https://arxiv.org/abs/2412.08139
項目地址:https://peihuali.org/WKD/
代碼地址:https://github.com/JiamingLv/WKD
背景與動機介紹
知識蒸餾(KD)旨在將具有大容量的高性能教師模型中的知識遷移到輕量級的學生模型中。近年來,知識蒸餾在深度學習中受到了越來越多的關注,並取得了顯著進展,在視覺識別、目標檢測等多個領域得到了廣泛應用。
在其開創性工作中,Hinton等人引入了Kullback-Leibler散度(KL-Div)用於知識蒸餾,約束學生模型的類別概率預測與教師模型相似。
從那時起,KL-Div在Logit蒸餾中佔據主導地位,並且其變體方法DKD、NKD等也取得了令人矚目的性能。此外,這些Logit蒸餾方法還可以與將知識從中間層傳遞的許多先進方法相互補充。
儘管KL-Div取得了巨大的成功,但它存在的兩個缺點阻礙了教師模型知識的遷移。
首先,KL-Div僅比較教師和學生在相應類別上的概率,缺乏執行跨類別比較的機制。
然而,現實世界中的類別呈現不同程度的視覺相似性,例如,哺乳動物物種如狗和狼彼此間的相似度較高,而與汽車和單車等人工製品則有很大的視覺差異,如圖1所示。
不幸的是,由於KL-Div是類別對類別的比較,KD和其變體方法無法顯式地利用這種豐富的跨類別知識。
圖1 左圖使用t-SNE展示了100個類別的嵌入分佈。可以看出,這些類別在特徵空間中表現出豐富的相互關係 (IR)。然而,右圖中的KL散度無法顯式地利用這些相互關係
其次,KL-Div在用於從中間層特徵進行知識蒸餾時存在局限性。圖像的深度特徵通常是高維的且空間尺寸較小,因此其在特徵空間中非常稀疏,不僅使得KL-Div在處理深度神經網絡特徵的分佈時存在困難。
KL-Div無法處理不重疊的離散分佈,並且由於其不是一個度量,在處理連續分佈時能力有限,無法感知底層流形的幾何結構。
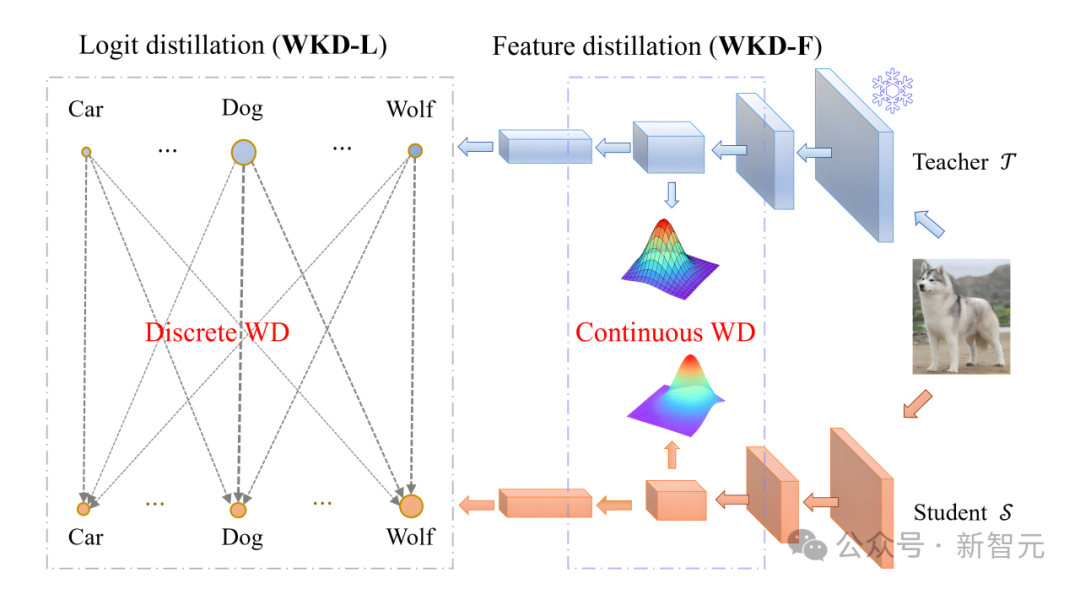 圖2 基於Wasserstein距離(WD)的知識蒸餾方法的總覽圖
圖2 基於Wasserstein距離(WD)的知識蒸餾方法的總覽圖為瞭解決這些問題,研究人員提出了一種基於Wasserstein距離的知識蒸餾方法,稱為WKD,同時適用於Logit蒸餾(WKD-L)和Feature蒸餾(WKD-F),如圖2所示。
在WKD-L中,通過離散WD最小化教師和學生之間預測概率的差異,從而進行知識轉移。
通過這種方式,執行跨類別的比較,能夠有效地利用類別間的相互關係(IRs),與KL-Div中的類別間比較形成鮮明對比。
對於WKD-F,研究人員利用WD從中間層特徵中蒸餾知識,選擇參數化方法來建模特徵的分佈,並讓學生直接匹配教師的特徵分佈。
具體來說,利用一種最廣泛使用的連續分佈(高斯分佈),該分佈在給定特徵的1階和2階矩的情況下具有最大熵。
論文的主要貢獻可以總結如下:
提出了一種基於離散WD的Logit蒸餾方法(WKD-L),可以通過教師和學生預測概率之間的跨類別比較,利用類別間豐富的相互關係,克服KL-Div無法進行類別間比較的缺點。
將連續WD引入中間層進行Feature蒸餾(WKD-F),可以有效地利用高斯分佈的Riemann空間幾何結構,優於無法感知幾何結構的KL-Div。
在圖像分類和目標檢測任務中,WKD-L優於非常強的基於KL-Div的Logit蒸餾方法,而WKD-F在特徵蒸餾中優於KL-Div的對比方法和最先進的方法。WKD-L和WKD-F的結合可以進一步提高性能。
用於知識遷移的WD距離
用於Logit蒸餾的離散WD距離
類別之間的相互關係(IRs)
如圖1所示,現實世界中的類別在特徵空間中表現出複雜的拓撲關係。相同類別的特徵會聚集並形成一個分佈,而相鄰類別的特徵有重疊且不能完全分離。
因此,研究人員提出基於CKA量化類別間的相互關係(IRs),CKA是一種歸一化的Hilbert-Schmidt獨立性準則(HSIC),通過將兩個特徵集映射到再生核高治伯特空間(RKHS)來建模統計關係。
首先將每個類別中所有訓練樣本的特徵構成一個特徵矩陣,之後通過計算任意兩個類別特徵矩陣之間的CKA得到類間相互關係(IR)。計算IR的成本可以忽略,因為在訓練前僅需計算一次。
由於教師模型通常包含更豐富的知識,因此使用教師模型來計算類別間的相互關係
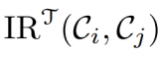
損失函數
用
分別表示教師模型和學生模型的預測類別概率,其通過softmax函數和溫度對Logit計算得到。將離散的WD表示為一種熵正則化的線性規劃:
和
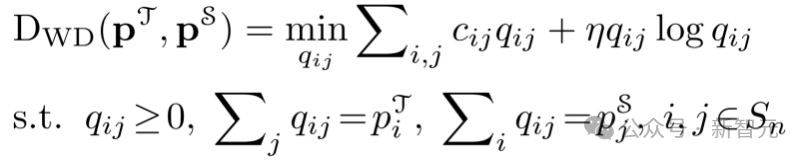
其中和
移動到
分別表示每單位質量的運輸成本和在將概率質量從
時的運輸量;
是正則化參數。
定義運輸成本與相似度度量
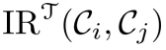
成負相關。
因此,WKD-L的損失函數可以定義為:
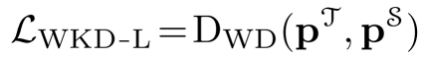
用於Feature蒸餾的連續WD距離
特徵分佈建模
將模型某個中間層輸出的特徵圖重塑為一個矩陣,其中第i列
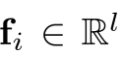
表示一個空間特徵。
之後,估計這些特徵的一階矩
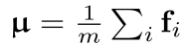
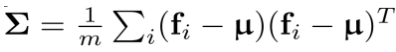
,並將二者作為高斯分佈的參數來建模輸入圖像特徵的分佈。
和二階矩
損失函數
設教師的特徵分佈為高斯分佈
。類似地,學生的分佈記為
兩者之間的連續Wasserstein距離(WD)定義為:
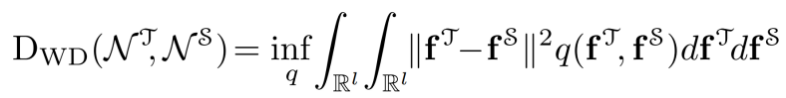
其中,和
是高斯變量,q表示聯合分佈。最小化上式可以得到閉集形式的WD距離。此外,為了平衡均值和協方差的作用,引入了一個均值-協方差比率γ,最後損失定義為:
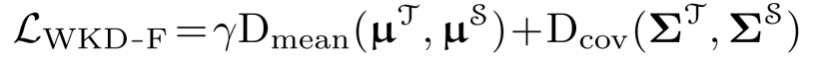
實驗分析和比較
研究人員在ImageNet和CIFAR-100上評估了WKD在圖像分類任務中的表現,還評估了WKD在自蒸餾(Self-KD)中的有效,並且將WKD擴展到目標檢測,並在MS-COCO上進行了實驗。
在ImageNet上的圖像分類
研究人員在ImageNet的在兩種設置下與現有工作進行了比較。設置(a)涉及同質架構,其中教師和學生網絡分別為ResNet34和ResNet18;設置(b)涉及異質架構,在該設置中,教師網絡為ResNet50,學生網絡為MobileNetV1。
對於Logit蒸餾,WKD-L在兩種設置下均優於經典的KD及其所有變體。對於特徵蒸餾,WKD-F也超過當前的最佳方法ReviewKD;最後,WKD-L和WKD-F的結合進一步提升了性能,超越了強有力的競爭方法。
 表1 在ImageNet上的圖像分類結果
表1 在ImageNet上的圖像分類結果在CIFAR-100上的圖像分類
研究人員在教師模型為CNN、學生為Transformer或反之的設置下評估了WKD方法,使用的CNN模型包括ResNet(RN)、MobileNetV2(MNV2)和ConvNeXt;Transformer模型包括ViT、DeiT和Swin Transformer。
對於Logit蒸餾,WKD-L在從Transformer到CNN遷移知識或反之的設置下始終優於最新的OFA方法。對於特徵蒸餾,WKD-F在所有實驗設置中排名第一;
研究人員認為,對於跨CNN和Transformer的知識轉移,考慮到兩者特徵差異較大,WKD-F比像FitNet和CRD這樣直接對原始特徵進行對齊的方法更為合適。
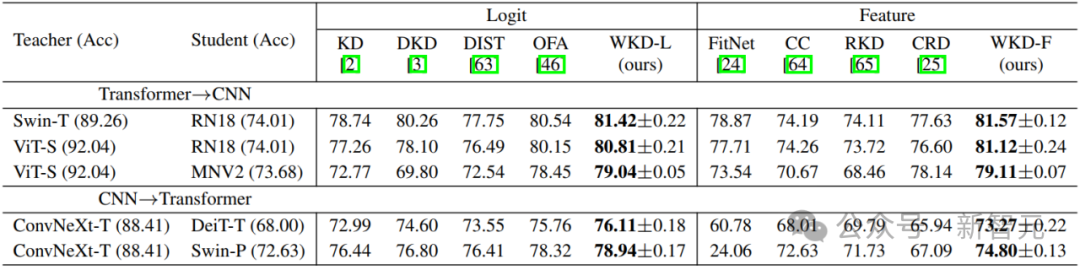 表2 CIFAR-100上跨CNN和Transformer的圖像分類結果(Top-1準確率)
表2 CIFAR-100上跨CNN和Transformer的圖像分類結果(Top-1準確率)在ImageNet上的自蒸餾
研究人員在Born-Again Network(BAN)框架中將WKD方法用於自蒸餾任務(Self-KD)。
使用ResNet18在ImageNet上進行實驗,結果如表3所示,WKD-L取得了最佳結果,比BAN的Top-1準確率高出約0.9%,比第二高的USKD方法卡奧出0.6%。這一比較表明,WKD方法可以很好地推廣到自蒸餾任務中。
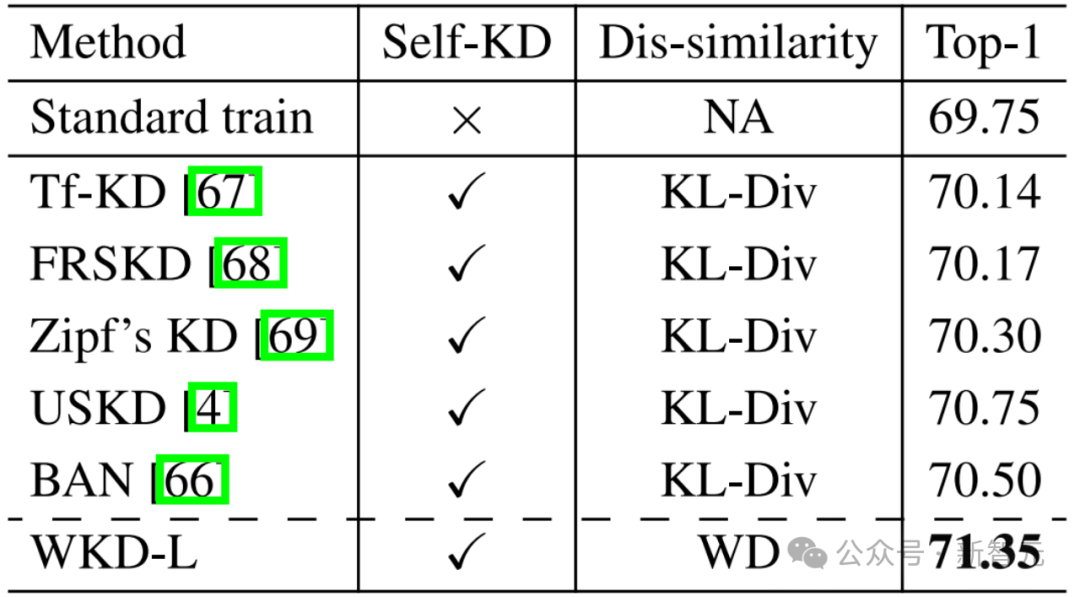 表3 在ImageNet上自蒸餾(Self-KD)的結果
表3 在ImageNet上自蒸餾(Self-KD)的結果在MS-COCO上的目標檢測
研究人員將WKD擴展到Faster-RCNN框架下的目標檢測中。對於WKD-L,使用檢測頭中的分類分支進行Logit蒸餾。對於WKD-F,直接從輸入到分類分支的特徵中進行知識遷移,即從RoIAlign層輸出的特徵來計算高斯分佈。
對於Logit蒸餾,WKD-L顯著優於經典的KD,並略微優於DKD。對於特徵蒸餾,WKD-F在兩個設置中均顯著超過之前的最佳特徵蒸餾方法ReviewKD。最後,通過結合WKD-L和WKD-F,表現超過了DKD+ReviewKD。當使用額外的邊框回歸進行知識遷移時,WKD-L+WKD-F進一步提高並超越了之前的最先進方法FCFD。
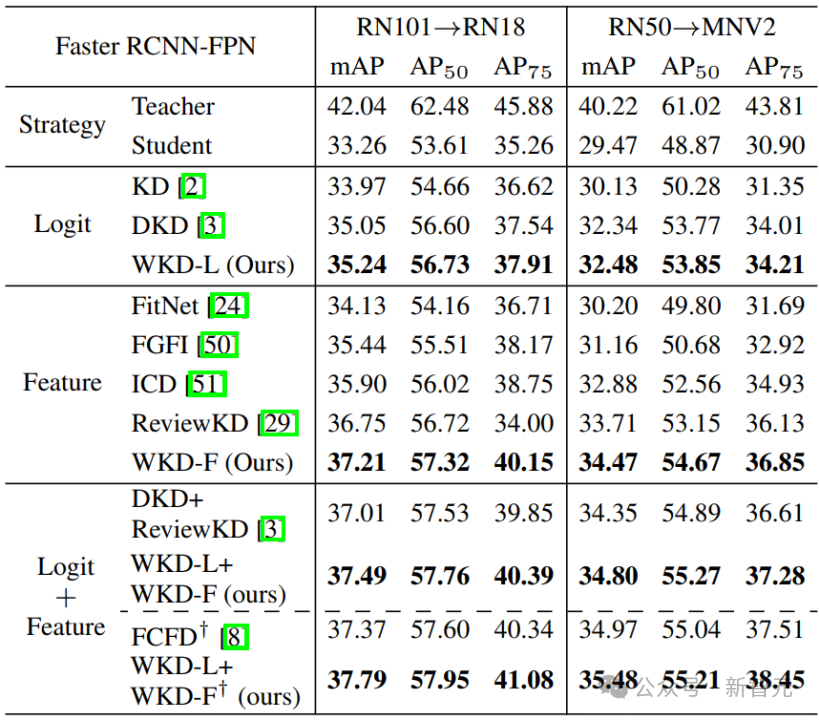 表4 在MS-COCO上的目標檢測結果。†:使用了額外的邊框回歸進行知識遷移
表4 在MS-COCO上的目標檢測結果。†:使用了額外的邊框回歸進行知識遷移結論
Wasserstein距離(WD)在生成模型等多個領域中已展現出相較於KL散度(KL-Div)的顯著優勢。
然而,在知識蒸餾領域,KL散度仍然佔據主導地位,目前尚不清楚Wasserstein距離能否實現更優的表現。
研究人員認為,早期基於Wasserstein距離的知識蒸餾研究未能充分發揮該度量的潛力。
因此,文中提出了一種基於Wasserstein距離的全新知識蒸餾方法,能夠從Logit和Feature兩個方面進行知識遷移。
大量的實驗表明,離散形式的Wasserstein距離在Logit蒸餾中是當前主流KL散度的極具潛力的替代方案,而連續形式的Wasserstein距離在中間層特徵遷移中也取得了令人信服的性能表現。
儘管如此,該方法仍存在一定局限性:WKD-L相比基於KL散度的Logit蒸餾方法計算開銷更高,而WKD-F假設特徵服從高斯分佈。
參考資料:
https://arxiv.org/abs/2412.08139