通義萬相首創生成漢字影片,全面進化稱霸VBench!AI影片GPT-3時刻來臨

編輯:編輯部 HYZ
【新智元導讀】通義萬相影片模型,再度迎來史詩級升級!處理複雜運動、還原真實物理規律等方面令人驚歎,甚至業界首創了漢字影片生成。現在,通義萬相直接以84.70%總分擊敗了一眾頂尖模型,登頂VBench榜首。
Sora、Veo 2接連發佈之後,AI影片生成的戰場又熱鬧了起來。
就在昨天,通義萬相影片生成模型迎來了重磅升級!
他們一口氣推出了兩個版本:注重高效的2.1極速版、追求卓越表現的2.1專業版。
 剛一上線,就異常火爆,等待時間甚至一度達到了1小時
剛一上線,就異常火爆,等待時間甚至一度達到了1小時此次,全面升級的模型不僅在架構上取得創新,更是以84.70%總分登頂權威評測榜單VBench榜首。
通義萬相2.1的性能一舉超越了Gen-3、CausVid等全球頂尖模型。

在實用性方面,通義萬相2.1也得到了顯著的提升,尤其是在處理複雜運動、還原真實物理規律、提升影視質感、優化指令遵循等方面。
以下都是我們實測出的Demos,就說夠不夠拍電影大片吧!



更令人驚歎的是,它還在業界首次實現了中文文字影片生成,讓AI影片文字創作再無門檻。

以紅色新年宣紙為背景,出現一滴水墨,暈染墨汁緩緩暈染開來。文字的筆畫邊緣模糊且自然,隨著暈染的進行,水墨在紙上呈現「福」字,墨色從深到淺過渡,呈現出獨特的東方韻味。背景高級簡潔,雜誌攝影感。
從今天起,所有人皆可在通義萬相官網體驗新模型,開發者則可以通過阿里雲百煉直接調用API,阿里雲也成為了國內第一家實現影片生成模型商業化的雲廠商。
那麼,通義萬相2.1究竟給我們帶來了哪些驚喜?
我們經過一番實測後,總結出了5大要點。
1. 首創中文文字生成
通常來說,文字生成是AI影片模型進化的一大痛點。
我們已經看到Sora、Gen-3等模型,已經能夠生成很好的英文字母效果,不過截至目前,從未有一個模型能攻克漢字的生成難題。

為什麼之前的AI影片生成工具,都在「逃避」中文文字生成這個難題?
這是因為難點在於,中文文字的字體結構比英文更複雜,而且需要考慮筆畫的層次感。在佈局方面,中文字體更講究,做成動態效果時對美感要求更高。
而阿裡通義萬相,便是首個中文文字影片生成的模型。從此,AI影片生成邁入「中文時代」!
這一切,只需要你動動手指,輸入簡單的文字提示就夠了。

天空中飄著雲朵,雲朵呈現「新年快樂」的字樣,微風吹過,雲朵隨著風輕輕飄動。

水彩透疊插畫風格,兩隻不同顏色的可愛小貓咪手舉著一條超大的魚,從右邊走到左邊。它們分別穿著粉色和藍色的小背心,眼睛圓圓的,表情呆萌。充滿童趣,筆觸淡雅溫馨,簡筆畫風格。純白背景上逐漸顯示出來幾個字體,寫著:「摸魚一天 快樂無邊」。
一隻柯基坐在桌前冥想,背後一個「靜」字非常應景。

一隻柯基面前擺放著一隻小巧的木魚,彷彿在進行冥想儀式,背景出現字樣「靜」。
2. 更穩定的複雜運動生成
對於大多數AI影片模型來說,無法逃脫「體操」魔咒。有人稱,這是AI影片最新的「圖靈測試」。
你會經常看到,AI體操影片生成中,扭曲的肢體、不協調的動作滿屏皆是。

這僅是複雜肢體運動的一種,因為涉及到精細細節和高水平動作協調,成為了AI影片生成的一項重要評判標準。
生成一個人物複雜運動,對於AI來說就像是在解一道物理難題——
它不僅要做到身體各個部位精準配合,讓四肢保持協調,還要考慮重力、人體運動特點、平衡感等各種細節。
在最新升級中,通義萬相在多種場景下展示了驚人的「運動天賦」。
滑冰、游泳、插水這些極易出錯的名場面,萬相2.1也通通Hold住,沒有出現任何詭異的肢體動作,和不符合物理規律的場景。

平拍一位女性花樣滑冰運動員在冰場上進行表演的全景。她穿著紫色的滑冰服,腳踩白色的滑冰鞋,正在進行一個旋轉動作。她的手臂張開,身體向後傾斜,展現了她的技巧和優雅。

在泳池中,一名男子正在奮力向前遊動。近景俯拍鏡頭下,他穿著黑色泳衣,戴著白色泳帽和黑色泳鏡,正在水中劃動雙臂。他的頭部部分被泳帽和泳鏡遮擋,只露出嘴巴和鼻子。他的手臂在水中劃動,產生了一系列的浪花和氣泡。隨著他的動作,水面上出現了漣漪,浪花四濺。背景是藍色的泳池。
就看這個插水動作,完全就是一個專業級選手的樣子。肌肉的精準控制、濺起的浪花,都非常符合自然規律。

一名男子在跳台上做專業插水動作。全景平拍鏡頭中,他穿著紅色泳褲,身體呈倒立狀態,雙臂伸展,雙腿併攏。鏡頭下移,他跳入水中,濺起浪花。背景中是藍色的泳池。
特寫鏡頭下,女孩以手指輕觸紅唇,然後開懷大笑。這麼近的懟臉特寫,表情肌的走向和分佈都十分自然,臉部紋路和嘴角笑起的弧線,也逼真似真人。

特寫鏡頭下,一位美女面容精緻,她先是以手指輕觸紅唇,微微抿嘴,眼神中透露出一絲俏皮。緊接著,她毫無保留地開懷大笑,笑容如同綻放的花朵,美麗動人,眼角彎成了月牙狀,展現出無比的快樂與感染力。
3. 更靈活的運鏡控制
同一個場景下的影片,為什麼專業人士拍出來就是不一樣?某種程度上講,秘訣在於「運鏡」。
那麼,對於AI來說,教它運鏡就相當於在教機器人當導演。
它需要理解跟隨拍攝節奏、快慢推進速度,還要保持協調性的問題,比如鏡頭移動時,主體不能丟失;運鏡速度變化要自然,不能忽快忽慢。
更重要的是,AI還得有藝術感,運鏡效果要符合視覺習慣,動態美感要恰到好處。
在通義萬相2.1版本中,AI展現出了專業級的運鏡效果。
穿著禪衣的小狐狸,在360度運鏡下歡快跳舞,這不,夢幻般的效果一下子就來了。

穿著禪意風服飾的可愛狐狸在林間空地上歡快地跳舞,身上的衣物隨風輕揚。狐狸有著蓬鬆的尾巴和靈動的眼神,嘴角帶著微笑,彷彿在享受自然的每一刻。背景是茂密的竹林,陽光透過竹葉灑下斑駁光影。畫面採用旋轉拍攝,營造出夢幻般的動感效果。整體風格清新自然,充滿東方韻味。近景動態特寫。
此外,新模型還能自動根據場景需求,智能調整運鏡速度,完美把控了鏡頭的節奏。
水行俠在暴風雨中駕馭巨浪前行,這種級別的運鏡絕對經得起考驗,出現在大螢幕上也毫不違和。

暴風雨中的海面,水行俠駕馭巨浪前行,肌肉線條,灰暗天空,戲劇性照明,動態鏡頭,粗獷,高清,動漫風格
實驗室中女醫生精心設計的特寫鏡頭,細膩的表情刻畫,以及背後燈光、實驗器材等多種元素碰撞,讓整個角色立即具備了豐富的層次感。

富有電影感的鏡頭捕捉了一位身著暗黃色生化防護服的女醫生,實驗室慘白的螢光燈將她的身影籠罩其中。鏡頭緩緩推進她的面部特寫,細膩的橫向推移凸顯出她眉宇間深深刻畫的憂思與焦慮。她專注地俯身於實驗台前,目不轉睛地透過顯微鏡觀察,手套包裹的雙手正謹慎地微調著焦距。整個場景籠罩在壓抑的色調之中,防護服呈現出令人不安的黃色,與實驗室冰冷的不鏽鋼器械相互映襯,無聲地訴說著事態的嚴峻和未知的威脅。景深精確控制下,鏡頭對準她眼中流露的恐懼,完美傳達出她肩負的重大壓力與責任。
下面這個鏡頭中,穿過一條兩盤種滿樹木的郊區住宅街道,給人一種實時拍攝的感覺。

A fast-tracking shot down an suburban residential street lined with trees. Daytime with a clear blue sky. Saturated colors, high contrast
4. 真實的物理規律模擬
AI影片模型不理解物理世界,一直以來飽受詬病。
比如,Sora不僅會生成8條腿的螞蟻,而且眼瞧著手都要被切斷了,也切不開西紅柿, 而通義萬相2.1切西紅柿就像發生在現實生活中一樣自然真實。

這一次,通義萬相在物理規律理解上,得到顯著提升。通過對現實世界動態和細節深入認知,就能模擬出真實感十足的影片,避免「一眼假」情況的出現。
就看這個經典切牛排的影片,刀刃沿著肉質紋理緩緩切入,表面上一層薄薄的油脂,在陽光下散發著誘人的光澤,每一處細節都盡顯質感與鮮美。

在餐廳里,一個人正在切一塊熱氣騰騰的牛排。在特寫俯拍下,這個人右手拿著一把鋒利的刀,將刀放在牛排上,然後沿著牛排中心切開。這個人手上塗著白色指甲油,背景是虛化的,有一個白色的盤子,裡面放著黃色的食物,還有一張棕色的桌子。
它具備更強大的概念組合能力,能夠準確理解和整合元素級的概念,使其在生成內容時更加智能。
比如,柯基+拳擊,會碰撞出什麼呢?
AI生成的柯基打鬥的畫面,真給人一種人類拳擊的現場感。

兩隻柯基狗在擂台中央進行拳擊比賽。左邊的狗戴著黑色拳套,右邊的狗戴著紅色拳套。平拍鏡頭下,兩隻狗都穿著拳擊短褲,身體肌肉線條明顯。它們互相揮動拳頭,進行攻防轉換。整個場景在固定視角下拍攝,沒有明顯的運鏡變化。
AI大牛Karpathy最愛考驗AI影片的難題,就是「水獺在飛機上用wifi」。這道題,萬相2.1完美做出。

5. 高級質感、多種風格、多長寬比
更值得一提的是,萬相2.1能夠生成「電影級」畫質的影片。
同時,它還能支持各類藝術風格,比如卡通、電影色、3D風格、油畫、古典等等。
不論是哥特式電影風格,還是中國古典宮廷風格,AI將其特點呈現得淋漓盡致。

哥特式電影風格,亞當斯騎在一匹黑色駿馬上,馬蹄輕踏在古老的石板路上。她身穿黑色長裙,頭戴寬邊帽,眼神冷峻,嘴角微揚,透出一絲神秘。背景是陰暗的古堡和茂密的森林,天空中飄著烏雲。鏡頭晃動,營造出一種不安與緊張的氛圍。近景動態騎馬場景。
這個中國古典宮廷風格的畫面,鏡頭由群臣向前推進,聚焦在身披龍袍的占士身上,好像正在上映的一部古裝劇。

中國古典宮廷風格,古代皇宮宮殿上正在進行占士的登基大典。群臣身著華麗朝服,表情肅穆,排列整齊。鏡頭從群臣視角出發快速向前推進,鎖定在身穿龍袍、頭戴皇冠的占士身影上。占士面容威嚴,眼神堅定,緩緩步入大殿。背景是金碧輝煌的大殿,雕樑畫棟,氣勢恢宏。畫面帶有濃厚的皇家氛圍,近景特寫與中景結合,快速推進和跟隨拍攝。
養蜂人手中的蜂蜜罐在陽光中折射出溫暖的光暈,背後的向日葵與鄉村老宅相映成趣,構築出一幅充滿歲月與質感的畫面。

The camera floats gently through rows of pastel-painted wooden beehives, buzzing honeybees gliding in and out of frame. The motion settles on the refined farmer standing at the center, his pristine white beekeeping suit gleaming in the golden afternoon light. He lifts a jar of honey, tilting it slightly to catch the light. Behind him, tall sunflowers sway rhythmically in the breeze, their petals glowing in the warm sunlight. The camera tilts upward to reveal a retro farmhouse.
大文豪李白的「舉頭望明月,低頭思故鄉」,AI直接把氛圍感拉滿。

古風畫面,一位古人抬頭望著月亮,緩緩低頭,眼神中流露出深深的思鄉之情。
對於詞窮的創意者來說,通義萬相「智能體擴寫」功能非常友好。比如, 我想生成一個「超快放大蒲公英,展現宏觀夢幻般的抽像世界」。
若想要細節更豐富的描述,直接交給AI就好了。它會自動生成一段文案,可以直接複用,也可以二次編輯修改。

且看,AI影片中展現了蒲公英種子的驚人細節,鏡頭慢慢放大至每根絨毛纖毫畢現,彷彿進入了一個夢幻般的世界。

此外,萬相2.1還能支持5種不同的長寬比——1:1, 3:4, 4:3, 16:9, 9:16,恰好可以匹配電視、電腦、手機等不同終端設備。

核心架構創新
那麼,到底是什麼讓通義萬相,能在激烈AI影片生成競爭中脫穎而出?
它又藏著哪些讓人眼前一亮的「黑科技」?
接下來,讓我們逐一分解此次2.1版本的技術創新突破點。
自研VAE與DiT雙重突破
通過採用自研的高效VAE和DiT架構,阿里團隊在時空上下文關係建模方面取得重大突破。
模型基於線性噪聲軌跡的Flow Matching方案展開了深度設計,同時驗證了Scaling Law在影片生成任務中的有效性。
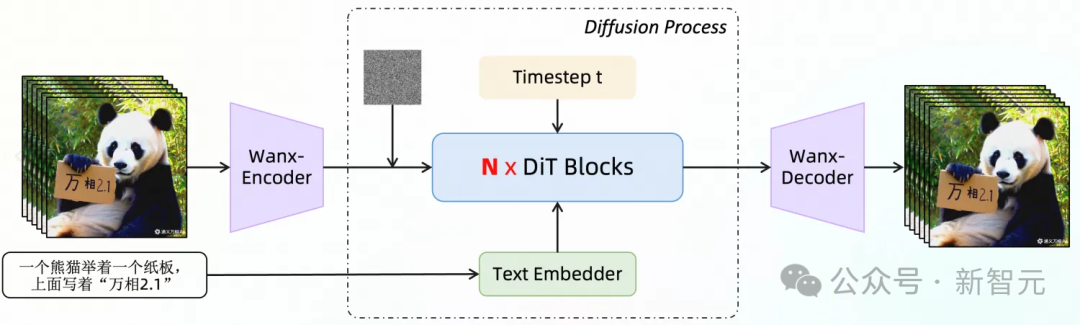 通義萬相2.1影片生成架構圖
通義萬相2.1影片生成架構圖在影片VAE層面,通過結合緩存機制和因果卷積,團隊提出了一個極具創新性的影片編碼解決方案。
通過將影片拆分為多個若干塊(Chunk)並緩存中間特徵,替代長影片的E2E編端到端解碼過程。顯存的使用僅與Chunk大小相關,與原始影片長度無關。
由此,這一關鍵技術能夠支持無限長1080P影片的高效編解碼,為任意時長影片訓練開闢新途徑。
如下圖所示,展示了不同VAE模型的計算效率和影片壓縮重構指標的結果。
值得一提的是,通義萬相VAE在較小的模型參數規模下,取得了業內領先的影片壓縮重構質量。
 通義萬相2.1影片VAE和其他方法的結果對比
通義萬相2.1影片VAE和其他方法的結果對比DiT架構的設計圍繞兩個核心目標展開:實現強大的時空建模能力,同時保持高效的訓練過程。
具體創新包括:
· 時空全注意機制
為了提高時空關係建模能力,通義萬相團隊採用了「時空全注意機制」,讓模型能夠更準確地模擬現實世界的複雜動態。
· 參數共享機制
團隊引入了「參數共享機制」,不僅提升了模型性能,還有效降低了訓練成本。
· 優化文本嵌入
針對文本嵌入進行了性能優化,在提供更優的文本可控性的同時,還降低了計算需求。
得益於這些創新,使得新模型在相同計算成本下,凸顯出收斂的優越性,並更易實現Scaling Law的驗證。
超長序列訓練和推理
通過結合全新通義萬相模型 Workload 的特點和訓練集群的硬件性能,團隊製定了訓練的分佈式、顯存優化的策略。
這一策略在保證模型迭代時間前提下,優化訓練性能,在業界率先實現了100萬Tokens的高效訓練。
在分佈式訓練策略上,團隊開發了創新的4D並行策略,結合了DP、FSDP、RingAttention、Ulysses混合併行,顯著提升了訓練性能和分佈式擴展性。
 通義萬相4D並行分佈式訓練策略
通義萬相4D並行分佈式訓練策略在顯存優化上,採用了分層顯存優化策略優化Activation顯存,解決了顯存碎片問題。
在計算優化上,使用FlashAttention3進行時空全注意力計算,並結合訓練集群在不同尺寸上的計算性能,選擇合適的CP策略進行切分。
同時,針對一些關鍵模塊,去除計算冗餘,使用高效Kernel實現,降低訪存開銷,提升了計算效率。
在文件系統優化上,結合了阿里雲訓練集群的高性能文件系統,採用分片Save/Load方式,提升了讀寫性能。
在模型訓練過程中,通過錯峰內存使用方案,能夠解決多種OOM問題,比如由Dataloader Prefetch 、CPU Offloading 和 Save Checkpoint所引起的問題。
在訓練穩定性方面,借助於阿里雲訓練集群的智能化調度、慢機檢測,以及自愈能力,能在訓練過程中實現自動識別故障節點並快速重啟任務。
規模化數據構建管線與模型自動化評估機制
規模化的高質量數據是大型模型訓練的基礎,而有效的模型評估,則指引著大模型訓練的方向。
為此,團隊建立了一套完整的自動化數據構建系統。
該管線在視覺質量、運動質量等方面與人類偏好分佈高度一致,能夠自動構建高質量的影片數據,同時還具備多樣化、分佈均衡等特點。
針對模型評估,團隊還開發了覆蓋多維的自動化評估系統,涵蓋美學評分、運動分析和指令遵循等20多個維度。
與此同時,訓練出專業的打分器,以對齊人類偏好,通過評估反饋加速模型的迭代優化。
AI影片生成下一個裡程碑
去年12月,OpenAI和Google相繼放出Sora、Veo 2模型,讓影片生成領域的熱度再一次升溫。
從創業新秀到科技巨頭,都希望在這場技術革新中尋找自己的位置。
但是相較於文本的生成,製作出令人信服的AI影片,確實是一個更具挑戰性的命題。
Sora正式上線那天,奧特曼曾表示,「它就像影片領域的GPT-1,現在還處於初期階段」。

若要從GPT-1通往GPT-3時刻,還需要在角色一致性、物理規律理解、文本指令精準控制等方面取得技術突破。
當AI真正打破現實創作的局限,賦予創意工作者前所未有的想像,新一輪的行業變革必將隨之而來。
此次,通義萬相2.1取得重大突破,讓我們有理由相信,AI影片的GPT-3時刻正加速到來。
參考資料:
https://tongyi.aliyun.com/wanxiang/videoCreation