AI預測論文能不能中,8B超越70B大模型,港大發佈圖文融合多智能體GraphAgent
GraphAgent團隊 投稿
量子位 | 公眾號 QbitAI
論文能不能中?可以用AI提前預測~
港大黃超教授團隊提出多智能體自動化框架GraphAgent,能自動構建和解析知識圖譜中的複雜語義網絡,應對各類預測和生成任務。

GraphAgent通過圖生成、任務規劃和任務執行三大核心智能體的協同運作,融合大語言模型與圖語言模型的優勢,成功連接了結構化圖數據與非結構化文本數據,在文本總結與關係建模方面實現了明顯提升。
實驗中,在預測性任務(如節點分類)和生成性任務(如文本生成)上,GraphAgent均取得突出成果,僅以8B參數規模便達到了與GPT-4、Gemini等大規模封閉源模型相當的性能水平。
特別在零樣本學習和跨域泛化等場景中,GraphAgent展現出顯著優勢。
有意思的是,團隊將GraphAgent應用到了學術論文評審場景。
在實際投稿流程中,作者往往需要根據評審意見準備Rebuttal回應,而GraphAgent僅基於論文評審意見(Reviews)就能幫助作者更好地評估論文的錄取可能。
GraphAgent長什麼樣?
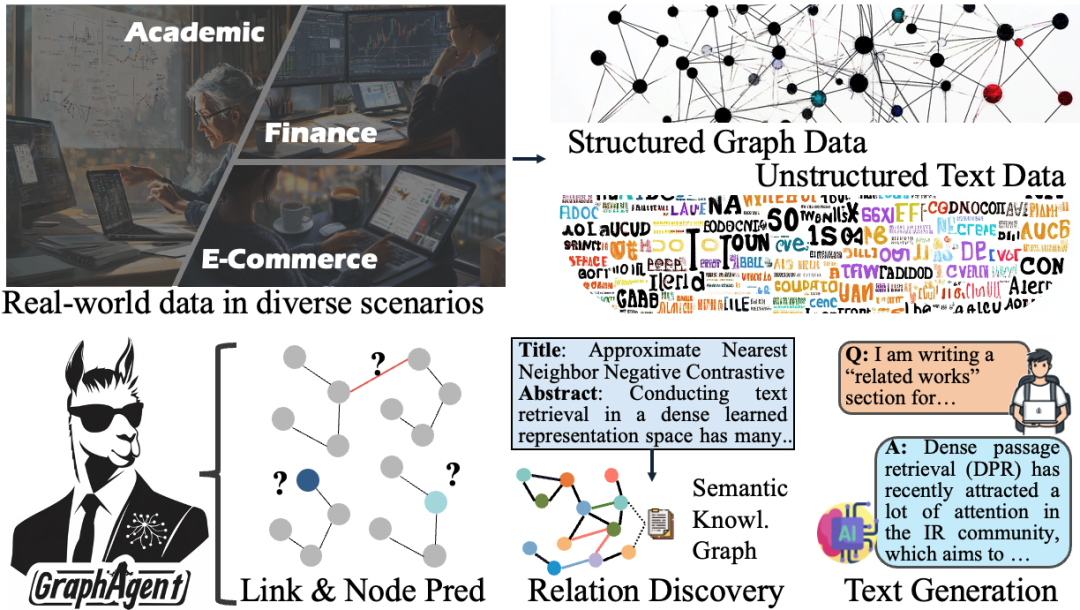
現實世界的數據呈現雙重特性:一方面是結構化的圖連接數據,另一方面是非結構化的文本與視覺信息。
這些數據中蘊含的關係網絡也分為兩類:顯式的連接關係(如社交網絡互動),以及隱式的語義依賴(常見於知識圖譜)。
這種複雜性帶來了三大核心挑戰:
-
異構數據融合:系統需要整合多種形式的信息。以學術網絡為例,論文間的引用構成了圖結構關係,而標題、摘要等文本則承載著豐富的語義信息。有效整合這些異構信息可支持知識總結、科學問答等應用。
-
多層次關係理解:實際場景中往往存在多維度的關聯。例如電商平台中,用戶-商品交互構成行為圖譜,產品評論則形成語義網絡。深入理解這些多層關係有助於提升用戶-商品交互預測的準確性。
-
任務多元化:應用場景要求系統具備廣泛的處理能力。預測類任務包括節點分類、鏈接推斷等圖分析;生成類任務涉及圖增強文本生成、知識圖譜問答等。這需要系統能夠靈活適應不同任務特點,並充分利用數據中的結構化與語義信息。
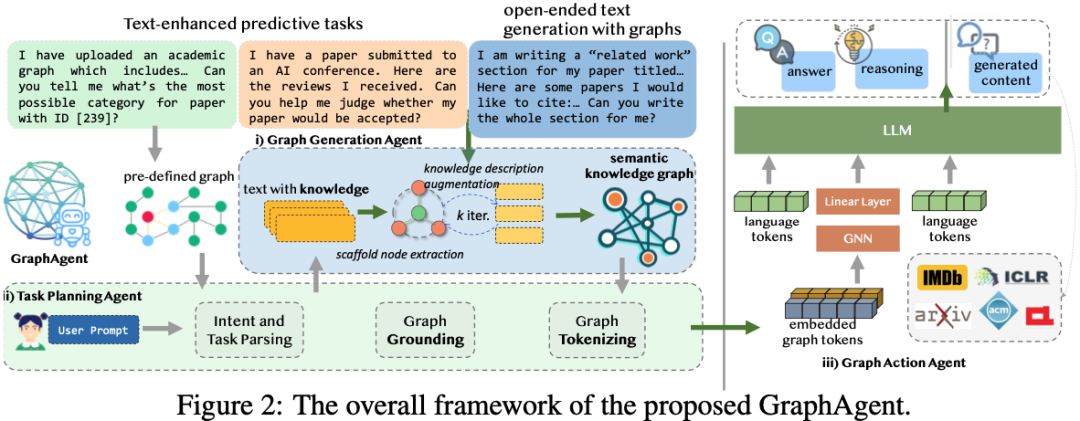
為應對上述挑戰,研究團隊提出多智能體自動化框架GraphAgent。
該框架通過三大核心智能體的協同配合,實現了圖結構與語義信息的深度融合,可同時支持預測型(圖分析、節點分類)和生成型(文本創作)等多樣化任務。
其核心架構包括:
-
圖生成智能體(Graph Generator Agent)
-
任務規劃智能體(Task Planning Agent)
-
任務執行智能體(Task Execution Agent)
三大智能體通過協同機制緊密配合,融合大語言模型與圖語言模型的優勢,有效挖掘數據中的關係網絡與語義依賴。
下面詳細介紹各個智能體的核心功能:
圖生成智能體
圖生成智能體負責構建語義知識圖譜(Semantic Knowledge Graph, SKG),通過創新的雙階段迭代機制實現深層語義信息的提取與整合。
該智能體的工作流程分為兩個核心階段:
1)知識節點提取階段
該階段採用自適應的分層策略,從非結構化文本中識別多維度的知識實體:
-
通過定製化的系統提示,調用大語言模型(LLM)處理輸入文本
-
運用迭代式識別技術,同時捕獲宏觀領域概念(如」Machine Learning」)和微觀技術細節(如」Self-Supervised Learning」)
-
基於多輪迭代構建層次化知識結構,確保知識體系的完整性與連貫性
2)知識描述增強階段
這一階段著重提升知識表示的豐富度與準確性:
-
為每個識別的節點生成詳實的語義描述
-
整合相關上下文信息,構建完整的知識聯繫
-
採用動態迭代更新機制:i) 將每輪描述作為下輪優化的基礎;ii) 持續深化和拓展知識內容;iii) 通過多輪迭代融合,最終形成語義完備的知識圖譜
任務規劃智能體
任務規劃智能體作為框架的決策核心,通過精密的三階段處理機制完成複雜任務的規劃與分解。
其工作流程包括:
1)意圖識別與任務製定
該階段專注於準確理解用戶需求並確定處理策略:
-
深度解析用戶查詢,提取核心意圖
-
將任務分類為三大類型:預定義圖預測(Predictive_predefined),處理已知結構的圖分析;開放圖預測(Predictive_wild),應對未知結構的圖推理;自由生成任務(Open_generation),執行靈活的創作需求。
2)圖結構標準化處理
此階段實現不同類型圖數據的統一表達:
-
運用專業圖構建工具(GBW_Tool)進行結構轉換
-
同步處理顯式關係圖(G_exp)與語義知識圖(G_skg)
-
建立標準化的異構圖表示體系,確保處理一致性
3)圖文特徵融合
這一階段著重實現信息的深度整合:
-
結合預訓練文本編碼器與圖神經網絡,構建雙層編碼體系
-
生成文本語義與圖結構的聯合表示
-
為下遊任務提供豐富的特徵支持,奠定執行基礎
圖動作智能體
圖動作智能體是框架的核心執行單元,通過創新的三維處理架構,實現了任務的精準執行與性能優化。
其工作機制包括:
1)智能化任務處理機制
針對不同類型任務採用差異化處理策略:
-
預測類任務:設計專屬系統提示,引導模型進行精準預測
-
生成類任務:融合語義知識圖譜,提升文本生成的質量與相關性
-
自適應優化:根據任務特點動態調整處理流程,確保執行效率
2)深度圖指令對齊技術
創新性地實現了多層次的模態對齊:
-
同類型圖結構對齊:增強模型對特定圖模式的理解能力
-
跨類型知識融合:提升處理異構圖關係的準確性
-
雙向增強機制:顯著提升模型在多樣化場景下的泛化表現
3)漸進式學習策略
採用先進的課程學習方法:
-
基於難度梯度的任務編排:從基礎到進階的平滑過渡
-
精細化的訓練序列設計:確保知識積累的連續性
-
全方位性能調優:在各類任務中保持穩定的高水平表現
實驗
數據集設置
實驗評估採用了六個各具特色的基準數據集,涵蓋了不同場景和任務類型。
如Table 1所示,這些精心選擇的數據集在規模、結構和應用領域等方面展現出顯著差異,為全面驗證框架性能提供了理想的測試基礎。
為全面評估GraphAgent的通用性能,本研究精選了六個具有代表性的基準數據集開展系統實驗。這些數據集按照任務特徵可劃分為三大類:
結構化圖數據集: 採用了兩個經典的節點分類數據集IMDB和ACM。其中IMDB數據集包含11,616個節點,ACM數據集涵蓋10,942個節點,這兩個數據集都具有清晰的圖結構特徵,為評估模型在結構化數據處理方面的能力提供了可靠基準。
文本處理數據集: 選擇了Arxiv-Papers和ICLR-Peer Reviews兩個具有代表性的數據集。Arxiv-Papers構建了包含153,555個SKG節點的語義知識圖,用於評估文檔分類性能;ICLR-Peer Reviews則包含161,592個SKG節點,專門用於論文錄用預測任務,這些數據集體現了模型處理複雜文本及語義關係的能力。
智能生成數據集: 引入了Related Work Generation和GovReport總結兩個具有挑戰性的數據集。Related Work Generation基於多篇論文構建,包含875,921個SKG節點,用於驗證模型的相關工作生成能力;GovReport包含15,621個SKG節點,針對長文檔摘要生成任務,這兩個數據集都對模型的生成能力提出了較高要求。
實驗效果分析
結構化數據預測性能分析
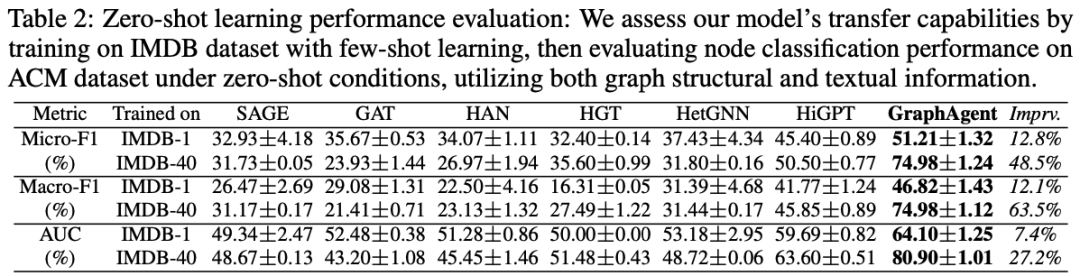
為深入評估GraphAgent在結構化圖任務中的零樣本學習能力,研究團隊設計了一組的對比實驗。
實驗採用IMDB數據集進行模型訓練,分別在1-shot和40-shot兩種低資源場景下驗證模型性能,並在ACM數據集的1,000個未見節點上開展遷移測試,以評估模型的泛化能力。
實驗結果表明:GraphAgent在所有關鍵指標上都顯著優於當前最先進的圖語言模型HiGPT,平均性能提升超過28%。模型在40-shot設置下取得了顯著性能提升:Micro-F1和Macro-F1均達74.98%(提升48.5%/63.5%),AUC達80.90%(提升27.2%)。
GraphAgent的卓越性能主要源於三項核心技術創新:
首先,智能圖生成機制通過自動構建語義知識圖譜(SKG)為模型注入豐富的補充信息,顯著增強了複雜語義關係的理解能力;
其次,精確的任務規劃機制使模型能夠準確理解和分解用戶意圖,並為不同應用場景製定最優執行策略;
最後,創新性的雙重優化策略結合了圖文對齊和任務微調機制,不僅提升了模型的基礎性能,還增強了遷移學習能力,使模型即使在1-shot等低資源場景下仍能保持穩定的高性能表現。
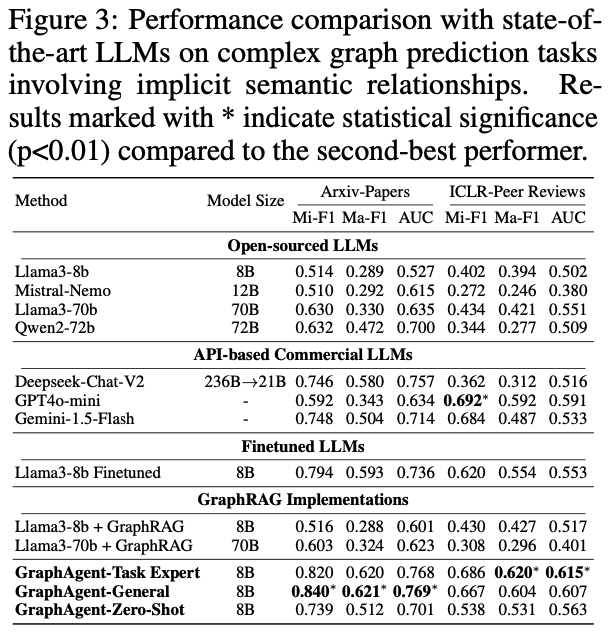
語義理解能力分析
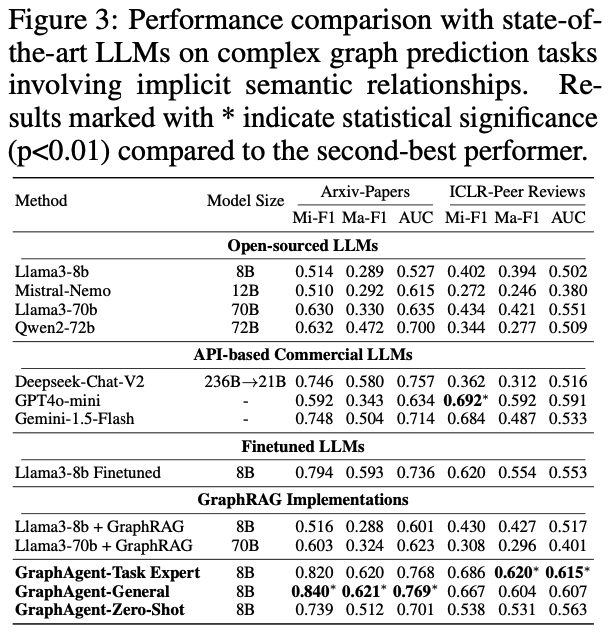
為深入評估GraphAgent在複雜語義關係處理方面的性能,研究團隊基於兩個典型數據集開展了系統實驗:利用Arxiv-Papers數據集進行論文分類驗證,並通過ICLR-Peer Reviews數據集測試論文錄用預測能力。
通過嚴格的實驗評估,GraphAgent在處理隱式語義依賴關係時展現出如下突出優勢:
實驗結果凸顯了GraphAgent的三大核心優勢:
在參數規模優化方面,僅有8B參數的GraphAgent憑藉其獨特的語義知識圖譜架構,成功實現了對複雜語義依賴關係的精準把握,通過多層次語義信息的局部與全局整合,在各項評估指標上顯著超越了Llama3-70b和Qwen2-72b等大規模模型,平均性能提升達31.9%。
在泛化能力表現上,GraphAgent展現出卓越的跨任務學習潛力。其多任務版本GraphAgent-General在Arxiv-Papers數據集的表現甚至優於專門優化的單任務版本。
特別值得注意的是,8B規模的GraphAgent在零樣今場景下也能達到Deepseek-Chat-V2等大型閉源模型的性能水平。
在架構效率方面,GraphAgent通過創新性地整合語義知識圖譜和結構化知識表示,相比傳統的監督微調方法和GraphRAG系統,不僅顯著提升了模型性能,還有效降低了輸入開銷,同時成功緩解了大語言模型常見的幻覺問題。
文本生成任務
GraphAgent在圖增強文本生成任務中展現出卓越表現,通過性能評估、模型對比和架構分析三個維度的系統實驗,充分驗證了其突出優勢。
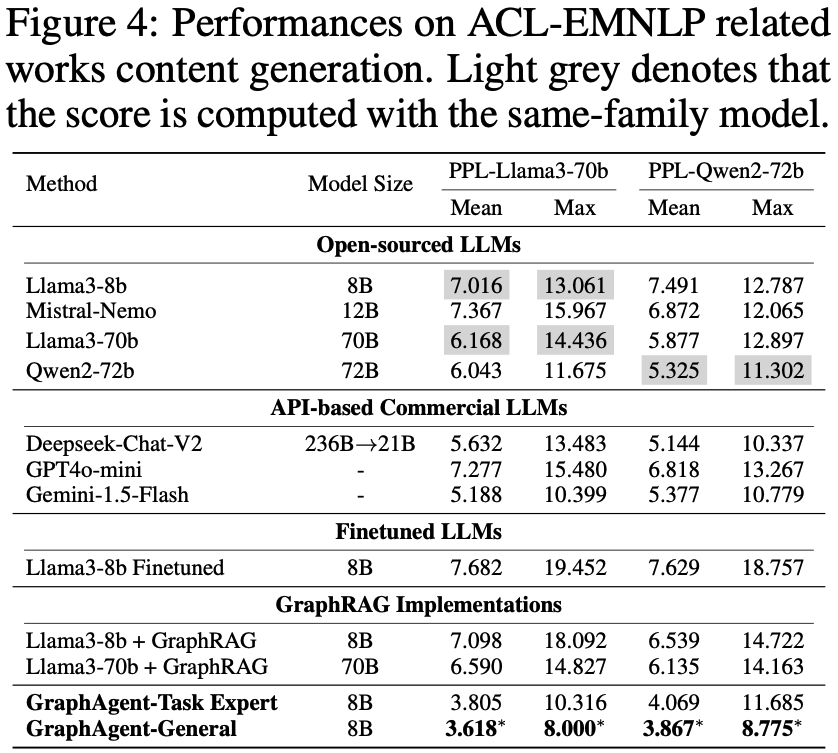
基於Llama3-70b和Qwen2-72b的雙重對比驗證表明,GraphAgent在困惑度(PPL)等核心指標上顯著優於基線模型。不同於傳統的監督微調(SFT)和GraphRAG方法,GraphAgent通過智能構建語義知識圖譜,從根本上提升了模型的推理理解能力,有效解決了常規微調和知識注入方法在處理複雜推理模式時的固有局限。
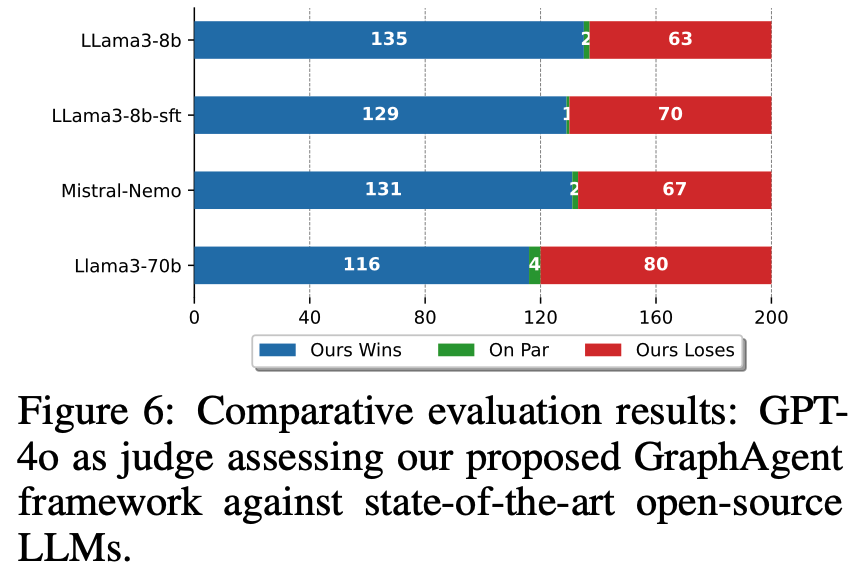
在架構創新和性能對標方面,GraphAgent展現出突出優勢。
以GPT-4為評判基準的實驗顯示,GraphAgent相比Llama3-8b和Llama3-70b分別實現了114%和45%的性能提升,在67%的測試案例中領先同等規模模型,58%的情況下超越主流開源方案。
尤為顯著的是,GraphAgent僅以8B的參數規模和極低的計算開銷便達成這些卓越成果,充分驗證了基於語義知識圖譜的架構設計在增強文本生成能力方面的顯著效果。
消融實驗
通過系統化的消融實驗(Ablation Study),研究團隊深入評估了GraphAgent架構中三個核心組件的性能貢獻,研究結果揭示了以下關鍵發現:
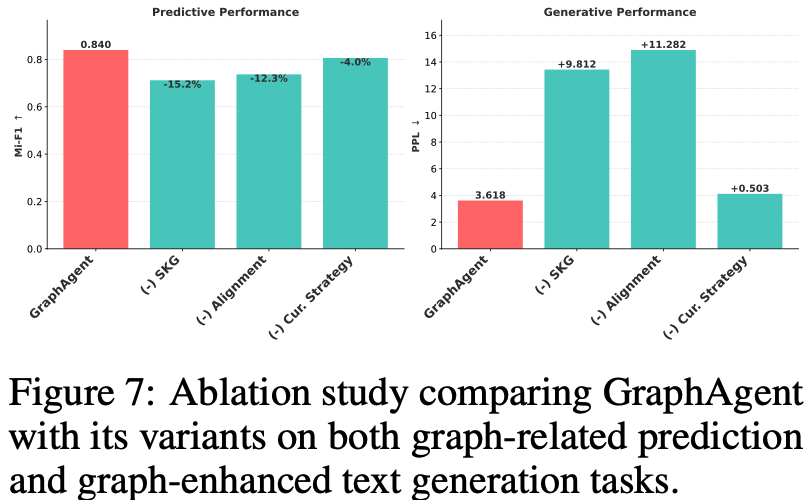
語義知識圖譜(SKG)的基礎支撐作用:移除SKG組件導致模型性能顯著降低15.2%,充分證實了自動構建的語義知識圖譜在提供關鍵補充信息方面的不可替代性。這一發現強調了結構化知識表示對模型整體性能的決定性影響。
圖文對齊機制的重要性:實驗表明,缺失圖文對齊機制造成了最顯著的性能損失,困惑度(PPL)增加達11.282。這突出表明深層次的圖文理解能力對於需要複雜推理的生成任務至關重要,是保障模型高質量輸出的關鍵環節。
課程學習策略的優化效果:雖然相較其他組件影響相對較小(預測任務降低4.0%,生成任務PPL增加0.503),但課程學習策略的缺失仍對雙任務性能產生明顯負面影響。這驗證了漸進式學習路徑在優化模型訓練效果方面的積極作用。
最後研究團隊透露了他們的未來研究方向,包括:
多模態能力拓展:計劃將當前框架的處理能力擴展至視覺信息領域,建立支持關係型數據、文本內容和視覺元素的綜合處理機制。這一拓展不僅包括多模態信息的理解與融合,還將重點開發跨模態知識表示和生成能力,從而實現更豐富的智能交互場景。特別關注視覺-文本-關係的協同建模,為多模態智能系統開闢新的研究方向。
模型性能優化:致力於提升模型在複雜現實場景中的泛化表現,重點研究如何在保持或提升性能的同時實現模型壓縮。這涉及創新的模型架構設計、高效的參數共享機制以及先進的知識蒸餾技術。同時,將探索計算資源優化策略,提高模型在實際部署環境中的效率,為大規模應用奠定基礎。
應用場景擴展:積極探索框架在多個實際領域的落地應用,重點關注科學研究輔助和商業智能分析等高價值場景。在科研領域,將開發專門的文獻分析和知識發現工具;在商業領域,著重構建面向決策支持的智能分析系統。同時,密切關注新興技術趨勢,探索在醫療健康、金融科技等領域的應用場景。
項目地址:https://github.com/HKUDS/GraphAgent
論文鏈接:https://arxiv.org/abs/2412.17029
實驗室主頁: https://sites.google.com/view/chaoh



















