最強代碼模型刷新:Mistral新品上線即登頂,上下文窗口增至256k
基爾西 發自 凹非寺
量子位 | 公眾號 QbitAI
「歐洲版 OpenAI」 Mistral 的代碼模型 CodeStral,又上新了!
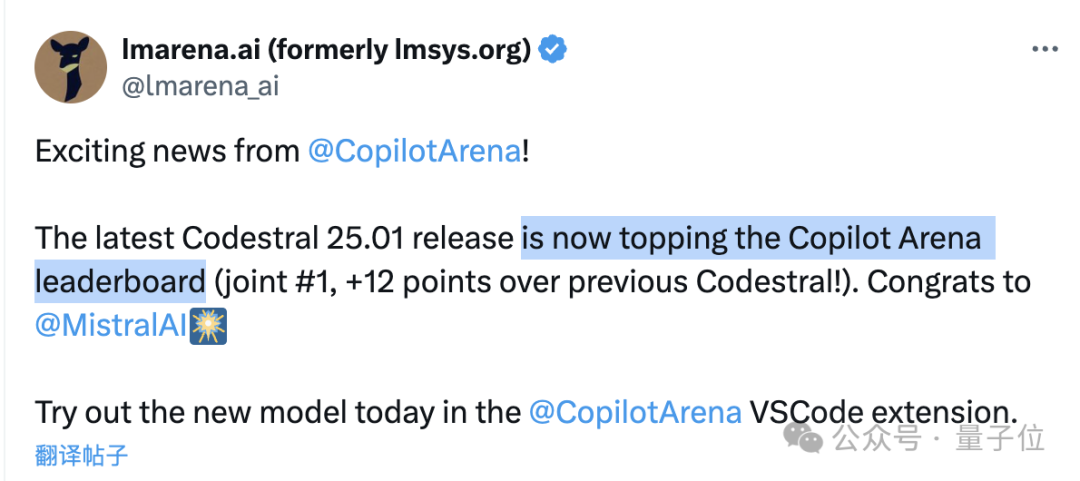
而且與 DeepSeek V2.5 和 Claude 3.5 平起平坐,共同位列 Copilot 競技場第一名。
上下文窗口也增長到了之前的 8 倍,達到了 256k。
據介紹,新版 Codestral(2501)使用了更高效的架構和分詞器,生成速度比前一代大約快了 2 倍。
在多個 Benchmark 當中,2501 版本都取得了 SOTA 的成績,代碼補全(FIM)能力也可圈可點。
Mistral 的合作方 Continue.dev 聯創 Ty Dunn 還表示,Codestral 2501 標誌著FIM領域的重大進步。
登頂代碼模型競技場,多種編程語言均是SOTA
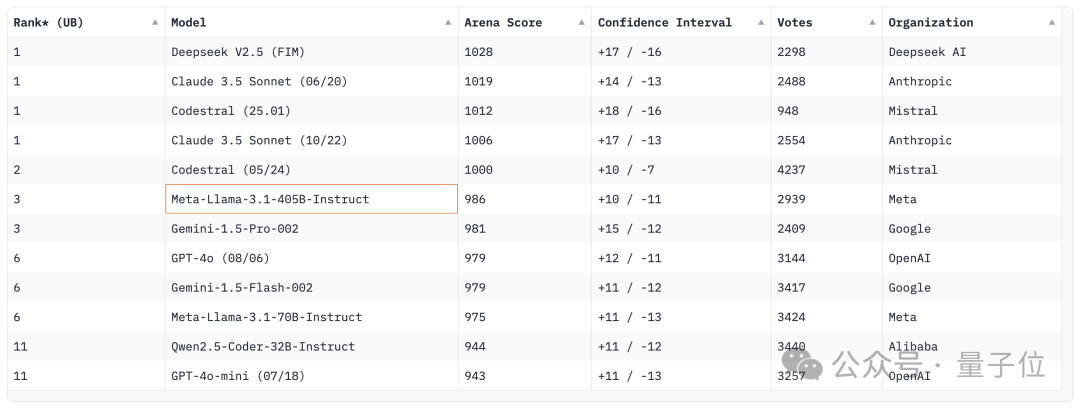
在代碼模型競技場 Copilot Arena 上,CodeStral 2501 取得了第一名,與 Deepseek V2.5 以及 Claude 3.5 Sonnet 並列。
之後是 CodeStral 的上一個版本(2405),新版得分相比這一版提高了 12 分(1.2%)。
Llama 3.1、Gemini 1.5 Pro 和 GPT-4o 的排名則還要再靠後。
不過榜單當中沒有 o1,如果加進來對話可能形勢還會有所改變。
Copilot Arena 由卡內基梅隆大學和 UC 伯克利的研究人員與 LMArena 合作於去年 11 月推出。
它和我們更熟悉的 LLM 競技場很類似,由用戶出題並讓系統隨機選擇兩個模型匿名輸出,然後用戶根據輸出選擇優勝方。
Copilot Arena 可以看做是 LLM 競技場的代碼專用版本,不過同時它也是一款開源編程工具,可以在 VSCode 中同時讓多個模型同時生成,方便用戶「貨比三家」。
目前已經有 12 個代碼模型在 Copliot Arena 中進行過 PK,總共進行了 1.7 萬餘場battle。
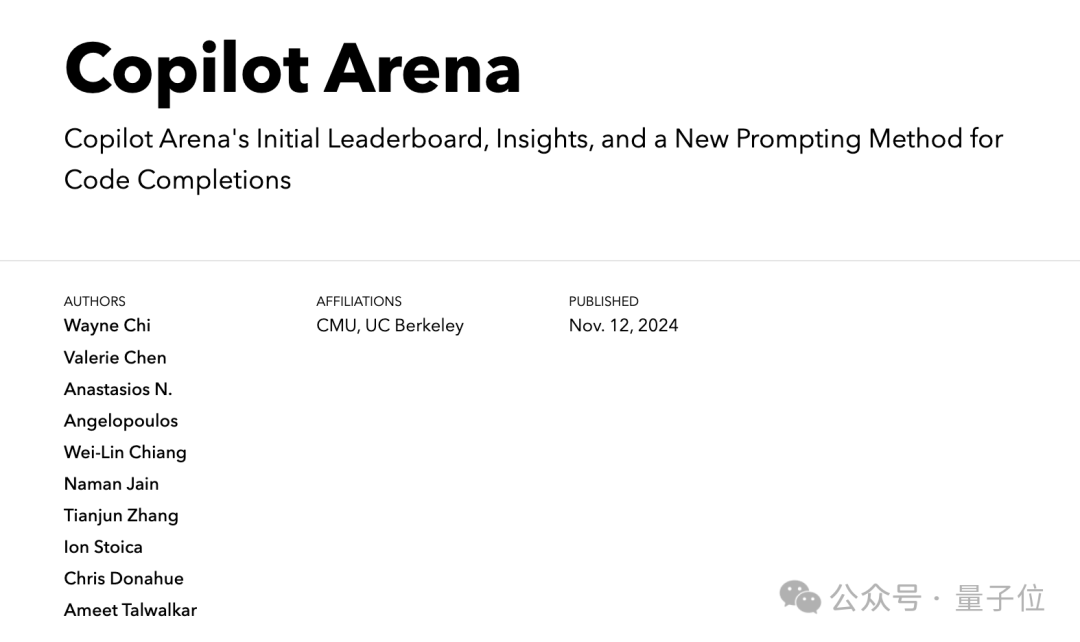
而根據 Mistral 官方曬出的成績單,CodeStral 2501 在 HumanEval 等傳統測試當中的多個指標上,也取得了 SOTA 的成績。
(按照 Mistral 的說法,選擇參與對比的模型是參數量 100B 以下且在 FIM 任務當中普遍被認為表現較好的模型。)
並且窗口長度也從 2405(參數量 22B)的 32k 增長到了 256k。
在 Python 語言和 SQL 數據庫的測試中,CodeStral 2501 在多個測試指標上都位列第一,其餘位列第二。
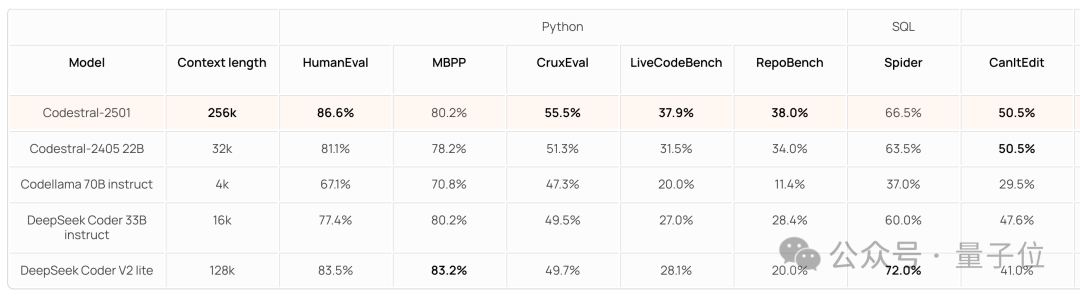
其他語言方面(據宣傳 CodeStral 共支持 80+ 種語言),CodeStral 的 HumanEval 平均分為 71.4%,比第二名高出近 6 個百分點。
具體來看,在 Python、C+、JS 等多種常用語言中也都是 SOTA,並且實現了 C# 語言得分過半。
不過有意思的是,在 Java 上 CodeStral 2501 的成績相比前一代出現了下降。
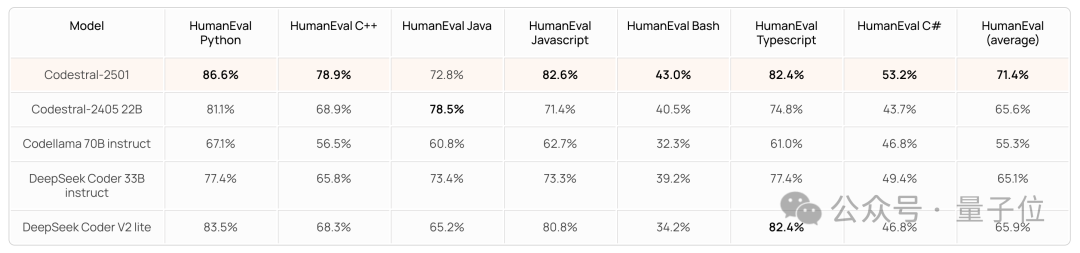
除了生成,Mistral 團隊也發佈了 CodeStral 2501 的 FIM 表現(單行精確匹配)。
結果平均成績以及 Python、Java 和 JS 三個單項相比前一代均進步明顯,且優於 OpenAI FIM API(最新版是3.5 Turbo)等其他模型(不過緊隨其後的 DeepSeek 咬得很緊)。
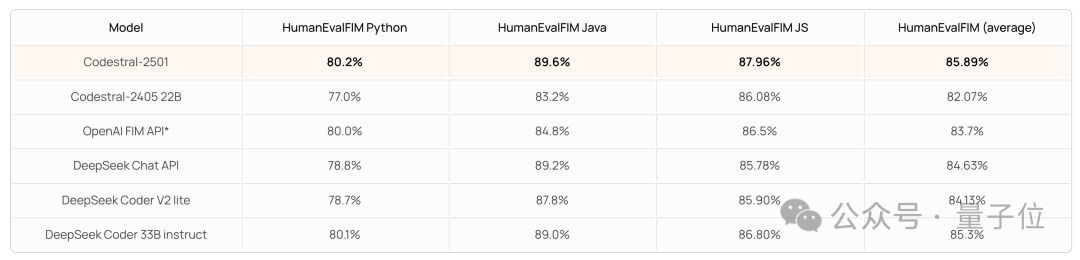
在 FIM 的 pass@1 當中,表現也是類似:

目前,CodeStral 2501 可以通過 Mistral 的合作方 Continue,在 VSCode 或 Jetbrains 系列 IDE 中使用。
當然動手能力強的用戶,也可以通過 API 自己來部署,價格是 0.3/0.9 美元或歐元每百萬輸入/輸出 token。
參考鏈接:
[1]https://x.com/lmarena_ai/status/1878872916596806069
[2]https://mistral.ai/news/codestral-2501/