微軟華人團隊最新研究:從LLM到LAM,讓大模型真正具有「行動力」!

新智元報導
編輯:澤正 英智
【新智元導讀】AI大模型正從僅會聊天的LLM進化為能夠執行任務的大型行動模型LAM。它不僅能理解用戶的指令,還能在軟件環境中自主執行任務。
LLM只能針對問題進行回答與分析?這種「隔靴搔癢」的體驗也許就要被終結了!
最近,微軟推出了一項名為「大型行動模型」(Large Aciton Model,LAM)的創新技術,標誌著大模型從語言理解向實際執行任務的轉變。
與傳統的LLM不同,LAM不僅能理解用戶的自然語言指令,還能將這些指令轉化為具體的行動步驟,在軟件環境中自主執行文檔編輯、表格處理等任務。
雖然這實際上並不是一個全新的概念,但LAM是首款能夠操作Microsoft Office來執行任務的模型。
 論文鏈接:https://arxiv.org/pdf/2412.10047
論文鏈接:https://arxiv.org/pdf/2412.10047不同於GPT-4o等負責處理和生成文本的傳統語言模型,LAM可以將用戶請求轉化為實際操作。
例如同樣是給一個男人買夾克,LLM只能給出文本步驟,而LAM卻可以直接像女朋友一樣挑選款式並網購。
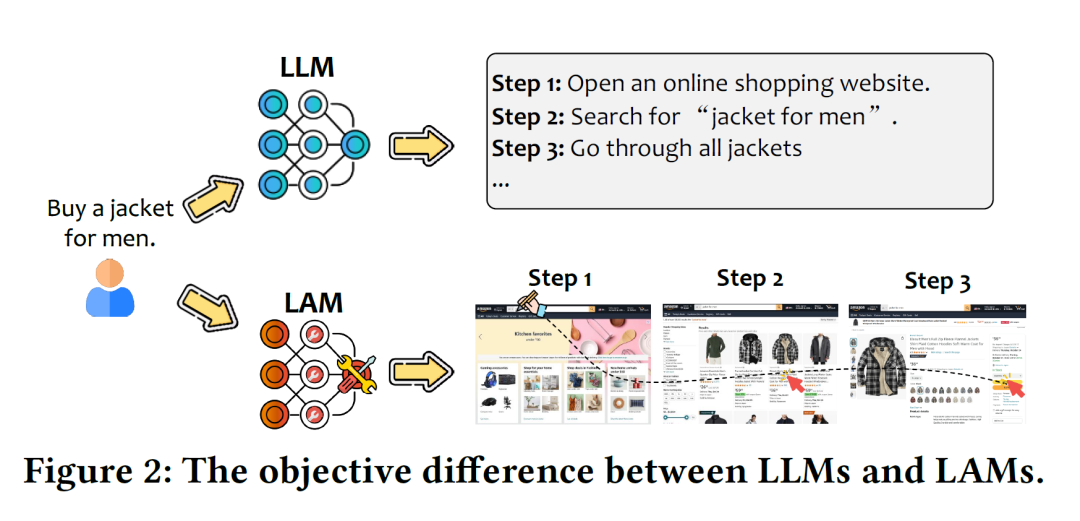
哪個更加有實際效用,這就自不必多說了。畢竟誰不想有個能直接替自己去解決一些生活瑣碎的「分身」呢?
LAM能夠理解用戶通過文本、語音或圖像等各種輸入方式表達的需求,並將這些需求轉化為詳細的逐步計劃。
執行過程中,LAM能將複雜的任務分解為多個子任務,根據實時情況調整其行動策略,以應對執行過程中的意外情況。
此外,LAM還能自主探索與學習,獨立探索新的解決方案。
讓LLM行動起來
LAM通常建立在LLM的基礎上,但是從LLM到LAM的過渡卻並沒那麼容易,如下圖所示。
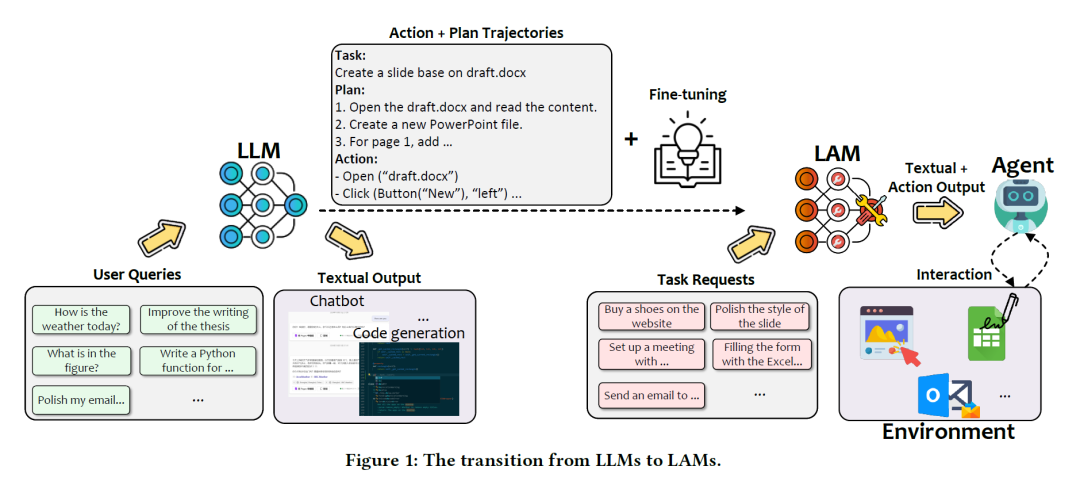 從LLM到LAM的轉變
從LLM到LAM的轉變將LLM轉化為功能性LAM的過程涉及多個複雜的階段,每個階段都需要大量的努力與專業知識。
首先需要利用LLM來處理用戶數據集,並生成對應的文本輸出,將任務分解為行動與相應的計劃。
經過微調之後,接受了任務要求的LAM就能輸出對應的文本格式的行動輸出。
最後將其輸出反饋給智能體,讓其與環境不斷地實時交互。
如何開發LAM?
既然LAM能夠為我們執行任務,化為我們的「分身」來幫我們與世界互動,那麼如何開發與部署LAM就是一個關鍵的問題。
LAM的訓練過程包括以下關鍵步驟:
1. 任務分解與規劃:模型首先學習將任務分解為邏輯步驟,並生成詳細的執行計劃。
2. 行動生成與執行:將用戶意圖轉化為具體的行動指令,包括圖形用戶界面操作、API調用等。
3. 動態調整與優化:在執行過程中,LAM能根據反饋調整其行動策略,以提高成功率和效率。
4. 從獎勵機制學習:通過獎勵機制進行微調訓練,進一步優化模型的性能。
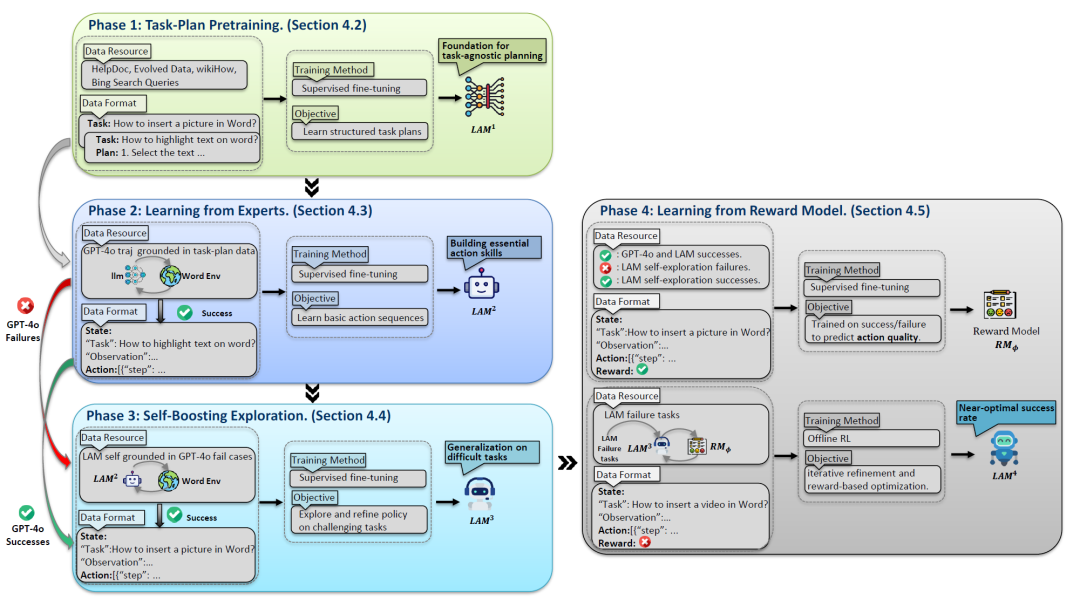
階段1:任務分解與規劃
在初始階段,模型將任務分解為邏輯步驟。
研究人員以Mistral-7B作為基礎模型,收集了來自多個來源的76,672個任務-計劃對(𝑡𝑖 , 𝑃𝑖),包括應用幫助文檔、WikiHow和歷史搜索查詢。
在此階段不會生成具體的行動,但模型獲得了強大的規劃能力,為後續的動作執行提供了重要基礎。
階段2:行動生成與執行
在此階段,作者引入了由GPT-4o標註的任務-動作軌跡,讓LAM向先進的AI模型GPT-4o學習。
將學習到的任務規劃轉化為可執行的動作,從GPT-4o的成功經驗中汲取知識和策略,更好地理解和處理複雜任務。
本文中的示例應用是Microsoft Word,在該環境下共收集了2,192個成功的專家軌跡。每個軌跡由一系列狀態-動作對(𝑠𝑡 , 𝑎𝑡)組成。通過對這些成功的行動序列進行學習,我們獲得了LAM2。
階段3:動態調整與優化
之後,我們讓模型嘗試解決GPT-4o失敗的任務,通過ReAct機制與環境進行交互。
首先從GPT-4o失敗的任務中采樣2,284個任務,並收集了LAM2生成的496個成功軌跡,將這些數據與2,192個GPT-4o成功軌跡相結合,形成了一個增強數據集。
在這一階段,LAM會自主探索新的解決方案,嘗試解決那些曾難倒其他AI系統的問題,拓展自身能力邊界,增強對不同任務和場景的適應性。
階段4:從獎勵機制中學習
儘管模型在前述階段有所改進,但未能充分利用失敗所帶來的學習機會。
因此,論文引入了強化學習來解決這些問題。通過基於獎勵的訓練對系統進行微調,根據模型執行任務的結果給予相應的獎勵或懲罰,引導模型不斷優化行為策略,以達到更好的效果。
可以看到,訓練LAM的過程包括四個步驟:首先,模型學習如何將任務分解為邏輯步驟。其次,通過先進的AI系統(如GPT-4o)學習如何將計劃轉化為具體行動。然後,LAM會獨立探索新的解決方案。最後,通過獎勵機制進行微調訓練。
表中總結了每個階段使用的訓練數據。

LAM數據收集與構建
眾所周知,數據是訓練LLM的基石。類似地,LAM在監督微調階段也需要經過精心準備的以行動為導向的高質量數據。
因此研究者採用了兩階段的數據收集:任務-計劃數據和任務-行動數據,如下圖所示。

任務-計劃數據:在這一階段,研究者收集包含任務和對應計劃的數據。
任務是用自然語言表達的用戶請求,而計劃是為完成這些任務而設計的詳細步驟。例如,「如何在Word中更改字體大小?」會有一個對應的計劃,概述完成該任務所需的步驟。
這些數據用於微調模型,以生成有效的計劃,並提升其高層次的推理和規劃能力。
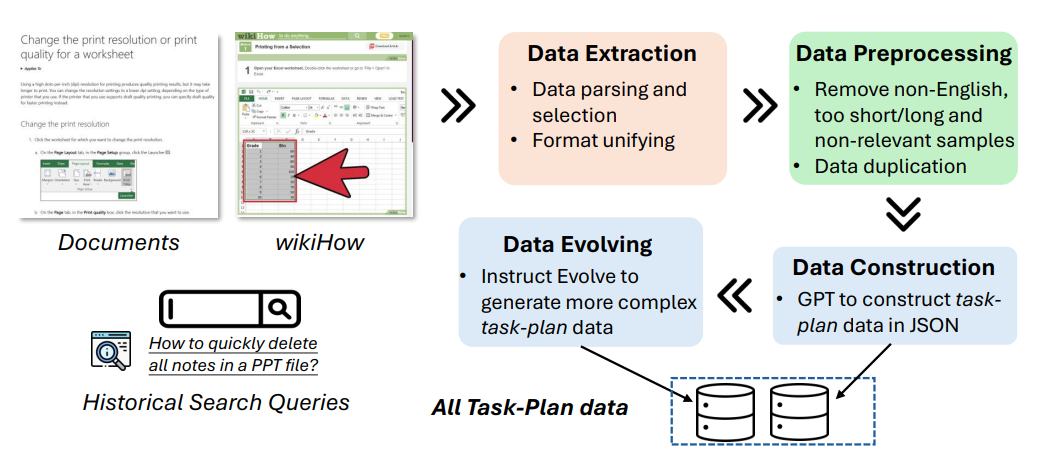 構建任務-計劃數據的流程
構建任務-計劃數據的流程任務-行動數據:在這一階段,任務-計劃數據被轉換為任務-行動數據,包括任務、計劃和執行這些計劃所需的相應動作序列。任務和計劃被細化為更具體且能夠在特定環境中執行的內容。
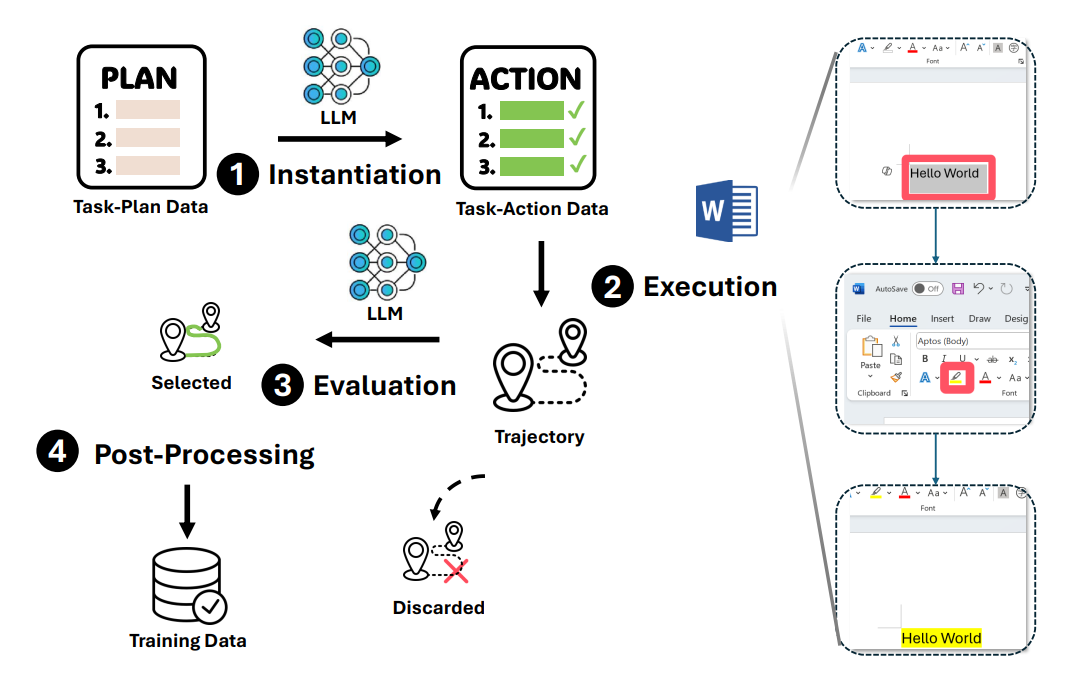 構建任務-行動數據的流程
構建任務-行動數據的流程經過上述圖中的4個處理步驟後,最終生成的動作序列類似於:
select_text(text="hello")或者是
click(on=Button("20"), how="left", double=False)也就是能夠直接與環境交互的可執行指令。
總的來說,任務-計劃數據旨在增強模型的高層次規劃能力,使其能夠根據用戶請求生成詳細的逐步計劃。
而任務-行動數據則側重於通過將每個計劃步驟轉化為具體、可執行的步驟或序列,從而賦予模型執行這些計劃的能力,並能接受環境的實時反饋。
數據收集和準備流程確保模型能夠同時進行高層次規劃和低層次行動執行,從而彌合了LLM生成計劃與能夠採取可執行行動之間的差距。
LAM的在線評估
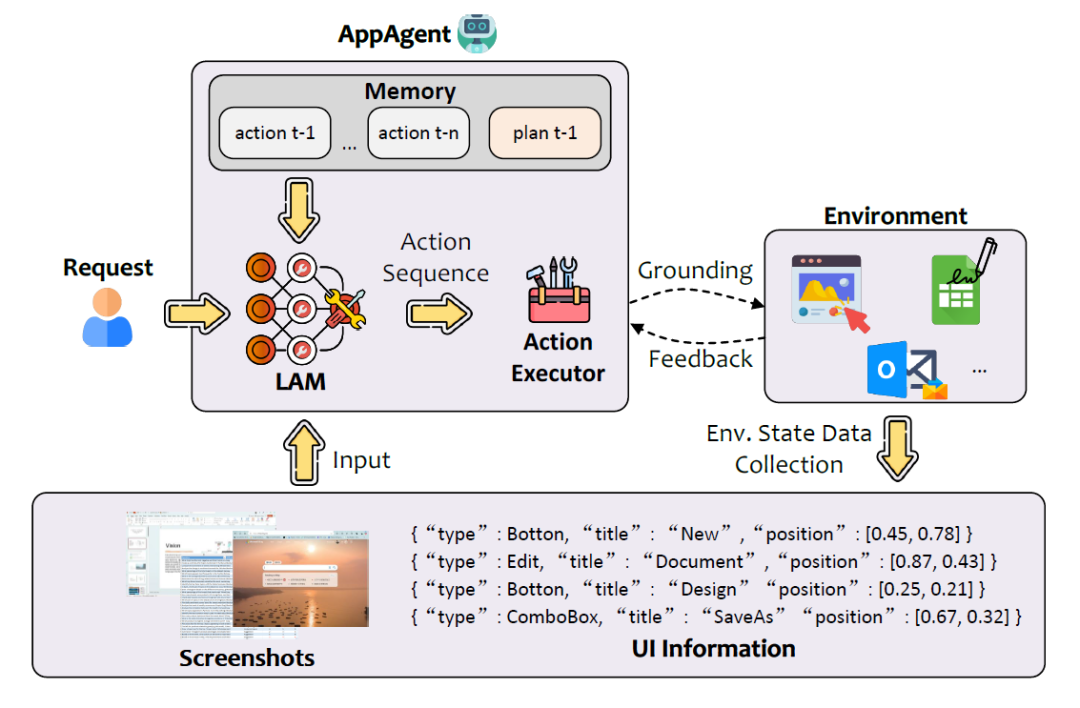
我們將訓練完成的LAM集成到GUI智能體UFO中,使模型預測的行動能夠在Windows操作系統中有效執行,並與環境進行交互。
UFO智能體通過接受自然語言的用戶請求,並與Windows應用程序的UI控件進行互動,完成具體任務。
我們採用以下指標對 LAM 的性能進行全面評估:
1. 任務成功率(Task Success Rate, TSR): 成功完成任務的數量佔嘗試總任務數量的百分比。
2. 任務完成時間: 從初始請求到最終動作完成的總時間。
3. 任務完成步驟: 智能體成功完成每個任務所執行的總動作步驟數量。
4. 平均步驟延遲: 每個動作步驟的平均耗時。
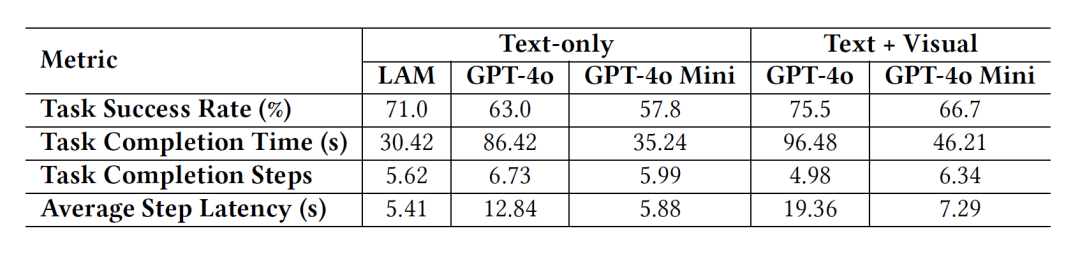
LAM在Word測試環境中的成功率為71%,而GPT-4o在無視覺信息輸入的情況下,成功率為63%。
此外,LAM的執行速度也更快,每個任務僅需30秒,而GPT-4o則需要86秒,是LAM的2.8倍。
實驗結果突顯了LAM作為僅使用文本的模型的優勢,使LAM成為實際應用中有效的解決方案。
未來展望
LAM的推出為辦公自動化、複雜任務處理等領域帶來了新的可能性。例如,在Microsoft Office中,LAM可以自動執行文檔編輯、表格處理等任務,極大地提高工作效率。此外,LAM還有潛力在更多領域發揮重要作用。
LAM展示了其發展潛力,在商業化落地中仍然面臨一些挑戰,例如,控制機器人系統的LAM可能會誤解指令並導致損害;金融或醫療應用中如果執行錯誤動作,可能帶來嚴重的後果。
然而,研究人員相信,LAM代表了AI發展的一次重要轉變,預示著AI助手將能更積極地協助人類完成實際任務。
行動勝於言辭
LAM的推出標誌著人工智能從語言理解向任務執行的轉變,開啟了AI自主的新時代。從生成語言到執行具體動作,大模型將能在現實世界中產生直接影響,這是邁向AGI的關鍵一步。
未來,隨著技術的不斷髮展,LAM將在更多領域發揮重要作用,為我們的生活和工作帶來更多便利和驚喜。
參考資料:
https://the-decoder.com/microsofts-new-large-action-model-can-perform-some-tasks-in-word/
https://arxiv.org/pdf/2412.10047
https://microsoft.github.io/UFO/dataflow/overview/



















