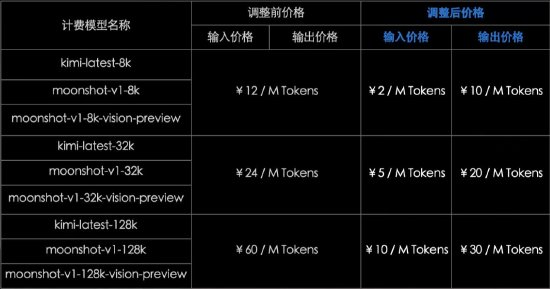
Google提出創新神經記憶架構,突破Transformer長上下文限制
讓 AI 模型擁有人類的記憶能力一直是學界關注的重要課題。傳統的深度學習模型雖然在許多任務上取得了顯著成效,但在處理需要長期記憶的任務時往往力不從心。就像人類可以輕鬆記住數天前看過的文章重點,但目前的 AI 模型在處理長文本時卻經常丟三落四,這種差距一直是困擾研究人員的關鍵問題。
近日,Google研究院的研究團隊在這一領域取得了重要突破,Ali Behrouz、鍾沛林(Peilin Zhong)和 Vahab Mirrokni 在預印本平台 arXiv 發表論文,提出了一種名為 Titans 的創新神經記憶架構,其核心是一個能在測試時動態學習和更新的神經長期記憶模塊。

目前主流的 Transformer 架構在處理文本時面臨著明顯的局限。雖然它能夠準確捕捉短距離的文本關係,但其注意力機制的計算複雜度會隨著序列長度呈二次增長,這使得處理長文本時的計算成本變得難以承受。為解決這一問題,研究者們提出了 RetNet、Mamba 等線性遞歸模型。這些模型雖然將計算複雜度降至線性水平,但由於需要將信息壓縮到固定大小的狀態中,在處理超長序列時常常出現嚴重的信息丟失。
論文作者 Ali Behrouz 在 X 上解釋了 Titans 的設計理念:「我們從人類記憶的視角重新思考這個問題。人類大腦會優先記住那些違反預期的事件,但有趣的是,一個事件雖然可能值得長期記住,它的’驚訝度’卻會隨時間推移而減弱。」基於這一對人類記憶特性的觀察,研究團隊開發出了 Titans 獨特的記憶更新機制。
 圖丨相關推文(來源:X)
圖丨相關推文(來源:X)具體來說,Titans 包含三個核心組件,分別對應人類記憶系統的不同方面。
首先是基於注意力機制的核心短期記憶,負責處理當前上下文窗口內的信息,類似於人類的工作記憶。
其次是 Titans 最具創新性的神經長期記憶模塊,它能在測試時動態學習和更新記憶,通過神經網絡的梯度來衡量信息的重要性。這個模塊將「驚訝度」分為瞬時驚訝度(momentary surprise)和過去驚訝度(past surprise)兩個維度,前者衡量當前輸入與已有記憶的差異程度,後者評估近期歷史信息的重要性。其計算公式如下:
St = ηtSt-1 – θt∇ℓ(Mt-1; xt)
其中,ηtSt-1 代表過去驚訝,它通過一個數據依賴的衰減率 ηt 來控制歷史信息的保留程度。當系統判斷當前上下文與過去相關時,ηt 會接近 1,保持對歷史信息的重視;當需要切換到新的上下文時,ηt 會接近 0,允許系統「忘記」不再相關的歷史信息。
而 -θt∇ℓ(Mt-1; xt) 則代表瞬時驚訝,它通過計算損失函數關於輸入的梯度來量化當前輸入 xt 與已有記憶 Mt-1 之間的差異程度。θt 參數控制了系統對新信息的敏感度。這種設計讓模型能夠像人類一樣,對違反預期的信息保持特別的關注。
在具體實現中,研究團隊使用了一個關聯記憶損失函數:
ℓ(Mt-1; xt) = ||Mt-1(kt) – vt||²₂
其中,輸入 xt 會被轉換為鍵值對:kt = xtWK 和 vt = xtWV。這種設計讓模型能夠學習和存儲信息之間的關聯關係,類似於人類記憶中的聯想機制。
第三個組件是持久記憶,這是一組與數據無關的可學習參數,專門用於存儲完成特定任務所需的基礎知識,類似於人類的程序性記憶。
從效率角度來看,研究團隊還特別優化了 Titans 的訓練過程。Behrouz 在推文中提到:「我們通過 湯臣T(Sun et al., 2024)擴展了 mini-batch 梯度下降的可並行化對偶形式,並通過額外的矩陣乘法來實現權重衰減。」通過將 mini-batch 梯度下降的前向傳播重新表述為矩陣乘法操作,他們實現了高效的並行訓練。
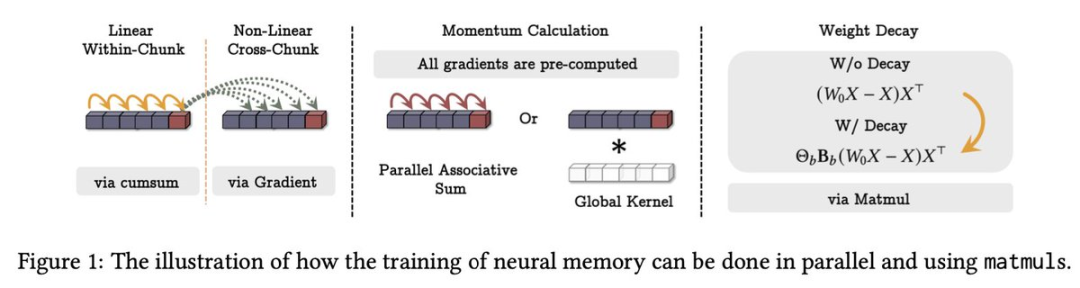 圖丨展示如何並行使用 matmuls 進行神經記憶訓練的示意圖(來源:arXiv)
圖丨展示如何並行使用 matmuls 進行神經記憶訓練的示意圖(來源:arXiv)然後,研究團隊提出了三種將這些組件整合的變體架構:
-
MAC(Memory as Context):這種方案將記憶作為上下文信息處理,對輸入序列進行分段,並使用過去的記憶狀態來提取相應的記憶信息。
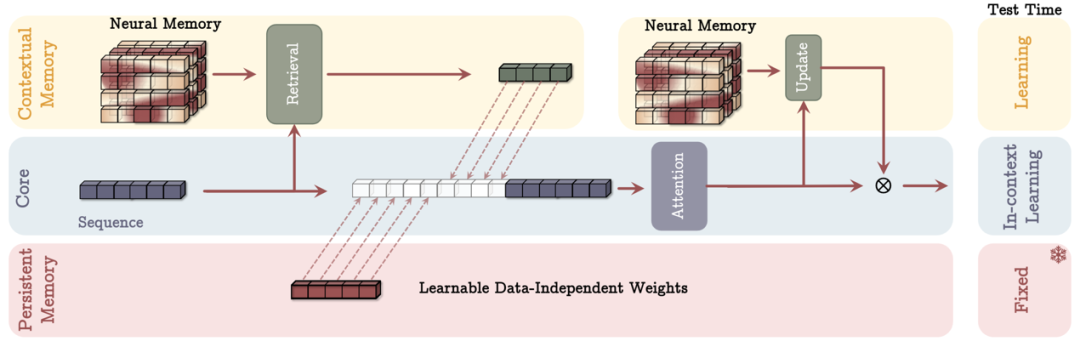 圖丨作為上下文(MAC)架構的內存(來源:arXiv)
圖丨作為上下文(MAC)架構的內存(來源:arXiv)-
MAG(Memory as Gate):這種方案使用滑動窗口注意力機制作為短期記憶,同時使用神經記憶模塊作為長期記憶,通過門控機制將兩者結合。
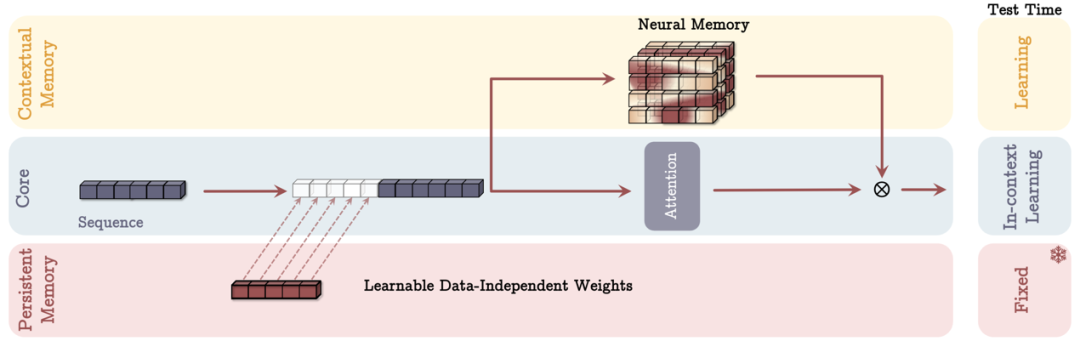 圖丨作為門的內存(MAG)架構(來源:arXiv)
圖丨作為門的內存(MAG)架構(來源:arXiv)-
MAL(Memory as Layer):這種方案將神經記憶作為深度神經網絡的一個層,更接近傳統的混合模型設計。
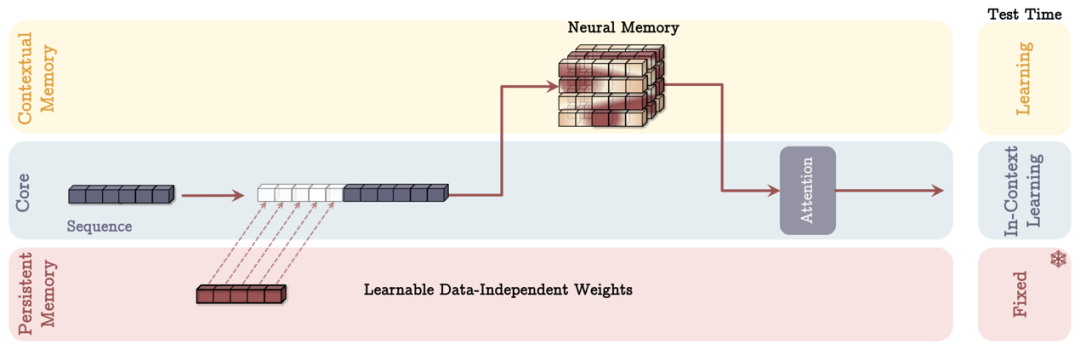 圖丨作為層的內存(MAL)架構(來源:arXiv)
圖丨作為層的內存(MAL)架構(來源:arXiv)實驗結果顯示,Titans 在多個測試基準上都表現出色。
在語言建模任務上,擁有 760M 參數的 Titans(MAC) 在 WikiText 上達到了 19.93 的困惑度,顯著優於同等規模的 Transformer++(25.21) 和 Mamba2(22.94)。在常識推理任務上,Titans 在包括 PIQA、HellaSwag、WinoGrande 等 9 個基準測試中的平均準確率達到 52.51%,超過了現有的最好成績。
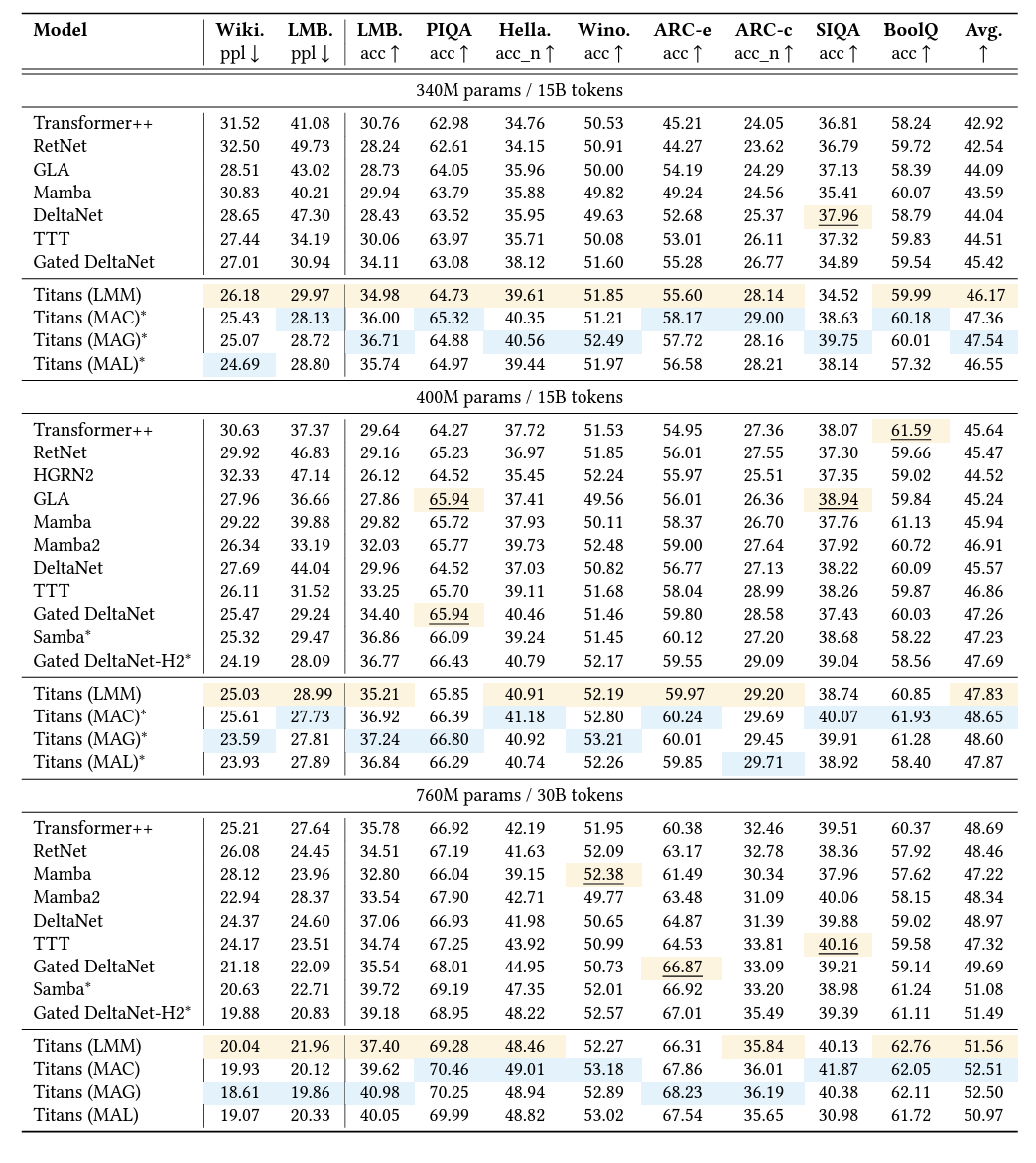
圖丨Titans 和基於循環和 Transformer 的基線在語言建模和常識推理任務中的性能。混合模型用 ∗ 標記。簡單和混合模型中的最佳結果被突出顯示。(來源:arXiv)
值得一提的是,在 BABILong 基準測試中,即使是參數量較小的 Titans 也展現出出色的性能。在需要在超長文檔中進行推理的任務中,Titans(MAC) 不僅戰勝了 Mamba2、RWKV 等現代模型,甚至超越了參數量大得多的 GPT-4 和 Llama3-70B。實驗證明,Titans 能夠有效處理超過 200 萬個 token 的上下文窗口,這一突破將為長文本處理開闢新的可能。
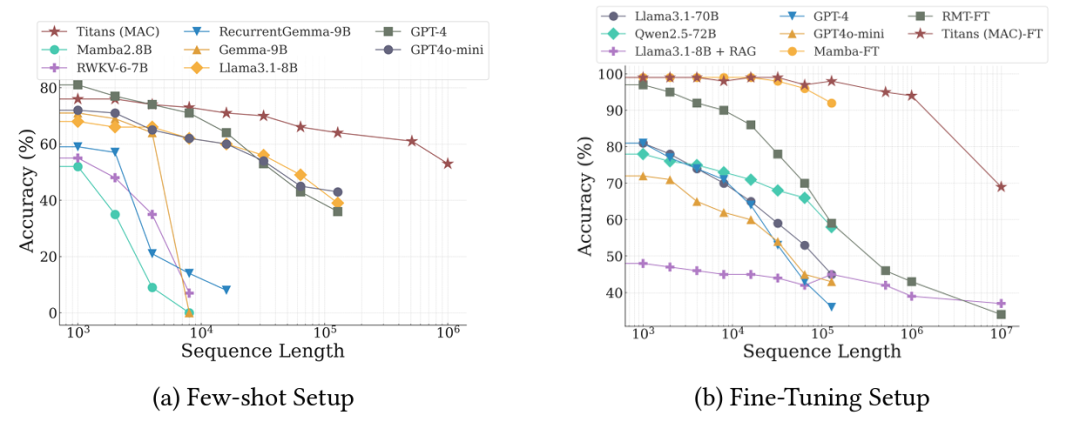 圖丨Titans 和基線在 BABILong 基準上的性能(來源:arXiv)
圖丨Titans 和基線在 BABILong 基準上的性能(來源:arXiv)研究團隊表示,Titans 的 PyTorch 和 JAX 實現代碼將很快開源。隨著這一技術的進一步發展和應用,我們有望看到更多能夠處理超長文本的高效 AI 系統湧現,這對於文檔分析、長文本理解、知識檢索等領域都具有重要意義。
當然,這項研究仍有進一步探索的空間。如何設計更高效的神經記憶架構、如何在更大規模的模型中應用這一技術,都是未來值得關注的方向。但毫無疑問,Titans 的出現為解決 AI 系統的長期依賴問題提供了一個極具前景的新方向。
參考資料:
1.https://arxiv.org/abs/2501.00663
2.https://x.com/behrouz_ali/status/1878859673555624373
運營/排版:何晨龍