MiniMax開源4M超長上下文新模型!性能比肩DeepSeek-v3、GPT-4o
西風 發自 凹非寺
量子位 | 公眾號 QbitAI
開源模型上下文窗口捲到超長,達400萬token!
剛剛,「大模型六小強」之一MiniMax開源最新模型——
MiniMax-01系列,包含兩個模型:基礎語言模型MiniMax-Text-01、視覺多模態模型MiniMax-VL-01。
MiniMax-01首次大規模擴展了新型Lightning Attention架構,替代了傳統Transformer架構,使模型能夠高效處理4M token上下文。

在基準測試中,MiniMax-01性能與頂級閉源模型表現相當。
MiniMax-Text-01性能與前段時間大火的DeepSeek-V3、GPT-4o等打的有來有回:
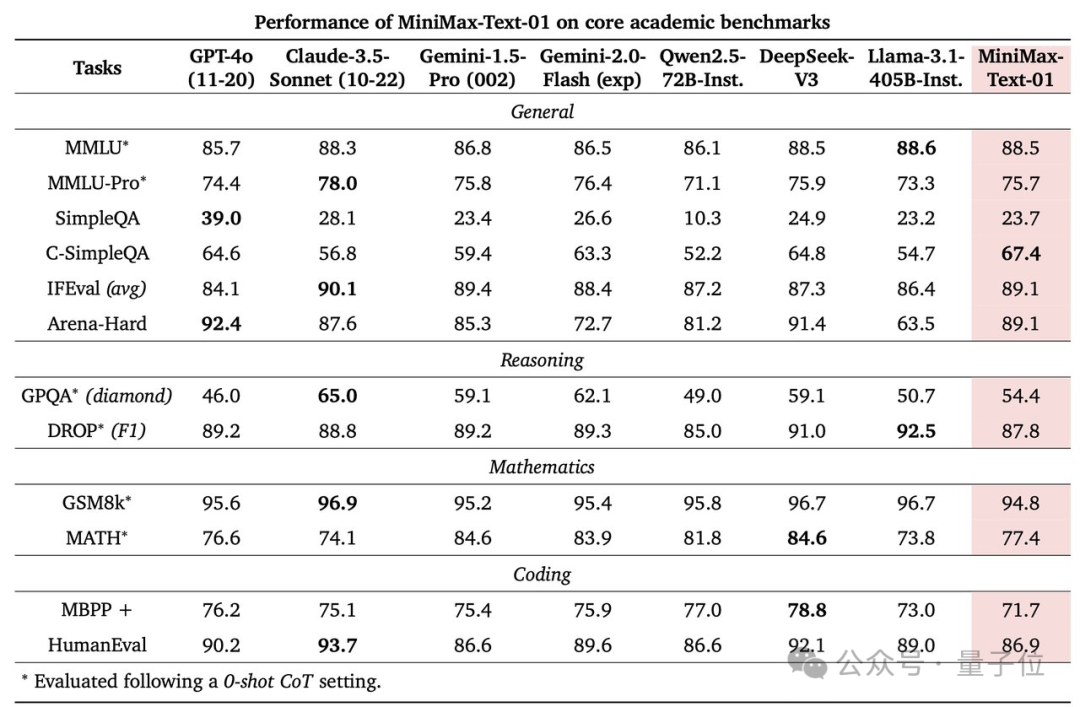
如下圖(c)所示,當上下文超過20萬token,MiniMax-Text-01的優勢逐漸明顯。
在預填充延遲方面也有顯著優勢,在處理超長上下文時更高效,延遲更低:
網民直呼「難以置信」:
開放權重,擁有400萬token的上下文窗口!我原本以為這可能要五年後才會實現。
官方表示,MiniMax-01是為支持之後Agent相關應用而預備的:
因為Agent越來越需要擴展的上下文處理能力和持續的內存。
目前官方還公開了MiniMax-01的68頁技術論文,並且已將MiniMax-01在Hailuo AI上部署了,可免費試用。
另外,新模型API價格也被打下來了:
輸入每百萬token0.2美元,輸出每百萬token1.1美元。

下面是模型更多細節。
4M超長上下文
MiniMax-Text-01
MiniMax-Text-01,參數456B,每次推理激活45.9B。
它創新性地採用了混合架構,結合了Lightning Attention、Softmax Attention以及Mixture-of-Experts(MoE)。
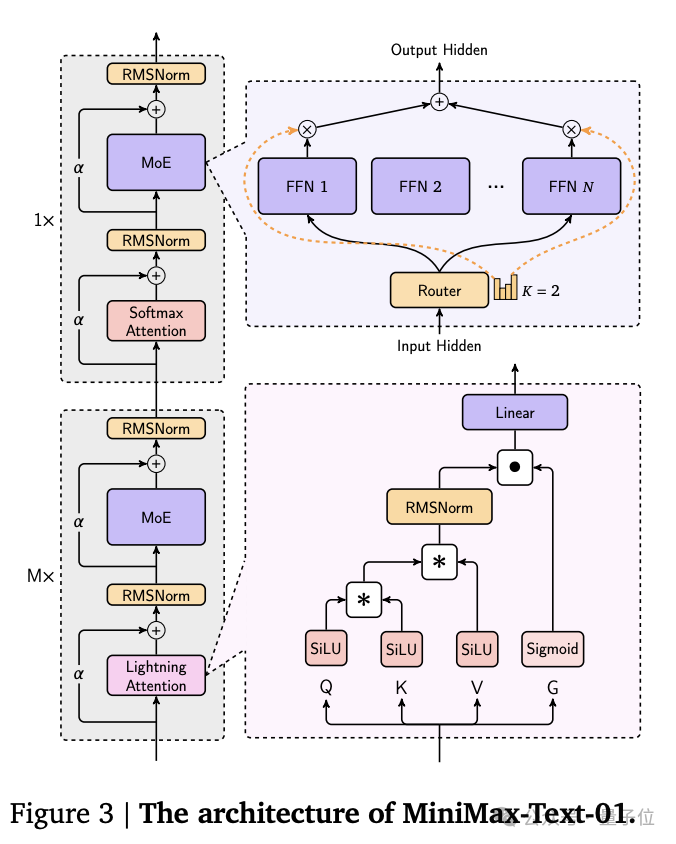
並且通過LASP+、varlen ring attention、ETP等優化的並行策略和高效的計算通信重疊方法,MiniMax-Text-01訓練上下文長度達100萬token,推理時可以擴展到400萬token上下文。
模型架構細節如下:

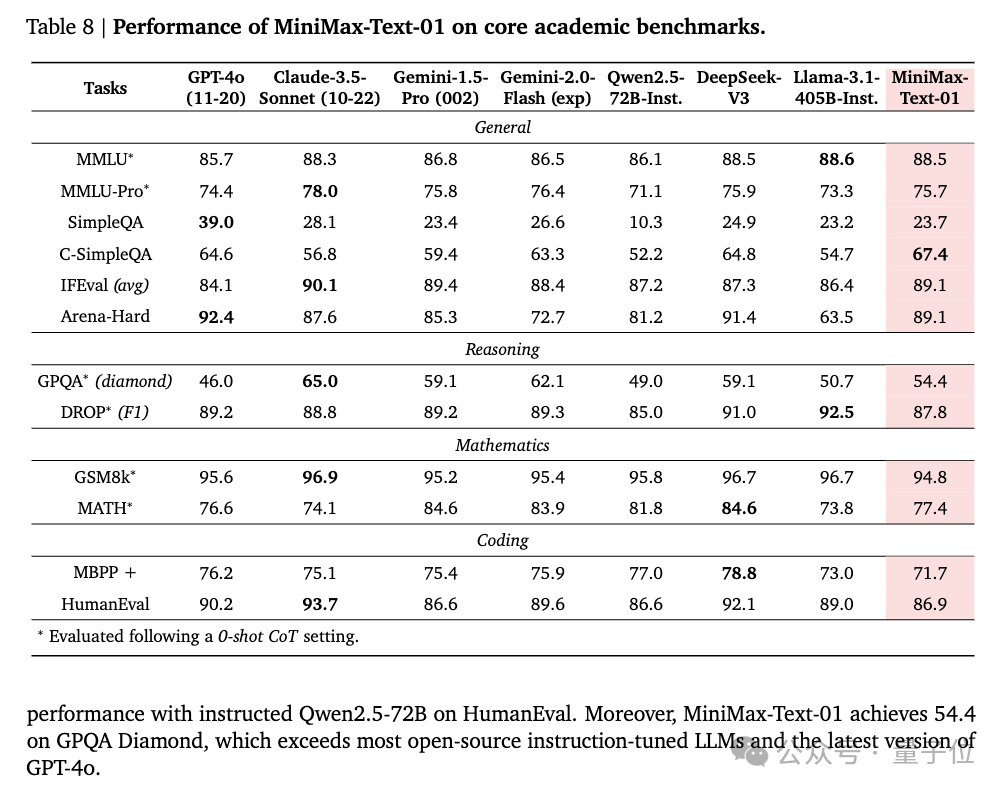
在Core Academic Benchmark上,MiniMax-Text-01在GPQA Diamond上獲得54.4分,超越GPT-4o。
在長基準測試之4M大海撈針測試,MiniMax-Text-01一水兒全綠。
也就是說,這400萬上下文里,有細節MiniMax-Text-01是真能100%捕捉到。
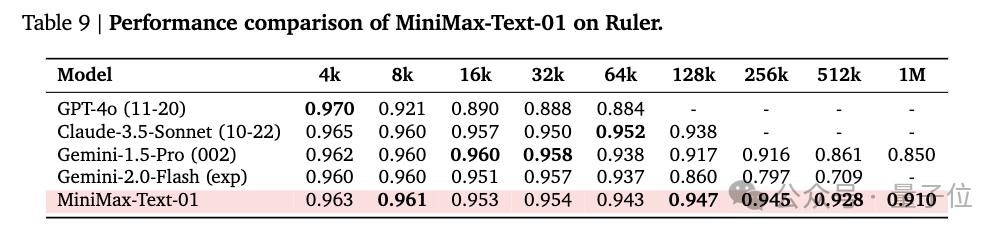
除此之外,還有LongBench v2、Ruler基準測試,考驗的是模型長上下文理解能力,包含基於長上下文輸入的邏輯推理能力。
MiniMax-Text-01模型在處理Ruler的長上下文推理任務時表現出顯著的優勢。
在64K輸入級別的表現與頂尖模型GPT-4o、Claude-3.5-Sonnet等競爭力相當,變化微小,但從128K開始顯現出明顯的優勢,並超越了所有基準模型。
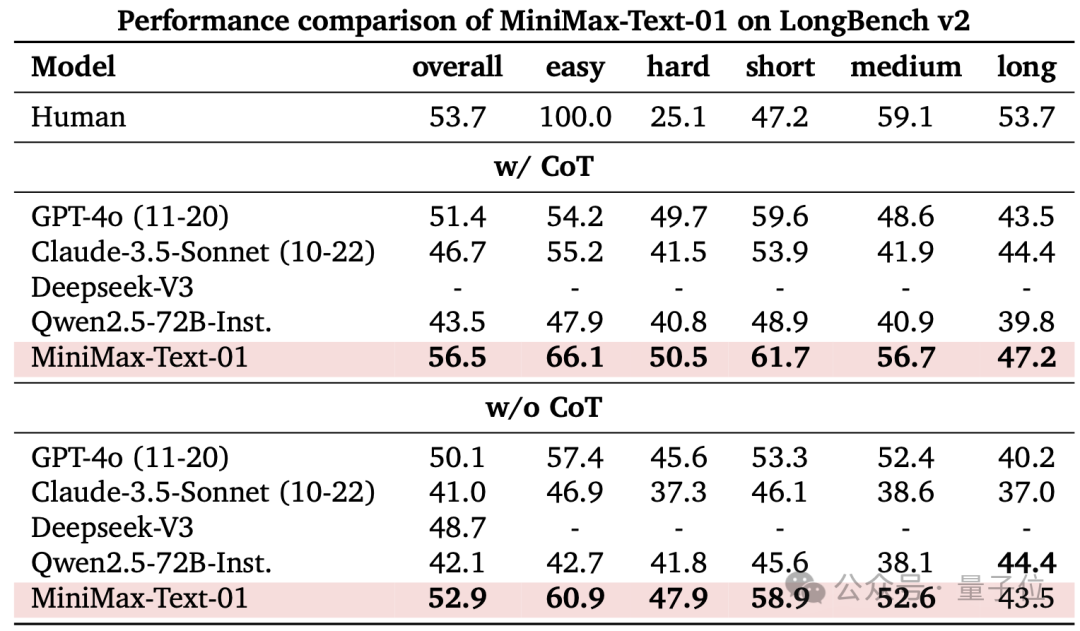
LongBench-V2包括不同難度級別的問答任務,涵蓋多種上下文類型,包括單文檔和多文檔、多輪對話、代碼倉庫和長結構化數據等。團隊考慮了兩種測試模式:不使用思維鏈推理(w/o CoT)和使用思維鏈推理(w/ CoT)。
MiniMax-Text-01在w/ CoT設置中實現了所有評估系統中的最佳結果,在w/o CoT中表現也很顯著。
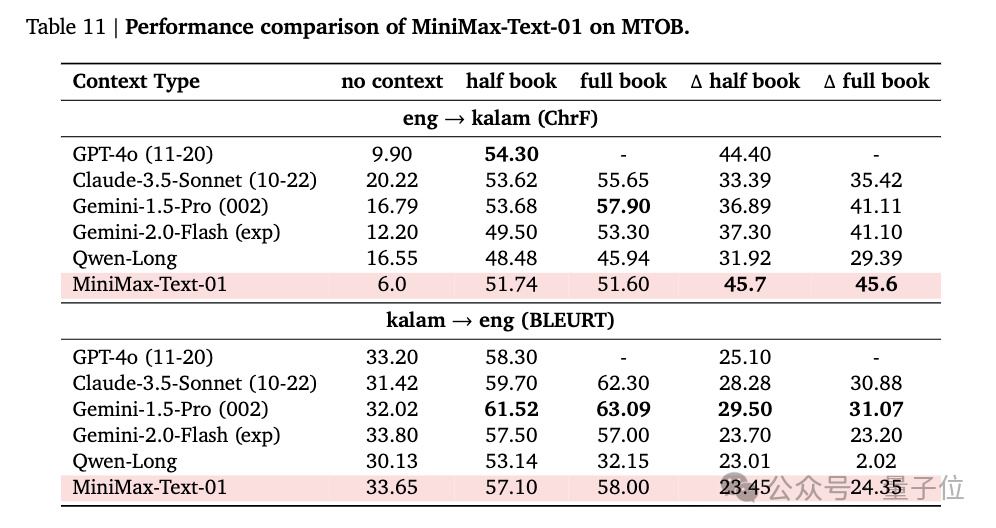
團隊還用MTOB( Machine Translation from One Book)數據集評估了模型從上下文中學習的能力。
該任務要求模型在英語和Kalamang(一種在公開數據中非常有限的語言)之間進行翻譯,因此在訓練語料庫中,LLM僅從一部語法書的部分內容和375個翻譯示例中學習該語言。
測試結果顯示,MiniMax-Text-01在無上下文場景下eng→kalam (ChrF)得分最低,團隊認為其它模型可能是在預訓練或後訓練數據中集加入了kalam相關數據。在delta half book和full book上,MiniMax-Text-01超過了所有模型。
在kalam→eng(BLEURT)得分上MiniMax-Text-01也與其它模型表現相當。
MiniMax-VL-01
MiniMax-VL-01採用多模態大語言模型常用的「ViT-MLP-LLM」框架:
-
一個具有3.03億參數的ViT用於視覺編碼
-
一個隨機初始化的雙層MLP projector用於圖像適配
-
以及作為基礎LLM的MiniMax-Text-01
MiniMax-VL-01特別具有動態解像度功能,可以根據預設網格調整輸入圖像的大小,解像度從336×336到2016×2016不等,並保留一個336×336的縮略圖。
調整後的圖像被分割成大小相同的不重疊塊,這些塊和縮略圖分別編碼後組合,形成完整的圖像表示。
MiniMax-VL-01的訓練數據涵蓋標題、描述和指令。ViT從頭開始在6.94億圖像-標題對上進行訓練。在訓練過程的四個階段,處理了總計5120億token。
最終,MiniMax-VL-01 在多模態排行榜上表現突出,證明了其在處理複雜多模態任務中的優勢和可靠性。
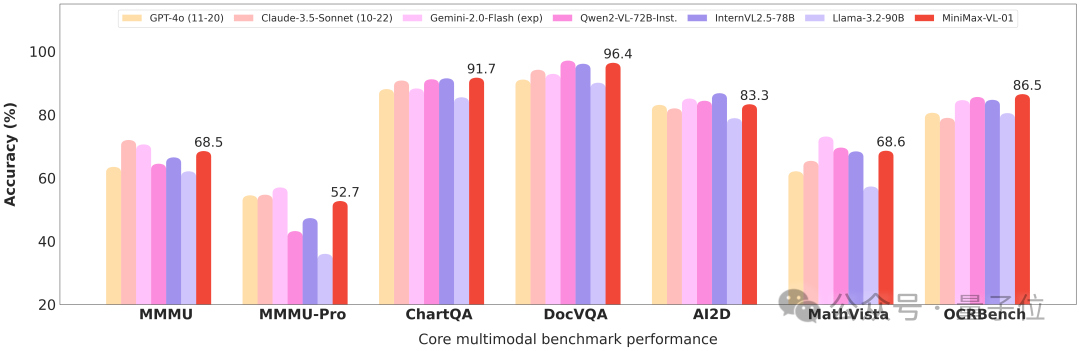
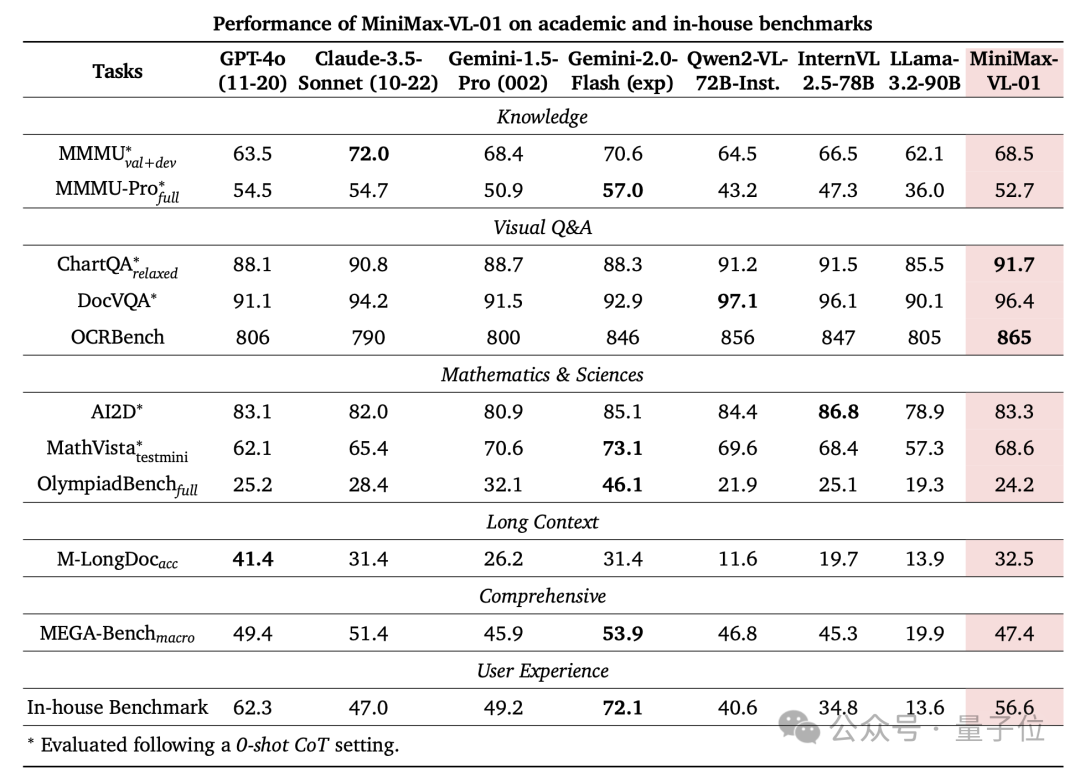
網民們已開始第一波實測
得知新模型已在Hailuo AI上部署,網民們已緊忙趕往測試。
有網民使用相同的prompt將它和Gemini、o1對比,感歎MiniMax-01表現令人印象深刻。
下面這個測試也沒能難倒它:
給我5個奇數,這些數的英文拚寫中不包含字母「e」。
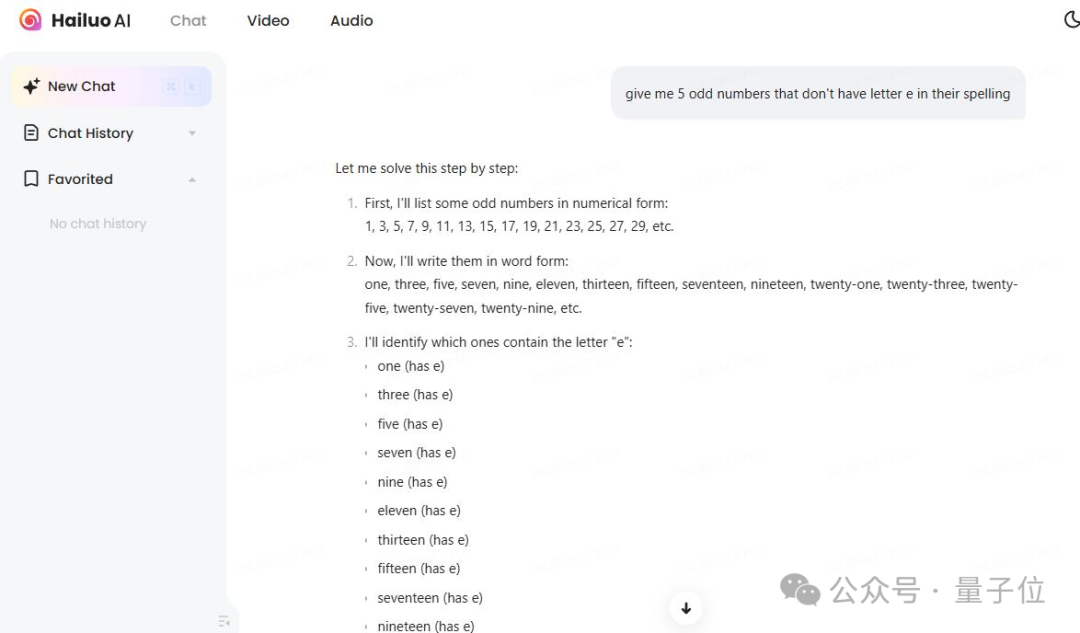
感興趣的童鞋可以玩起來了。
技術論文:https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf
參考鏈接:
[1]https://x.com/MiniMax__AI/status/1879226391352549451
[2]https://huggingface.co/MiniMaxAI/MiniMax-Text-01
[3]https://huggingface.co/MiniMaxAI/MiniMax-VL-01



















