激進架構,400萬上下文,徹底開源:MiniMax-01有點「Transformer時刻」的味道了

作者|王兆洋郵箱|wangzhaoyang@pingwest.com
「MoE」加上「前所未有大規模投入生產環境的 Lightning Attention」,再加上「從框架到CUDA層面的如軟件和工程重構」,會得到什麼?
答案是,一個追平了頂級模型能力、且把上下文長度提升到400萬token級別的新模型。
1月15日,大模型公司MiniMax正式發佈了這款預告已久的新模型系列:MiniMax-01。它包括基礎語言大模型MiniMax-Text-01 和在其上集成了一個輕量級ViT模型而開發的視覺多模態大模型 MiniMax-VL-01。
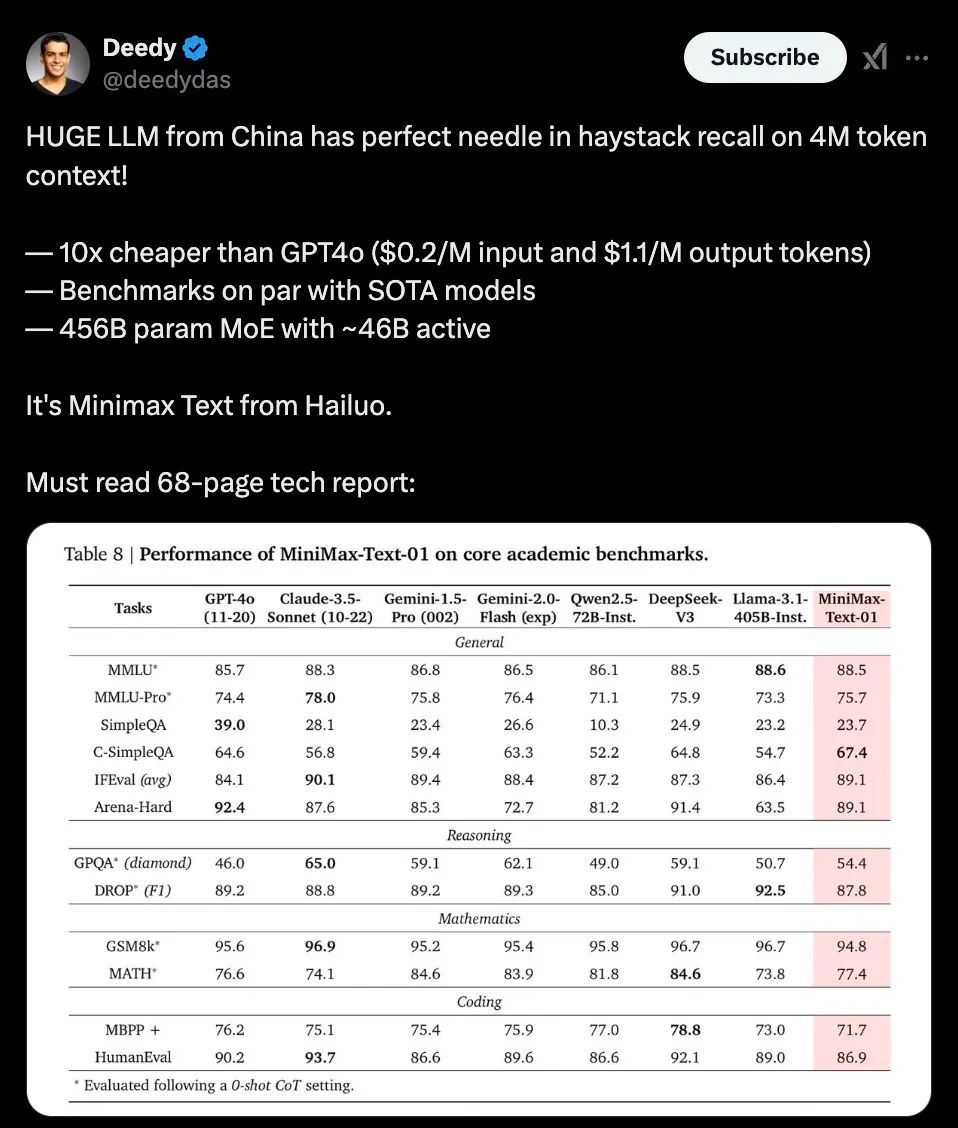
MiniMax-01是一個總參數4560億,由32個Experts組成的MoE(混合專家)模型,在多個主流評測集上,它的綜合能力與GPT-4o和Claude 3.5 sonnet齊平,而同時,它的上下文長度是今天頂尖模型們的20-32倍,並且隨著輸入長度變長,它也是性能衰減最慢的那個模型。
也就是,這可是實打實的400萬token上下文。

這對今天所有大模型來說都是個新突破。而MiniMax實現它的方式也很激進——
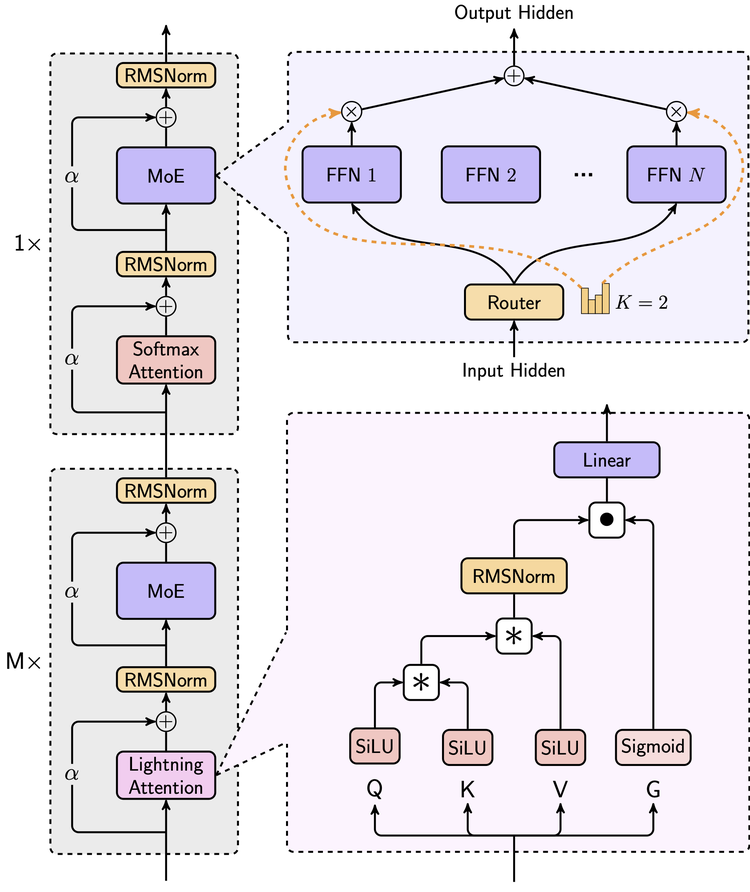
如此大參數的模型並不少見,但它是第一個依賴線性注意力機制的大規模部署的模型。在注意力機制層面,MiniMax-01做了大膽的創新,在業內首次實現了新的線性注意力機制,它的80層注意力層里,每一層softmax attention層前放置了7層線性注意力lightning attention層。
Softmax attention是Transformer的核心注意力機制,它是Transformer成為今天大模型熱潮里的基石的關鍵,但同時它也有著先天的問題——它會讓模型在處理長文本時複雜度成n的平方的增加。線性注意力則可以把複雜度控制在線性增加。線性注意力機制相關的研究一直在冒出來,但它們往往是一種「實驗」的狀態,MiniMax-01第一次把它放到了生產環境里。
它的目的就是要在成本得以控制的同時,給MoE模型帶來更長的上下文能力。
「我們希望這個模型能為接下來的AI Agent爆發做出貢獻。」MiniMax-01也是MiniMax第一個開源的模型,它的權重等全部對社區公開。

MiniMax是國內最早做預訓練模型的商業公司之一,在模型的技術路線上它一直按著自己的想法走。而這些路線多次被證明成為了業內後來的主流方向。MiniMax-01是這家公司的技術品味和技術路線在今天的一個集中展示。
它再次把很多人相信的實驗性要素,一步一步組成它自己信仰的基礎模型架構,並用最極致且真刀真槍堆資源的方式實現了出來。
相信線性注意力和MoE,建造一個全新模型架構
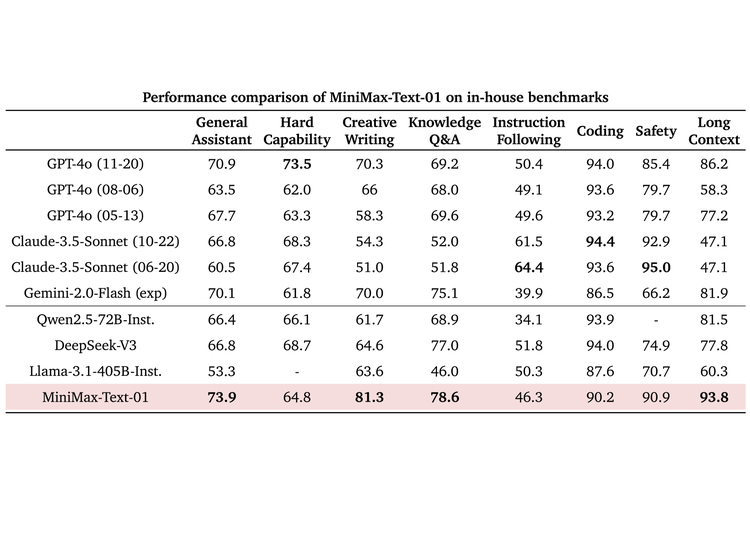
根據這份技術報告里提供的評測信息,MiniMax-01在業界主流的文本和多模態理解任務上的表現,在大多數任務上追平了來自OpenAI和Anthropic的最先進模型,在長文能力上,它與目前在上下文能力上最強的Google Gemini對比,顯示出更強的穩定性,並且隨著輸入文本的增加,評分開始出現明顯的領先。
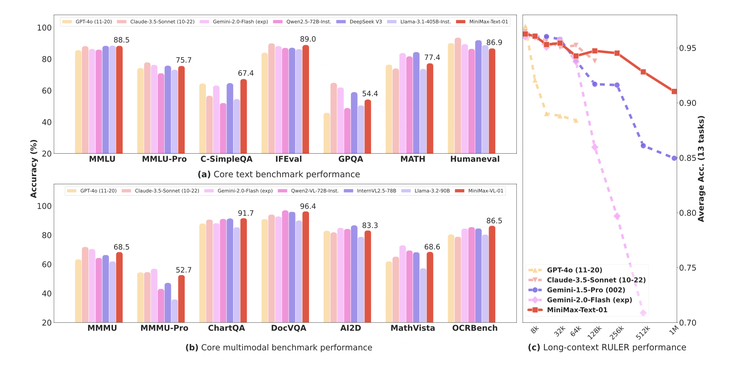
作為同時擁有多個明星toC產品的公司,MiniMax也構建了一個基於真實助手場景數據的測試集,它在其中的表現也呈現出同樣的特徵,基本能力在第一梯隊,長文本能力明顯領先。
「這個工作的核心是我們第一次把線性注意力機制擴展到商用模型的級別,從Scaling Law、與MoE的結合、結構設計、訓練優化和推理優化層面做了綜合的考慮。由於是業內第一次做如此大規模的主要依賴線性注意力模型,我們幾乎重構了我們的訓練和推理系統,包括更高效的MoE All-to-all通訊優化、更長的序列的優化,以及推線性注意力層的高效Kernel實現。」MiniMax介紹。
這是一個長期的系統性的工作,從算法到架構再到軟硬件訓推一體的基礎設施,MiniMax的技術品味和定力基本都體現在了MiniMax-01的創新上。
在去年MiniMax第一次開發者活動上,創始人就曾系統分享過MiniMax的技術「信仰」:更快的訓練和推理,而實現方式他當時也舉了兩個例子:線性注意力和MoE。而這次的開源模型技術報告基本就是那次分享的「交作業」,它難得把MiniMax的諸多工作展示給了外界。
在MoE上,一年前MiniMax正式全量上線了國內第一個千億參數的MoE模型。簡單來說,MoE (Mixture of Experts 混合專家模型)架構會把模型參數劃分為多組「專家」,每次推理時只有一部分專家參與計算。這種架構可以讓模型在小參數的情況下把計算變得更精細,然後擁有大參數才有的處理複雜任務的能力。
對於MoE模型來說,設置幾個專家、決定專家分配的路由如何優化等,是決定它效率的關鍵。此次的MiniMax-01,經過各種實驗後,確定模型內使用 32 個專家模塊,雖然總參數量達到了 4560 億,但每個 token 激活的參數僅為 45.9 億。這個設定的現實考慮,是要讓模型在單台機器8 個 GPU 和 640GB 內存的條件下,使用 8 位量化處理超過 100 萬個token。同時,它還改進了全新的 Expert Tensor Parallel (ETP) 和 Expert Data Parallel (EDP) 架構,它們能幫助降低數據在不同專家模塊間通信的成本。
而更核心就是對注意力機制的重構。
在MiniMax-01的性能報告里有這樣一張圖,從中可以看到,在其他模型處理256k的時間窗口內,MiniMax的模型可以處理多達 100萬個詞的信息。也就是說,即使模型一次只能專注於一部分內容,它仍然可以通過高效的計算策略和巧妙的設計,將更多信息納入整體理解。
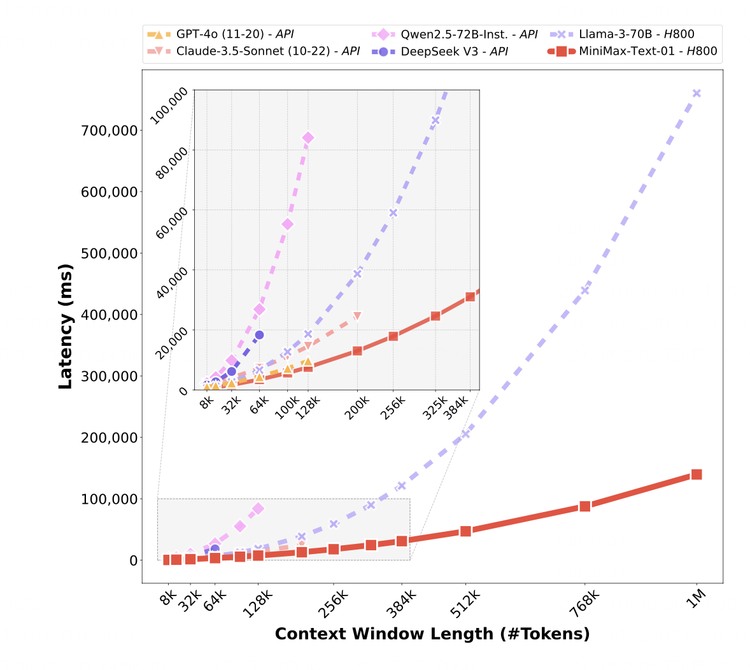
把模型想像成在翻閱一本巨大的書,即使每次只能看幾頁,但它能記住之前的內容,最終把整本書的知識都處理一遍。
對於傳統的Transformer來說,它使用Softmax注意力,需要為此構建一個N×N 的全連接矩陣,對於超長序列,這個矩陣會非常龐大。而 Lightning Attention 這樣的線性注意力機制則是進行「分塊計算」(tiling),模型將超長序列分成若干小塊,每個塊的大小固定,先計算塊內部的詞之間的關係(intra-block),接著再通過一種遞歸更新的方法,將塊與塊之間的信息逐步傳遞(inter-block),使得最終可以捕捉到全局語義關係。
這個過程類似於分組討論:先解決每組內部的問題,再彙總所有組的結果,最終得到全局的答案。
這種優化大大減少了計算和內存需求,也從傳統 Softmax 注意力的平方複雜度降低為線性。
同時,為了平衡效率與全局信息捕捉能力,它通過大量的實驗最終找到當下混合注意力機制的最佳配方:7比1。在 Transformer 的每 8 層中,有 7 層使用 Lightning Attention,高效處理局部關係;而剩下 1 層保留傳統的 Softmax 注意力,確保能夠捕捉關鍵的全局上下文。
和傳統的機制相比,一個是看書時候每個字都看,另一個是挑重點看,然後偶爾看一下目錄對照一下整體。效率自然不同。
此外,它還引入了Varlen Ring Attention,用來直接將整個文本拚接成一個連續的序列,從而讓變長序列的數據在模型中按需分配資源;在預訓練數據上使用數據打包(Data Packing),將不同長度的文本拚接成連續的長序列;在分佈式計算時改進了 Linear Attention Sequence Parallelism (LASP+),使模型能夠在多 GPU 之間高效協作,無需對文本進行窗口切分。
某種程度上,MiniMax在引入線性注意力機制上的「哲學」,和它一直以來追逐MoE模型路線的思想是一脈相承的——就是用更聰明的方式解決問題,把資源發揮到極致,然後通過大量真刀真槍的實驗把它在真實場景大規模實現。
線性注意力和MoE在MiniMax-01這裏,成了絕配。
下個Transformer時刻
當模型的代際迭代不再兇猛,上下文長度和邏輯推理正在成為兩個最重點方向。
在上下文方面,此前Gemini一度是最長的那個。而且,DeepMind的CEO Demsi Hassabis也曾透露,在Google內部,Gemini模型已經在實驗中實現過1000萬token的長度,並且相信最終會「抵達無限長度」,但阻止Gemini現在就這麼做的,是它對應的成本。在最近的一個訪談里他表示,Deepmind目前已經有新的方法來解決這個成本難題。
所以,誰能先把上下文長度提高,同時把成本打下來,誰可能就會佔得先機。從MiniMax-01展示的效果來看,它的效率確實獲得了質的提升。
在這篇詳盡的技術報告里,從一個數據可以看出對於硬件的使用效率——在推理上,MiniMax 在 H20 GPU 上的MFU 達到了 75%。這是一個相當高的數字。
MFU(Machine FLOPs Utilization,機器浮點利用率)指的是模型在運行過程中對硬件計算能力(FLOPs,即每秒浮點運算次數)的實際利用率。簡單來說,MFU 描述了一個模型是否充分發揮了硬件性能。高利用率必將帶來成本上的優勢。
MiniMax 01無疑是近來死氣沉沉的「撞牆論」中,難得令人驚喜的模型之一。另一個最近引發廣泛討論的是DeepSeek V3。如上面所說,今天兩個重要的方向,一個在推理,一個在更長上下文,Deepseek V3和MiniMax-01 各自代表了其中一個。
有意思的是,從技術路線上,某種程度上兩者都是在對奠定今天繁榮基礎的Transformer里最核心的注意力機制做優化,而且是大膽的重構,軟硬件一體的重構。DeepSeek V3被形容把Nvidia的卡榨幹了,而MiniMax能夠實現如此高的推理MFU,很關鍵的也是他們直接對訓練框架和硬件做優化。
根據MiniMax的報告,他們直接自己從零開始一步步深度開發了一個適合線性注意力的CUDA 內核,並為此開發了各種配套的框架,來優化 GPU 資源的利用效率。兩家公司都通過更緊密的軟硬結合能力實現了目標。
另一個有意思的觀察是,這兩家出彩的公司,都是在ChatGPT出現之前就已經投入到大模型技術研發里去的公司,這兩個模型驚豔之處也都不在於過去習慣看到的「追趕GPT4」的模式,而是根據自己對技術演進的判斷,做出的重投入、甚至有些賭注意味的創新,在一系列持續的紮實工作後,交出的答卷。
而且這答卷也都不只是對自己的,它們都在試圖證明某些曾停留在實驗室的概念,在大規模部署到實際場景里後也可以有它承諾的效果,並借此讓更多人繼續優化下去。
這不免讓人聯想到Transformer出現的時候。
當初Attention機制也已經在實驗室走紅,但爭議依然不斷,是相信它的潛力的Google真正堆上了算力和資源,把它從理論實驗,做成了大規模部署實現出來的真東西。接下來才有了人們蜂擁而上,沿著被證明的路線走到今天的繁榮。
當時的Transformer把注意力機制堆了更多層,用上了更多的算力,今天的MiniMax-01則在嘗試徹底改造舊的注意力機制,一切都有些似曾相識。甚至當時Google的研究員為了強調注意力機制而起的那個著名的論文標題「Attention is all you need 」也非常適合被MiniMax借鑒:線性注意力is all you need ——
「模型目前仍有1/8 保留了普通softmax 注意力。我們正在研究更有效的架構,最終完全去掉softmax 注意力,從而有可能在不出現計算過載的前提下實現無限制上下文窗口。」
在這篇論文的最後,MiniMax的研究員們這樣寫道。
這顯然是巨大的野心,但在如今人們都在關注大模型接下來往哪兒走的時候,非常需要這樣的野心,非常需要一個或者更多個「Transformer時刻」——在一個自己相信的路線上做到極致,把看似所有人都知道的配方,最終兌現出來,展示給技術社區里的人們,讓它變成某個決定性的時刻,給AI的前進再添把火。