姚期智團隊開源新型注意力,節省90%內存不降性能,一個框架統一MHA/MQA/GQA
夢晨 發自 凹非寺
量子位 | 公眾號 QbitAI
新型注意力機制TPA,姚期智院士團隊打造。

TPA對每個token做動態的張量分解,不存儲完整的靜態KV,而是保留分解的版本,內存佔用節省90%(或者更多),而不會犧牲性能。
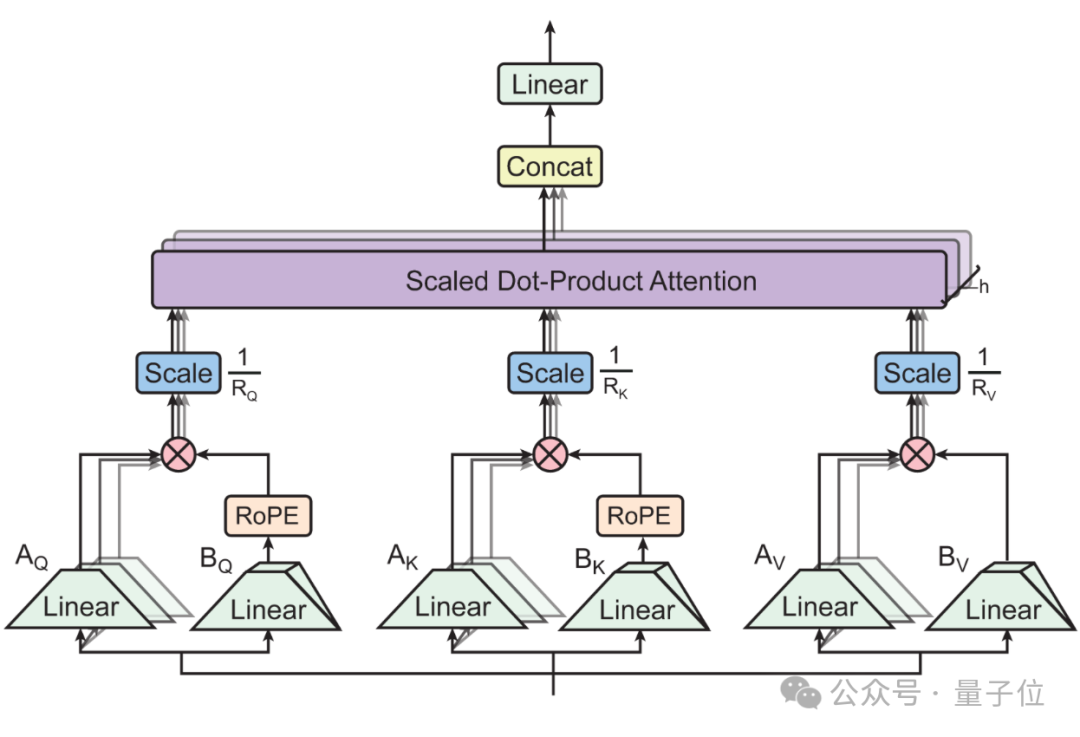
論文中還證明了流行的MHA、MQA、GQA都是TPA的特殊情況,用一個框架統一了現代注意力設計。

用此方法訓練的新模型T6,代碼已在GitHub開源。

論文發佈後,有創業者表示,終於不用付那麼多錢給雲廠商了。
也有研究者認為,論文中的實驗看起來很有希望,不過實驗中的模型規模有點小,希望看到更多結果。

動態張量分解,無縫集成RoPE
儘管現有的注意力機制在眾多任務中取得了不錯的效果,但它還是有計算和內存開銷大的缺陷。
DeepSeek-v2中提出的MLA壓縮了KV緩存,但與RoPE位置編碼不兼容,每個注意力頭需要額外的位置編碼參數。
為了克服這些方法的局限性,團隊提出張量積注意力(TPA,Tensor Product Attention)。
新方法在注意力計算過程中對QKV做分解。
與LoRA系列低秩分解方法相比,TPA將QKV分別構造為與上下文相關的分解張量,實現動態適應。

通過只緩存分解後的秩,設置合適的參數可使內存佔用降低90%或以上。

對於流行的RoPE位置編碼,TPA可以與之無縫集成,實現以較低的成本旋轉分解KV,無需進行複雜的調整。

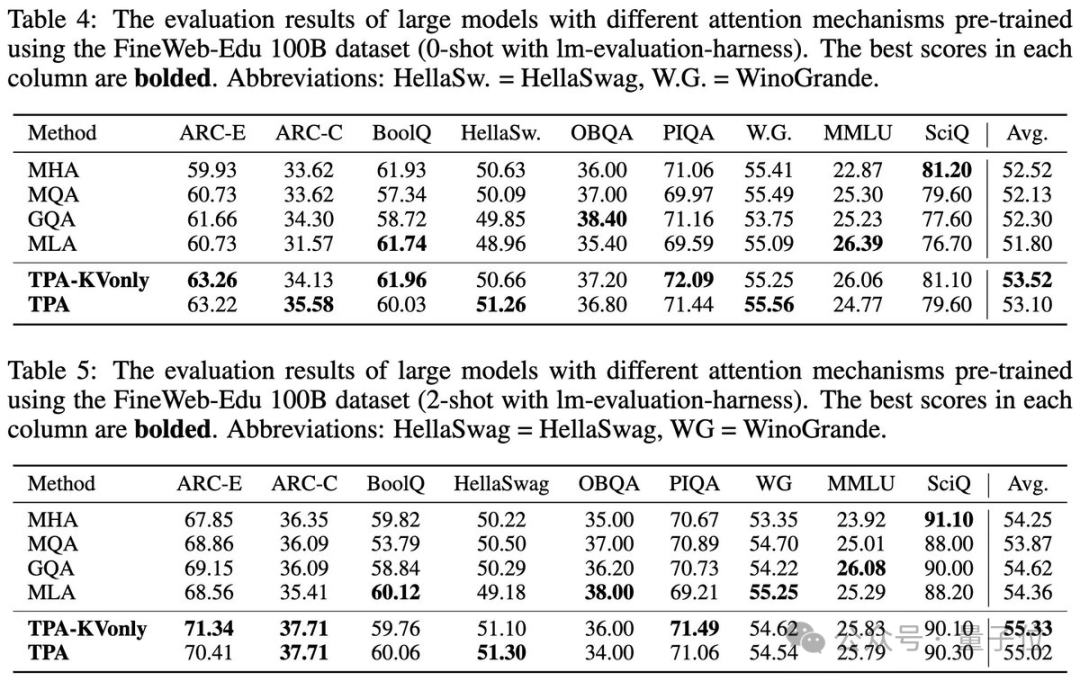
在實驗中,使用FineWeb-Edu 100B數據集訓練模型,TPA與其他注意力設計相比始終保持較低的困惑度。
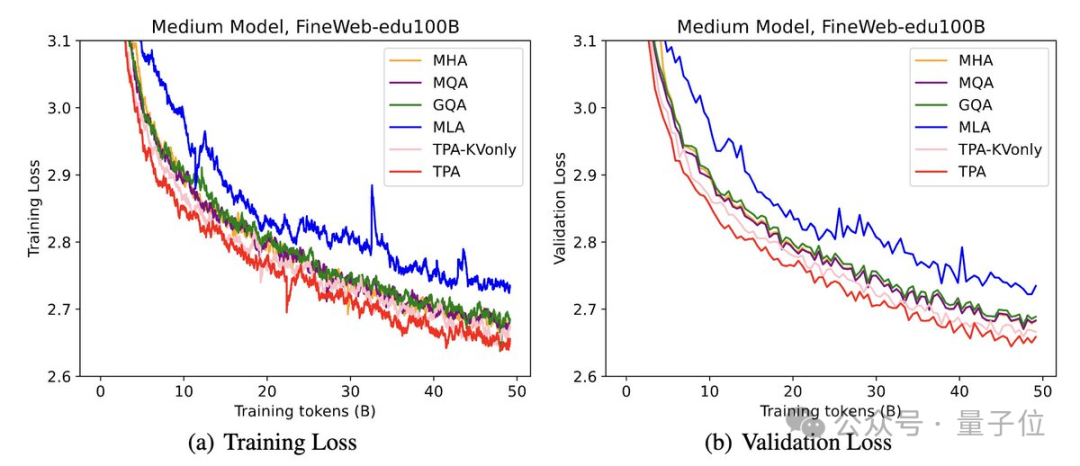
在ARC、BoolQ、HellaSwag和MMLU等基準測試中測試了零樣本和少樣本性能。TPA和TPA-KVonly在大多數任務中都優於或匹配所有基線。
論文由清華&上海期智研究員團隊、UCLA顧全全團隊合作,共同一作為清華博士生張伊凡與姚班校友、現UCLA博士生劉益楓。
此外還有來自心動網絡Taptap的Qin Zhen。

論文地址:
https://arxiv.org/abs/2501.06425
開源代碼:
https://github.com/tensorgi/T6
參考鏈接:
[1]https://x.com/yifan_zhang_/status/1879049477681741896