揭秘大模型強推理能力幕後功臣「缺陷」,過程級獎勵模型新基準來了
複旦大學桑治明陽 投稿
量子位 | 公眾號 QbitAI
截止目前,o1 等強推理模型的出現證明了 PRMs(過程級獎勵模型)的有效性。
(「幕後功臣」 PRMs 負責評估推理過程中的每一步是否正確和有效,從而引導 LLMs 的學習方向。)
但關鍵問題來了:我們如何準確評估 PRMs 本身的性能?
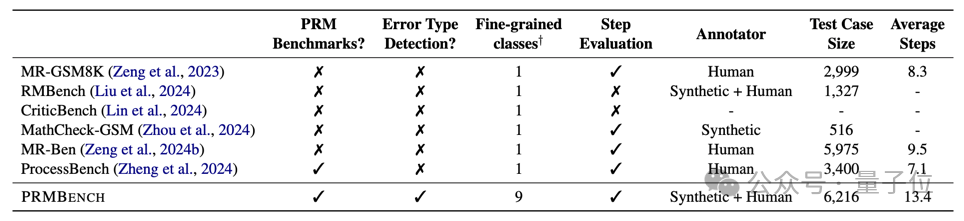
作為回應,複旦大學、蘇州大學,上海AI Lab等聯合提出了 PRMBench,它包含 6,216 條精心設計的問題和 83,456 個步驟級標籤,用於評測模型細粒度的錯誤檢測能力。

具體而言,目前主流的評估方法往往側重於最終結果的正確性,而忽略了對推理過程中細緻入微的錯誤類型的識別。例如,一個推理步驟可能存在冗餘、部分正確、 甚至完全錯誤等多種狀態,簡單的「正確/錯誤」標籤難以捕捉其複雜性。
而 PRMBench 提供了一個更全面、更精細化的評估工具,可以更有效地識別 PRMs 的潛在缺陷,促進相關算法的改進。
實驗發現,目前 PRMs 在細粒度錯誤檢測上仍有較大提升空間。即使是表現最佳的模型 Gemini-2-Thinking,其 PRMScore 也僅為 68.8,勉強高於隨機猜測的 50.0。
即使是專門在步驟級數據上訓練過的 PRMs,其表現仍不如優秀的閉源通用模型,且多步推理能力專門增強過的模型表現優於一般通用模型。
除此之外,研究人員還公佈了一些其他發現和探討。
PRMBench:一次針對PRMs的「全方位體檢」
據介紹,PRMBench 並非簡單的「升級版」評估數據集,而是一套經過精心設計的「體檢方案」,目的是全面考察 PRMs 在不同維度上的能力。
下圖為 PRMBench 的主要結構,左側部分展示了數據整理的流程,右側部分展示了評估主題的示例以及測試模型的相對性能表。
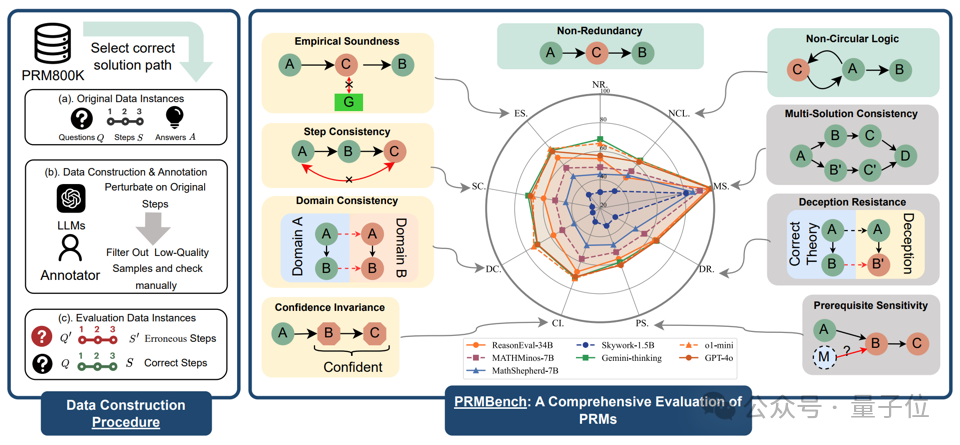
其主要特點包括:
-
海量且精細的標註數據:包含 6,216 個精心設計的問題,并包含 83,456 個步驟級別的標籤,確保評估的深度和廣度。
-
多維度、多層次的評估體系:從簡潔性 (Simplicity)、合理性 (Soundness) 和敏感性 (Sensitivity) 三個主要維度出發,進一步細分為九個子類別,例如非冗餘性、非循環邏輯、評價合理性、步驟一致性、領域一致性、置信度不變性、前提條件敏感性、 欺騙抵抗和一題多解一致性,力求全面覆蓋PRMs可能遇到的挑戰。
-
揭示現有 PRMs 的「盲區」:研究團隊對 15 個代表性模型進行了廣泛的實驗,包括開源 PRMs 以及將強力通用語言模型提示作為 Critic Model 的模型。實驗結果令人驚訝,也引人深思。
具體來說,研究的主要發現如下:
1、整體表現堪憂。即使是表現最佳的模型 Gemini-2-Thinking,其 PRMScore 也僅為 68.8,勉強高於隨機猜測的 50.0。這表明,即使是最先進的 PRMs,在多步過程評估中仍然有巨大的提升空間。
2、開源 PRMs 表現更弱。開源 PRMs 的平均 PRMScore 更低至 50.1,部分模型甚至不如隨機猜測,揭示了其可靠性和潛在訓練偏差的問題。
3、「簡潔性」成最大挑戰。在 「簡潔性」 維度上,即使是表現相對較好的 ReasonEval-34B,其 PRMScore 也驟降至 51.5,表明 PRMs 在識別推理過程中的冗餘步驟方面能力不足。
4、 「陽性偏好」現象顯著。部分模型,例如 ReasonEval-7B 和 RLHFlow-DeepSeek-8B,在評估中表現出顯著的「陽性偏好」,難以區分正確和錯誤的步驟。
5、數據驅動的洞察。研究發現,錯誤步驟出現的位置也會影響PRMs的判斷準確率。總的來說,隨著錯誤步驟位置的後移,PRMs 的表現會逐漸提升。
具體提出過程
下面介紹一下具體研究過程。
提出主要問題
在一項需要舉出反例的證明題實踐中,研究人員觀察到一個有趣的現象:
即使大語言模型 (o1) 自身意識到當前推理過程存在一些問題,仍然會產生錯誤的推理步驟。
更令人擔憂的是, 當調用現有的 PRMs 去檢測剛剛 o1 生成的推理過程時,結果卻發現多數 PRMs 無法檢測出這種細粒度的錯誤。
這一發現引出了一個關鍵問題:當前的 PRMs 是否具備檢測推理過程中細粒度錯誤的能力?
下圖為,當詢問模型一道拉格朗日中值定理相關問題時,o1 和 PRMs 可能會產生的錯誤。
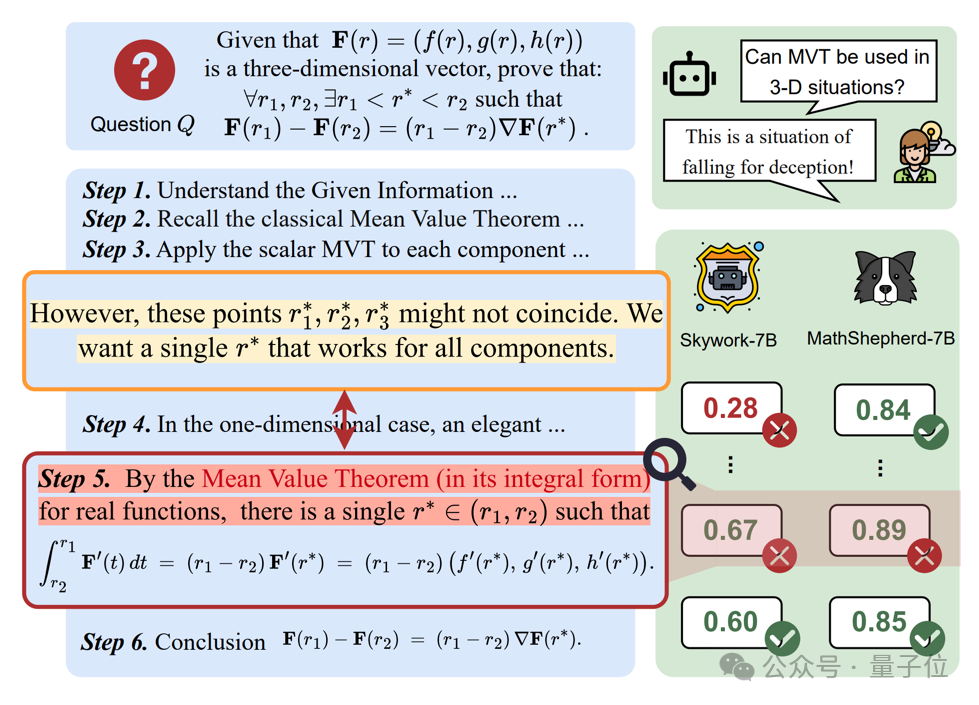
然而,現有針對 PRMs 評測而設計的 benchmark 大多僅僅關注步驟評判的對錯,而忽視步驟評判的錯誤類型, 缺乏對錯誤類型的細緻分類。
這也就意味著,目前缺少這樣能夠評測 PRMs 在細粒度錯誤上表現的綜合 benchmark。
而這,正是研究人員推出 PRMBench 這一精細化基準的根本原因。
他們希望通過 PRMBench,打破現有評估的局限,真正遴選出能夠有效識別細粒度錯誤的「優秀」 PRM。
下圖為 PRMBench 與其他數據集對比。
PRMBench構建
如下所示,PRMBench 包含三大評測主題:簡潔性,合理性和敏感性。
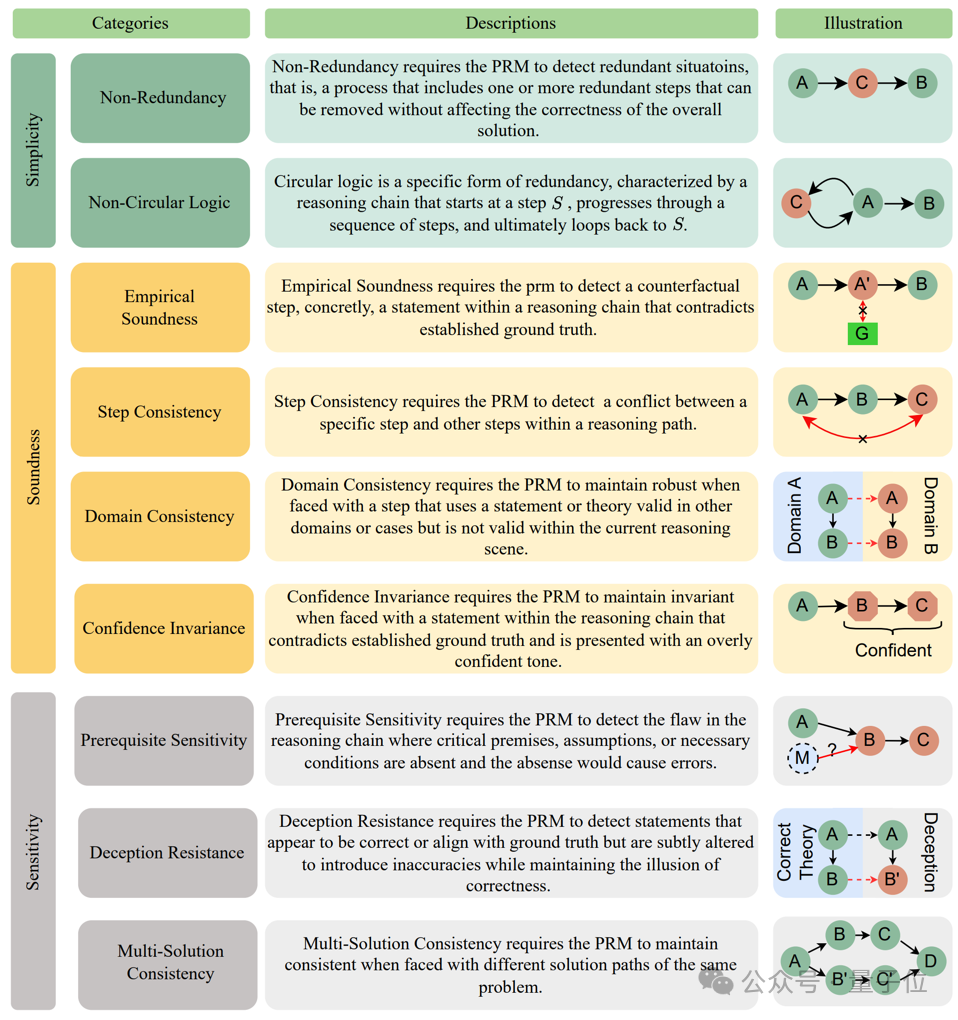
-
數據來源:基於PRM800K構建,首先篩選出其完全正確的問題、答案以及解題步驟作為元數據。
-
錯誤引入:針對多數評測主題(前8個)使用 LLMs(特別是 GPT-4o)將各種細粒度的錯誤引入到完全正確的解題推理步驟中。對於一題多解的情況,則使用多步推理增強過的語言模型為同一問題生成不同的正確解法及其推理步驟。
-
人工驗證:嚴格的人工審查,以確保引入錯誤的質量和相關性。
-
數據集統計:包含 6,216 個精心設計的問題,帶有 83,456 個步驟級別的標籤。
-
評估對象:分為三個主要領域。簡潔性評估冗餘檢測能力(非冗餘性、非循環邏輯);合理性評估PRM產生獎勵的準確性和正確性(評價合理性、步驟一致性、領域一致性、 置信度不變性);敏感性評估對變化和誤導性信息的魯棒性(前提條件敏感性、欺騙抵抗、多解一致性)。
實驗與結果
研究人員測試了 15 個模型,包括開源 PRMs (Skywork-PRM, Llemma-PRM, MATHMinos-Mistral,MathShepherd-Mistral, RLHFlow-PRM) 和提示為 Critic Models 的優秀閉源語言模型 (GPT-4o, o1-mini,Gemini-2)。
評估指標主要為:
-
負 F1 分數 (Negative F1 Score):評估錯誤檢測性能的主要指標。
-
PRMScore:將 F1 和負 F1 相結合的統一、標準化的分數,以反映整體能力。
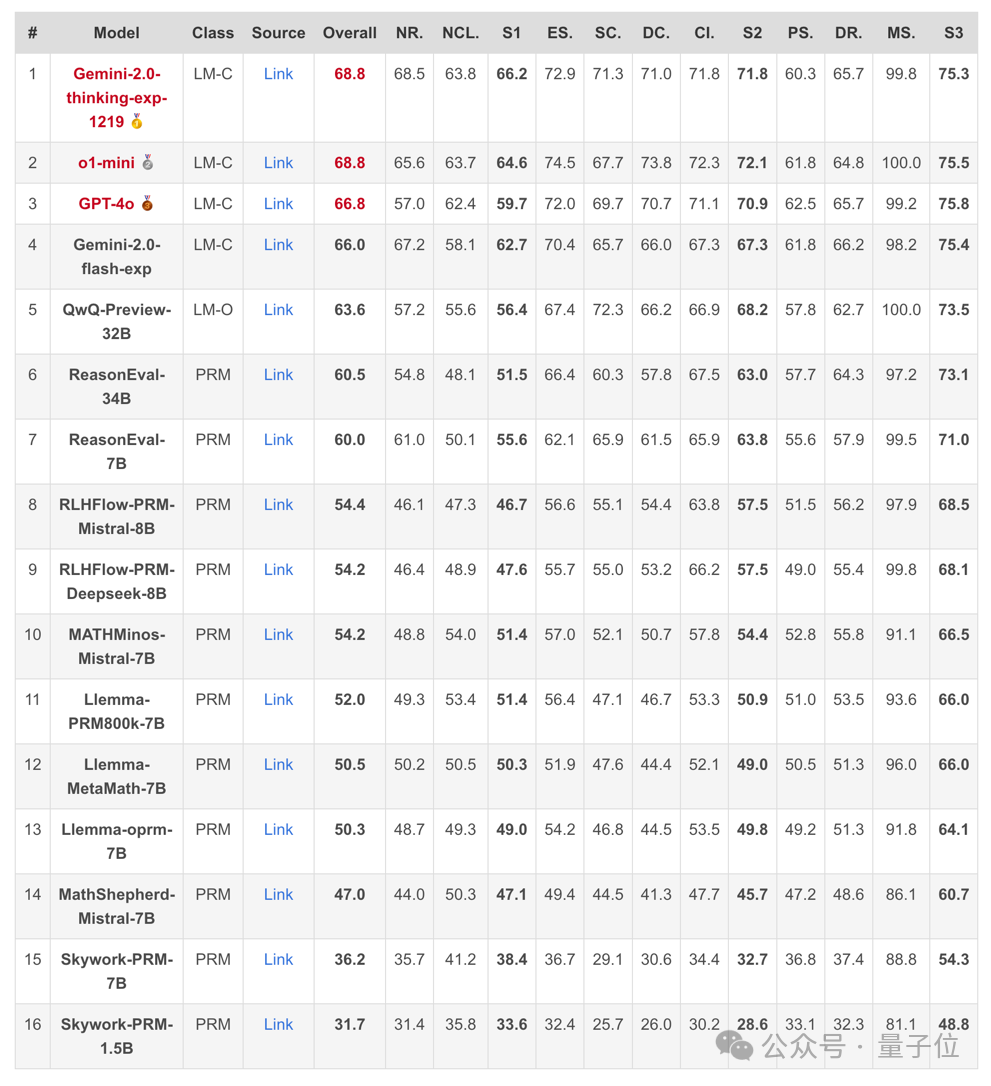
可以看出,整體而言 PRMs 在多步過程評估中表現出有限的能力,其得分通常僅略高於隨機猜測。
同時, 開源 PRMs 的表現通常不如將強力通用語言模型(如o1, Gemini-thinking等)提示為 Critic Model 的表現更好。
而且相較於其他評測主題,檢測冗餘 (簡潔性) 被證明對 PRMs 來說尤其困難。
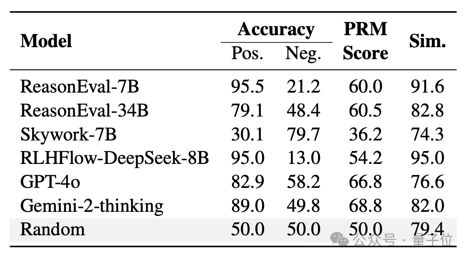
另外,通過 PRMBench 下模型對於正確標籤測試樣例(陽性數據)和錯誤標籤測試樣例(陰性數據)的得分對比及相似度來看。
許多 PRMs 表現出對正確標籤的偏好,難以正確識別錯誤標籤測試樣例(陰性數據)。
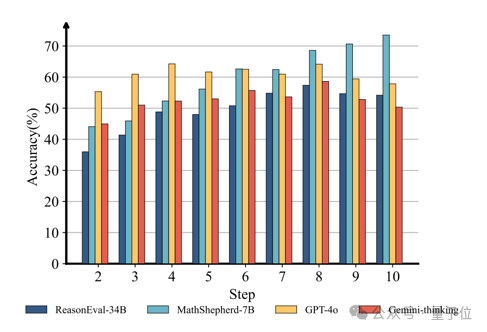
且從推理步驟位於推理鏈中不同位置對模型 PRMScore 的影響來看,PRMs 的性能往往會隨著推理步驟位於推理鏈中的位置逐漸靠後而提高。
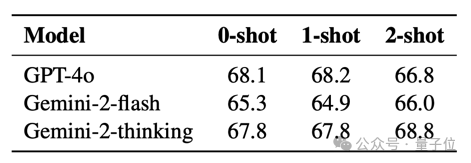
最後從不同 Few shot 數目對於提示為 Critic Model 的通用語言模型表現影響來看,少樣本 ICL 的影響有限。
在 reward 過程中使用不同數量示例的 In-Context Learning 對閉源模型的性能影響不大。
小結一下,PRMBench 的發佈,提醒我們重新審視現有 PRMs 的能力邊界。
按照研究團隊的說法,「我們希望 PRMBench 能夠成為推動 PRM 評估和發展研究的堅實基石」。
更多細節歡迎查閱原論文。
論文鏈接:
https://arxiv.org/abs/2501.03124
項目主頁:
https://prmbench.github.io/
Code:
https://github.com/ssmisya/PRMBench
Data:
https://huggingface.co/datasets/hitsmy/PRMBench_Preview



















