打臉!GPT-4o輸出長度8k都勉強,陳丹琦團隊新基準測試:所有模型輸出都低於標稱長度
奇月 發自 凹非寺
量子位 | 公眾號 QbitAI
很多大模型的官方參數都聲稱自己可以輸出長達32K tokens的內容,但這數字實際上是存在水分的??
最近,陳丹琦團隊提出了一個全新的基準測試工具LONGPROC,專門用於檢測長上下文模型處理複雜信息並生成回覆的能力。

實驗結果有點令人意外,團隊發現,包括GPT-4o等最先進的模型在內,儘管模型在常用長上下文回憶基準上表現出色,但在處理複雜的長文生成任務時仍有很大的改進空間。
具體來說,測試的所有模型都聲稱自己上下文窗口大小超過32K tokens,但開源模型一般在2K tokens任務中就表現不佳,而GPT-4o等閉源模型在8K tokens任務中性能也明顯下降。
舉例來說,讓GPT-4o模型生成一個詳細的旅行規劃時,即使提供了相關的時間節點和直飛航班線路,在模型的生成結果中仍然出現了不存在的航班信息,也就是出現了幻覺。

這到底是怎麼回事呢?
全新LONGPROC基準
目前現有的長上下文語言模型(long-context language models)的評估基準主要集中在長上下文回憶任務上,這些任務要求模型在處理大量無關信息的同時生成簡短的響應,沒有充分評估模型在整合分散信息和生成長輸出方面的能力。
為了進一步精確檢測模型處理長上下文並生成回覆的能力,陳丹琦團隊提出了全新的LONGPROC基準測試。
從表1中各測試基準的對比可以看出,只有LONGPROC基準同時滿足6個要求,包括複雜的流程、要求模型輸出大於1K tokens、且提供確定性的解決方案等。

新基準包含的任務
具體來說,LONGPROC包含6個不同的生成任務:
1.HTML到TSV:要求模型從HTML頁面中提取指定信息並格式化為表格。需要從複雜的HTML結構中穩健地提取所有相關信息,並將其正確格式化。
比如從下面的網頁中提取出所有影片的信息:

2.偽代碼生成代碼:要求模型將偽代碼翻譯成C++代碼。需要保持源代碼和目標代碼之間的一一對應關係,並確保翻譯的正確性。
3.路徑遍曆:要求模型在假設的公共交通網絡中找到從一個城市到另一個城市的路徑。需要確保路徑的唯一性和正確性。
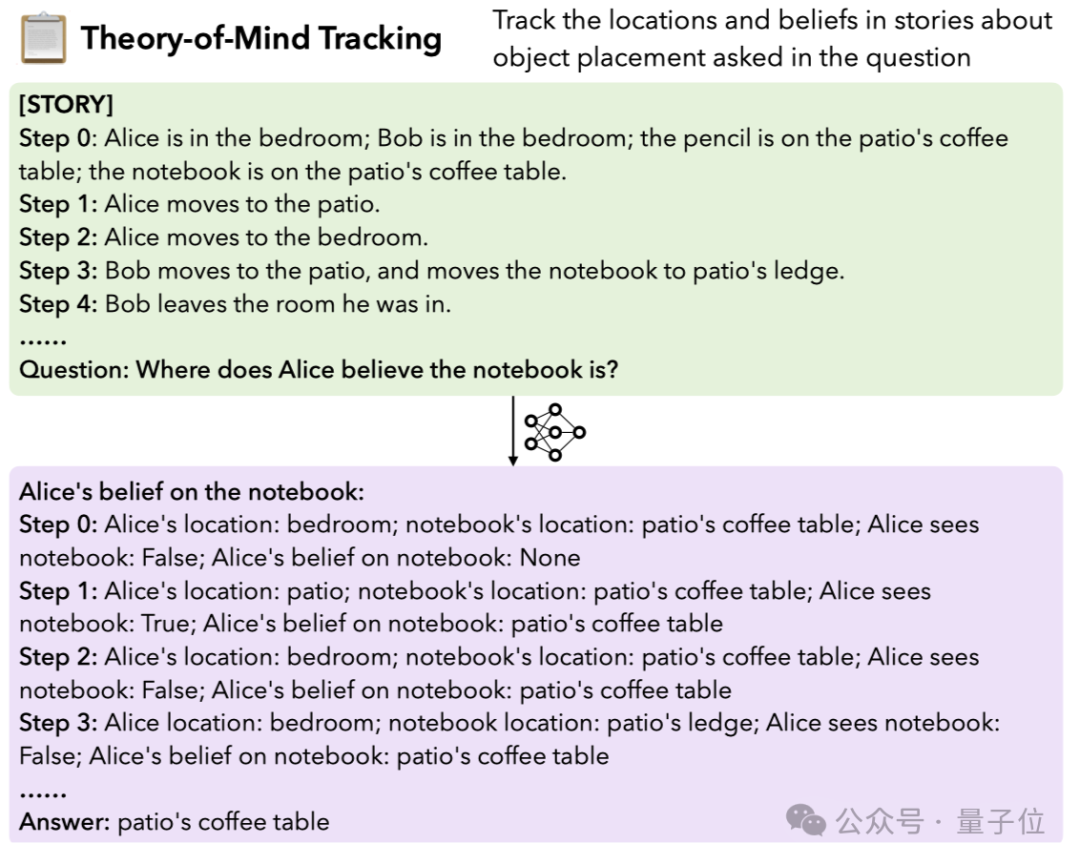
4.Theory-of-Mind跟蹤:要求模型跟蹤故事中對象位置的思想變化。需要進行長距離的推理,以準確反映對像在不同時間點的位置和狀態。
比如根據下面的文字敘述推斷出「Alice認為筆記本在哪裡」:
5.Countdown遊戲:要求模型使用四個數字和基本算術操作找到達到目標數字的方法。需要進行深度優先搜索,並確保搜索過程的完整性和正確性。
比如在下面的示例中,要求模型用四則運算操作輸入的數字,最終得出29的結果:

6.旅行規劃:要求模型生成滿足多種約束的多城市旅行計劃。需要探索多種可能的行程安排,並確保所有約束條件得到滿足。
如下圖所示,圖中要求模型根據任務提供的歐洲行程計劃和直飛航班規劃最佳的旅行時間安排:

在輸出結果的同時,LONGPROC還會要求模型在執行詳細程序指令的同時生成結構化的長形式輸出 。
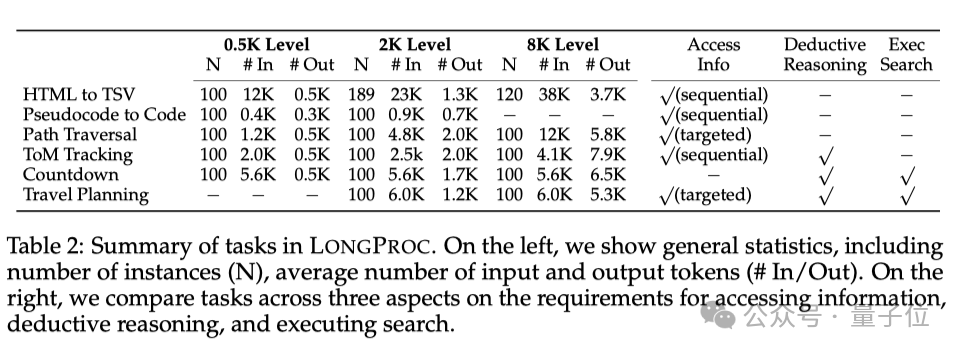
從表2中可以看出,除了對比左邊的實例數量(N)、輸入和輸出tokens的平均數量(#In/#Out),團隊還會從表格最右3列的獲取信息的方式、是否存在演繹推理和執行搜索這三個方面對任務進行比較。
實驗任務設置
實驗中,上面的6個任務都有不同的數據集。例如,HTML到TSV任務使用了Arborist數據集中的56個網站;偽代碼生成代碼任務使用了SPOC數據集;路徑遍曆任務構建了一個假設的公共交通網絡等等。
實驗都會要求模型執行一個詳細的程序來生成輸出。
此外,根據任務的輸出長度,數據集會被分為500 tokens、2K tokens和8K tokens三個難度級別。比如對於HTML到TSV任務來說,每個網站都會被分割成非重疊子樣本,這樣就可以獲得更多數據點。
參與實驗的模型包括17個模型,包括流行的閉源模型(如GPT-4o、Claude 3.5、Gemini 1.5)和開源模型(如ProLong、Llama-3、Mistral-v0.3、Phi-3、Qwen-2.5、Jamba)。
實驗結果及分析
首先來看看實驗中模型的整體表現。
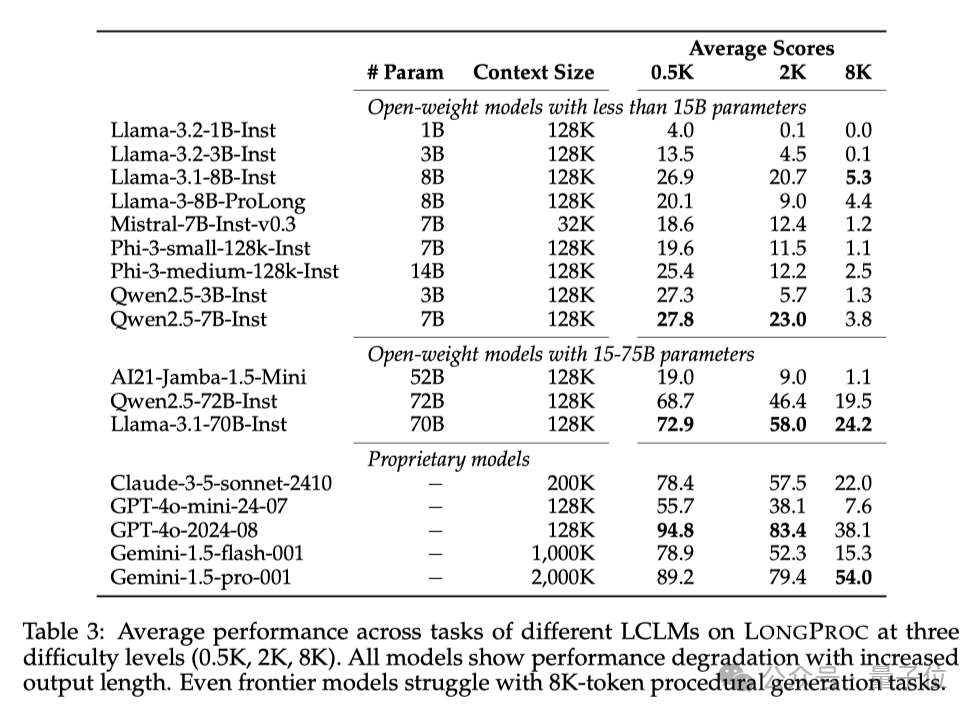
結果有點令人意外,所有模型在長程序生成任務中都表現出顯著的性能下降!具體的數值可以查看下面的表3。
即使是GPT-4o這種前沿模型,在8K tokens的輸出任務上也難以保持穩健的表現。
我們再來詳細分析一下不同模型之間的差異。
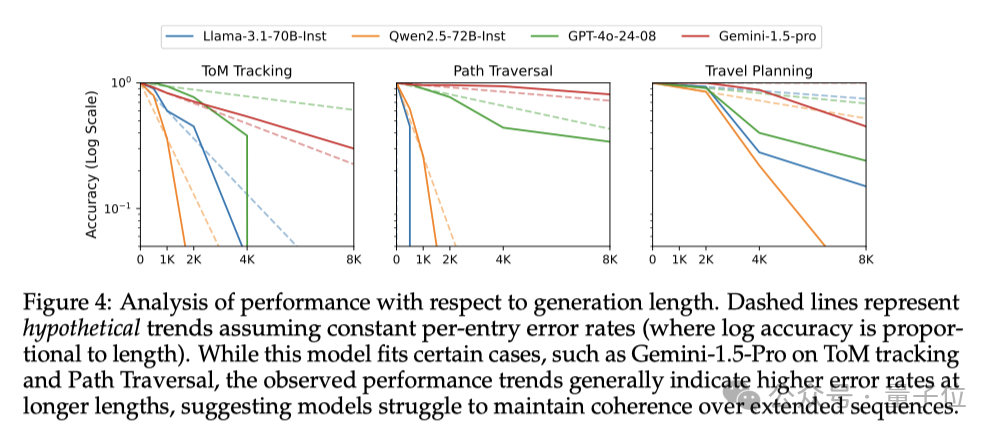
根據下面的圖3可以看出,像GPT-4o這樣的頂尖閉源模型在0.5K任務上表現最佳,但在8K任務上性能顯著下降。
小規模的開源模型基本都表現不佳,而中等規模的開源模型(Llama-3.1-70B-Instruct)在低難度任務上表現與GPT-4o相差不大。
不過,在某些8K任務上,中等規模的模型表現很不錯,比如Gemini-1.5-pro在HTML to TSV任務中就超過了GPT-4o,Llama-3.1-70B-Instruct、Qwen2.5-72B-Instruct在8K的Countdown遊戲中也與GPT-4o相差不大。
但整體來看,開源模型的性能還是不及閉源模型。
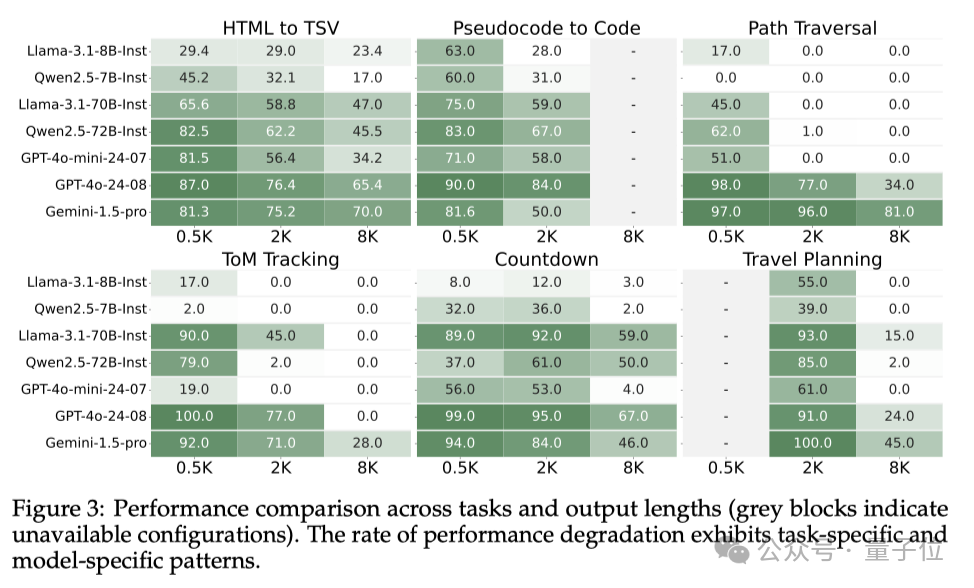
此外,模型表現跟任務類型也有關係。在需要更長推理的任務中,模型的性能普遍出現了更顯著的下降。
如圖4所示,在Theory-of-Mind跟蹤、Countdown遊戲和旅行規劃任務這些需要處理更複雜的信息、進行更長鏈的推理的任務中,模型性能的下降幅度都更大,GPT-4o、Qwen等模型的精確度甚至直線下降。
除了對比17個模型之間的能力,團隊成員還將表現較好的模型輸出內容與人類輸出進行了對比。
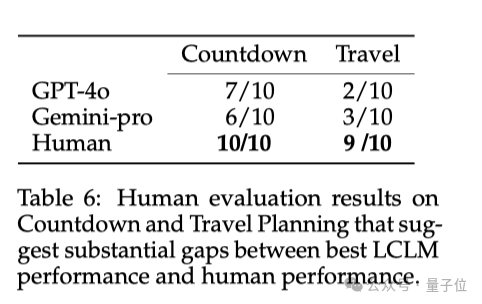
從表6的結果中可以看出,與人類能力相比,當前模型還存在顯著差距。
人類在Countdown遊戲和旅行規劃任務中分別解決了10個和9個問題,而最好的模型GPT-4o分別只解決了7個和3個問題。
總體來說,本論文提出的LONGPROC測試基準有效地評估了模型在長程序生成任務方面的表現,是對現有基準的一個補充。
實驗發現,即使是最先進的模型,在生成連貫的長段內容方面仍然有很大的改進空間。
尤其是在要求輸出8k tokens的任務中,參數較大的先進模型也表現不佳,這可能是未來LLM研究的一個非常有意義的方向。
一作是清華校友
這篇論文的一作是本科畢業於清華軟件學院的Xi Ye(葉曦),之後從UT Austin計算機科學係獲得了博士學位。
清華特獎得主Tianyu Gao(高天宇)也有參與這篇論文:

據一作Xi Ye的個人主頁顯示,他的研究主要集中在自然語言處理領域,重點是提高LLM的可解釋性並增強其推理能力,此外他還從事語義解析和程序綜合的相關工作。
目前他是普林斯頓大學語言與智能實驗室(PLI)的博士後研究員,還將從 2025 年 7 月開始加入阿爾伯塔大學(University of Alberta)擔任助理教授。
PS:他的主頁也正在招收25屆秋季全獎博/碩士生哦
參考鏈接:
[1]https://arxiv.org/pdf/2501.05414
[2]https://xiye17.github.io/



















