科幻「巴別魚」真來了?AI實現人類101種語言語音互譯
《銀河系漫遊指南》中的神奇「巴別魚」,賦予了人們瞬間跨越語言鴻溝的能力,是無數人心中「高效語言交流」的終極形式。
如今,我們距離實現這一夢想或許不遠了。
就在今天,權威科學期刊 Nature 報導了由 Meta 開發的開源多語言、多模態機器翻譯模型 SeamlessM4T,其突破性地實現了 100 多種語言在語音-語音、語音-文本和文本-語音方面的高效翻譯,為全球語言溝通帶來了新的可能。

具體而言,SeamlessM4T 能夠接受這些語言中的任何一種的文本或語音輸入,並將其翻譯為文本,還可以直接將語音翻譯為 36 種語言的語音。
不僅如此,SeamlessM4T 在處理語音到文本任務時,抵禦背景噪音和適應說話者變化的能力也比其他系統平均高出約 50%,展現出強大的魯棒性。
對此,塔林理工大學語言處理教授 Tanel Alumäe 在評論文章中表示,「作者利用現實世界數據的方法將為語音技術開闢一條充滿希望的道路,有望與科幻作品中的技術相媲美。」
他還寫道,「這項工作最大的優點並非提出的想法或方法,而是運行和優化該技術的所有數據和代碼都可公開獲取,儘管模型本身僅可用於非商業用途。研究人員將他們的翻譯模型描述為‘基礎模型’,這意味著它可以在精心策劃的數據集上進行微調,以實現特定目的,例如提高某些語言對或專業術語的翻譯質量。」
當前,在這項研究的基礎上,Meta 基於 UnitY2 架構,運用層級字符到單元的上采樣和非自回歸文本到單元的解碼方法,訓練出了改進版本 SeamlessM4T V2,在保持高準確率的同時,加快了生成語音和文本翻譯結果的速度。
AI 正在打破人類語言壁壘
儘管當前的機器翻譯技術已經取得顯著進展,但大多局限於文本翻譯,語音到語音翻譯(S2ST)面臨諸多挑戰。
現有的多語種翻譯系統通常依賴於級聯繫統,通過多個子模型串聯完成複雜任務,不僅翻譯效率低,而且主要適應於少數幾種語言,在面對背景噪音和說話人變化等不穩定因素時,魯棒性不足。
為瞭解決這些問題,SeamlessM4T 應運而生。該模型基於 SONAR 多語言和多模態嵌入空間架構,將語音、文本的處理能力有效結合,並通過海量原始語音和文本數據自動挖掘對齊資源,實現了翻譯的準確性和流暢性提升。
另外,研究團隊還採用自監督和半監督學習方法訓練模型,使其能從大量原始數據中學習,減少了對人工特定標籤的依賴。
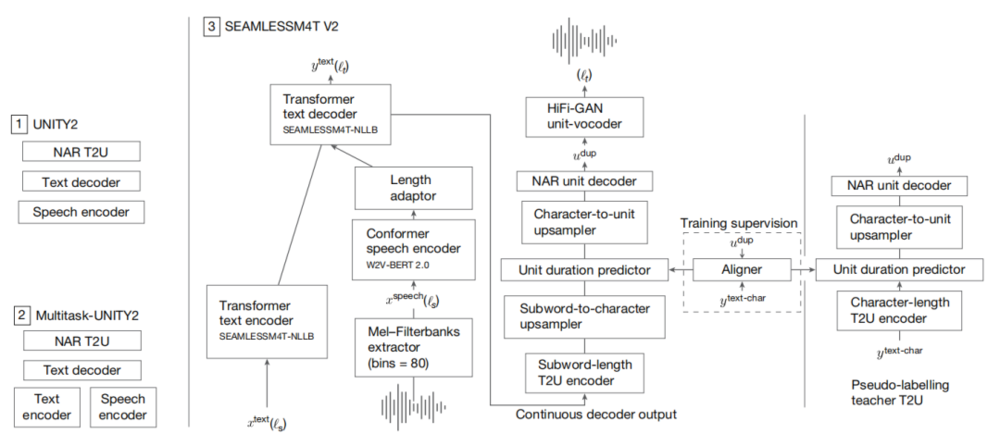 圖 | SEAMLESSM4T-V2 系統架構
圖 | SEAMLESSM4T-V2 系統架構在數據層面,SeamlessM4T 通過新的語言識別(LID)模型識別 100 多種語言。在研究過程中,Meta 團隊基於 SONAR 嵌入空間為 200 種語言提供了單一的文本編碼器和解碼器,並為 37 種語言提供了語音編碼器,且通過文本到文本翻譯(T2湯臣)任務,證明注意力機制並非實現合理翻譯準確率的必要條件。利用 SONAR 的文本和語音編碼器,Meta 團隊挖掘出三種對齊數據,構建了涵蓋 37 種語言、時長超 47 萬小時的 SeamlessAlign 語料庫。
SeamlessM4T 在多個翻譯任務中的表現顯著超過了傳統的級聯模型,在語言覆蓋和任務處理速度等方面優勢顯著。與 AudioPaLM、WHISPER 等大型語音理解和生成模型相比,SeamlessM4T 優勢明顯。
在語音到文本翻譯(S2湯臣)任務的 X-eng 方向,SeamlessM4T-V2 的 BLEU 得分比傳統級聯繫統提高了 4.6 分,性能提升顯著;對比 AudioPaLM 2 – 8B AST 等直接 S2湯臣 模型,提高了 6.9 分,展現出其在多語種翻譯中的強大優勢。
在語音到語音翻譯(S2ST)任務中,SeamlessM4T-LARGE 比兩階段級聯模型的 ASR-BLEU 得分高出 8 分,改進以後的SeamlessM4T-V2 進一步提升了 3.9 分,顯著領先於其他同類系統。
在語音到文本翻譯的 CVSS 任務中,SeamlessM4T – V2 相較於兩階段級聯模型,ASR – BLEU 得分提高了 9.6 分。
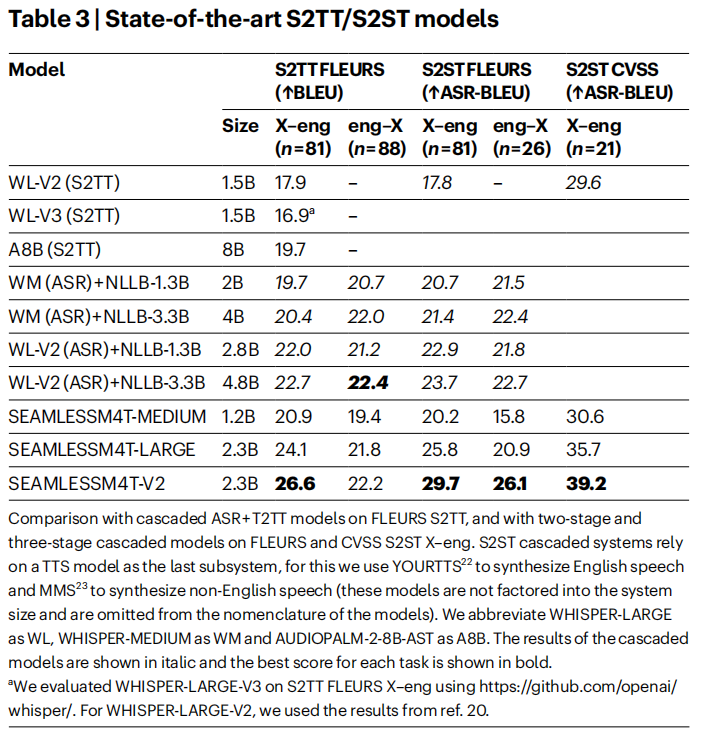 圖 | SOTA 語音到文本翻譯/語音到語音翻譯模型
圖 | SOTA 語音到文本翻譯/語音到語音翻譯模型在零樣本文本到語音翻譯(T2ST)任務中,SeamlessM4T – LARGE V2 部分語言方向的表現與級聯模型相當,甚至更優,體現了模型強大的通用性和靈活性。
這表明,SeamlessM4T 在沒有訓練數據的情況下,仍然能夠提供準確的翻譯結果,進一步提升了模型的通用性和靈活性。
SeamlessM4T 在抗噪聲和適應說話人變化方面也實現了技術突破。在背景噪音和說話人變化的實驗中,SeamlessM4T – V2 比 WHISPER – LARGE – V2 的表現提升近 50%。
在語音到語音翻譯任務中,SeamlessM4T – V2 抗背景噪聲能力提高 42%,對說話人變化的適應性提升 66%。這些改進使 SeamlessM4T 在嘈雜環境等實際應用場景中,仍能保證高效、精確的翻譯表現。
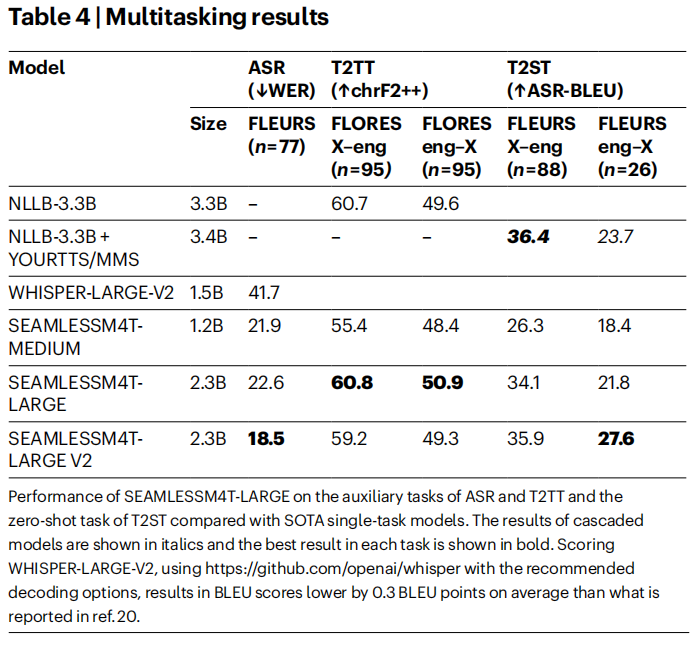 圖|多任務處理結果
圖|多任務處理結果此外,隨著 AI 技術的廣泛應用,機器翻譯模型中的毒性和偏見問題備受關注。Meta 團隊對 SeamlessM4T 進行了嚴格的毒性和性別偏見評估,並採取了緩解措施。
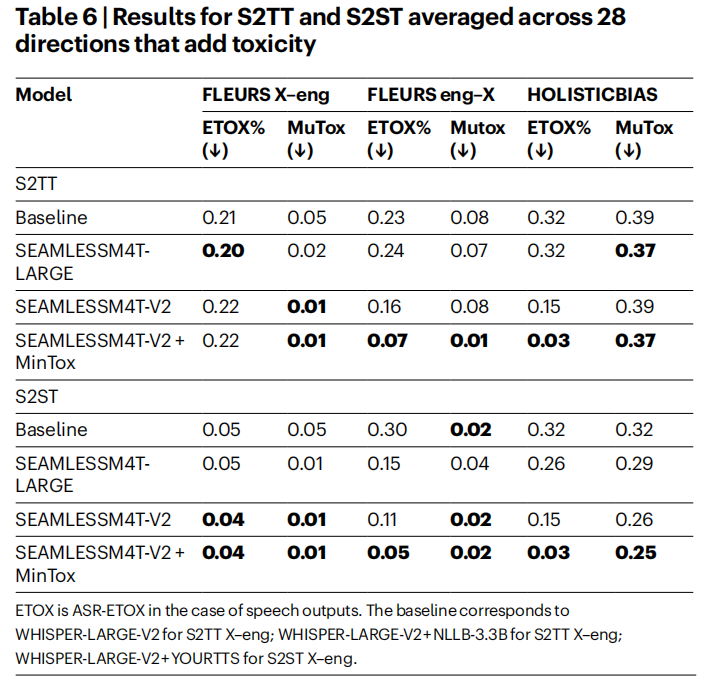 圖 | 語音到文本翻譯和語音到語音翻譯在添加了毒性考量的 28 種語言方向上的平均結果
圖 | 語音到文本翻譯和語音到語音翻譯在添加了毒性考量的 28 種語言方向上的平均結果在毒性檢測方面,他們採用 ETOX、MuTox 和 Mintox 等工具,排除訓練中的有害數據,減少模型產生有毒輸出的概率,為用戶提供健康的交流環境;在性別偏見方面,研究團隊通過 BLASER 2.0 等工具對 SeamlessM4T 進行檢測和優化,SeamlessM4T 在處理性別變化時比之前版本表現出更強的魯棒性,尤其是在 S2ST 任務中的性別變化魯棒性顯著提升。
警惕潛在風險
儘管 SeamlessM4T 已經可以翻譯約 100 種語言,但仍然存在一些局限性。
世界上約有 7000 種語言,該工具在許多人類易處理的場景中仍面臨困難。而且,在實際應用中,SEAMLESSM4T 系統的 ASR 性能受用戶性別、種族、口音和語言差異影響,導致識別和翻譯不準確,限制了其在多元化人群中的應用。
在處理俚語和專有名詞時,該系統在不同資源程度語言中的翻譯質量參差不齊;在實時交互場景中,由於語音交流對即時反饋要求高,用戶難以評估輸出質量,誤譯或毒性內容風險較高,且無法像書面交流那樣修改。同時,語音的韻律和情感信息在當前系統輸出中未得到充分體現,影響信息準確傳達。
研究人員表示,未來將進一步研究語音的韻律和情感,讓翻譯後的語音輸出更加自然生動。另一方面,低延遲語音翻譯和流式翻譯技術成為關鍵突破點,低延遲可減少翻譯時間差,使交流更流暢。
在評論文章中,康奈爾大學助理教授 Allison Koenecke 則從安全方面提出了擔憂,「基於語音的技術越來越多地用於高風險任務,例如在醫療檢查中做筆記或轉錄法律程序,像 Meta 團隊開發的模型正在加速這一領域的進展。但是,這些模型的用戶(例如醫生和法庭官員)以及提供語音輸入的個人,都應該意識到語音技術的易錯性。」
Koenecke 提到,鑒於現有模型的性能在不同語言之間差異很大,必須格外小心,以確保模型能夠熟練翻譯或轉錄某些語言中的特定術語。這方面的努力應與計算機視覺研究人員的工作同步進行,後者正在努力改善圖像識別模型在代表性不足群體中的不佳表現,並防止模型做出冒犯性預測。
此外,她還認為,未來有必要運用以設計為導向的思維,確保用戶能夠正確理解這些質量參差不齊的模型所提供的翻譯。開發者還應該考慮如何告知模型的局限性。這可能包括在準確性存疑時完全放棄輸出,或者為低質量的輸出配上書面警告或視覺提示。也許最重要的是,如果用戶願意,他們應該能夠選擇不使用語音技術,如在醫療或法律環境中。
參考鏈接:
https://www.nature.com/articles/s41586-024-08359-z
https://www.nature.com/articles/d41586-024-04095-6
本文來自微信公眾號:學術頭條,作者:田小婷