DeepSeek砍掉英偉達台積電5萬億市值!登五大外媒頭版,OpenAI急得發預告
矽谷地震,華爾街變天。
作者 |ZeR0
編輯 |漠影
一隻藍色鯨魚,正在矽谷和華爾街掀起海嘯。
智東西1月28日報導,震動美股的「國產AI之光」DeepSeek,在瘋狂霸屏主流美媒頭版、令美股科技股血流成河後,今日乘勢追擊——發佈全新開源多模態AI模型Janus-Pro!
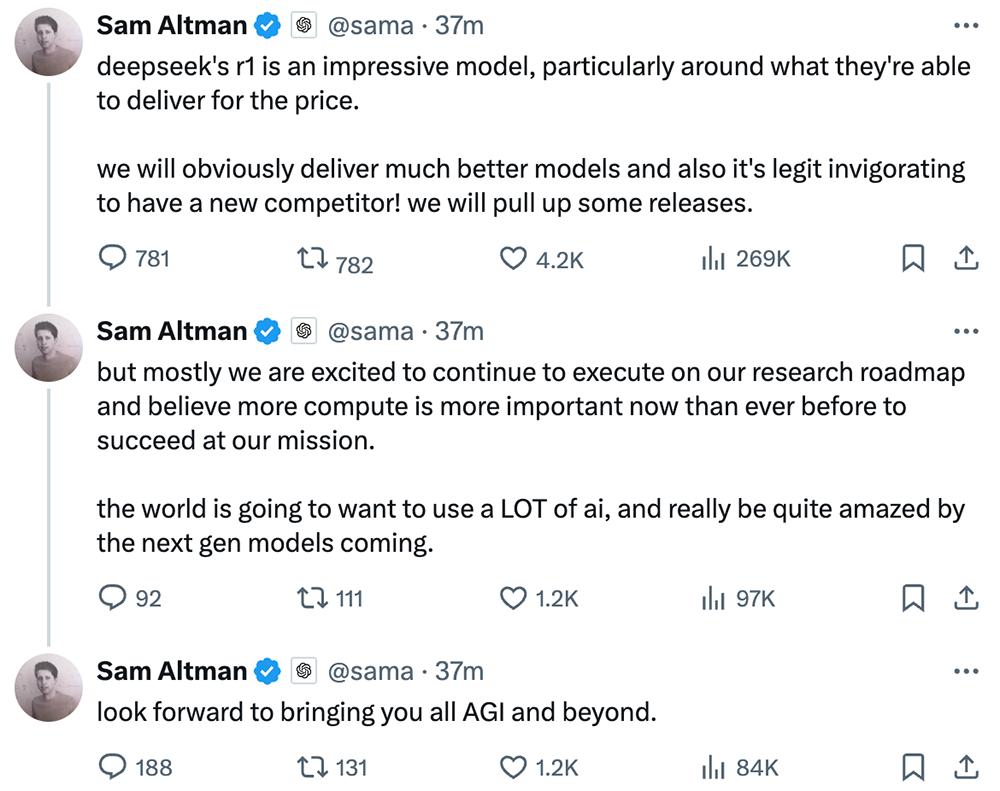
OpenAI顯然也感受到DeepSeek帶來的壓力。今日,OpenAI聯合創始人兼CEO Sam Altman連發多條推文,難得公開誇讚DeepSeek R1,稱這是一款「令人印象深刻的模型」。接著他給自家模型打廣告,說OpenAI將推出更好的模型,而且會繼續執行原有路線圖,相信更多計算比以往任何時候都更重要。
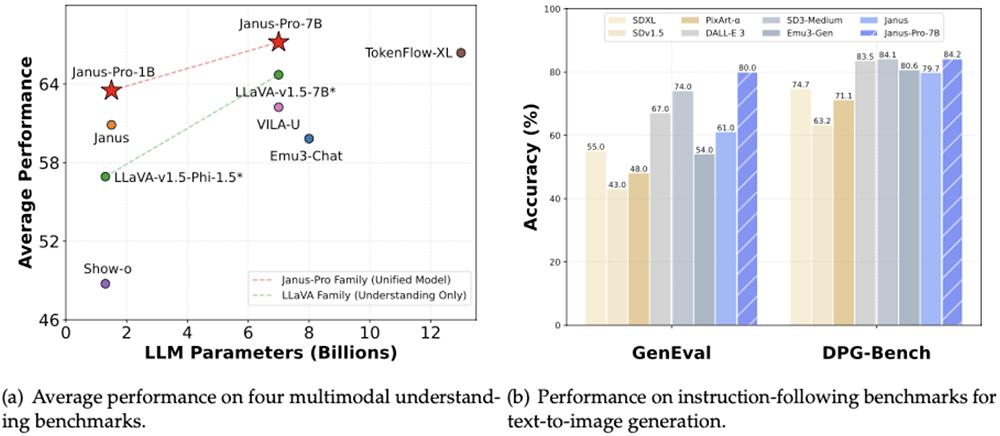
根據DeepSeek披露的信息,新開源模型Janus-Pro-7B在GenEval和DPG-Bench基準測試中,性能擊敗OpenAI DALL-E 3和Stable Diffusion。這顯然又戳中了業界的興奮點,網民們在社交平台發出各種梗圖。其中一張圖給GPT-5打了個大紅叉,在巨鯨身上放了個大大的DeepSeek logo。

此前DeepSeek新模型R1的發佈,憑藉前所未有的高性能和成本效益,徹底坐實了「國產AI價格屠夫」的標籤,令整個矽谷驚慌失措,業界對美國科技巨頭重資砸向AI基礎設施的必要性產生質疑。(突發!DeepSeek暴擊美股,讓整個矽谷坐立不安)
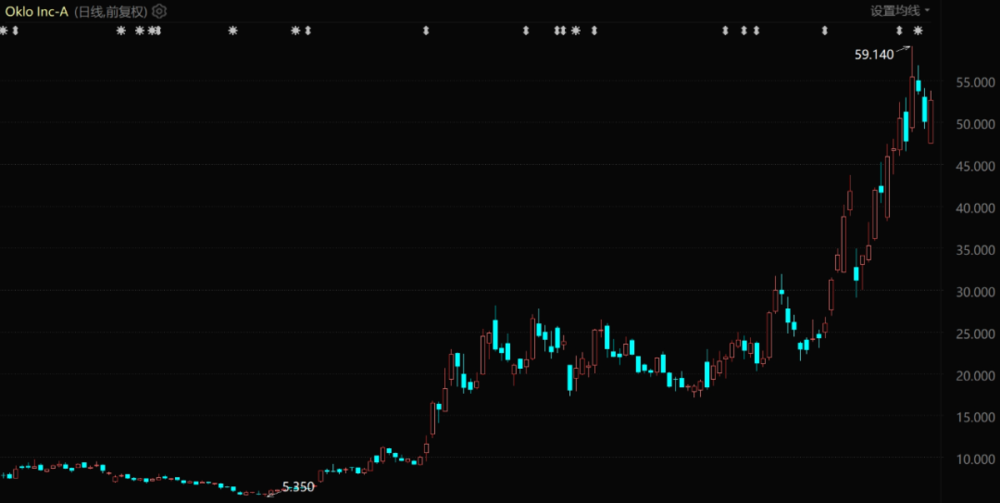
隨著影響力快速發酵,DeepSeek登頂中美等多國App Store免費榜。受DeepSeek衝擊美股影響,英偉達昨日股價暴跌17%,收於118.42美元/股,市值蒸發近6000億美元(折合人民幣近4.35萬億元)。一天之內,排名彭博億萬富豪榜第15名的英偉達創始人兼CEO黃仁勳財富縮水201億美元(約合人民幣1458億元)。
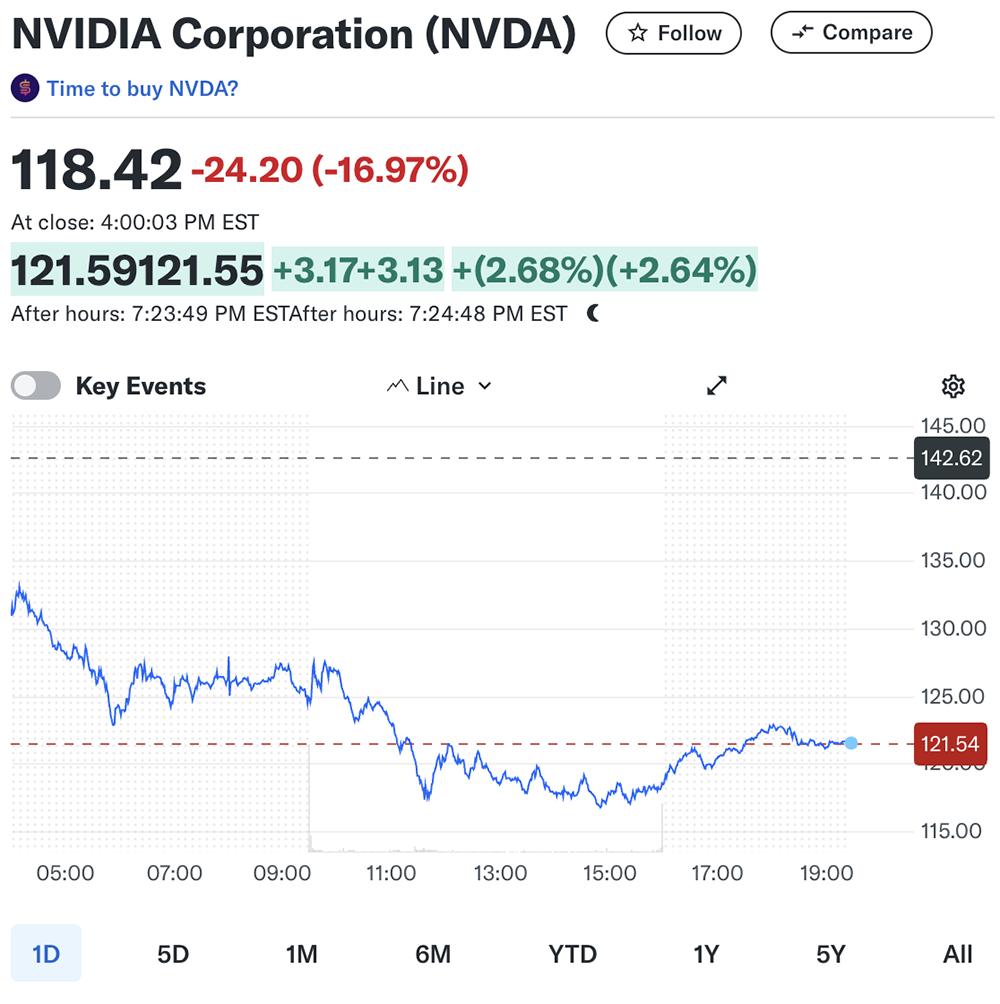
其晶圓代工供應商台積電的市值也在昨日蒸發了1508億美元(約合人民幣1.09萬億元)。等於DeepSeek作為「AI界拚多多」,一刀「砍掉」了英偉達和台積電共超5萬億元市值,實屬罕見。
美股科技股、芯片股均受重挫,諾斯達克100指數下跌3.1%,標普500指數下跌1.5%,微軟下跌2.14%,Google母公司Alphabet下跌4.03%,博通下跌17.40%,台積電下跌13.33%,ASML下跌5.75%,為AI基礎設施提供電氣硬件的西門子能源下跌20%,電力產品製造商施耐德電氣下跌9.5%……對AI競賽並不熱衷的蘋果則安然無恙,在一眾暴跌的科技股中逆勢上漲3.2%,重返全球市值第一。
幾乎各大主流美媒的網站頭版都是針對DeepSeek的報導,這十分少見。

隨著以閃電速度陸續開源高質量新模型,DeepSeek在全球科技圈引起的轟動效應還在持續擴大。
新發佈的Janus-Pro有1B和7B兩款尺寸,能輸出生成高質量的AI圖像,一如既往開源、免費、可商用。13頁技術報告已經公開。
「Janus-Pro超越了之前的統一模型,達到甚至超過了特定任務模型的性能。」DeepSeek在一篇文章中寫道,「Janus-Pro的簡單性、高靈活性和有效性使其成為下一代統一多模態模型的有力候選者。」

網民們已經在社交平台上積極曬出對Janus-Pro-7B的體驗。總體來看,Janus-Pro-7B的信息理解基本準確,生成圖像很完整,在局部細節上相對有欠缺。

以下是DeepSeek最新多模態理解和生成模型Janus-Pro的技術解讀:

根據技術報告,Janus-Pro是前作Janus的升級版,結合了優化的訓練策略、擴展的訓練數據,並擴展到更大的模型尺寸,在多模態理解和文本到圖像的指令遵循能力方面都取得了顯著進步,同時也增強了文生圖的穩定性。

技術報告:
https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf
Janus-Pro只能分析解像度至多384 x 384的小圖像。但考慮到模型尺寸很小,其性能令人印象深刻,相比前代輸出了更好的視覺質量、更豐富的細節,並具備生成簡單文本的能力。

對於富有想像力和創造性的場景,Janus-Pro-7B能夠從提示中準確捕獲語義信息,產生合理和連貫的圖像。

Janus-Pro 1B模型更適合需要緊湊高效的AI任務,比如在消費級硬件上做輕量化部署。這款模型同樣在GenEval等基準測試中取得了較高的平均性能,證明它能夠以更少資源在指令遵循和圖像分析上表現出色。
此前一些統一多模態理解和生成模型方法已被證明可以增強視覺生成任務中的指令遵循能力,同時減少模型冗餘。它們大多使用相同的視覺編碼器來處理多模態理解和生成任務的輸入。由於兩個任務所需的表示不同,這通常會導致多模態理解中的次優性能。
為瞭解決這個問題,Janus提出瞭解耦視覺編碼,將視覺理解與圖像生成任務分開,確保兩個任務不會互相干擾,從而在多模態理解和生成任務中都取得了優異的性能。Janus在1B參數尺寸上進行了驗證,但受限於訓練數據量和相對較小的模型容量,它表現出一定的缺點,例如短提示圖像生成的性能不理想、文生圖質量不穩定。
Janus-Pro則是Janus的增強版,著重改進了訓練策略、數據和模型大小。新模型遵循一款自回歸框架,解耦了多模態理解和視覺生成的視覺編碼。研究團隊採用獨立的編碼方法將原始輸入轉換為特徵,然後由統一的自回歸Transformer進行處理。

其實驗使用最大支持序列長度為4096的DeepSeek大模型(1.5B和7B)作為基礎模型。

對於多模態理解,研究人員使用SigLIP-Large-Patch16-384編碼器從圖像中提取高維語義特徵,將這些特徵從二維網格平展到一維序列,並使用理解適配器將這些圖像特徵映射到大語言模型的輸入空間中。
對於視覺生成任務,研究人員使用VQ tokenizer將圖像轉換為離散ID,在將ID序列平面化為1-D後,使用生成適配器將每個ID對應的碼本嵌入映射到大語言模型的輸入空間中,然後將這些特徵序列連接起來形成一個多模態特徵序列,隨後將其輸入大語言模型進行處理。
除了大語言模型中內置的預測頭外,研究人員還在視覺生成任務中使用隨機初始化的預測頭進行圖像預測。
前代Janus模型採用了三階訓練過程:第一階段的重點是訓練適配器和圖像頭,第二階段是使用多模態數據做統一預訓練,第三階段是進行監督微調。這種方法使Janus能夠勝過更大的模型,同時保持可管理的計算佔用空間。但經實驗,其策略會導致大量計算效率低下。

為此DeepSeek做了兩處修改:一是增加第一階段的訓練步驟,允許在ImageNet數據集上進行足夠的訓練;二是在第二階段,放棄ImageNet數據,直接利用正常的文生圖數據來訓練模型,以基於密集描述生成圖像。這種重新設計的方法使第二階段能夠更有效地利用文本到圖像的數據,從而提高訓練效率和整體性能。
研究人員還調整了第三階段監督微調過程中不同類型數據集的數據比例,將多模態數據、純文本數據和文本到圖像數據的比例從7:3:10更改為5:1:4,使模型在保持出色視覺生成能力的同時,實現改進的多模態理解性能。
Janus-Pro將模型大小擴展到7B。當使用更大規模的大語言模型時,與較小的模型相比,多模態理解和視覺生成的損失收斂速度都有顯著提高。該發現進一步驗證了這個方法的可擴展性。

研究人員在訓練過程中使用序列打包來提高訓練效率,在單個訓練步驟中根據指定的比例混合所有數據類型。Janus使用輕量級高效分佈式訓練框架HAI-LLM進行訓練和評估。對於1.5B/7B模型,在16/32個節點的集群上,每個節點配備8個英偉達A100 (40GB) GPU,整個訓練過程大約需要7/14天。
DeepSeek在多個基準上對Janus-Pro進行了評估,結果顯示了出色的多模態理解能力和顯著提高的文生圖指令遵循性能。

比如Janus-Pro-7B在多模態理解基準MMBench上獲得了79.2分,超過最先進的統一多模態模型;在文生圖指令遵循基準測試GenEval中,Janus-Pro-7B得分為0.80,超過Janus、Stable Diffusion 3 Medium、DALL-E 3、Emu3-Gen、PixArt-alpha等先進圖像生成模型。

總體來看,Janus-Pro在訓練策略、數據、模型大小上的改進,使其取得多模態理解和文生圖指令遵循能力的進步。該模型仍存在一定的局限性,例如在多模態理解方面,輸入解像度限制為384 ×384會影響其在細粒度任務(如OCR文本識別)中的性能。
對於文生圖,低解像度加上視覺tokenizer帶來的重建損失,導致圖像雖然具有豐富的語義內容,但仍然缺乏精細的細節。例如,佔用有限圖像空間的小面部區域可能顯得不夠精細。技術報告指出,提高圖像解像度可以緩解這些問題。
本文來自微信公眾號「智東西」(ID:zhidxcom),作者:ZeR0,36氪經授權發佈。