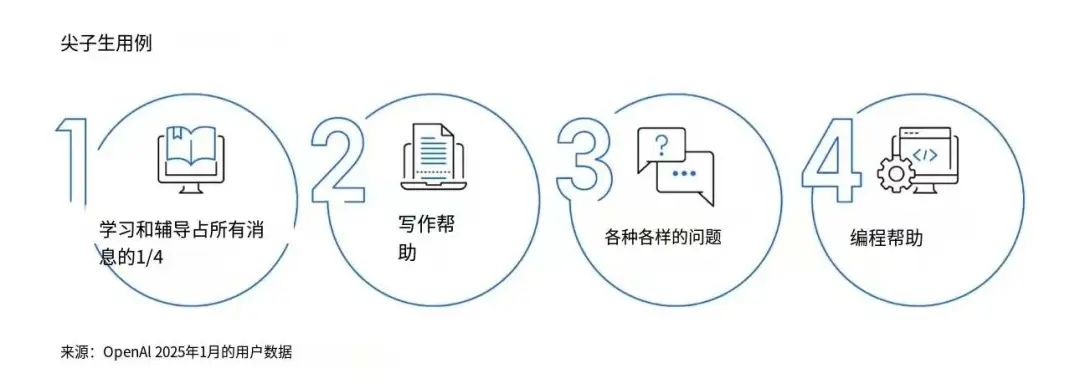
27頁綜述,354篇參考文獻!最詳盡的視覺定位綜述來了
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

-
論文題目:Towards Visual Grounding: A Survey
-
工作內容:視覺定位(Visual Grounding)任務十年發展系統性回顧
-
論文鏈接:https://arxiv.org/pdf/2412.20206
-
代碼 / 倉庫鏈接:https://github.com/linhuixiao/Awesome-Visual-Grounding.
-
作者:肖麟慧(中國科學院自動化研究所,中國科學院大學)
27 頁綜述,354 篇參考文獻!史上最詳盡的視覺定位綜述,內容覆蓋過去十年的視覺定位發展總結,尤其對最近 5 年的視覺定位論文系統性回顧,內容既涵蓋傳統基於檢測器的視覺定位,基於 VLP 的視覺定位,基於 MLLM 的視覺定位,也涵蓋從全監督、無監督、弱監督、半監督、零樣本、廣義定位等新型設置下的視覺定位。
視覺定位任務新入門必讀!跟進最新進展,視覺定位審稿人必讀論文!
一、論文摘要
視覺定位(Visual Grounding)也被稱為指代表達文本理解(Referring Expression Comprehension)和短語定位(Phrase Grounding)。它涉及根據給定的文本描述在圖像中定位自然數量的特定區域。該任務的目標是模擬社會對話中普遍存在的指代關係,使機器具有類似人類的多模態理解能力。因此,視覺定位在各個領域有著廣泛的應用。然而,自 2021 年以來,視覺定位取得了重大進展,比如,基於定位的預訓練、定位多模態大語言模型、廣義視覺定位、多圖片定位、千兆像素定位等新概念不斷湧現,帶來了許多新的挑戰。在本綜述中,我們首先回顧了視覺定位的發展歷史,並概述了基本的背景知識,包括視覺定位的基本概念和評估指標。我們系統地跟蹤和總結了當前視覺定位的發展,並精心整理了各種已有的設置,並建立了這些設置的精確定義,以規範未來的研究並確保不同方法之間公平的比較。此外,我們深入討論了幾個高級話題,並強調了視覺定位的許多應用。在數據集部分,我們編製了當前相關數據集的列表,同時在 RefCOCO/+/g 系列數據集上進行了公平的比較分析,並提供了最終的性能預測,以啟發未來新的標準測試基準的提出。最後,我們總結了視覺定位當前所面臨的挑戰,並為未來的研究提出有價值的方向,這可能為後續的研究人員提供啟發。本綜述通過提取常見的技術細節的方式進行敘述,進而以涵蓋過去十年中每個子主題的代表性工作。據我們所知,本文是目前視覺定位領域最全面的綜述。本文不僅使適用視覺定位的入門研究者,也適用於資深的研究人員用於跟蹤最新的研究進展。
二、視覺定位任務介紹、發展歷史和研究現狀
人工智能領域中,視覺感知和自然語言理解的多模態融合學習已經成為在機器中實現類人認知的關鍵。其核心是視覺和語言線索的融合,旨在彌合圖像場景與語言表達之間的語義鴻溝。而視覺定位,代表了這樣一種基本的目標,其包括人工智能模型在語言描述和相應的視覺元素之間建立內在聯繫的能力。

圖 1. 視覺定位任務簡要示意圖
圖 1 是視覺定位的簡要的示意圖。視覺定位(Visual Grounding),也被稱作指代表達理解(Referring Expression Comprehension),依據傳統的定義,是指在一副圖像中依據一個給定的指代表達句子定位出一個具體的區域。這一任務的目的是模擬社交對話中最常見的指代關係,使機器具備類人的多模態理解能力。因此,他可以廣泛應用於人機對話、視覺語言導航、視覺問答當中。
數據、算法、算力是當今深度學習不斷進化的三大要素,對於視覺定位來說也不例外。從數據的角度上看,定位任務涉及了三種基本數據,即,圖像,指代表達文本,以及指代的邊界框,同時,這三種數據需要構成配對的三元組數據對。在這三種數據中,圖像是比較常見的,然而,指代表達文本和配對的邊界框卻並不容易獲取。第一,視覺定位作為指代表達生成(Referring Expression Generation,REG)的逆過程,獲得指代表達文本數據是視覺定位的基礎,因此早期的視覺定位受 REG 任務的影響比較大。雖然指代表達在日常對話中無處不在,但獲取有價值的指代表達並不是易事。類似於圖像描述(Image Captioning)生成,作為一個經典的 NLP 問題,大概從 1970 年代起,就有大量的關於區域信息描述的指代表達生成的工作出現。在 1975 年,Paul Grice 提出自然語言對話交互的合理性原則,稱之為 Gricean Maxims。這一準則對應到真實複雜場景下描述一個物體時,則需要滿足三點:信息性,簡潔,和不模糊性(informative, concise, and unambiguous)。其中,不模糊性(unambiguous)對於指代表達文本來說是尤其重要的,因為在真實的場景中通常會存在許多同類別的物體。如果表達不具備不模糊性,那模型並不能從數據中學到有價值的信息,反而會使模型產生困惑。因此,在獲得有效的不模糊性表達之前,視覺定位模型都難以進行學習。正因為此,如圖 6 所示,在 204 年之前,大量的工作都主要集中在指代表達生成上,而很少專注於定位的工作出現。第二,配對的邊界框同樣也是耗費人力的標註信息。在 2013 年之前,由於缺乏與指代表達句子配對的邊界框,大量的工作都以弱監督的設置為主。在 2014 年,隨著 Kazemzadeh 等人提出了第一個基於真實世界圖片的大規模指代表達理解的數據集 ReferIt Game,全監督的視覺定位才逐步面向更真實的場景。然而,由於 ReferIt Gmae 數據集的圖片中的類別較為單一、指代文本太過簡單,從而難以滿足不模糊性的要求。因此,在 2016 年,Mao 等人基於 MS COCO 圖像數據集提出了 RefCOCOg 數據集。由於該數據集存在驗證集和訓練集圖片泄露的問題,在同年,Nagaraja 等人對該數據集進行重新劃分為 RefCOCOg-umd 數據集。在 2016 年同年,Yu 等人同樣基於 MSCOCO 提出了 RefCOCO 和 RefCOCO + 數據集。

圖 2. RefCOCO/+/g 數據集差異對比及統計信息
如圖 2 為 RefCOCO/+/g 數據集的差異對比及統計信息樣例。其中,RefCOCO 以簡單的空間方位關係為主(如,左右、前後),RefCOCO + 中禁止使用空間方位詞而更關注物體的外觀(如,顏色、大小等),RefCOCOg 則使用更為複雜的句子。RefCOCO/+/g 這三個數據集的出現奠定了後續視覺定位任務的堅實基礎,同時也成為後續近十年來的標準基準。從那以後,大量的視覺定位工作開始噴湧而出。
隨著時間的推移,在 2021 年,Kamath 等人將主流的細粒度檢測數據集進行混合,同時將定位任務作為一個調製的檢測任務,定位的預訓練數據得到進一步的擴大,從而使得視覺定位的性能有了進一步的提升。隨後,隨著 2021 年預訓練範式的出現(如,VLP 和 MLLMs),近些年也湧現出了更大規模的細粒度數據集,如 GRIT 等,不斷的推進視覺定位任務走向新的高峰。

圖 3. 視覺定位的五種技術路線及近十年發展中的幾個主要階段
從算法和算力的角度,視覺定位的研究在受深度學習主流算法和算力的影響也在不斷的演化。如圖 3 所示,依據深度學習算法的發展,我們大致可以將視覺定位的研究分成三個階段,2014 年以前為初期,2014 年至 2020 年為早期,2021 至今為高速發展的時期。在 2014 年以前,視覺定位作為一個驗證任務用於輔助 REG,那時還並未成體系。那時的方法主要是通過一些 NLP 語言解析的手段在弱監督的設置下對 proposal 進行選擇。在 2014 至 2020 年期間,視覺定位在算法上主要是通過以小規模的 LSTM 網絡對語言進行編碼,通過 CNN 網絡對圖像進行編碼,再基於二階段或一階段方式實現定位結果。已有的綜述中,Qiao 等人對此時期的工作在方法上進行了總結。然而,在 2021 年之後,隨著 Transformer 的提出,LSTM 和 CNN 方法逐漸被摒棄。同時,隨著預訓練模型的發展,預訓練再微調成為下遊遷移的基礎範式。此時,單模態預訓練模型(如 Bert,DETR 等)和多模態預訓練模型(如,CLIP)開始應用在視覺定位當中。在此期間,各種各樣的設置,如全監督、弱監督、零樣本等等,開始湧現。此外,隨著算力的突飛猛進,預訓練中的模型和數據越來越大,深度學習的尺度法則(Scaling Law)在視覺定位中也得到體現。在 2023 年,隨著大語言模型、多模態大語言模型在尺度規律的加持下表現出驚人的效果之後,定位多模態大語言模型(GMLLMs)如雨後春筍一般,在短短 1 年多時間湧現了大量的代表性工作,如 LION, Ferret 等等。

圖 4. 視覺定位任務近十年發展趨勢
如圖 4 所示為視覺定位任務這十年來在論文數量和 RefCOCO 數據集性能上的增長趨勢。視覺定位任務從 2014 以來,經歷了高速發展的近 10 年,其中論文數量上 2024 年論文比 2021 年增長了近 3 倍,同時數據集的性能也趨近於極限。儘管這一領域發展如此迅速,當前也積攢了許多的問題。首先,各種設置層出不窮、定義混亂。具體來說,由於視覺定位中三元組數據對獲取的複雜性,以及在各種預訓練模型的加持下,從 2021 年以來湧現了各種各樣的設置,包括全監督、無監督、半監督、弱監督、零樣本設置等等。然而,這些設置中,存在定義不清楚和設定混亂,從而產生許多不公平的比較。比如,全監督設置中,存在採用混合數據集預訓練的模型和單數據集微調的工作進行直接比較,採用大規模預訓練模型的工作直接和採用單模態檢測預訓練模型的工作進行直接比較。此外,弱監督設置常常被定義為零樣本設置,無監督設置和弱監督設置也存在定義模糊,等等問題。然而,這些問題至今沒有相關的工作對此有過系統的梳理和總結。第二,數據集受限,未來的發展方向不夠明確。具體來說,RefCOCO 系列數據集提出已近 10 年,當前依然是核心的評價基準。然而,這一數據集從性能上已經快接近極限,這導致新的工作的性能增益有限。同時,隨著大語言模型的出現,已有的數據集已經不能滿足基本任務的設定。比如說,現有的數據集是定位出一個物體,然而,某種程度上,依據視覺定位的概念,如圖 5 所示,數據集應該要滿足三種情況,即(1)定位 1 個物體、(2)定位多個物體、(3)定位無物體。

圖 5. 廣義視覺定位示意圖
第三、缺乏一個系統性的回顧,以便對已有的工作進行總結歸納,並對未來的發展做出指引。由於當前論文過多,導致大量最新的工作對已經存在的類似 idea 的工作都沒有進行充分的引用和對比,這些論文在投稿時審稿人也難以辨別優劣。Qiao 等人對 Visual Grounding 做了一個技術總結,然而,其總結的工作主要集中在 2019 年以前。從 2019 年至今,已經 5 年過去,多模態的研究局面已經發生了巨大的變化,視覺定位任務已經湧現了大量的工作,早已與此前的情況大不相同。因此,此時非常急迫需要有一篇視覺定位綜述對最近的工作做一個總結,並給未來的研究方向指明新的方向。
三、綜述流程
本文的提出,就是為了對視覺定位過去十年的發展做一個總結,並及時解決上述在視覺定位發展過程中累積的問題。圖 6 為該綜述的論文結構。

圖 6. 視覺定位綜述論文結構
具體來說,在該綜述中,在第 1 章簡要地回顧了視覺定位的發展歷史和當前存在的問題。在第 2 章中,研究者將介紹背景知識,包括基本的任務定義、評價標準和強相關的研究領域。除了圖 1 所示的經典視覺定位之外,作者還重點介紹了近期的一種新型設置:廣義視覺定位。如圖5所示,在廣義視覺定位的定義之下,定位任務打破了傳統一個文本必然定位一個物體的強假設限制,從而轉為需要定義自然數個物體(即,一個,多個,和零個物體)。

圖 7. 當前主流視覺定位設置差異對比示意圖
隨後,在第 3 章中,研究者將從任務設置的視角出發,分別從全監督、弱監督、半監督、無監督、零樣本、廣義視覺定位新型設置等 6 個方面對當前的研究進行系統性回顧,並比較了不同任務設置下基準測試的結果。圖 7 是當前主流視覺定位設置在監督信息上的差異對比示意圖。

圖 8. 傳統視覺定位中一階段和二階段處理流程對比

圖 9. 全監督視覺定位的五種代表性模型框架

論文表 2. 全監督視覺定位按三種實驗設置進行劃分的 SoTA 結果對比
在上述這些設置中,特別是全監督設置,其作為主流的設置在論文第 3 章中進行了重點介紹。在技術路線上,如圖 3 所示,作者將現有的技術路線分為 5 大類,分別是傳統基於 CNN 檢測器的方法,傳統基於 Transformer 的方法,基於 VLP 模型的方法,定位導向的預訓練方法,以及在 2023 年湧現的定位多模態大語言模型的方法。針對傳統基於 CNN 檢測器的方法,如圖 8 所示,作者首先介紹在傳統 CNN 時期的一階段視覺定位和二階段視覺定位的處理流程。隨後,如圖 9 所示,作者在這一章中,分析概括了現有全監督視覺定位的五種代表性模型框架(即,2 個模態編碼器 + 1 個融合編碼器,2 個模態編碼器 + 1 個融合編碼器 + 1 個解碼器,僅 2 個模態編碼器結構,單塔編碼器結構,以及當前的定位多模態大語言模型結構)。此外,如圖論文表 2 所示,作者還對現有的全監督設置在數據集的使用上劃分出四種實驗大類設置已進行公平的比較,分別是基於單模態預訓練的閉集檢測器和語言模型的單數據集微調,基於自監督多模態視覺語言預訓練模型的單數據集微調,基於多數據集混合的中間預訓練設置,以及定位多模態大語言模型。

論文表 5 零樣本視覺定位設置的 4 種子設置

圖 10. 全監督視覺定位、傳統零樣本視覺定位和開放詞彙零樣本視覺定位對比
在第 3 章節的零樣本部分,為了規範當前的研究,如論文表 5 所示,作者將零樣本設置分成 4 種情況,分別是(a)定位新類物體和未見過的名詞短語,(b)開放詞彙的視覺定位,(c)基於預訓練模型和已有 Proposal 情況下的免微調 / 免訓練學習,(d)在預訓練模型基礎上免 proposal 和免微調的直接定位。如圖 10 所示為全監督設置、傳統零樣本設置和開放詞彙視覺定位設置的語義示意圖。

圖 11. NLP 自然語言解析在視覺定位中的應用
隨後,作者在第 4 章討論了一些與設置無關的進階技術。包括 NLP 結構解析在視覺定位中的應用(如圖 11 所示),場景圖和圖神經網絡在視覺定位中的應用,以及模塊化定位技術等等。
在第 5 章中,作者介紹了視覺定位的一些應用場景,包括定位式物體檢測,指代定位計數,遙感視覺定位,醫療視覺定位,3D 視覺定位,影片物體定位,以及機器人和多智能體應用等等。
最後,作者在第 6 章中介紹了已有的經典數據集和新型定位數據集,在第 5 章指出當前的挑戰和未來的發展方向,並在第 6 章中進行了總結。
四、貢獻
這一綜述的貢獻可概括為如下五點:
-
(i) 本文是近五年來第一個系統跟蹤和總結近十年視覺定位發展的綜述。通過提取常見的技術細節,本綜述涵蓋了每個子主題中最具代表性的工作。
-
(ii) 本文根據視覺定位中出現的各種各樣的設置做了系統的梳理,並對各種設置做了嚴格的定義,用以規範後續視覺定位的研究,以便獲得公平公正的比較。
-
(iii) 本文對近些年的數據集進行了整理,並對視覺定位中五個經典的數據集進行了極限預測,以啟發新的標準基準的出現。
-
(iv) 本文對當前的研究難點進行了總結,並對後續的視覺定位的研究提供了有價值的研究方向,用以啟發後續研究者的思考。
-
(v) 據我們所知,這篇綜述是目前在視覺定位領域最全面的綜述。作者希望本文不僅可以助力於新手入門 Grounding,也希望可以幫助有一定研究基礎的人對當前的研究進行梳理,使他們能夠跟蹤並對最新的進展保持瞭解。
最後,由於視覺定位領域正在迅速發展,本文可能不可能跟上所有最新的發展。作者歡迎研究人員與他們聯繫,與他們分享在這一領域的新發現,以便本文可跟蹤最新進展。這些新的工作將被納入修訂版本並進行討論。同時作者也會更新和維護論文的項目倉庫:https://github.com/linhuixiao/Awesome-Grounding。