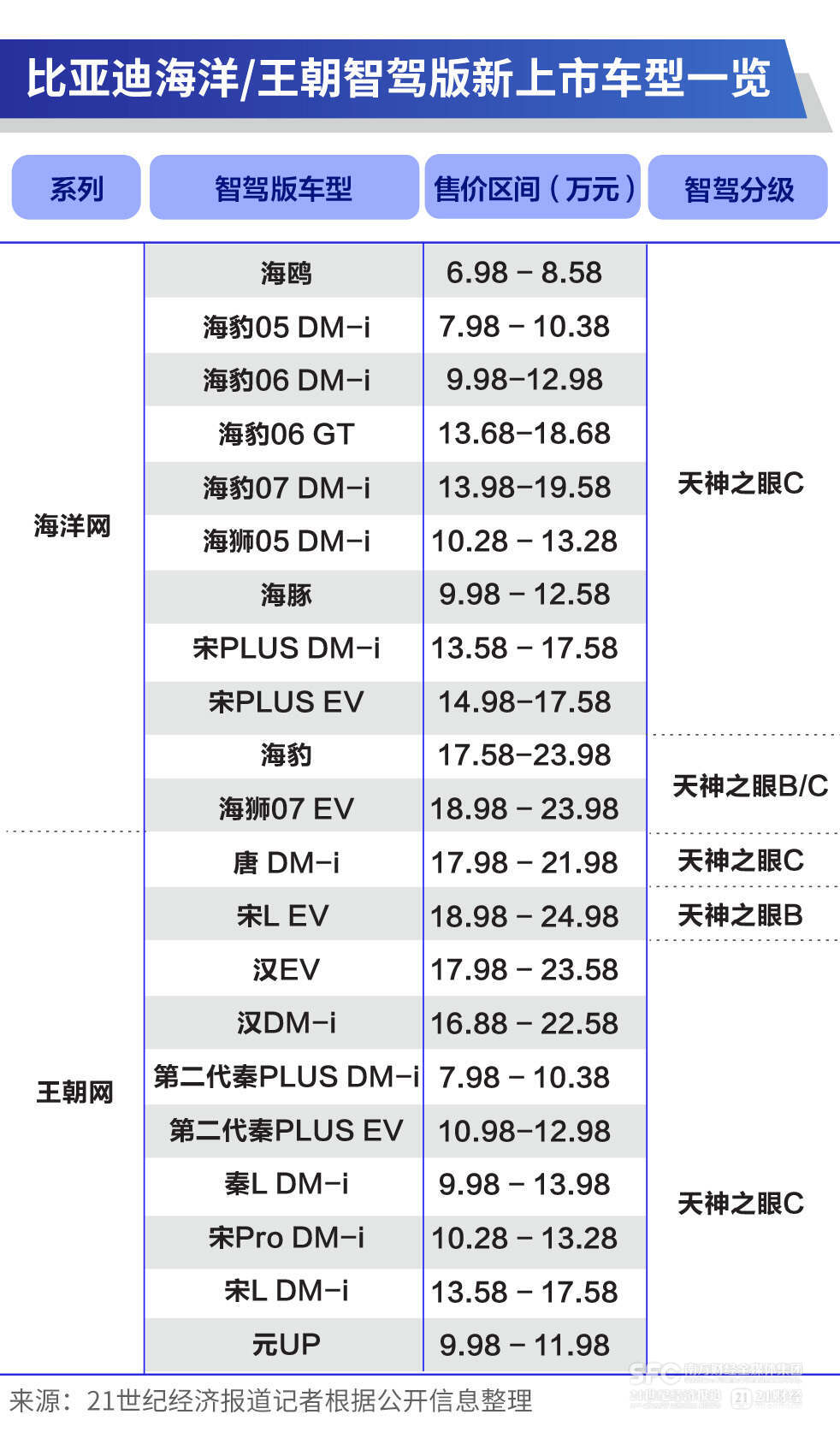
清華翟季冬:DeepSeek 百倍算力效能背後的系統革命 | 智者訪談
 題圖
題圖2025 年伊始,全球 AI 業界被 DeepSeek 刷屏。當 OpenAI 宣佈 5000 億美元的「星際之門」計劃,Meta 在建規模超 130 萬 GPU 的數據中心時,這個來自中國的團隊打破了大模型軍備競賽的既定邏輯:用 2048 張 H800 GPU,兩個月訓練出了一個媲美全球頂尖水平的模型。
這一突破不僅撼動了英偉達萬億市值,更引發了整個行業的反思:在通往 AGI 的征程上,我們是否過於盲信算力規模,而忽視了一條更加務實且充滿創新可能的路徑?
與 2023 年「更大即更好」的粗放發展觀不同,2025 年 AI 發展或將更像是一場精打細算的技術煉金:如何用最少的資源最大化模型效能,如何在特定場景實現極致效率。DeepSeek 已經展現出這種方式的威力——開發者總是傾向於選擇性價比更高的開源方案,當千千萬萬的應用都以 DeepSeek 為基座,由此構建的生態將如何重塑 AI 產業格局?
本期《智者訪談》邀請到清華大學計算機系長聘教授、高性能計算研究所所長翟季冬,深入探討大模型時代的 AI 算力優化之道。翟季冬教授指出,DeepSeek 實現百倍性價比提升的一個重要原因,是其在系統軟件層面的深度創新。
「性能優化是一個無止境的過程,」翟季冬教授表示,在中國面臨算力資源挑戰的背景下,通過系統軟件創新提升算力效能,是產業突圍的關鍵。這不僅需要在編程語言、編譯器、通信庫、編程框架等多個技術層面發力,更需要建立起完整的基礎軟件體系。
當下,一個值得深思的現像是:儘管 AI 算力需求持續攀升,但國內眾多智算中心的國產算力資源卻存在閑置。供需錯配的背後,暴露出基礎軟件體系的短板。
但困境也蘊含著重要機遇:如何打通從應用到系統軟件,再到自主芯片的完整鏈路,探索出一條符合中國現實的發展路徑?這不僅是技術創新,更是戰略抉擇。
在算力主導 AI 競爭力的時代,如何讓每一份計算資源都能釋放最大價值,這個問題本身,與答案同樣重要。
時間戳
03:35
DeepSeek 與算力需求未來趨勢
06:41
算力效能評估新視角
10:26
中美硬件差異下的軟件思考
14:00
為何還沒 Transformer 專用芯片
17:41
萬卡集群訓練難點
21:01
降本增效:推理優化的關鍵
24:41
Infra 如何為下一代大模型做好準備
27:19
大規模異構集群的算力管理
29:42
智算供需錯配:系統軟件如何補位
訪談文字整理
機器之心:翟季冬教授好,歡迎作客機器之心的《智者訪談》。最近在 AI 算力市場出現了很多新的趨勢。首先,大家討論非常多的,Scaling Law 是不是真撞牆了?其次,隨著 OpenAI o1/o3 模型的推出,通過增加推理計算時間也能夠帶來模型性能的顯著提升,這也讓我們重新思考,究竟要把算力用在哪裡。
可以看到,如何提升算力的利用效率,成為業界越來越關注的議題。非常高興能邀請到您,與我們一同從系統軟件的角度探討算力優化之道。
DeepSeek 的啟發:性能優化永無止境
翟季冬:謝謝主持人。非常榮幸來到機器之心做交流。Dr. Ilya Sutskever 在一次論壇上表示,我們所知的 Scaling Law 已經快走到終點。我認為這個問題分幾方面來看。首先,現在互聯網上高質量的文本數據的確是越來越少,但多模態數據(比如圖片、影片)還有很多挖掘空間,它們對未來模型訓練會產生非常大的影響。
第二,以 OpenAI o1/o3 為代表的複雜推理系統,在後訓練階段使用了強化學習(RL)等技術,RL 會生成大量新的數據,這也導致對算力的需求持續增長。第三,如今訓練一個基座模型,可能需要幾週乃至一兩個月的時間,如果有更多算力,幾天就能預訓練出一個好的模型,這也將極大地改變後期的生產效率。此外,對於終端的用戶來說,大家對性能,包括對精度的追求實際上是無止境的。
機器之心:DeepSeek 公司最近在業界引發廣泛討論,他們以較低成本訓練出了堪比國外頂尖水平的模型。從公開信息來看,您認為這裏的提升主要在哪裡?
翟季冬:首先是算法層次的創新。他們採用了新的 MoE 架構,使用了共享專家和大量細粒度路由專家的架構。通過將通用知識壓縮到共享專家中,可以減輕路由專家的參數冗餘,提高參數效率;在保持參數總量不變的前提下,劃分更多的細粒度路由專家,通過靈活地組合路由專家,有助於更準確和針對性的進行知識表達。同時,通過負載均衡的算法設計,有效地緩解了傳統 MoE 模型因負載不均衡帶來訓練效率低下的問題。
其次在系統軟件層次,DeepSeek 採用了大量精細化的系統工程優化。例如,在並行策略方面,採用雙向流水的並行機制,通過精細的排布,挖掘了計算和通信的重疊,有效的降低了流水並行帶來的氣泡影響;在計算方面,採用 FP8 等混合精度進行計算,降低計算複雜度;在通信方面,採用低精度通信策略以及 token 路由控制等機制有效降低通信開銷。
上述算法和軟件的創新與優化,極大地降低了模型的訓練成本。DeepSeek 給我們的啟示,更多在於如何在有限的算力情況下,通過算法和軟件的協同創新,充分挖掘硬件的極致性能,對中國發展未來人工智能至關重要。
從 DeepSeek 的成功可以看出,在大模型領域仍然存在很多可以改進的空間。 他們的創新涵蓋了從算法、軟件到系統架構的多個層面,為國內大模型的發展提供了很好的啟發。
我是做高性能計算方向出身,我們領域一直在追求應用程序的極致性能。之前我在清華帶領學生參加國際超算比賽時,每當拿到題目,我們就會不斷思考:當你發現了負載的某些特點後,如何針對這些特點進行有效優化,可能會帶來幾十、幾百,甚至上千倍的性能提升。可以說,性能優化是一個永無止境的過程。
在當前形勢下,中國在算力資源方面面臨很大挑戰。國外像微軟、X 公司等,投入了 10 萬卡甚至更大的規模,在如此雄厚的算力基礎上,他們可能會將更多精力放在設計更好的模型上,極致的性能優化也許並不是他們當前的重點。但當我們算力有限時,比如固定只有 1 萬張加速卡,就需要思考如何更極致地利用好這些硬件,挖掘算法、系統,包括硬件等各方面協同創新的可能性。
機器之心:追求性能優化和模型創新兩種發展路線是否相互衝突?它們能在同一個階段共存嗎?
翟季冬:從系統軟件層面來看,它與算法發展是解耦的。換句話說,這些優化技術同樣適用於算力更充足的場景,換到美國的研究環境中也可以應用,並不會阻礙上層模型的發展。
機器之心:業界似乎還沒有一個客觀評價算力利用效率的體系或標準。從您的角度看,我們應該如何科學、客觀地評價算力的利用?
翟季冬:這是個很好的問題。現在一些科技報導中經常提到「GPU 利用率」這樣的指標,但要評價一個系統是否用得好,很難用單一指標來衡量,就像評價一個人不能只看單一維度一樣。
具體來說,在大模型訓練時,GPU 利用率只是其中一個方面。在大型集群中,還包括網絡設備、存儲設備等。僅僅追求 GPU 利用率很高,而網絡利用效率或內存使用率很低,這並不是最優的狀態。從系統軟件優化的角度,我們需要追求整體的均衡,可能通過提高網絡和內存的使用率來適當降低 GPU 消耗。
評價標準也因場景而異。在訓練場景中,我們更關注整個集群(包括加速卡、存儲、網絡、通信等)的整體利用效率。在推理場景中,終端用戶更關心延遲,比如是否能在幾毫秒內得到響應,除了第一個 token 的生成延遲,後續每個 token 之間的間隔時間也是重要的指標;算力提供方則更關注整體吞吐量,比如 1000 張加速卡每天能處理多少請求,是每天能響應 100 萬個請求,還是 1000 萬個請求。
一個經常被忽視但很重要的指標是成本,特別是每個 token 的處理成本。大家總說追求極致性能,但當我們將成本約束也納入考慮時,對系統吞吐量和處理延遲的討論會更有現實意義。從長遠來看,顯著降低推理成本對於推廣 AI 應用至關重要。
中美硬件差異下的算力突圍
系統軟件雙向適配
機器之心:由於中美之間的硬件差異,大家很關注軟件棧層面是否會出現代際分叉,甚至發展出不同的科技樹?
翟季冬:中國確實在系統軟件方面面臨著不同的思考方向。在美國和歐洲,AI 基礎設施主要以 NVIDIA GPU 為主,但在中國,很難獲得最先進的 NVIDIA 算力。
NVIDIA GPU 之所以受歡迎,很大程度上歸功於其成熟的生態系統。我印象很深刻的是,從我讀書時期開始,NVIDIA 就與清華等高校展開合作,探索如何更好地在他們的硬件上實現加速。他們現在的軟件棧也是經過多年積累形成的。相比之下,中國的 AI 芯片公司大多始於最近幾年,發展歷程不到十年。
我們還有很長的路要走,無論是在底層編譯器優化芯片算力,還是在多卡互連的高效通信協同方面。中國面臨雙重挑戰:一方面需要補齊短板,提升芯片易用性;另一方面由於獲取不到最先進的芯片製程工藝,可能會落後國外一到兩代。這使得軟件與硬件的協同優化在中國顯得更為重要,我們需要挖掘所有可能的優化空間。
機器之心:從您的角度看,我們應該用什麼樣的思路來應對 NVIDIA 建立的軟件生態壁壘?
翟季冬:作為後來者,我們首先要學習他們在算子庫、編程語言和編譯器方面的先進理念。在不違反知識產權的前提下,我們可以借鑒這些成果。但也不能完全照搬,而是要有自己的思考。例如,在工藝製程落後的情況下,我們可以在軟件棧方面做些什麼?針對與 NVIDIA 不同的架構特點,我們是否可以有自己的創新?
如果能夠把從應用側到系統軟件,再到自主研製芯片的整條路徑打通,我相信我們能找到一條適合中國現實環境的可行發展路線。
從學術角度來說,我們可以探索開發更好的領域特定編程語言,讓用戶編寫高層代碼時能自動生成更高效的實現。這裏還有很多可以探索的空間,但要實現商業落地需要時間。
機器之心:說到大模型算力優化,為什麼還沒有芯片廠商推出 Transformer 專用芯片?您如何看待這個趨勢?
翟季冬:我認為現在沒有並不代表將來沒有,可能有些公司正在這個方向上努力。從芯片設計到流片再到封裝,整個過程成本非常高,必須要有足夠大的市場空間才能支撐這種特定架構。
如果大模型最終確實會以 Transformer 架構為主,那麼我們確實可以設計一款完全針對 Transformer 的專用芯片。但目前存在幾個主要考慮:首先,AI 模型發展非常迅速,我們無法確定 Transformer 架構是否會一直保持主流地位,可能還會出現新的非 Transformer 架構。其次,Transformer 本身也在不斷演化,比如 MoE 這樣的稀疏激活模型,以及多模態 MoT(Mixture-of-Transformers)的稀疏特性,這些特性很難在芯片層面直接描述。
回顧最近這一波 AI 發展,大約從 2012 年至今,最初以卷積神經網絡為主,一些芯片公司專門為卷積設計了 ASIC 芯片。但到了 2017 年後,Transformer 架構逐漸興起,與卷積有很大的不同,導致之前針對卷積優化的 ASIC 芯片難以適應新的架構。
值得一提的是,在此過程中 NVIDIA 雖然也在其芯片架構中添加了各種新的硬件模塊,但整體架構保持相對穩定,通過系統軟件來適應應用的變化,比如他們的 Tensor Core 針對矩陣乘法進行優化,而不是專門為 Transformer 的某個組件(如 Attention)設計特定架構。
機器之心:NVIDIA 的做法能給我們帶來什麼啟示?
翟季冬:從軟件角度來說,最大的啟示是以不變應萬變。專用硬件的設計思路,本質上是把具體的算法用電路去實現,但設計的關鍵在於如何把這個具體的算法拆解成合適的、通用的基本硬件單元,以便各種應用都能通過這些基本單元來實現。例如,NVIDIA 的 Tensor Core 就是將各種操作都轉換成矩陣乘法,這種映射方式相對更靈活。
拆解的核心在於粒度要恰到好處:粒度過大,小型應用難以有效利用硬件資源,造成浪費且性能下降;粒度過小,則會增加數據搬運和調度開銷,降低整體效率,並增加硬件和軟件的複雜度。這是一個需要權衡的設計選擇。
機器之心:現在很多公司一方面投資現有基礎設施購買各類計算卡,一方面也在與高校合作並投資創業公司,以應對非 Transformer 架構帶來的挑戰。從系統軟件層面來看,這種佈局能在多大程度上應對下一代技術的衝擊?
翟季冬:系統軟件的本質是將上層應用程序更好地映射到底層硬件。一方面要關注應用層面的變化,比如現在多模態模型越來越重要,我們就需要思考多模態帶來的新模式和負載特徵,同時要關注底層架構的演進,無論是 NVIDIA GPU 還是國產加速卡,都可能會增加新的計算單元或訪存單元,我們需要思考如何更好地利用這些硬件特性。
系統軟件的核心任務是密切關註上下層的變化,通過中間層的合理設計將兩端匹配起來,讓硬件效率發揮到極致。對於正在探索的新型模型,我們需要分析它們的負載特徵,研究如何更好地映射到底層芯片以充分利用硬件資源。
從提前佈局的角度來說,系統軟件要做好新興應用負載的分析。同時,當新的芯片架構出現時,系統軟件也要及時做出相應的改進和適配。這種雙向的適配能力,是系統軟件應對技術變革的關鍵。
萬卡集群時代的算力優化
機器之心:您參與了多個基座大模型的訓練,在使用萬卡級集群方面有第一手經驗,能否分享一下在這種超大規模訓練中遇到的主要技術挑戰?
翟季冬:2021 年,我們與北京智源研究院等機構合作,使用新一代神威超算系統進行一個基座大模型的訓練,可以把它理解為一個 10 萬卡的集群。在這個過程中,我體會到大模型訓練主要有幾方面的挑戰。
首先是並行策略的選擇。因為模型很大,用 10 萬台機器去做,就要把模型進行切分,就像把一塊豆腐要切成很多塊,可以切成方塊,也可以切成細條,原理是一樣的。要把一個大模型分到 10 萬台機器上,也有很多切分方式。用術語來講,比如說有數據並行、模型並行、流水線並行、序列並行等等,每個並行策略都有自己的優缺點。在 10 萬台機器上,如何組合這些並行策略,本身就是很大的挑戰。而且 10 萬規模的集群,沒辦法像單卡那樣反復測試各種策略,一定要把策略分析清楚了才去跑,因為一次的測試成本就很高,也不允許做太多次嘗試。
第二個挑戰是通信問題。10萬台機器需要通過高速網絡互連,但不同的機器組網方式不一樣,網絡的拓撲是不一樣的。大模型訓練時有很多通信函數,這些通信函數如何跟底層的網絡拓撲高效映射是一大挑戰。我們發現,不同的通信策略可能導致 1-2 倍的性能差異。
第三個挑戰是容錯機制。當機器規模增大,整個系統平均無故障時間就會非常小。基座模型訓練通常需要幾週到一兩個月。我們必須設計輕量級的容錯機制,在硬件出現故障時能夠快速替換出錯的卡並繼續訓練,同時將這個開銷降得越低越好。
最後,單卡性能也至關重要。在關注萬卡、10 萬卡這類整體系統的同時,也要把單卡效率打得特別高,比如通過編譯優化等策略,確保每張卡都能發揮出極致性能。
機器之心:在提升算力利用率方面,我們應該關注哪些點?
翟季冬:大模型的生命週期包含多個階段,每個階段對算力的需求都不相同。我們剛才談了預訓練,但在預訓練模型完成後,還有一個很重要的階段就是後訓練(post training)。以 OpenAI o1/o3 為代表的後訓練技術,為整個訓練過程帶來了新的挑戰。
後訓練包括生成階段、推理階段和微調階段,每個階段的負載特點都不同,最優的並行策略也會不同。需要注意的是,不能簡單地追求每個階段的局部最優,因為階段之間的切換也會產生開銷。我們要從整個 pipeline 的角度來考慮優化策略。後訓練還面臨著負載不均衡的問題,需要探索如何有效重疊不同階段以提高資源利用率。
在微調階段,客戶往往會用自己的私有數據對基座模型進行調整。由於硬件資源可能有限,這時需要考慮一些特殊的策略,比如 offloading,也即當 GPU 內存不足時,將部分參數存儲在 CPU 端。微調本身作為一個訓練過程,對並行策略也有很高要求。
推理階段的優化面臨更多挑戰:
KV Cache 管理:推理過程會產生大量中間結果(KV Cache)用於降低計算量。如何管理這些數據很關鍵,比如可以採用頁面式管理,但頁面大小是固定還是根據負載特徵動態調整,都需要仔細設計。
多卡協同:當模型較大時需要多 GPU 配合,比如在 8 個 GPU 上進行大模型推理,如何優化卡間並行也是一大挑戰。
算法優化:還可以從量化等角度進行優化,充分發揮底層算力性能。
總的來說,從預訓練到後訓練,再到微調和推理,每個階段對算力的要求都不同,我們需要針對這些特點進行深入的優化。
機器之心:如果要建設百萬卡集群,是選擇多家廠商的卡,還是只選擇少數廠商乃至單獨一家的卡更好?
翟季冬:從管理和使用效能的角度來說,選擇單一類型的加速卡無疑是最方便的。但實際情況往往更加複雜。比如說在美國,企業可能先購入 1000 張 A100,後來又添置 1000 張 H100。不同代際的加速卡存在性能差異,整合使用時就會帶來系統優化的挑戰,而且這個問題在訓練和推理場景下的表現也不盡相同。
從系統軟件角度看,這實際上是芯片碎片化的挑戰。我目前正在負責一個項目,面向異構芯片的統一編程和編譯優化。核心理念是,雖然底層使用不同的 AI 芯片,但在編程模型和編譯優化層面要儘可能統一。我們希望同一套程序能在不同加速卡上都發揮出高效性能,同時降低不同加速卡間的移植開銷。
很多人都說過,希望算力像水電一樣成為基礎設施。用電時我們並不需要關心是風力發電還是煤炭發電。要實現這個目標,實際上有很長的路要走,我們需要做好中間層的軟件工作。此外,還要建立完善的算力度量標準,比如如何計算算力使用量,如何計價,這些都需要標準化。
在現階段,我們還是需要關注底層硬件的具體情況。但未來的發展方向是,通過完善中間層的系統軟件,為用戶提供透明的接口。用戶只需要調用簡單的 API 就能方便使用各種算力資源,不必關心底層細節。這可能是一個終極的發展方向。
機器之心:那我們把時間拉近一些,未來 1-3 年內,系統軟件優化方面可能會看到哪些顯著趨勢或變化?
翟季冬:目前我國各省市建立了許多智算中心,以國產算力為主。我們觀察到一個現像是,儘管應用開發者普遍缺乏算力資源,但許多國產算力中心卻存在閑置現象。用戶更傾向於使用 NVIDIA 這樣開箱即用的解決方案。
這種狀況其實帶來了重要機遇:如何將巨大的算力需求與現有的國產算力有效對接?我們的目標是讓國產算力達到同樣的易用性,使用戶感受不到差異。這不僅能促進人工智能在中國各行各業的發展,也能帶動從芯片到軟件再到應用的整體發展。
為此,我們實驗室孵化了一家公司「清程極智」,致力於為國產閑置算力提供更友好的接口,幫助行業用戶方便地整合各類國產算力資源。
從技術層面來說,這不僅僅是優化算子庫那麼簡單。系統軟件的完整建設應該包括編程語言、編譯器、通信庫、並行計算、編程框架,這些方向都需要投入。就像木桶效應,任何一個短板都可能影響芯片的整體使用效果。要充分發揮國產算力的性能,我們需要在這些方向全面發力,才能真正把算力這個方向做好。
嘉賓簡介
翟季冬,清華大學計算機系長聘教授,博士生導師,高性能計算研究所所長。青海大學計算機技術與應用學院院長。CCF高性能計算專委副主任、CCF傑出會員。清程極智首席科學家。
主要研究領域包括並行計算、編程模型與編譯優化。在並行計算與系統領域頂級會議和期刊發表論文 100 餘篇,出版專著一部。研究成果獲 IEEE TPDS 2021 最佳論文獎、IEEE CLUSTER 2021 最佳論文獎、ACM ICS 2021 最佳學生論文獎等。擔任清華大學學生超算團隊教練,指導的團隊 15 次獲得世界冠軍。獲教育部科技進步一等獎、中國計算機學會自然科學一等獎、CCF-IEEE CS 青年科學家獎、高校計算機專業優秀教師獎勵計劃。國家傑出青年科學基金獲得者。
本文來自微信公眾號「機器之心」(ID:almosthuman2014),作者:聞菲,36氪經授權發佈。