奧特曼被逼急:深夜上線 o3-mini,甚至免費,網民:還是選DeepSeek
機器之心報導
機器之心編輯部
奧特曼能不急嗎?
被 DeepSeek 狂轟亂炸了一週後,終於在今天發佈了新的模型 o3-mini。
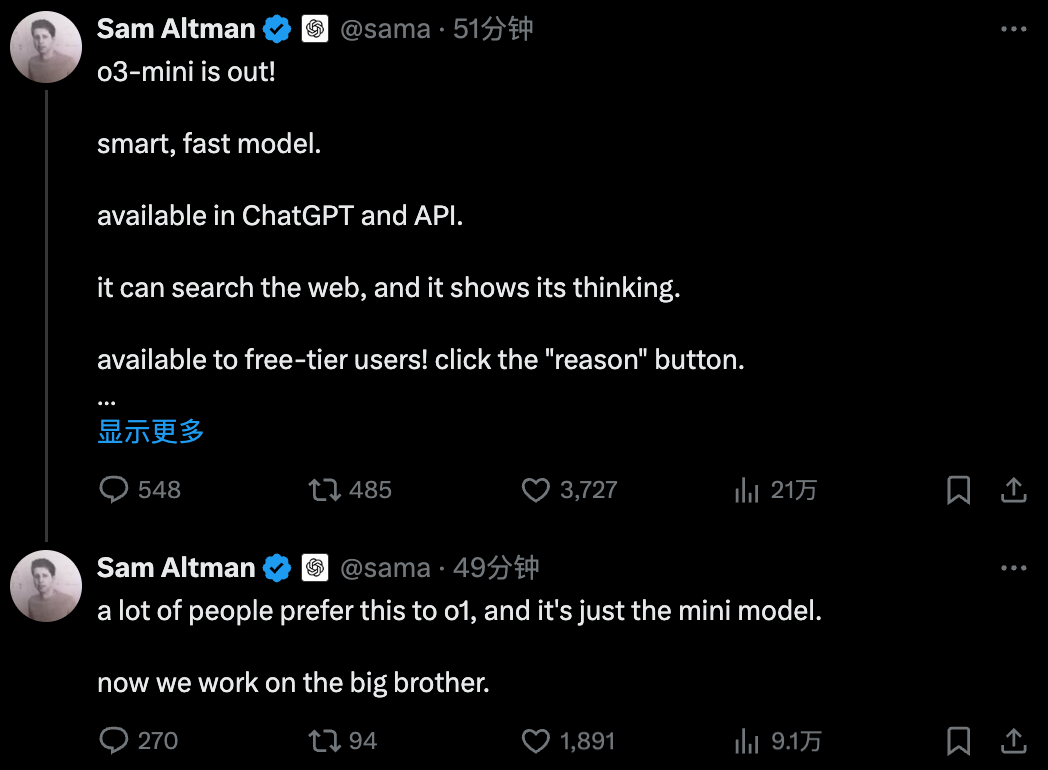
此次發佈,o3-mini 包含 low、medium 和 high 三個版本。
OpenAI 表示,今天發佈的 o3-mini 是其推理模型系列中最新、最具成本效益的模型,已上線 ChatGPT 和 API 。
我們打開 ChatGPT,o3-mini 和 o3-mini-high 兩個新模型已然上線。
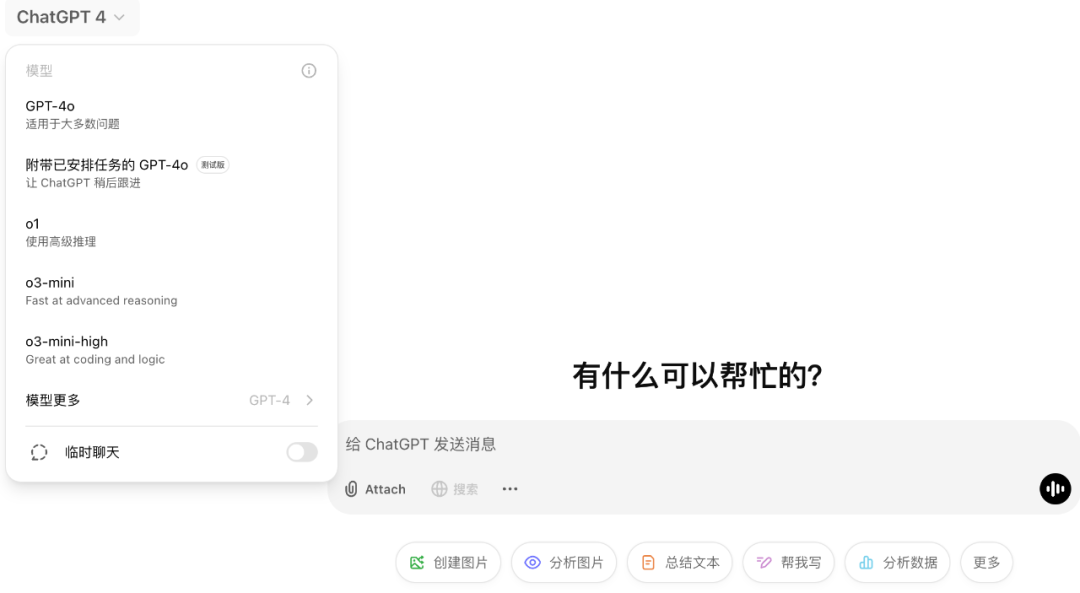
不過 o3-mini 目前還不支持視覺功能,因此開發者需要繼續使用 OpenAI o1 進行視覺推理任務。
在使用權限上,ChatGPT Plus、Team 和 Pro 用戶從今天起就可以訪問 OpenAI o3-mini,企業版訪問權限將在一週內開放。
作為此次升級的一部分,OpenAI 將 Plus 和 Team 用戶的速率限制從 o1-mini 的每天 50 條消息提高到 o3-mini 的每天 150 條消息。此外,o3-mini 現在可以使用搜索功能,提供帶有相關網絡來源鏈接的最新答案。這是其在推理模型中整合搜索功能的早期原型。
從今天開始,免費用戶也可以通過在消息編輯器中選擇「推理」或重新生成響應來試用 OpenAI o3-mini。這是 OpenAI 首次向 ChatGPT 的免費用戶提供推理模型。
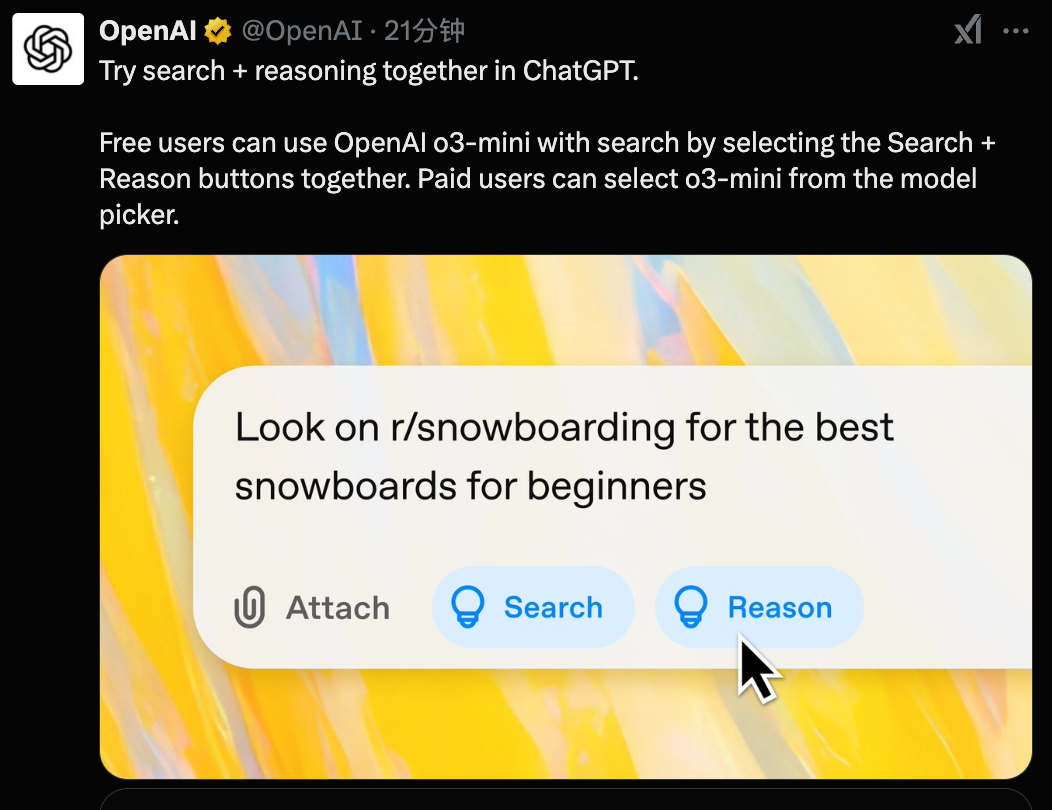
雖然 OpenAI o1 仍然是更廣泛使用的通用知識推理模型,但 OpenAI o3-mini 為需要精確性和速度的技術領域提供了專門的替代選擇。在 ChatGPT 中,o3-mini 使用中等推理級別來提供速度和準確性之間的平衡。所有付費用戶還可以在模型選擇器中選擇 o3-mini-high,從而獲得需要更長時間生成響應但智能水平更高的版本。Pro 用戶將可以無限制地訪問 o3-mini 和 o3-mini-high。
對於此次發佈,網民反饋如何?
知名播客主理人 Lex Fridman 表示,OpenAI o3-mini 雖然是一個很好的模型,但 DeepSeek r1 的性能相似,而且更便宜,並揭示推理過程。
他甚至給出了「DeepSeek moment」這樣一個詞形容 DeepSeek 帶來的深遠影響。
接下來,就讓我們看下 o3-mini 的性能指標:
快速、強大且針對 STEM 推理優化
與其前身 OpenAI o1 類似,OpenAI o3-mini 針對 STEM 推理進行了優化。o3-mini-medium 在數學、編程和科學領域的表現與 o1 相當,同時響應速度更快。專家測試人員的評估顯示,o3-mini 產生的答案比 o1-mini 更準確、更清晰,推理能力更強。測試人員在 56% 的情況下更偏好 o3-mini 的響應,並觀察到 o3-mini 在困難的現實問題上重大錯誤減少了 39%。o3-mini-medium 在一些最具挑戰性的推理和智能評估(包括 AIME 和 GPQA)上與 o1 的表現相當。
競賽數學(AIME 2024):
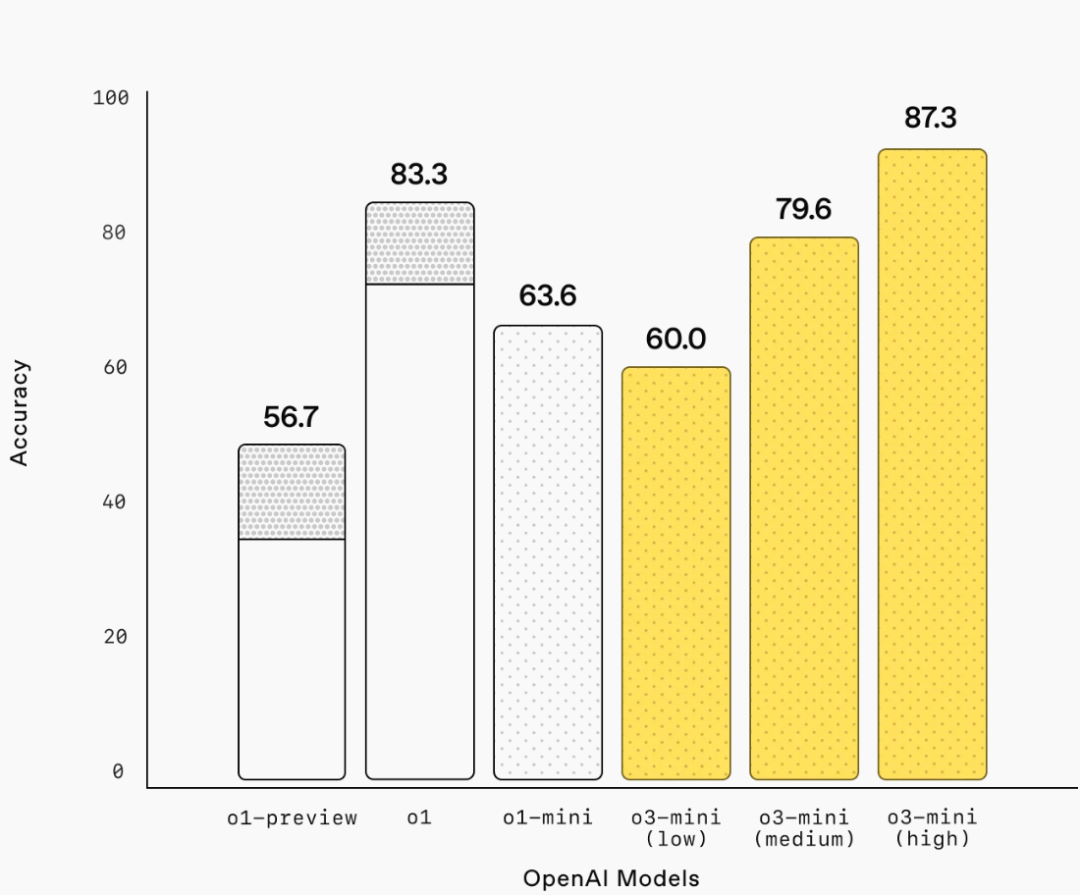
競賽數學:o3-mini-low 與 o1-mini 的表現相當。o3-mini-medium 達到與 o1 相當的表現。o3-mini-high 超過了 o1-mini 和 o1,上圖中灰色陰影區域為 64 個樣本的多數投票(共識)。
博士級科學問題(GPQA Diamond):
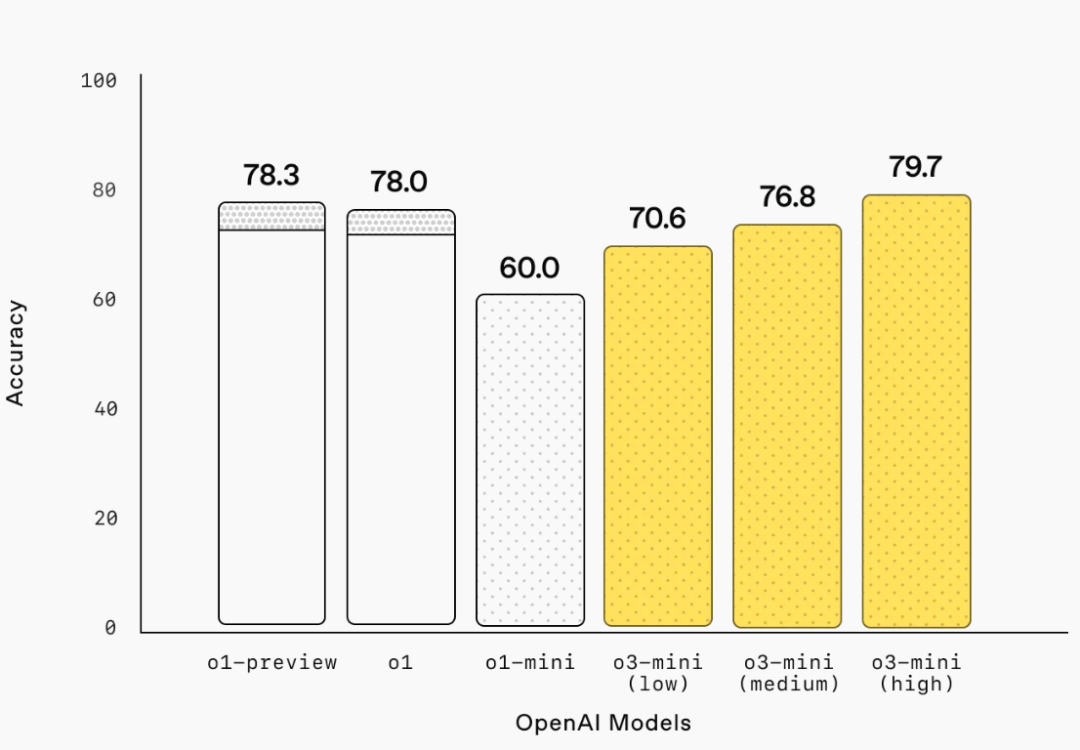
博士極科學問題:o3-mini-low 的表現優於 o1-mini。o3-mini-high 的表現與 o1 相當,在博士級生物學、化學和物理問題上都顯示出顯著進步。
研究級數學(FrontierMath):

研究級數學:o3-mini-high 在 FrontierMath 上的表現優於其前代產品。使用 Python 工具時,o3-mini-high 能夠在首次嘗試時解決超過 32% 的問題,包括超過 28% 的具有挑戰性的(T3)問題。
競賽編程(Codeforces):
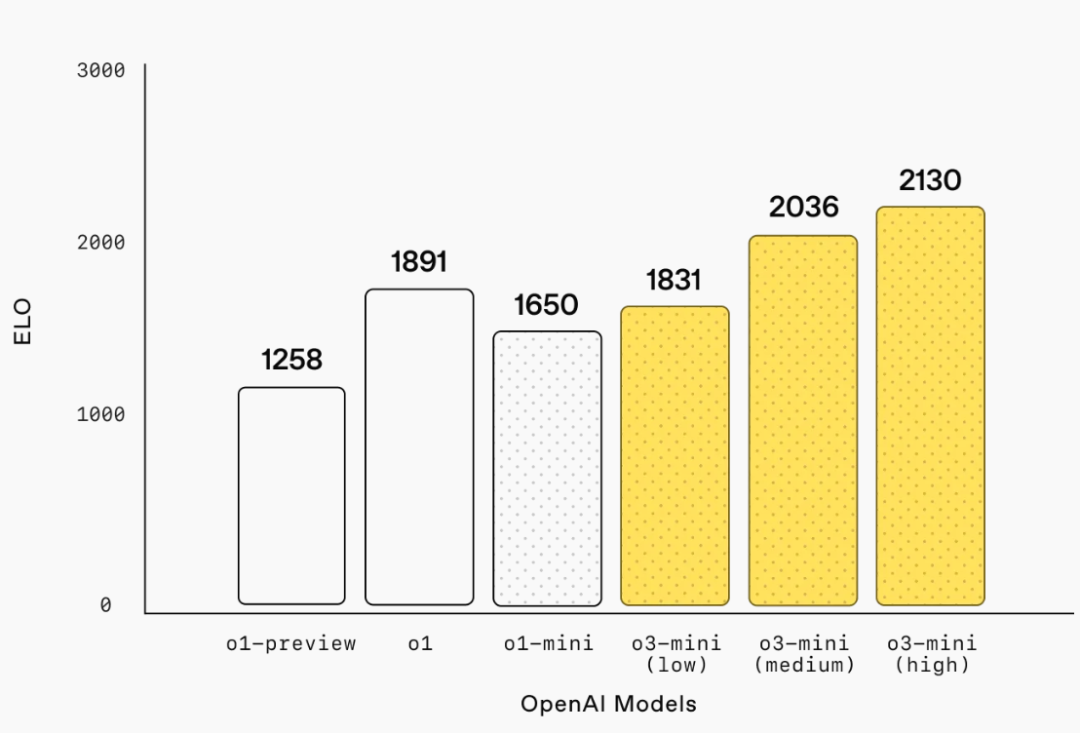
在 Codeforces 編程中, o3-mini 隨著推理努力級別的提高獲得了越來越高的 Elo 分數,均優於 o1-mini。o3-mini-medium 達到了與 o1 相當的表現。
軟件工程(SWE-bench Verified):
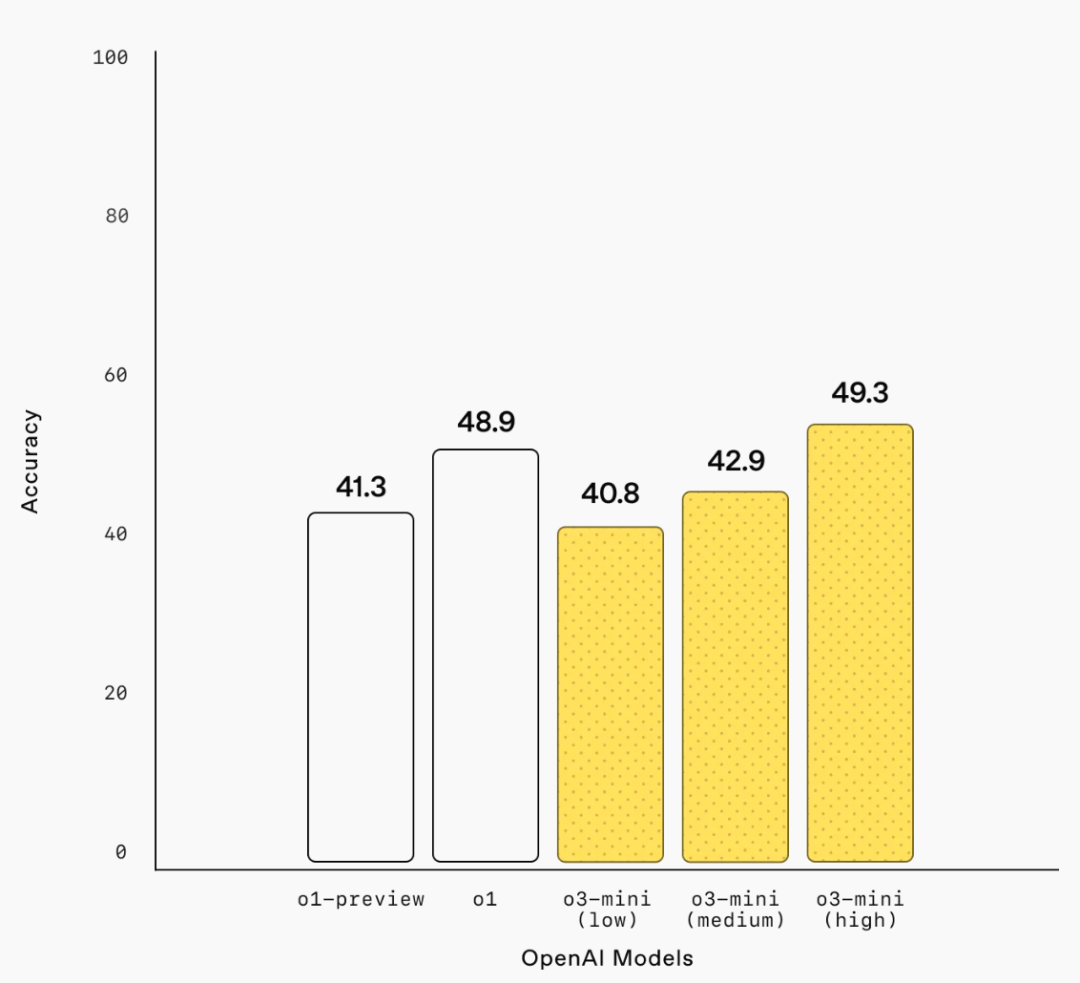
軟件工程:o3-mini 是 OpenAI 發佈的在 SWEbench-verified 上表現最好的模型。o3-mini-high 使用開源 Agentless 框架可達到 39% 的準確率,使用內部工具可達到 61% 的準確率。
LiveBench 編碼:
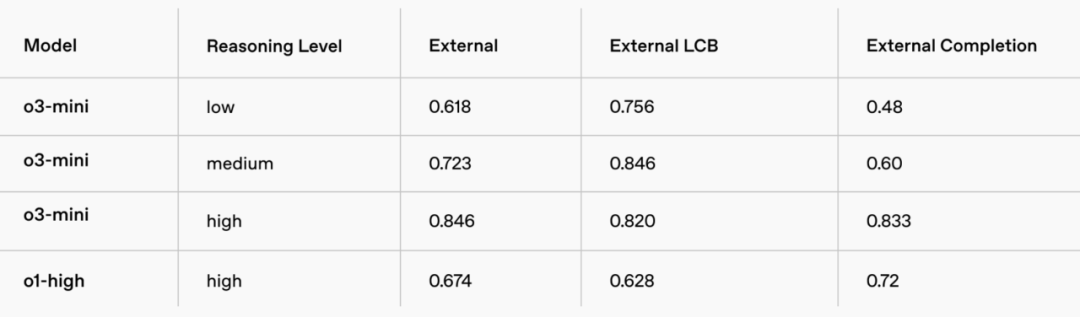
LiveBench 編碼:即便是 o3-mini-medium 也超過了 o1-high,突顯了其在編碼任務中的效率。o3-mini-high 進一步擴大了領先優勢,在關鍵指標上取得了顯著更強的表現。
普通知識問題:
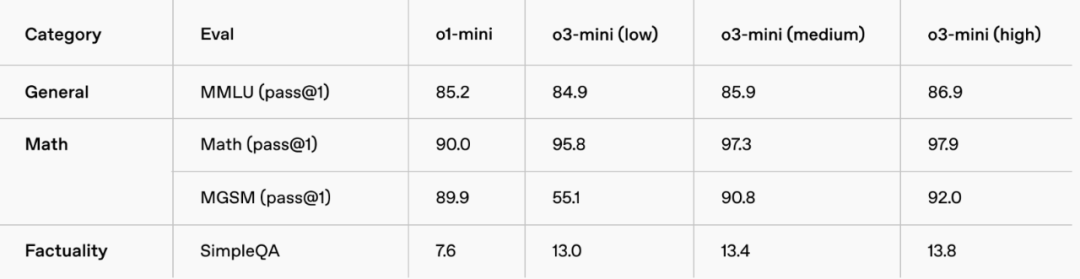
普通知識問題:o3-mini 在各個一般性知識領域的評估中都優於 o1-mini。
人類偏好評估:
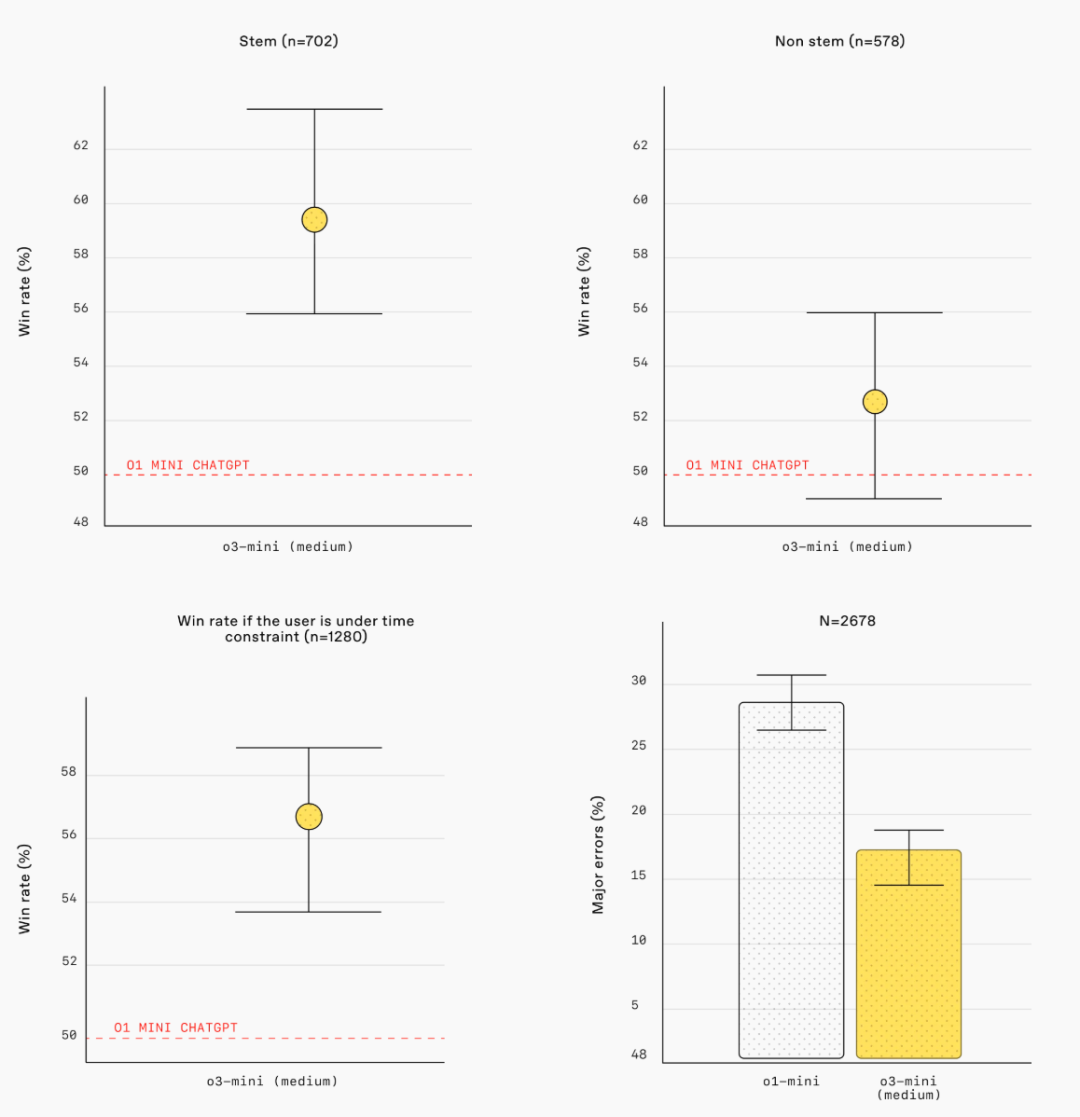
人類偏好評估:外部專家測試人員的評估顯示, o3-mini 產生的答案比 o1-mini 更準確、更清晰,推理能力更強,特別是在 STEM 領域。測試人員在 56% 的情況下更偏好 o3-mini 的響應,並觀察到 o3-mini 在困難的現實問題上重大錯誤減少了 39%。
模型速度和性能
o3-mini 在保持與 OpenAI o1 相當的智能水平的同時,提供了更快的性能和更高的效率。除了上述 STEM 評估外,o3-mini-medium 的其他數學和事實性評估中也展現出優越的結果。在 A/B 測試中,o3-mini 的響應速度比 o1-mini 快 24%,平均響應時間為 7.7 秒,而 o1-mini 為 10.16 秒。
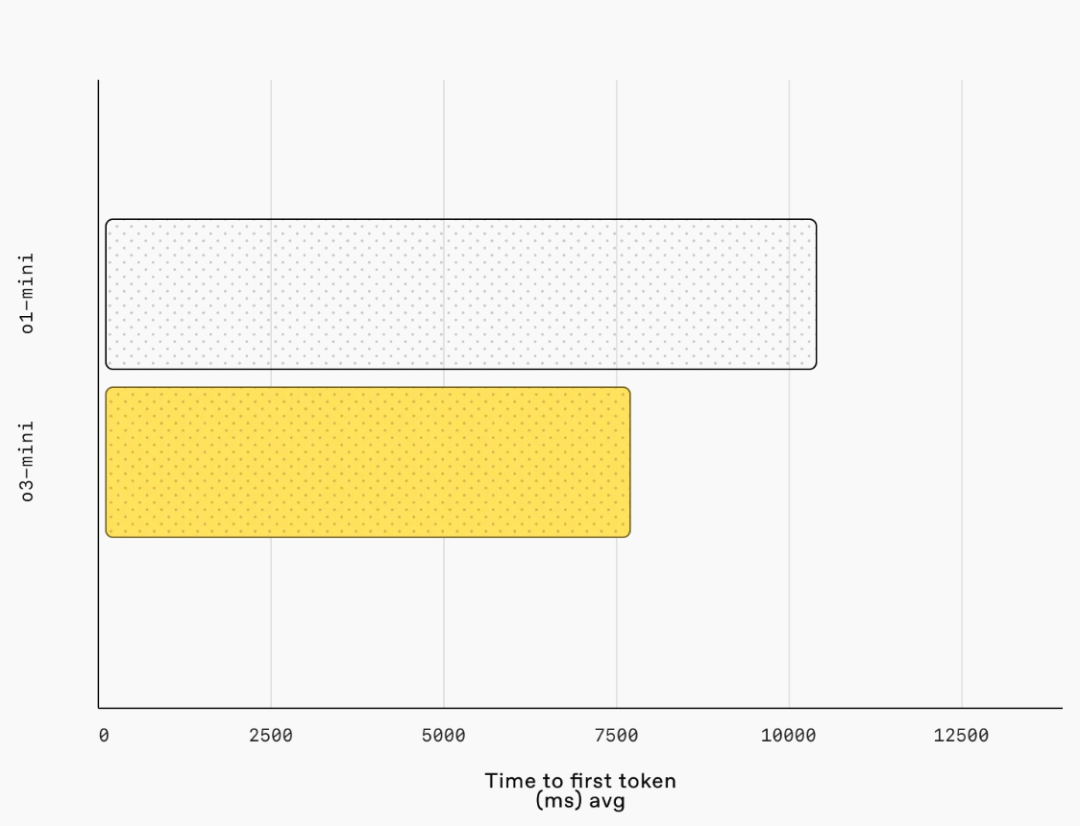
延遲:o3-mini 的首個 token 生成時間平均比 o1-mini 快 2500 毫秒。
安全
OpenAI 教導 o3-mini 安全響應的主要技術之一是審慎對齊(deliberative alignment),這種對齊方式訓練模型在回答用戶提示之前,先對人工編寫的安全規範進行充分的思考和推理。與 OpenAI o1 類似,研究人員發現 o3-mini 在具有挑戰性的安全性和越獄評估上顯著超越了 GPT-4o。在部署之前,OpenAI 使用了與 o1 相同的準備方法、外部紅隊測試和安全性評估來仔細評估 o3-mini 的安全風險。
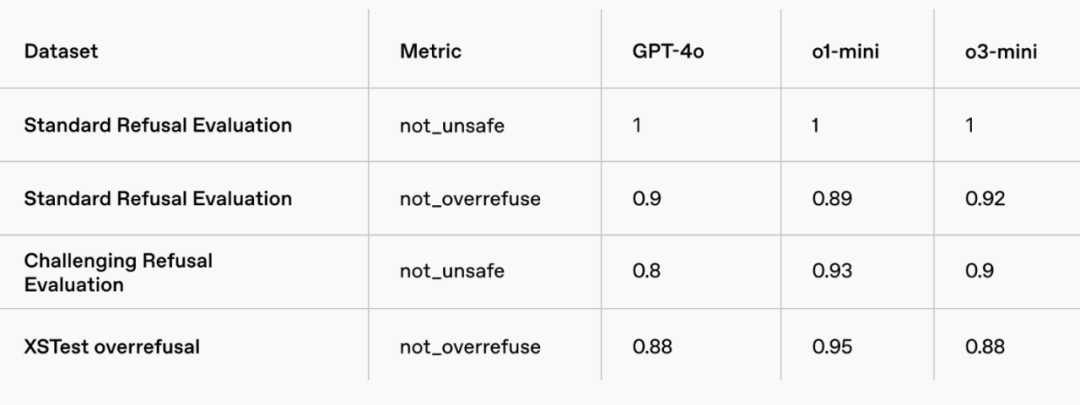
審慎對齊評估結果
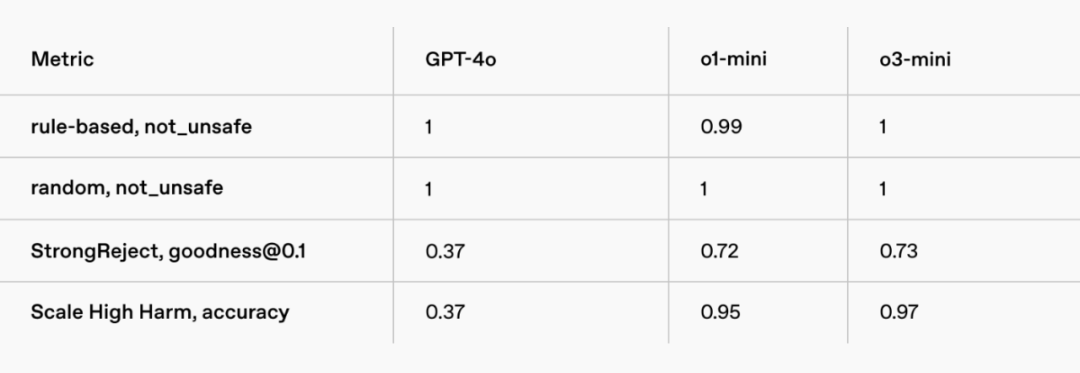
越獄評估結果
未來展望
OpenAI o3-mini 的發佈標誌著 OpenAI 在推進高性價比智能方面又邁出了一步。通過優化 STEM 領域的推理能力,同時保持低成本,OpenAI 正在使高質量 AI 變得更加容易獲取。該模型延續了其降低智能成本的記錄 —— 自 GPT-4 推出以來,每個 token 的定價降低了 95%—— 同時保持頂級推理能力。隨著 AI 應用的擴展,OpenAI 仍然致力於在前沿領域引領,構建即使在大規模部署和使用的情況下,也能保持智能、效率與安全平衡的模型。