大芯片,兩條路線
在前不久剛結束的CES展會上,英偉達重磅推出RT50系列顯卡和GB10超級芯片等產品,引發行業關注。
對此,Cerebras直言不諱地對英偉達評價道:「它不是真正的AI大芯片」。

眾所周知,隨著AI浪潮的興起,芯片成為行業關鍵推手。作為GPU巨頭,英偉達憑藉高性能GPU佔據AI芯片市場的主導地位,跟英特爾、AMD等廠商一樣,都是採用將大片晶圓切分成小型芯片的方式,然後將眾多GPU或加速器互聯起來打造成性能強勁的AI處理器集群。
與此同時,業界還有一種直接在整片晶圓上做AI大芯片架構的廠商。其中,Cerebras就是後者的典型代表之一,旨在以不同設計規範和架構的AI大芯片,領跑「後AI時代」。
英偉達,Not a real big AI chip
首先以芯片巨頭英偉達為例,來看看這種通過小芯片集群架構來設計AI芯片的方式。
進入AI大模型時代,因為單芯片算力和內存有限,無法承載大模型,單個GPU訓練AI模型早已成為歷史。通過多種互連技術將多顆GPU算力芯片互連在一起提供大規模的算力、內存,成為行業趨勢。
在DGX A100情況下,每個節點上8張GPU通過NVLink和NVSwitch互聯,機間直接用200Gbps IB HDR網絡互聯;到了DGX H100,英偉達把機內的NVLink擴展到機間,增加了NVLink-network Switch,可以搭建256個H100 GPU組成的SuperPod超級計算系統。
可以看到,隨著AI算力需求不斷增長,多GPU並行成為一種趨勢,可以支撐大模型的訓練和推理。
對於多GPU系統而言,一個關鍵的挑戰是如何實現GPU之間的高速數據傳輸和協同工作。然而,傳統的PCIe總線由於帶寬限制和延遲問題,已經無法滿足GPU之間通信的需求。
對此,英偉達推出了NVLink、NVSwitch等互連技術,通過更高的帶寬和更低的延遲,為多GPU系統提供更高的性能和效率,支持GPU之間的高速數據傳輸和協同工作,提高通信速度,加速計算過程等。
NVLink用於連接多個GPU之間或連接GPU與其他設備(如CPU、內存等)之間的通信。它允許GPU之間以點對點方式進行通信,具有比傳統的PCIe總線更高的帶寬和更低的延遲,為多GPU系統提供更高的性能和效率。
NVSwitch旨在解決單服務器中多個GPU之間的全連接問題,允許單個服務器節點中多達16個GPU實現全互聯,這意味著每個GPU都可以與其他GPU直接通信,無需通過CPU或其他中介。
 NVSwitch全連接拓撲(圖源:nextplatform)
NVSwitch全連接拓撲(圖源:nextplatform)2022年,英偉達將NVSwitch芯片獨立出來,並製作成NVLink交換機,可以在單個機架內和多個機架間連接成NVLink網絡,可以解決GPU之間的高速通信帶寬和效率問題。
2023年,英偉達生成式AI引擎DGX GH200投入量產,GH200是H200 GPU與Grace CPU的結合體,一個Grace CPU對應一個H200 GPU,GPU與GPU、GPU與CPU之間均採用NVLink4.0連接;
再到新一代AI加速卡GB200,由1個Grace CPU和2個Blackwell GPU組成。在GB200 NVL72整機櫃中,一共包含了72顆Blackwell GPU芯片,18顆NVSwitch芯片,英偉達用了5000根銅纜將所有的GPU都與所有的NVSwitch全部連接起來。
經過多年演進,NVLink技術已升級到第5代。NVLink 5.0以100GB/s的速度在處理器之間移動數據。每個GPU有18個NVLink連接,Blackwell GPU將為其他GPU或Hopper CPU提供每秒1.8TB的總帶寬,這是NVLink 4.0帶寬的兩倍,是行業標準PCIe Gen5總線帶寬的14倍。NVSwitch也升級到了第四代,每個NVSwitch支持144個NVLink端口,無阻塞交換容量為14.4TB/s。

能夠看到,隨著每一代NVLink的更新,其每個GPU的互聯帶寬都在不斷提升,其中NVLink之間能夠互聯的GPU數,也從第一代的4路到第四代/第五代的18路。每個NVLink鏈路的速度也由第一代的20Gb/s提升至目前的1800Gb/s。
NVLink和NVSwitch等技術的引入,為GPU集群和深度學習系統等應用場景帶來了更高的通信帶寬和更低的延遲,從而提升了系統的整體性能和效率。
在2025年CES上,英偉達新推出GeForce RTX 5090與GB10芯片,代表著英偉達在計算架構和技術路線上的再一次跨越。

Blackwell架構採用了最新一代的CUDA核心和Tensor核心,特別優化了AI計算的效率。NVLink72作為一種高速互聯技術,允許多達72個Blackwell GPU互聯,構建出極為強大的計算集群。此外,作為集群的一部分,2592個Grace CPU核心也為GPU提供了強大的協同計算能力,能夠更好地管理和調度任務。
除了傳統的GPU和集群解決方案,英偉達還推出了AI超級計算機Project DIGITS,Project Digits的核心在於其搭載了英偉達的Grace Blackwell超級芯片(GB10)。

GB10是一款SoC芯片,基於Grace架構CPU和Blackwell GPU的組合,Grace GPU部分基於Arm架構,具有20個高效節能核心,Blackwell GPU部分則支持高達1PFlops(每秒一千萬億次)的FP4 AI性能,可運行2000億參數的大模型。GB10還採用了NVLink-C2C芯片間互聯技術,將GPU與CPU之間的通信效率提升到新的高度,為本地AI模型的開發、推理和測試提供強大的支持。
據介紹,這台AI超算還集成了128GB LPDDR5X內存和高達4TB的NVMe存儲,使開發人員能夠處理許多要求苛刻的AI工作負載。
除此之外,Project DIGITS還配備了一顆獨立的NVIDIA ConnectX互聯芯片,它可以讓「GB10」超級芯片內部的GPU兼容多種不同的互聯技術標準,其中包括NCCL、RDMA、GPUDirect等,從而使得這顆「大核顯」可以被各種開發軟件和AI應用直接訪問,允許用戶運行具有多達4050億個參數的大模型。
這意味著,在分佈式系統中,除了單卡和多卡互連外,服務器之間的多機互聯也可以採用InfiniBand、以太網、GPUDirect等新的互聯技術。
在硬件和互聯技術之外,英偉達還開發了以CUDA為核心的軟件架構,與其硬件進行配套使用,從而更好地發揮硬件的性能。英偉達憑藉其在系統和網絡、硬件和軟件的全方位佈局,使其在AI生態牢牢佔據主導地位。
實際上,行業芯片大廠都在互聯技術上積極佈局。除了英特爾2001年提出的PCIe(PCI-Express)協議,AMD也推出了與英偉達NVLink相似的Infinity Fabric技術。

AMD的AI加速器Instinct MI300X平台,就是通過第四代Infinity Fabric鏈路將8個完全連接的MI300X GPU OAM模塊集成到行業標準OCP設計中,為低延遲AI處理提供高達1.5TB HBM3容量。第四代Infinity Fabric支持每通道高達32Gbps,每鏈路產生128GB/s的雙向帶寬。
與此同時,AMD、博通、思科、Google、惠普、英特爾、Meta和微軟在內的八家公司組建了新的聯盟,為人工智能數據中心的網絡製定了新的互聯技術UALink(Ultra Accelerator Link)。

據瞭解,UALink提議的第一個標準版本UALink 1.0,將連接多達1024個GPU AI加速器,組成一個計算「集群」,基於包括AMD的Infinity Fabric在內的「開放標準」,UALink 1.0將允許AI加速器所附帶的內存之間的直接加載和存儲,共同完成大規模計算任務。
與現有互連規範相比,UALink 1.0總體上將提高速度,同時降低數據傳輸延遲。
UALink聯盟旨在創建一個開放的行業標準,允許多家公司為整個生態系統增加價值,從而避免技術壟斷。
AI芯片,互連挑戰與內存瓶頸
從行業大廠推出的一系列GPU和SoC能夠看到,隨著AI大模型對算力基礎設施的要求從單卡拓展到了集群層面,其AI芯片採用的是將多個小芯片進行集群和互連的架構,這對大規模卡間互聯的兼容性、傳輸效率、時延等指標提出了更高的要求。
GPU集群的規模和有效算力,很大程度上取決於GPU集群網絡配置和使用的交換機設備,連接標準的帶寬也限制了計算網絡的帶寬。
從PCIe到NVLink、Infinity Fabric再到InfiniBand、以太網和UALink,儘管這些技術不斷迭代升級,通過高帶寬、低延遲的數據傳輸,實現了GPU或AI服務器之間的高速互聯,在提升深度學習模型的效率和計算性能方面發揮了重要作用。
但能夠預見的是,隨著未來計算數據的爆炸式增長、神經網絡複雜性不斷增加,以及AI技術的加速演進,對更高帶寬的需求還在繼續增長。
互聯技術仍不可避免地成為行業中的瓶頸挑戰,限制了GPU和AI芯片的最大性能釋放。
與互聯技術的滯後相比,存儲技術的瓶頸似乎也是一大關鍵。
眾所周知,馮·諾依曼架構面臨的一個核心挑戰是CPU/GPU等處理器的計算速度與內存訪問速度之間的不匹配,尤其是與存儲設備的速度相比更是天壤之別。這就是業界著名的「內存牆」,其不均衡的發展速度對日益增長的高性能計算形成了極大製約,成為訓練大規模AI模型的瓶頸。
當前在AI、機器學習和大數據的推動下,數據量呈現出指數級的增長,存儲技術必須緊隨其後,才能確保數據處理的效率和速度。對於當前的內存行業來說,高帶寬內存(HBM)已經成為焦點,尤其是在AI大模型訓練和推理所需的GPU芯片中,HBM幾乎已經成為標配。
儘管以HBM為代表的存儲技術帶來了顯著的存算帶寬提升,在一定程度上緩解了帶寬壓力,但並未從根本上改變計算和存儲分離的架構設計。與GPU等計算芯片的快速發展相比,仍面臨內存受限、存儲空間的數據吞吐能力容易跟不上計算單元需求量的挑戰。
 存算帶寬示意(圖源:Cerebras)
存算帶寬示意(圖源:Cerebras)存儲技術滯後於計算芯片發展的現象,顯然已經成為現代計算系統中的一大瓶頸。存儲技術的滯後會給高性能計算帶來多重挑戰:
計算能力浪費:GPU的強大計算能力無法得到充分利用,存儲瓶頸導致大量的GPU計算資源處於空閑狀態,無法卡奧效地執行任務。這種不匹配導致了系統性能的低效發揮,增加了計算時間和能源消耗。
AI訓練效率下降:在深度學習訓練過程中,大量的數據需要頻繁地在GPU與存儲之間交換。存儲的低速和高延遲直接導致AI訓練過程中數據加載時間過長,從而延長了模型訓練週期。這對於需要快速迭代的AI項目來說,可能會造成較大成本壓力。
大規模數據處理的障礙:隨著大數據的興起,許多AI應用需要處理海量數據。當前存儲技術未能有效支持大規模數據的快速處理和存儲,特別是在多節點分佈式計算的場景中,存儲瓶頸往往成為數據流動的最大障礙。
綜合來看,英偉達、AMD等芯片廠商作為AI領域的主導硬件選擇,其強大的並行計算能力為大規模神經網絡的訓練提供了極大的幫助。
然而,在AI模型規模持續擴大、推理任務逐漸提升的過程中,GPU架構的局限性逐漸顯現,大量數據的傳輸和存儲可能成為瓶頸,進而影響AI大模型訓練和推理的速度和效率。
Cerebras:A real big AI chip
面對上述挑戰,Cerebras推出的Wafer-Scale引擎成為了革命性的解決方案。
過去70年中,沒有任何公司成功克服製造大型芯片的複雜性,即便是Intel和Nvidia這樣的行業巨頭也未能解決這一挑戰。儘管在與諸多曾嘗試構建大型芯片的專家討論後,許多人認為製造如此大的芯片不可能實現,但Cerebras依然充滿信心。
「晶圓級」引擎,來勢洶洶
2019年,Cerebras公開展示了WSE-1芯片,這一芯片比當時最大的GPU大了56.7倍,包含超過1.2萬億個晶體管,而當時最大的GPU只有211億個晶體管;2022年,在灣區的計算歷史博物館展示了WSE-2芯片,WSE-2將晶體管數量提升到2.6萬億,並在更小的空間和功耗下提供了更強的計算性能,標誌著計算歷史上的一個重要里程碑。
2024年,Cerebras推出的WSE-3包含4萬億個晶體管和90萬個計算核心,其性能可以訓練比OpenAI的GPT-4大13倍的AI模型。
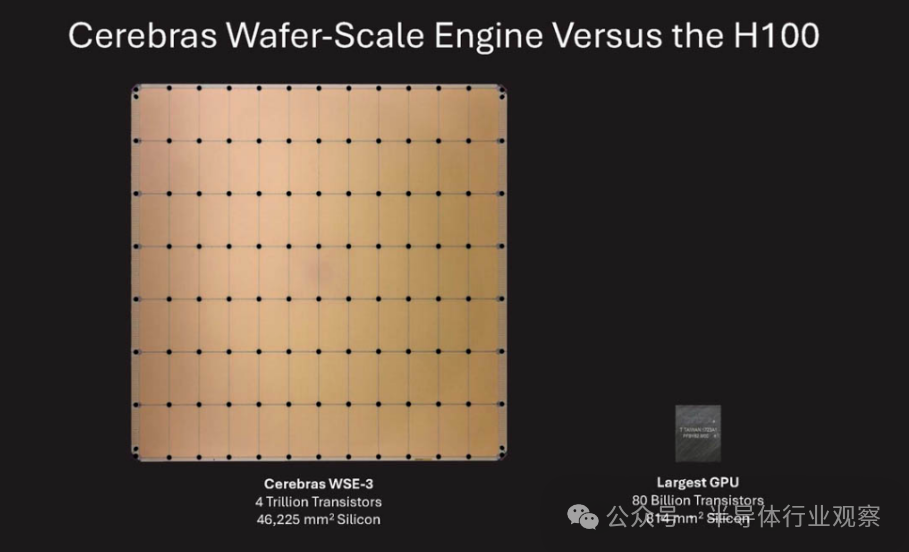 WSE-3與目前行業最新的GPU芯片尺寸對比
WSE-3與目前行業最新的GPU芯片尺寸對比傳統芯片在晶圓上以網格模式打印,然後切割成數百個小型芯片,而Cerebras的晶圓級集成則跳過了這種切割步驟,直接將整個晶圓設計成一個單一的超大芯片,因此稱為「晶圓級」引擎。該方案通過將海量的計算資源和存儲資源集中在單一的超大規模芯片(晶圓)上,優化了數據傳輸路徑,減少了延遲,顯著提高了推理速度。
要理解這種設計的必要性,首先需要瞭解AI開發中涉及的兩大瓶頸:一是處理數百萬矩陣乘法運算所需的計算能力(FLOPs);二是通過各種歸一化、SoftMax或ReLU操作在模型連接中更新權重所需的內存帶寬。
在計算能力部分,雖然其進步遵循摩亞定律,但內存帶寬的提升卻遠遠滯後。例如,英偉達從2020年發佈的A100到2022年的H100,計算能力增加了約6倍,但內存帶寬僅增長了1.7倍。
訓練時間的主導因素從計算能力轉向了內存帶寬。
同時,由於傳統的處理器芯片內部內存有限,無法存儲用於計算的數據。在處理如LLM模型訓練這樣的大規模計算任務時,處理器芯片需要不斷地將數據從芯片外的內存中進出。處理器與內存芯片之間的通信速度遠低於處理器計算速度,芯片與芯片之間的通信速度比芯片內部的通信慢100倍以上,導致內存瓶頸問題。
Cerebras的晶圓級引擎正是為瞭解決這些瓶頸而設計的。

通過設計更大的芯片,可以增加處理器和本地內存芯片的空間,利用成千上萬的矽線實現兩者之間的高速通信,設計避免了像英偉達、AMD在將多個GPU或處理器連接時面臨的互聯瓶頸和內存帶寬問題。
具體來看,在這個超大芯片上,Cerebras將計算單元和內存單元高度集成,形成了一個密集的網格結構。
與傳統的馮·諾依曼架構不同,這種存算一體技術將計算單元與存儲單元深度融合,極大地減少了數據在內存與處理器之間傳輸的距離和時間,從根本上打破了「存儲牆」問題,極大提升了存算交換效率,使得數據能在極短的時間內完成讀取和計算,從而實現超快推理。
得益於芯片尺寸,對比英偉達H100 GPU,Cerebras WSE-3擁有90萬個計算核心,是H100的52倍,片上內存是H100的880倍,內存帶寬是其7000倍,而通過WSE-3的片上互聯技術,核心之間的互連帶寬更是做到了214Pbps,是H100系統的3715倍。
 Cerebras WSE與英偉達H100存算帶寬對比
Cerebras WSE與英偉達H100存算帶寬對比諸多優勢加持下,根據Cerebras的數據,其推理服務在運行開源模型Llama 3.1 8B時可以達到1800 token/s的生成速度,而在運行Llama 3.1 70B時也能達到450 token/s。相比之下,英偉達H100 GPU在這兩個模型上的表現分別為242 token/s和128 token/s。在許多情況下,WSE-3比使用英偉達H100構建的系統快10到20倍。


然而,這麼大尺寸的芯片雖然性能強大,但更容易遭遇缺陷,因為隨著芯片面積增大,良率會指數級下降。因此,儘管較大的芯片通常運行速度更快,早期的微處理器為了維持可接受的製造良率與利潤,通常選擇適中的尺寸。
近年來,隨著製造工藝和光刻設備的進步,缺陷率得到了控制,且通過標準的內存製造工藝,可以繞過有缺陷的部分,確保整體芯片不被一個缺陷影響。Cerebras在其WSE芯片中添加了冗餘核心設計,並通過固件映射來屏蔽製造缺陷,以防止單一缺陷損壞整個芯片。這與傳統的芯片製造方式不同,後者通常會丟棄有缺陷的芯片。
同時,容錯率的程度可由缺陷發生時損失的芯片面積來衡量。對於多核心芯片而言,核心越小,容錯率越高。如果單個核心足夠小,就有可能製造非常大的芯片。
據瞭解,在決定構建晶圓級芯片之前,Cerebras首先設計了一個非常小的核心。Wafer Scale Engine 3中的每個AI核心約為0.05mm²,僅為H100 SM核心大小的約1%。這兩種核心設計均具備容錯能力,這意味著一個WSE核心的缺陷僅會損失0.05mm²,而H100則會損失約6mm²。從理論上來看,Cerebras WSE芯片的容錯率比GPU高約100倍,考慮的是缺陷對矽面積的影響。
但僅僅擁有小核心還不夠。Cerebras還開發了一種精密的路由架構,能夠動態重新配置核心之間的連接。當偵測到缺陷時,系統可透過冗餘通信路逕自動繞過缺陷核心,並利用鄰近核心保持芯片的整體運算能力。
 路由架構(圖源:techbang)
路由架構(圖源:techbang)該路由系統與小量備用核心協同工作,能夠替換受缺陷影響的核心。與以往需要大規模冗餘的方式不同,Cerebras的架構透過智慧型路由實現了以最少備用核心達成高良率。
在商業模式上,Cerebras的核心產品不是單獨銷售WSE芯片,而是提供與其WSE芯片共同設計和優化的集成計算系統。到目前為止,Cerebras已經推出了三款計算系統:CS-1(針對WSE-1),CS-2(針對WSE-2),以及最新的CS-3(針對WSE-3)。
每個系統都包含一個「引擎塊」,其中包括芯片封裝、供電系統和一個封閉的內部水循環,用於冷卻功耗巨大的WSE芯片。此外,所有的冷卻和電源設備都有冗餘且支持熱插拔。
據瞭解,Cerebras的系統方案具備諸多優勢:
擴展能力:Cerebras的計算系統通過其SwarmX(網絡通信)和MemoryX(存儲權重)技術來實現可擴展性。SwarmX技術允許最多192台CS-2系統或2048台CS-3系統連接在一起,實現幾乎線性性能增益。例如,三倍數量的CS-3系統可以將LLM的訓練速度提升三倍。相比之下,英偉達通過收購Mellanox來連接GPU,但性能增益是次線性的。
此外,MemoryX技術為每個計算系統提供最高1.2TB的存儲空間,允許每個系統存儲24萬億參數,並在訓練期間將所有模型參數存儲在芯片外,同時提供接近芯片內的性能。一個由2048台CS-3系統組成的集群可以以256 exaFLOPS的AI計算能力,不到一天的時間就可以完成Llama2-70B模型的訓練。
內存和計算解耦:Cerebras的系統允許內存和計算能力獨立擴展,而GPU的內存和計算能力是固定的。比如,英偉達的H100芯片內存限制為80GB,GPU集群需要將LLM分解成多個小部分,在成千上萬的GPU之間分配,增加了模型分佈和管理的複雜性。而Cerebras的單個計算系統可以容納和訓練一個包含數萬億參數的模型,不需要分佈式訓練軟件,從而減少了開發過程中97%的代碼量。
系統性能:Cerebras的計算系統單台設備的性能已經超過傳統的GPU機架。2019年發佈的CS-1就比GPU快1萬倍,且比當時全球排名第181的Joule超級計算機快200倍。CS-2於2021年發佈,性能較CS-1提升一倍。而CS-3於2024年推出,性能再翻倍,但功耗和成本未增加。一個CS-3系統的計算能力相當於一整個房間服務器中數十到數百個GPU的總和。48台CS-3的集群性能超過了美國的Frontier超級計算機——全球排名第一的超級計算機,但成本便宜了100倍。
AI推理能力:2024年8月,Cerebras為CS-3系統啟用了AI推理功能,成為全球最快的AI推理提供商。一個月後,Groq和SambaNova在推理速度上有所進展,但Cerebras迅速奪回了第一的位置。Cerebras的推理能力比Nvidia H100快20倍,成本僅為其五分之一。對於需要實時或高吞吐量推理的AI產品開發者,Cerebras的低延遲推理能力將尤為重要。
AI大芯片,更適用於大模型推理?
AI推理是指在經過大量數據訓練之後,AI系統利用其模型對新的輸入數據進行判斷、分類或預測的過程。推理速度的快慢直接影響著AI系統的響應能力、用戶體驗,以及AI技術在實時交互應用中的可行性。
當前,儘管大多數AI系統已經可以處理複雜的任務,但推理過程仍然耗時較長。尤其在自然語言處理(NLP)任務中,例如ChatGPT這種大語言模型,系統需要逐字生成回答,這使得實時交互變得緩慢且不流暢。
隨著AI大模型持續發展,行業重點正在從「訓練模型」轉向「模型推理」,意味著對推理基礎設施的需求呈現上升趨勢。例如,無論是OpenAI的o1和o3模型,還是Google的Gemini 2.0 Flash Thinking,均以更高強度的推理策略來提升訓練後結果。
J.巴克萊研報顯示,AI推理計算需求在快速提升,預計未來其將佔通用AI總計算需求的70%以上,推理計算的需求甚至可以超過訓練計算需求,達到後者的4.5倍。
面對行業趨勢,這家成立於2016年的巨型晶圓級芯片公司,展示了AI推理芯片領域創新的巨大潛力。Cerebras憑藉其超快的推理速度、優異的性價比和獨特的硬件設計,將賦予開發者構建下一代AI應用的能力,這些應用將涉及複雜、多步驟的實時處理任務。
從其財務數據來看,Cerebras呈現出快速增長的態勢。2024年上半年,公司實現銷售額1.364億美元,相比2023年同期的870萬美元增長超過15倍。淨虧損也從7780萬美元收窄至6660萬美元。2023年全年,Cerebras淨虧損1.272億美元,營收7870萬美元。公司預計2024年全年銷售額將達到2.5億美元,較2022年的8300萬美元增長201%。
這種高速增長無疑印證了Cerebras的核心競爭力,同時增強了其尋求上市的吸引力。
從更宏觀的角度來看,Cerebras的IPO反映了AI芯片市場的巨大潛力和激烈競爭。目前,英偉達在這一領域佔據約90%的市場份額,但隨著AI技術的普及和應用場景的拓展,市場對高性能AI芯片的需求正在快速增長。除了Cerebras,包括AMD、英特爾、微軟和Google在內的科技巨頭也都在積極佈局AI芯片領域。此外,亞馬遜、Google和微軟等雲服務提供商也開始自主開發AI芯片,以減少對第三方供應商的依賴。
高歌猛進背後,Cerebras仍挑戰重重
然而,儘管Cerebras一路高歌猛進,但其業務和技術也存在一些值得關注的風險因素,這也在一定程度上也反映著整個AI大芯片技術架構廠商存在的共性挑戰與隱憂。
存算一體技術:儘管存算一體技術展現出巨大潛力,但其市場化進程仍面臨挑戰。GPU方案在成本和生態成熟度上仍具有一定優勢。因此,存算一體芯片不僅要通過技術升級降低成本,還需通過實際應用培育市場,強化用戶對超快推理的價值認知。
散熱挑戰:當芯片的面積增加,有更多的電流流過晶體管,半導體電阻自然會產生更多的熱量。如果熱量過高,還會分解芯片及其表面的小部件。英偉達的Blackwell GPU數據中心中,都需要巨型的冷卻系統。而Cerebras的巨無霸芯片,更是需要一套龐大的散熱系統。專門的、龐大的散熱系統也意味著,部署芯片需要額外的配套成本。
客戶生態:英偉達的軟件和硬件堆棧在行業中佔據主導地位,並被企業廣泛採用。在生態系統的成熟度、模型支持的廣泛性以及市場認知度方面,英偉達仍然佔據優勢。相比於Cerebra,英偉達擁有更大的用戶群體和更豐富的開發者工具和支持。Futurum Group分析師指出,雖然Cerebras的晶圓級系統能夠以比英偉達更低的成本提供高性能,但關鍵問題是企業是否願意調整其工程流程以適應Cerebras的系統。
客戶集中度高/供應鏈中斷風險:招股說明書顯示,總部位於阿聯酋的AI公司Group 42在2023年貢獻了Cerebras 83%的收入。這種過度依賴單一客戶的情況可能會給公司帶來潛在風險,拓寬客戶基礎、降低對單一客戶的依賴,將是Cerebras必須面對的挑戰。其次,Cerebras的芯片由台積電生產,公司提醒投資者注意可能的供應鏈中斷風險。
盈利挑戰:儘管Cerebras在技術上處於領先,但其財務狀況卻仍是挑戰。數據顯示,從2022年到2023年,Cerebras累計收入1億美元,但淨虧損則高達3億美元。2024年上半年,儘管收入同比增長1480%,達到了1.364億美元,但淨虧損依舊達到6661萬美元。這表明,儘管收入增長迅猛,Cerebras仍面臨盈利轉化的嚴峻考驗。
市場競爭:隨著人工智能硬件市場的不斷髮展,Cerebras還將面臨來自專業雲提供商、微軟、AWS和Google等超大規模提供商以及Groq等專用推理提供商的競爭。性能、成本和易實施性之間的平衡可能會影響企業採用新推理技術的決策。
寫在最後
在當今快速演變的技術生態系統中,多技術協同升級已成為推動新興技術發展的核心動力。要實現算力的持續增長,GPU、互聯、存儲等技術必須協調發展。雖然GPU技術已取得了顯著進步,但沒有更高效的互聯技術和更快的存儲技術支撐,算力的潛力將無法完全釋放。
對於英偉達等科技巨頭而言,如何繼續推動GPU與其他關鍵技術的協同進化,解決存儲、互聯的瓶頸,將是未來幾年中的主要挑戰。
另一邊,作為一家成立僅8年的初創公司,Cerebras能夠在短時間內發展到挑戰行業巨頭的地步,充分說明了AI技術的巨大潛力和市場的快速變革。如今AI芯片市場的洗牌,不僅是技術的比拚,更是理念和未來願景的對抗。
根據半導體「牧本週期」——芯片類型有規律地在通用和定製之間不斷交替——在某個特定時期內,通用結構最受歡迎,但到達一定階段後,滿足特定需求的專用結構會奮起直追。
當前,英偉達所代表的通用結構時代正處於巔峰。而AI革命為Cerebras等大芯片廠商提供了成為行業領導者的機會,至於該技術路線是否能成為行業主流,還需要靜待市場的檢驗與淬煉。
本文來自微信公眾號:半導體行業觀察 (ID:icbank),作者:L晨光
















 國補的Mac mini真香 很多小夥伴都買了國補後的Mac mini M4 256GB版本吧,只…
國補的Mac mini真香 很多小夥伴都買了國補後的Mac mini M4 256GB版本吧,只…

