DeepSeek突圍奧秘曝光,一招MLA讓全世界抄作業!150+天才集結,開出千萬年薪

新智元報導
編輯:桃子 好睏
【新智元導讀】外媒SemiAnalysis的一篇深度長文,全面分析了DeepSeek背後的秘密——不是「副業」項目、實際投入的訓練成本遠超600萬美金、150多位高校人才千萬年薪,攻克MLA直接讓推理成本暴降……
整整半個月,中國AI承包了國內外各大頭條,影響力只增不減。
關於DeepSeek模型訓練數據、GPU用量、成員構成、RL訓練算法,早已成為所有人的關注焦點。
SemiAnalysis一篇深度報導中,從多個方面進行了推測——訓練成本、對閉源模型利潤影響、團隊等等。

其中一些關鍵亮點包括:
-
DeepSeek不是「副業」,在GPU等硬件支出遠超5億美元,論文中600萬美元僅是預訓練運行GPU成本,研發、硬件總擁有成本(TCO)被排除在外
-
DeepSeek大約有5萬塊Hopper GPU,包括特供版H800和H20
-
DeepSeek大約有150名員工,並定期從北大、浙大等招募頂尖人才,據稱有潛力的候選人能拿到超130萬美元(934萬元)薪金
-
DeepSeek一個關鍵創新——多頭潛注意力(MLA),耗時多月開發,將每個查詢KV量減少93.3%,顯著降低推理價格
-
o3性能遠超R1和o1,GoogleGemini 2.0 Flash Thinking與R1不相上下
-
V3和R1發佈後,H100價格猛漲,傑文斯悖論(Jevonʼs Paradox)正發揮作用
5萬塊Hopper GPU,投資超5億美金
DeepSeek背後頂級投資者幻方量化(High-Flyer),很早就洞察到了AI在金融領域之外的巨大潛力,以及規模化部署的關鍵重要性。
基於這一認知,他們持續擴大 GPU 投資規模。
在使用數千個GPU集群進行模型實驗後,幻方在2021年投資購入了10,000塊A100,這一決策最終證明是極具賽前分析性的。
隨著業務發展,他們在2023年5月決定分拆成立「DeepSeek」,以更專注地推進AI技術發展。由於當時外部投資者對AI領域持謹慎態度,幻方選擇自行提供資金支持。
目前,兩家公司在人力資源和計算資源方面保持密切合作。

與媒體將其描述為「副業項目」不同,DeepSeek已發展成為一個嚴肅且協調有序的重要項目。即使考慮到出口管製的影響,高級分析師估計他們在GPU方面的投資規模已超5億美元。
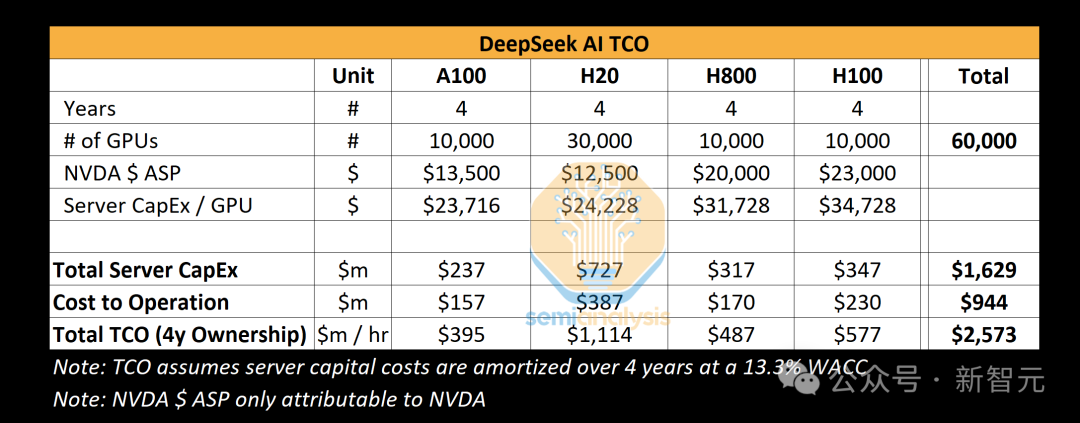
據SemiAnalysis評估,他們擁有約50,000塊Hopper架構GPU,這些計算資源在幻方和DeepSeek之間共享使用,並在地理位置上進行了分散部署,用於交易、推理、訓練和研究等多個領域。
根據分析,DeepSeek在服務器方面的資本支出總額約為16億美元,而運營這些計算集群的成本高達9.44億美元。
150+頂尖人才,年薪934萬
在人才戰略方面,DeepSeek專注於招募中國本土人才,不過分看重候選人的過往履曆,而是更注重其實際能力和求知慾望。
他們經常在北京大學和浙江大學等頂尖高校舉辦招聘活動,現有員工中很多都來自這些學校。
公司的職位設置非常靈活,不會過分限定崗位職責,招聘廣告甚至強調可以自由使用數萬個GPU資源。
他們提供極具競爭力的薪酬待遇,據報導為優秀候選人提供的年薪可達130萬美元以上,遠超其他科技巨頭和AI實驗室的水平。
目前公司約有150名員工,並保持快速擴張態勢。
歷史經驗表明,資金充足且目標明確的創業公司,往往能夠突破現有技術邊界。
與Google等大公司的繁瑣決策流程相比,DeepSeek 憑藉自主融資的優勢,能夠更快速地將創新理念付諸實踐。
有趣的是,DeepSeek在運營模式上卻與Google相似,主要依靠自建數據中心而非外部服務提供商。
這種模式為技術創新提供了更大的實驗空間,使他們能夠在整個技術棧上進行深度創新。
在SemiAnalysis看來,DeepSeek已經成為當今最優秀的「開源權重」(open weights)實驗室,其成就超越了Meta Llama、Mistral等競爭對手。
訓練成本不止600萬美金
DeepSeek的定價策略和運營效率在本週引發了廣泛關注,特別是有關DeepSeek V3訓練成本「600萬美元」的報導。
但事實上,預訓練成本僅是整體投入中的一小部分。
訓練成本解析
高級分析師認為,預訓練階段的支出遠不能代表模型的實際總投入。
據他們評估,DeepSeek在硬件方面的累計投資已遠超5億美元。在開發新架構的過程中,需要投入大量資源用於測試新理念、驗證新架構設計和進行消融實驗(ablation studies)。
比如,作為DeepSeek重要技術突破的多頭潛注意力機制(Multi-Head Latent Attention),其開發週期就長達數月,消耗了大量的人力資源和計算資源。
論文中,提到的600萬美元僅指預訓練階段的GPU直接成本,這隻是模型總成本的一個組成部分。
其中並未包含研發投入、硬件設施的總擁有成本(TCO)等關鍵要素。
舉例來說,Claude 3.5 Sonnet訓練成本就達到了數千萬美元。
如果這就是Anthropic所需的全部投入,他們就不會從Google籌集數十億美元,更不會從亞馬遜獲得數百億美元的投資。
這是因為他們需要持續投入實驗研究、架構創新、數據採集與清洗、人才招募等多個方面。
算法優化,讓性能差距縮小
V3無疑是一個令人矚目的模型,但需要在合適的參照系下評估其成就。
許多分析將V3與GPT-4o進行對比,強調V3超越了後者的性能。這個結論雖然正確,但需要注意GPT-4o是在2024年5月發佈的。
在AI快速迭代的背景下,半年前的技術水平已顯得相對陳舊。
此外,隨著時間推移,用更少的計算資源實現相當或更強的性能,也符合行業發展規律。推理成本的持續下降正是AI進步的重要標誌。

一個典型的例子是,現在可以在普通筆記本電腦上運行的小型模型,已能達到與GPT-3相當的性能水平,而後者在發佈時需要超級計算機進行訓練,且推理階段也需要多個GPU支持。
換言之,算法的持續優化使得訓練和推理同等性能的模型,所需的計算資源不斷減少,這種趨勢在行業內屢見不鮮。

目前的發展趨勢表明,AI實驗室在絕對投入增加的同時,單位投入所能獲得的智能水平提升更為顯著。
據估計,算法效率每年提升約4倍,這意味著實現相同性能所需的計算資源每年減少75%。
Anthropic CEO Dario的觀點更為樂觀,認為算法優化可以帶來10倍的效率提升。
就GPT-3級別的模型推理成本而言,已暴降1200倍。
在分析GPT-4成本演變時,高級分析師還觀察到類似的下降趨勢,儘管仍處於成本優化曲線的早期階段。
與前述分析不同的是,這裏的成本差異反映了性能提升和效率優化的綜合效果,而非保持性能不變的單純比較。
在這種情況下,算法改進和優化措施共同帶來了約10倍的成本降低和性能提升。
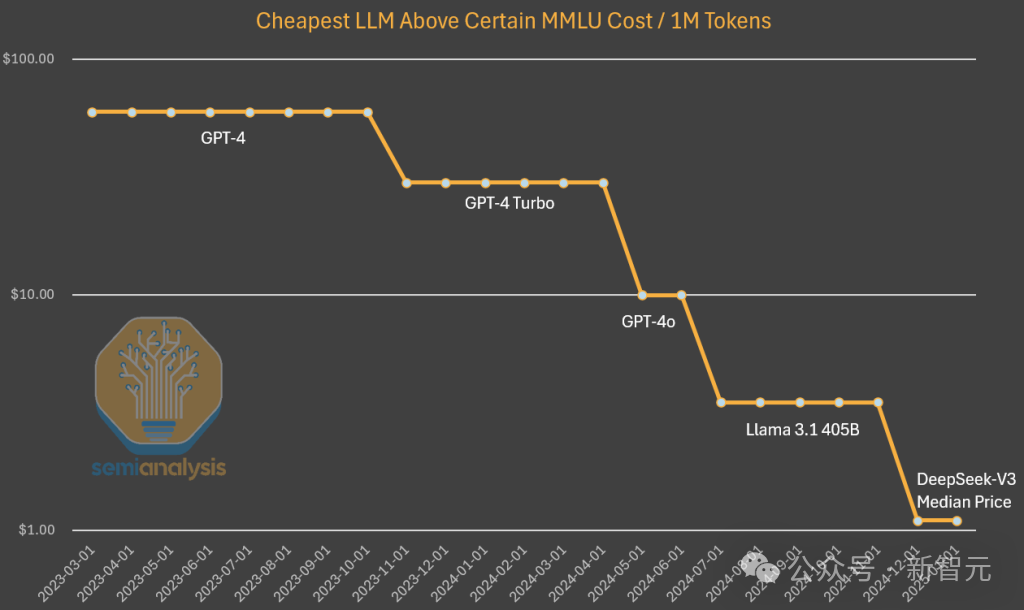
值得強調的是,DeepSeek獨特之處在於他們率先實現了這一成本和性能的突破。
雖然開源模型權重的做法,此前已有Mistral和Llama等先例,但DeepSeek的成就仍然顯著。
考慮到行業發展趨勢,到今年年底,相關成本可能還會進一步下降5倍左右。
R1與o1打和手,「推理」新範式
另一個引人關注的問題是,R1能夠達到與o1相當的性能水平,而o1僅在去年9月才發佈。
那麼,DeepSeek是如何能在如此短的時間內,實現這一跨越的?
其關鍵在於,「推理」這一新範式的出現。
與傳統範式相比,推理範式具有更快的迭代速度,且能以較少的計算資源獲得顯著收益。
正如SemiAnalysis在scaling law報告中指出的,傳統範式主要依賴預訓練,這種方式不僅成本越來越高,而且越來越難以實現穩定的性能提升。
新的推理範式,主要通過合成數據生成和在現有模型基礎上進行後訓練強化學習來提升推理能力,這使得以更低成本獲得快速進展成為可能。
隨著業界逐步掌握這一新範式的擴展技巧,高級分析師預計不同模型之間在能力匹配上的時間差距可能會進一步拉大。
雖然R1在推理性能上確實達到了相當水平,但它並非在所有評估指標上都佔據優勢,在許多場景下其表現甚至不如 o1。

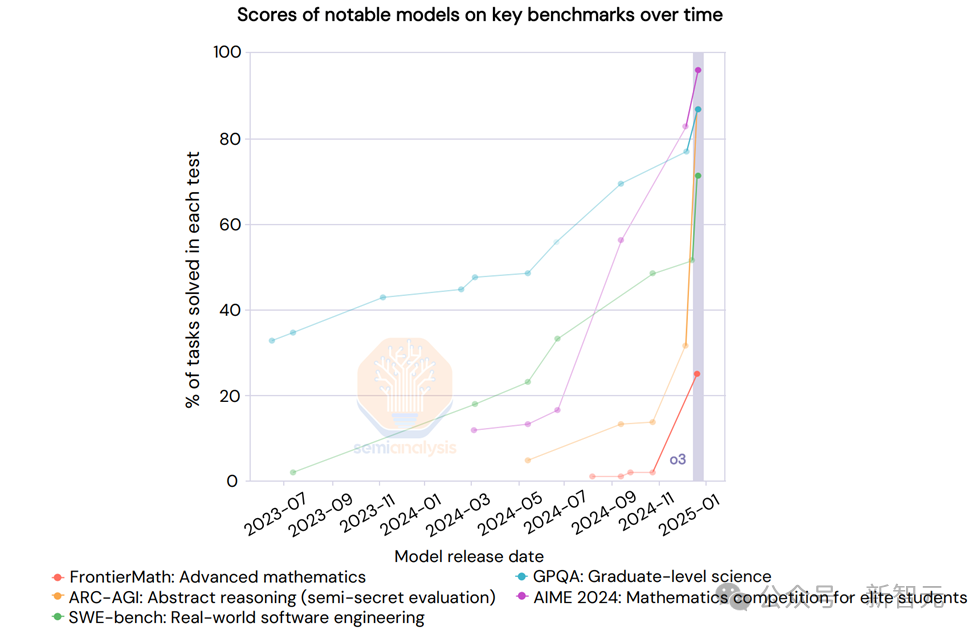
OpenAI最近發佈的o3測試結果顯示,其性能提升幾乎呈現垂直上升趨勢。
這似乎印證了「深度學習遇到了瓶頸」的說法,只是這個瓶頸的性質與以往不同。
Google推理模型,實力相當
在R1引發廣泛關注的同時,一個重要事實往往被忽視:Google在一個月前就推出了一款更具性價比的推理模型——Gemini Flash 2.0 Thinking。
這個模型不僅可以直接使用,而且通過 API 提供了更長的上下文長度。
在已公佈的基準測試中,Flash 2.0 Thinking表現優於 R1,儘管基準測試並不能完全反映模型的真實能力。Google僅公佈了3項基準測試結果,這顯然不足以提供完整的對比。
即便如此,分析師認為Google的模型具有很強的穩定性,在多個方面都能與R1分庭抗禮,只是沒有獲得應有的關注度。
這可能部分源於Google欠佳的市場策略和用戶體驗,也與出乎意料的競爭者R1的到來有關。
需要強調的是,這些比較並不會削弱DeepSeek的突出成就。
正是憑藉快速行動、充足資金、卓越智慧和明確目標的創業公司特質,DeepSeek才能在推理模型的競爭中超越Meta這樣的科技巨頭。
中國MLA創新,讓全世界抄作業
接下來,讓我深入扒一扒DeepSeek所取得的領先實驗室尚未實現的技術突破。
SemiAnalysis高級分析師預計,DeepSeek發佈的任何技術改進,都會被西方實驗室迅速複製。
那麼,這些突破性進展是什麼?
實際上,主要的架構創新與V3模型密切相關,該模型也是R1的基礎模型。
訓練(前期和後期)
不是「下一個token預測」,而是「多token預測」
DeepSeek V3以前所未見的規模實現了多Token預測(MTP)技術,這些新增的注意力模塊可以預測接下來的多個 Token,而不是傳統的單個Token。
這顯著提高了訓練階段的模型性能,且這些模塊可以在推理階段移除。
這是一個典型的算法創新案例,實現了在更低計算資源消耗下的性能提升。
其他方面,雖然DeepSeek在訓練中採用了FP8精度,但像全球一些頂尖的實驗室已經採用這項技術相當長時間了。
DeepSeek V3採用了我們常見的「混合專家模型」(MoE)架構,個由多個專門處理不同任務的小型專家模型組成的大模型,展現出強大的湧現能力。
MoE模型面臨的主要挑戰是,如何確定將哪個Token分配給哪個子模型(即「專家」)。
DeepSeek創新性地採用了一個「門控網絡」(gating network),能夠高效且平衡地將Token路由到相應的專家,同時保持模型性能不受影響。
這意味著路由過程非常高效,在訓練過程中每個Token只需要調整小量參數(相較於模型整體規模)。
這既提高了訓練效率,又降低了推理成本。
儘管有人擔心MoE帶來的效率提升,可能降低投資意願,但Dario指出,更強大的AI模型帶來的經濟效益非常可觀,任何節省的成本都會立即被投入到開發更大規模的模型中。
因此,MoE效率提升不會減少總體投資,反而會加速AI規模化進程。
當前,包括OpenAI、Google、Anthropic等一些公司正專注於擴大模型的計算規模,並提高算法效率。
V3打好了基礎,RL立大功
對於R1而言,它極大地受益於其強大的基礎模型——V3,這在很大程度上要歸功於強化學習(RL)。
RL主要關注兩個方面:格式化(確保輸出連貫性)以及有用性與安全性(確保模型實用且無害)。
模型的推理能力,是在對合成數據集進行微調過程中自然湧現的,這與o1的情況類似。
值得注意的是,R1論文中並沒有提及具體的計算量,因為披露使用的計算資源,會暴露DeepSeek實際擁有的GPU數量遠超過其對外宣稱的規模。
這種規模的強化學習需要龐大的計算資源,特別是在生成合成數據時。
談到蒸餾,R1論文最引人注目的發現可能是,通過具有推理能力的模型輸出來微調較小的非推理模型,使其獲得推理能力。
數據集包含了約80萬個樣本,現在研究人員可以利用R1的思維鏈(CoT)輸出創建自己的數據集,並借此開發具有推理能力的模型。
未來,我們可能會看到更多小模型展現出推理能力,從而提升小模型的整體性能。
多頭潛注意力(MLA)
如開頭所述,MLA是一項重要的技術創新,它顯著降低了DeepSeek模型推理成本。
與標準注意力機制相比,MLA將每次查詢所需的KV緩存減少了約93.3%(KV緩存是Transforme模型中的一種內存機制,用於存儲表示對話上下文的數據,從而減少不必要的計算開銷)。
KV緩存會隨著對話上下文的增長而不斷擴大,這會造成顯著的內存限制。
通過大幅減少每次查詢所需的KV緩存量,可以相應減少每次查詢所需的硬件資源,從而降低運營成本。
MLA這項創新,特別引起了許多美國頂級實驗室的關注。實際上,MLA首次在2024年5月發佈的DeepSeek V2中就已推出。
此外,由於H20芯片比H100具有更高的內存帶寬和容量,DeepSeek在推理工作負載方面獲得了更多效率提升。
R1並非真正動搖o1技術優勢
在利潤率方面,SemiAnalysis發現了一個關鍵現象:R1並非真正動搖了o1的技術優勢,而是以顯著更低的成本實現了相似的性能水平。
這種現象本質上符合市場邏輯,接下來高級分析師將提出一個框架,來分析未來價格機制的運作方式。
技術能力的提升往往能帶來更高的利潤率。
這種情況與半導體制造業的發展模式極其相似,只是節奏更快。就像台積電每當率先突破新製程時,都能獲得顯著的定價優勢,因為他們提供了此前市場上不存在的產品。
其他落後的競爭對手(如三星、英特爾)則會採取較低的定價策略,以在性價比上達到平衡。
對芯片製造商(在這個類比中,即AI實驗室)來說,一個有利條件是他們可以靈活調整產能分配。
當新型號能提供更優的性價比時,他們可以將產能轉移到新型號的生產上。雖然舊型號仍會繼續支持,但會相應減少其供應規模。
這種策略模式與當前AI實驗室的實際運營行為高度吻合,也反映了半導體制造業的基本規律。
率先破局者,手握定價權
這很可能就是AI能力發展的基本規律。
率先突破到新的能力層次,將帶來可觀的價格溢價,而那些能夠快速追趕到相同能力水平的競爭者,只能獲得適度利潤。
如果能為特定應用場景保留較低能力水平的產品,這些產品仍將繼續存在。
但能夠追趕到領先能力水平的公司,將隨著每一代技術更迭而逐漸減少。
所有人見證了,R1取得了領先水平,卻採用了0利潤率的定價策略。
這種顯著的價格差異不禁讓人質疑:為什麼OpenAI的價格如此之高?這是因為他們採用了基於SOTA的前沿定價策略,享受著技術領先帶來的溢價優勢。
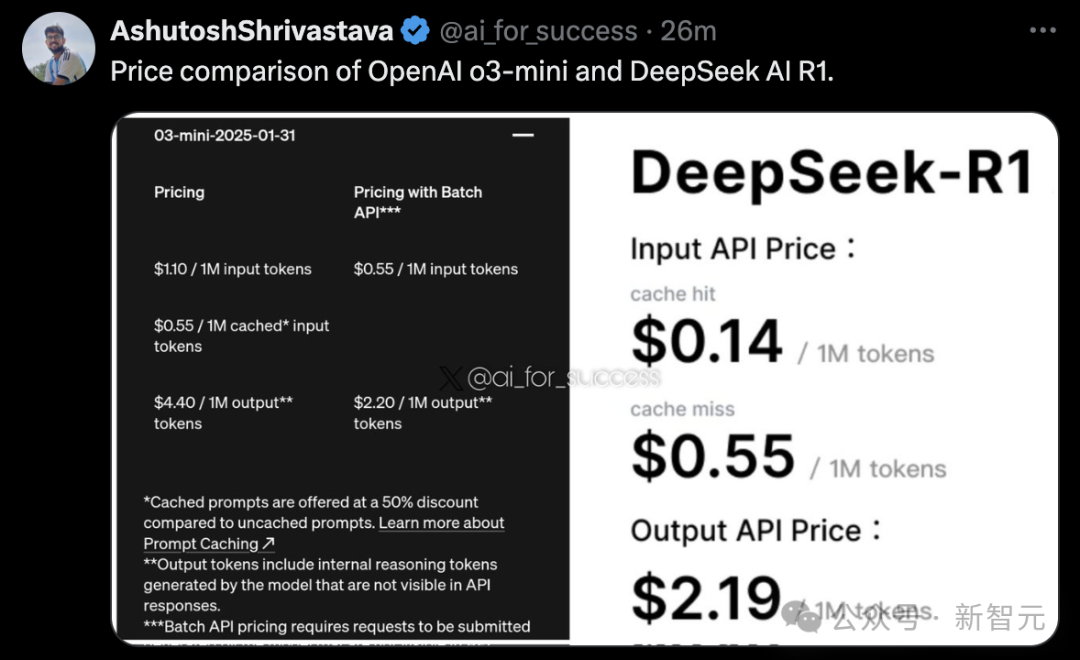 甚至就連剛剛上線的o3-mini,網民也不忘暗諷一下模型的定價
甚至就連剛剛上線的o3-mini,網民也不忘暗諷一下模型的定價SemiAnalysis預計,AI未來的發展速度,將超過領先芯片製造業的發展節奏。
快速實現最新能力意味著可以保持定價權(如ChatGPT Pro),而能力落後則意味著更低的定價,主要收益將流向提供token服務的基礎設施提供商。
當前正處於技術快速迭代的週期,我們將會看到產品以前所未有的速度更新換代。
只要科技公司能夠通過scaling能力來開發出新功能,並在這些功能基礎上創造價值,就應該擁有定價權。
否則,開源模型市場將在下一代技術中迅速商品化。
在這種背景下,高級分析師認為,市場存在一個「根本性的誤解」。
芯片製造業是目前資本最密集的行業,雖然全球沒有任何行業在研發投入上超過半導體行業,但這個最接近的現實類比實際上表明——模型公司發展態勢越快,對高性能芯片的需求也越大。
將AI token與「傑文斯悖論」(技術進步提高效率反而增加資源消耗)進行比較時,我們可以發現深刻的歷史相似性。

最初,業界並不確定是否能持續縮小晶體管尺寸,但當這一可能性得到證實後,整個行業都致力於將CMOS工藝微縮到極限,並在此基礎上構建有意義的功能。
目前,我們正處於整合多個CoT模型和能力的早期階段。
我們正在像早期縮小晶體管一樣scaling模型規模,儘管這在技術進步方面可能會經歷一段異常忙碌的時期,但這種發展趨勢對英偉達來說無疑是利好消息。
免費,還能維持多久?
事實上,市場一直在尋找一個突破點,而這就成為了他們的選擇。
如果DeepSeek願意接受零利潤率甚至負利潤率運營,他們確實可以維持如此低的價格水平。
但顯然,提供前沿token服務的價格彈性閾值要高得多。考慮到DeepSeek正在籌備新一輪融資,這種策略對他們來說是有其戰略意義的。
DeepSeek剛剛在推理能力這個關鍵突破點上,打破了OpenAI的高利潤率格局。
但這種領先優勢能持續多久?
SemiAnalysis對此持懷疑態度——這更像是一個開源實驗室展示了它能夠達到閉源實驗室的能力水平。

高級分析師確實認為,一個更強大的開源實驗室(而DeepSeek現在無疑是其中表現最好的)對新興雲服務提供商(Neoclouds)和各類服務提供商來說是重大利好。
無論採用開源還是閉源模式,計算資源的集中度仍然至關重要。
但如果上層服務提供商選擇免費提供其產品,那麼提升計算資源的商業價值就成為可能。
這意味著更多的資金將流向計算資源提供方而非閉源模型提供商,換句話說,支出將更多地流向硬件設施而非其他環節。
與此同時,軟件企業也將從這一趨勢中獲得巨大收益。
參考資料:
DeepSeek Debates: Chinese Leadership On Cost, True Training Cost, Closed Model Margin Impacts




















