ICLR 2025 | 極性感知線性注意力!哈工深張正團隊提出PolaFormer視覺基礎模型
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文一作孟維康是哈爾濱工業大學(深圳)與鵬城實驗室聯合培養的博士生,本科畢業於哈爾濱工業大學,主要研究方向是大規模基礎模型的高效訓練和推理算法研究。
通訊作者張正教授,哈爾濱工業大學(深圳)的長聘教授及博士生導師,教育部青年長江學者,廣東特支計劃青年珠江學者,深圳市優青。長期從事高效能多模態機器學習的研究,專注於高效與可信多模態大模型。
課題組:Big Media Intelligence (BMI) 歡迎校內外優秀學者的加入以及來訪交流。
課題組主頁:https://cszhengzhang.cn/BMI/

-
論文標題:PolaFormer: Polarity-aware Linear Attention for Vision Transformers
-
論文鏈接:https://arxiv.org/pdf/2501.15061
-
GitHub 鏈接:https://github.com/ZacharyMeng/PolaFormer
-
Huggingface 權重鏈接:https://huggingface.co/ZachMeng/PolaFormer/tree/main
儘管 Vision Transformer 及其變種在視覺任務上取得了亮眼的性能,但仍面臨著自注意力機制時空間平方複雜度的挑戰。為瞭解決這一問題,線性自注意力通過設計新的核函數替換標準自注意力機制中的 softmax 函數,使模型複雜度降低為線性。這篇論文中,研究者提出了一個新的「極性感知線性注意力」模塊,使模型達到了更高的任務性能與計算效率。
具體來說,本工作從線性自注意力方法需要滿足注意力權重矩陣的兩個特性(即正值性和低信息熵)入手。首先,指出了現有的做法為了滿足正值性,犧牲了 Q 矩陣和 K 矩陣元素中負值的缺陷,提出了極性感知的計算方式可以保證 Q 矩陣和 K 矩陣中所有元素可以平等地進行相似度的計算,使計算結果更準確,模型表示能力更強。其次,本文提出只要採用一族具有特殊性質的映射函數,就可以有效降低注意力權重分佈的信息熵,並給出了數學上的證明。
大量的實驗表明,本文提出的線性注意力模塊可以直接替換現有 Vision Transformer 框架中的自注意力模塊,並在視覺基礎任務和 LRA 任務上一致地提升了性能。
引入
Transformer 模型已經在廣泛的視覺任務中展現出亮眼的性能。其核心模塊 —— 通過 softmax 歸一化的點積自注意力機制,讓 Transformer 模型可以有效地捕捉長距離依賴關係。然而,這帶來了模型 O (N^2) 複雜度,在處理長序列影片或高解像度圖像時,會導致相當大的計算開銷和顯存佔用。這限制了它們在資源受限環境中的效率,使得在這些場景下的實際部署變得困難。
線性注意力,作為一種更具可行性的解決方案使用核化特徵映射替換 q,k 點積中的 Softmax 操作,有效地將時間和空間複雜度從 O (N²d) 降低到 O (Nd²)。儘管線性注意力在計算效率上有所提升,但在表達能力方面仍不及基於 Softmax 的注意力,我們的分析確定了造成這種不足的兩個主要原因,它們都源於 Softmax 近似過程中的信息丟失:
-
負值丟失。依賴非負特徵映射(如 ReLU)的線性注意力模型無法保持與原始 q,k 點積的一致性。這些特徵映射僅保留了正 – 正交互作用,而關鍵的正 – 負和負 – 負交互作用則完全丟失。這種選擇性表示限制了模型捕獲全面關係範圍的能力,導致注意力圖的表達能力減弱和判別力降低。
-
注意力分佈高信息熵。沒有 softmax 的指數縮放,線性注意力會導致權重分佈更加均勻且熵更低。這種均勻性削弱了模型區分強弱 q,k 對的能力,損害了其對重要特徵的關注,並在需要精細細節的任務中降低了性能。
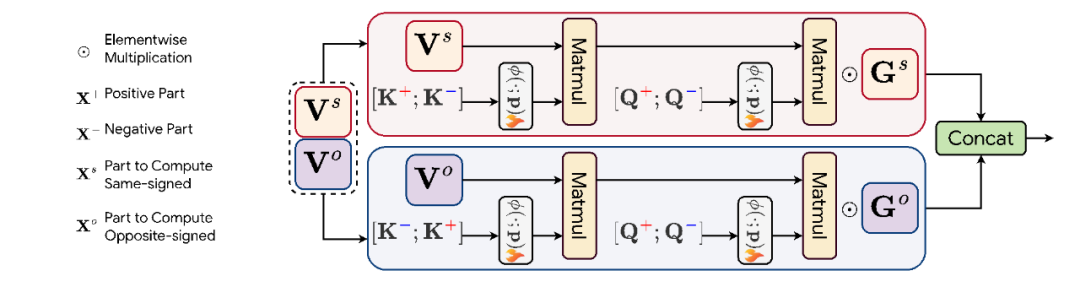
在這項工作中,作者提出了一種極性感知線性注意力(PolaFormer)機制,旨在通過納入被忽略的負交互作用來解決先前線性注意力模型的局限性。與此同時,為瞭解決線性注意力中常見的注意力權重分佈信息熵過高的問題,他們提供了數學理論基礎,表明如果一個逐元素計算的函數具有正的一階和二階導數,則可以重新縮放 q,k 響應以降低熵。這些增強功能共同提供了一個更穩健的解決方案,以縮小線性化和基於 Softmax 的注意力之間的差距。
背景
標準自注意力機制的低效
考慮一個長度為 N、維度為 D 的序列
。該序列被分成 h 個頭,每個頭的維度是 d。在每個頭中,不同位置的標記(token)共同被關注以捕獲長距離依賴關係。輸出可表示為
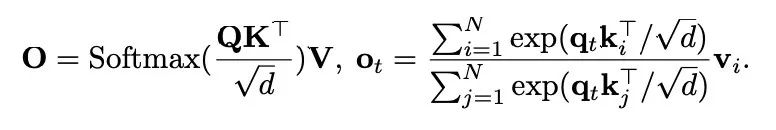
可見,自注意力的複雜度是 O (N2d)。這種複雜度使得自注意力機制在處理長序列時效率低下,導致計算成本急劇上升。目前,降低自注意力的複雜度的主要方法包括但不限於稀疏注意力、線性化注意力以及基於核的注意力等。
基於核的線性注意力
為了緩解標準自注意力機制的效率瓶頸,人們提出了基於核的線性注意力機制,該機制將相似度函數分解為特徵映射的點積。按照 Linear Attention 工作里的符號,我們定義
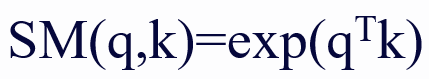
作為 softmax 核函數。從數學上講,線性注意力的目標是使用 ϕ(q_i)ϕ(k_j)^T 來近似 SM (⋅,⋅),則注意力輸出的第 t 行可以重寫為:
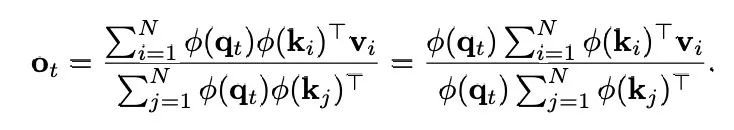
通過利用矩陣乘法的結合律,每個頭的複雜度可以降低到 O (Nd’2),其中 d’是特徵映射後的維度,與序列長度成線性關係。
方法概覽
極性感知注意力
極性感知注意力背後的核心思想是為瞭解決現有線性注意力機制的局限性,這些機制通常會丟棄來自負成分的有價值信息。
PolaFormer 在處理負成分時,極性感知注意力將 query 和 key 向量分解為它們的正部和負部。這種分解允許機制分別考慮正相似度和負相似度對注意力權重的影響。具體來說,對於查詢向量 q 和鍵向量 k,可以將它們分解為:
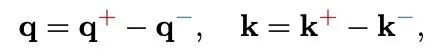
其中,
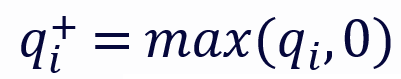
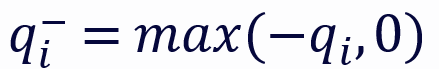
分別代表 q 的正部和負部,同理對於 k。
和
將這些分解代入 q 和 k 的內積中,可以得到:

前兩項捕捉了同號成分之間的相似性,而後兩項則代表了異號成分之間的相互作用。之前的線性注意力方法,如基於 ReLU 的特徵映射,通過將負成分映射到零來消除它們,這在近似 q,k 點積時會導致顯著的信息丟失。
為瞭解決這個問題,極性感知注意力機制根據 q,k 的極性將它們分開,並獨立計算它們之間的相互作用。注意力權重的計算方式如下:
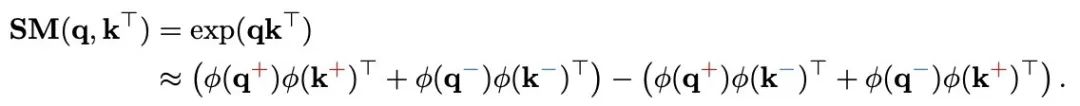
PolaFormer 根據極性明確地將 q,k 對分開,處理在內積計算過程中維度的同號和異號交互作用。這些交互作用在兩個流中處理,從而能夠更準確地重建原始的 softmax 注意力權重。為了避免不必要的複雜性,作者沿著通道維度拆分 v 向量,在不引入額外可學習參數的情況下處理這兩種類型的交互作用。然後,將輸出進行拚接,並通過一個可學習的符號感知矩陣進行縮放,以確保準確重建 q,k 關係。
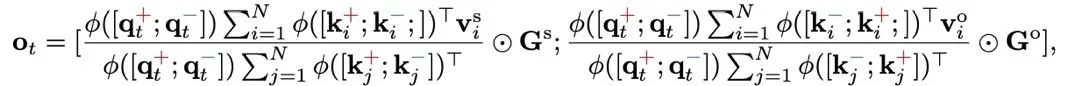
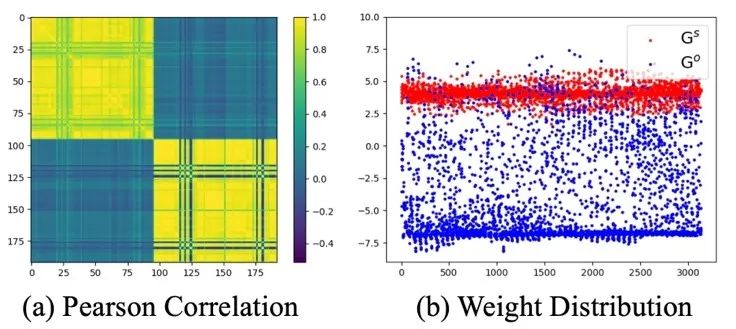
作者統計分析了兩個 G 矩陣的特性,存在一個明顯的負相關和價值差異。這證明了本文提出的可學習混合策略補償了鬆弛減法操作所帶來的影響。
用於降低信息熵的可學習冪函數
為瞭解決線性注意力中常見的注意力權重分佈信息熵過高的問題,作者提供了數學理論基礎,表明如果一個逐元素計算的函數具有正的一階和二階導數,則可以重新縮放 q,k 響應以降低熵。
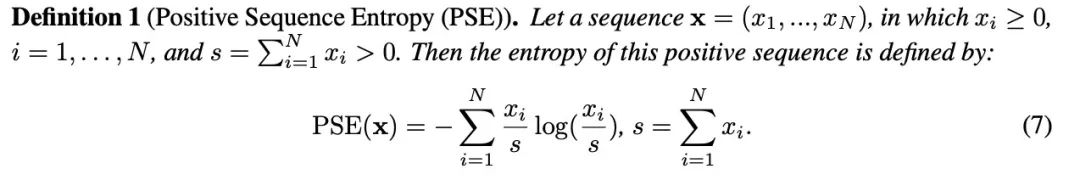

這一理論有助於闡明為什麼先前的特徵映射會提高信息熵,從而導致注意力分佈過於平滑。為了簡化,作者採用通道級可學習的冪函數進行重新縮放,這保留了 Softmax 中固有的指數函數的尖銳性。這使得模型能夠捕獲尖銳的注意力峰值,提高了其區分強弱響應的能力。與此同時,為了區分開不同通道之間的主次關係,作者設計了可學習的冪次來捕捉每個維度的不同重要性
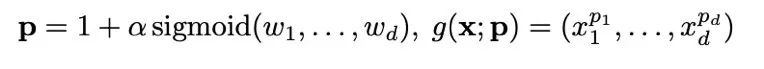
最後,由於之前的理論工作已經表明,自注意力矩陣本質上是低秩的。這一特性在學習 v 向量時可能導致退化解,尤其是在本文的情況下,當需要緊湊的表示來容納極性感知信息時。作者探索了各種技術來增加秩並進行了消融實驗,比如 DWC 和 DCN。
實驗結果
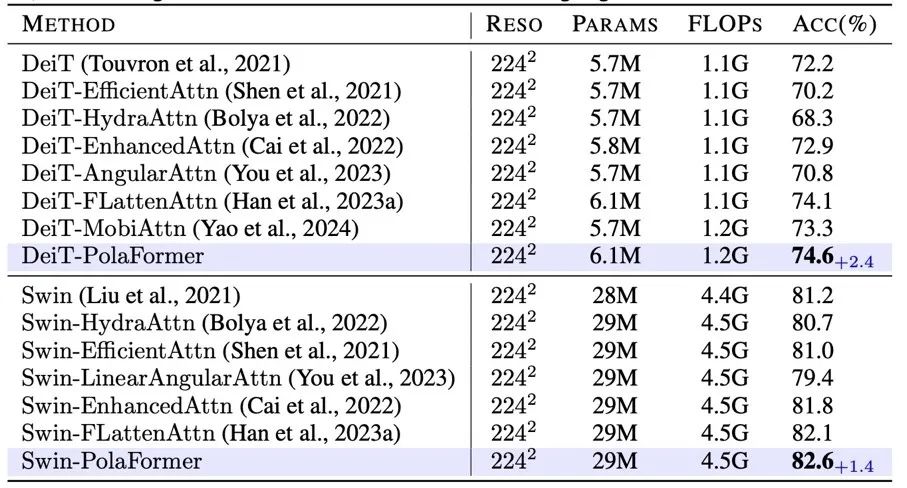
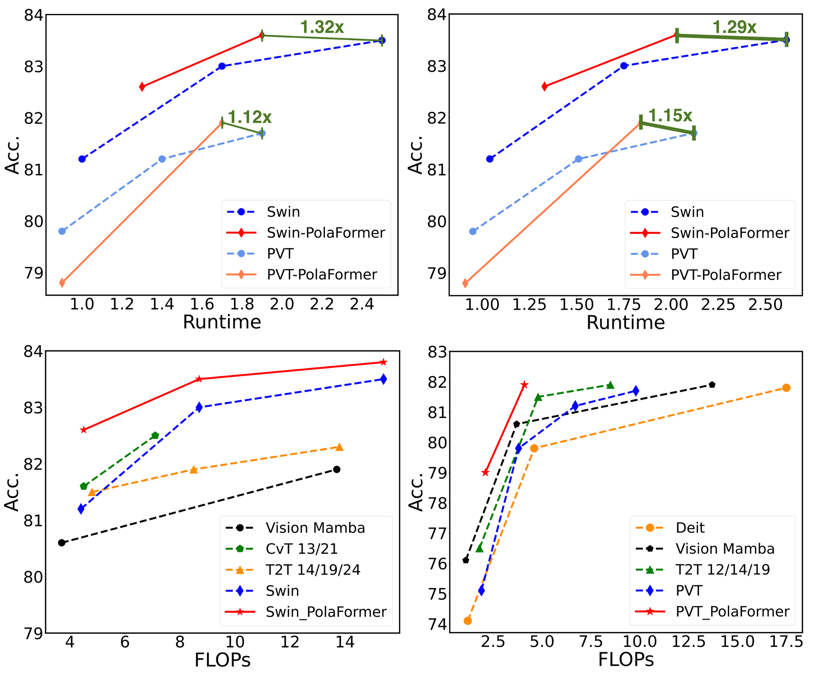
作者對模型在三個任務上進行了評估:圖像分類、目標檢測和實例分割,以及語義分割。作者將模型性能與之前的高效視覺模型進行了比較。此外,他們在 LRA 任務上評估了模型,便於與其他線性注意力模型進行對比。
首先,作者從頭開始在圖像分類任務上訓練了模型。然後,他們在 ADE20K 數據集上對預訓練模型進行微調,用於語義分割任務,還在 COCO 數據集上進行微調,用於目標檢測任務。
結論
在本研究中,作者提出了 PolaFormer,這是一種具有線性複雜度的新型高效 Transformer,主要貢獻如下:
-
本文指出現有方法負值忽略的問題,提出了極性感值的映射函數,讓每個元素都參與到注意力的計算;
-
在理論上,作者提出並證明了存在一族逐元素函數能夠降低熵,並採用了可學習的冪函數以實現簡潔性和重新縮放。
-
此外,作者還使用了卷積來緩解由自注意力矩陣的低秩特性引起的退化解問題,並引入了極性感知係數矩陣來學習同號值和異號值之間的互補關係。



















