4500美元驗證強化學習「魔力」,1.5B模型也能超越o1預覽版,模型、數據、代碼全開源
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
Deepseek-R1 的卓越表現引發了廣泛關注,但其訓練方法始終未曾公開。雖然 Deepseek 的模型已開源,但其訓練方法、數據和腳本等關鍵信息仍未對外披露。
根據 Deepseek 公佈的信息,許多人認為,只有訓練更大規模的模型,才能真正發揮強化學習(RL)的威力。然而,訓練大模型需要龐大的計算資源,讓開源社區望而卻步。目前的工作(如 TinyZero)僅在簡單任務上複現了所謂的 「Aha moment」,或者僅提供訓練基礎設施和數據(如 OpenR)。
一個由伯克利團隊領銜的研究小組提出了一個大膽的想法:能否用僅 1.5B 參數的小模型,以低成本複現 Deepseek 的訓練秘方?他們發現,簡單複現 Deepseek-R1 的訓練方法需要巨大成本,即使在最小的模型上也需要數十萬美元。但通過一系列訓練技巧,團隊成功將成本大幅降低,最終僅用 4500 美元,就在一個 1.5B 參數的模型上複現了 Deepseek 的關鍵訓練方法。
他們的成果 ——DeepScaleR-1.5B-Preview,基於 Deepseek-R1-Distilled-Qwen-1.5B 模型,通過強化學習(RL)微調,實現了驚人的 43.1% Pass@1 準確率,提升了 14.3%,並在 AIME 2024 競賽中超越了 O1-Preview。
這一成果不僅打破了 「大模型才能強大」 的固有認知,更展示了 RL 在小型模型中的無限可能。
更重要的是,伯克利團隊開源了所有的訓練秘方,包括模型、數據、訓練代碼和訓練日誌,為推動 LLM 強化學習訓練的普及邁出了重要一步。

-
博客地址:https://pretty-radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2
-
項目地址:https://github.com/agentica-project/deepscaler
-
項目網站:https://agentica-project.com/
-
Hugging Face 模型:https://huggingface.co/agentica-org/DeepScaleR-1.5B-Preview
-
Hugging Face 數據集:https://huggingface.co/datasets/agentica-org/DeepScaleR-Preview-Dataset
-
Wandb 訓練日誌:https://wandb.ai/mluo/deepscaler-1.5b?nw=nwusermluo
這項研究一經公佈,受到網民廣泛好評,有網民表示:「DeepScaleR-1.5B-Preview 正在撼動人工智能領域。」
「DeepScaleR 開創了 AI 擴展的新時代。」
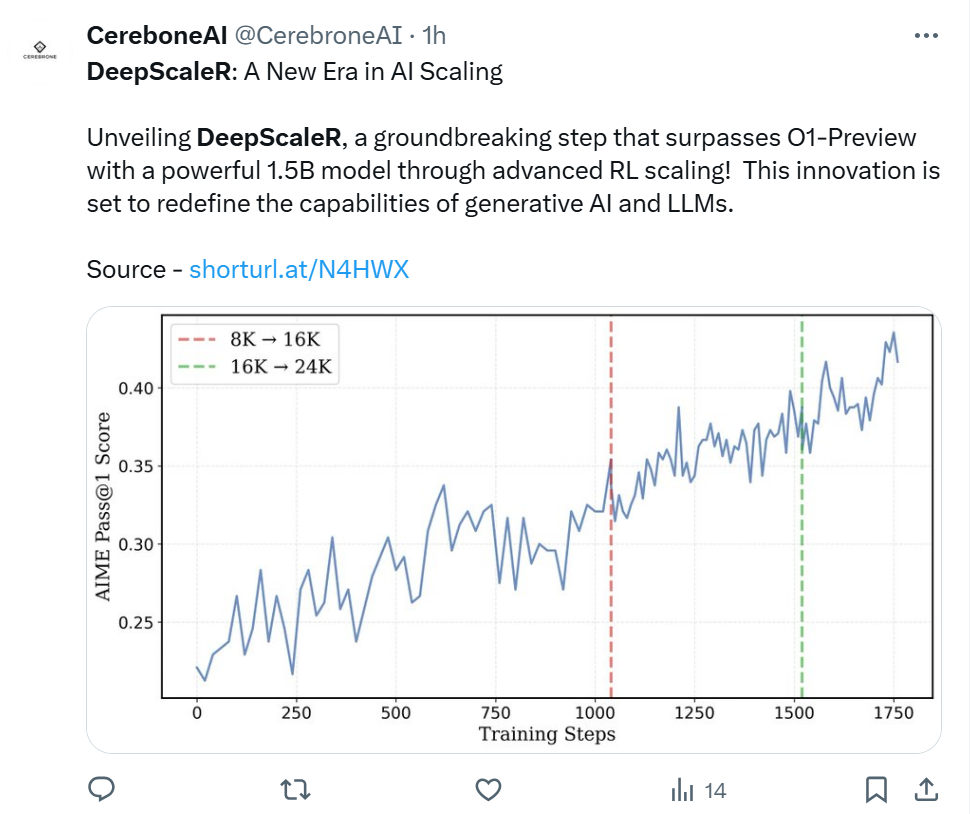
「開源界又贏了一局。」

還有人盛讚:「這才是研究者想要的東西。」
1. 小模型的反擊:DeepScaleR 的秘密
挑戰 RL 的極限
強化學習一直被視為大模型的 「專屬武器」,高昂的計算成本讓很多人望而卻步。研究團隊發現,假如直接複現 Deepseek-R1 的結果 (32K 上下文長度,8000 訓練步數),即使在一個 1.5B 的小模型上,需要的 A100 GPU 時長高達 70,000 小時。但研究團隊並未退縮,他們提出了一種巧妙的策略,讓 RL 的訓練成本降低至常規方法的 5%,最終只用了 3800 A100 GPU 小時和 4500 美元,就在 1.5B 的模型上訓練出了一個超越 OpenAI o1-preview 的模型,DeepScaleR 的秘密,在於提出了一個迭代式上下文擴展的訓練策略。
迭代式上下文擴展:小步快跑,突破瓶頸
在 RL 訓練中,上下文窗口的選擇至關重要。選擇一個比較長的上下文會導致訓練變慢,而選擇一個短的上下文則可能導致模型沒有足夠的上下文去思考困難的問題。
研究團隊在訓練前進行了先驗測試,發現錯誤答案的平均長度是正確答案的 3 倍。這表明,如果直接在大窗口上進行訓練,不僅訓練速度慢,效果也可能受限,因為有效訓練的字符(token) 數量較少。
基於這個發現,因此他們採用了迭代式上下文擴展策略:
1.8K 上下文窗口:模型先在較短的上下文中簡化自己的推理,精進推理技巧。
2. 擴展至 16K & 24K:逐步加大窗口,讓模型適應更複雜的數學推理任務。
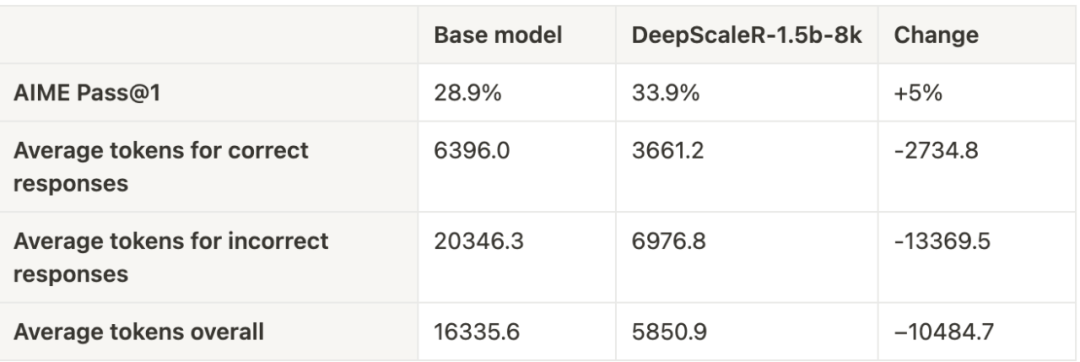
這種策略證明是有效的 —— 在第一輪 8K 上下文訓練後,模型的平均回答長度從 9000 字符降至 3000 字符,而 AIME 測試集上的正確率提高了 5%。隨著上下文窗口擴展至 16K 和 24K,模型更簡潔的回答方式使訓練時間至少提升了兩倍。
數據集:四萬道數學難題的試煉
團隊精心構建了一套高質量的數學訓練集,包括:
-
AIME(1984-2023)
-
AMC(2023 年前)
-
Omni-MATH & Still 數據集
數據篩選的關鍵步驟:
1. 答案提取:利用 gemini-1.5-pro-002 自動提取標準答案。
2. 去重:採用 sentence-transformers/all-MiniLM-L6-v2 進行語義去重,避免數據汙染。
3. 過濾不可評分題目:確保訓練數據的高質量,使模型能夠專注於可驗證的答案。
獎勵函數:精準激勵模型進步
傳統的 RL 訓練往往使用過程獎勵模型(PRM),但容易導致 「獎勵濫用」,即模型學會取巧而非真正優化推理能力。為瞭解決這一問題,研究團隊選擇了跟 Deepseek-R1 一樣的結果獎勵模型(ORM),嚴格按照答案正確性和格式進行評分,確保模型真正提升推理能力。
2. 實驗結果:數據不會說謊
在多項數學競賽基準測試中,DeepScaleR-1.5B-Preview 展現了驚人的實力:
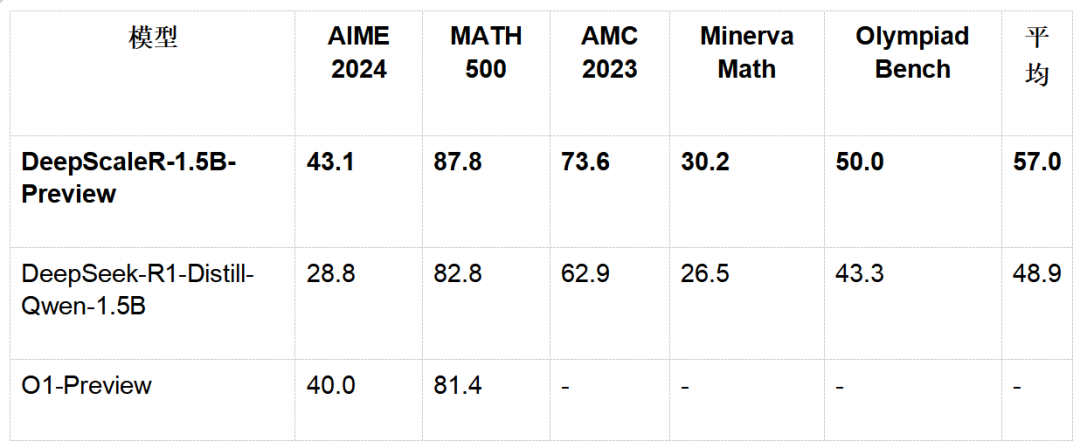
關鍵突破點:
1.DeepScaleR 在 AIME 2024 上超越 O1-Preview,證明了 RL 在小模型上的可行性。
2. 在所有測試集中,DeepScaleR 的平均表現遠超基礎模型,展現了強化學習的巨大潛力。
3. 關鍵發現:為什麼 DeepScaleR 能成功?
(1)RL 並非大模型專屬,小模型同樣能崛起
DeepScaleR 的成功打破了強化學習只能用於大模型的迷思。研究團隊通過高質量的 SFT 數據,讓 1.5B 小模型的 AIME 準確率從 28.9% 提升至 43.1%,證明了小模型也能通過 RL 實現飛躍。
(2)迭代式上下文擴展:比暴力訓練更高效
直接在 24K 上下文窗口中進行強化學習,效果遠不如逐步擴展。先學短推理,再擴展長推理,可以讓模型更穩定地適應複雜任務,同時減少訓練成本。
4. 結論:RL 的新紀元
DeepScaleR-1.5B-Preview 的成功,不僅展示了小模型在強化學習中的無限潛力,也證明了高效訓練策略的重要性。團隊希望通過開源數據集、代碼和訓練日誌,推動 RL 在 LLM 推理中的廣泛應用。
下一步,他們計劃在更大規模的模型上複現這一策略,並邀請社區共同探索 RL 的新可能。
或許,下一個挑戰 OpenAI 的模型,就藏在這樣一個小小的實驗之中。