清華一作 1B 暴打 405B 巨無霸,7B 逆襲 DeepSeek R1!測試時 Scaling 封神
【導讀】僅憑測試時Scaling,1B模型竟完勝405B!多機構聯手巧妙應用計算最優湯臣S策略,不僅0.5B模型在數學任務上碾壓GPT-4o,7B模型更是力壓o1、DeepSeek R1這樣的頂尖選手。
今天,一篇多機構聯合發表的論文,在AI圈引起轟動。
憑藉重新思考計算最優的測試時Scaling,1B模型竟然超越了405B?
隨著OpenAI o1證明了測試時擴展(湯臣S)可以通過在推理時分配額外算力,大幅增強LLM的推理能力。測試時計算,也成為了當前提升大模型性能的最新範式。
那麼,問題來了:
在不同的策略模型、過程獎勵模型和問題難度級別下,如何最優地擴展測試時計算?
擴展計算在多大程度上可以提高大語言模型在複雜任務上的表現,較小的語言模型能否通過這種方法實現對大型模型的超越?
對此,來自清華、哈工大、北郵等機構的研究人員發現,使用計算最優湯臣S策略,極小的策略模型也可以超越更大的模型——
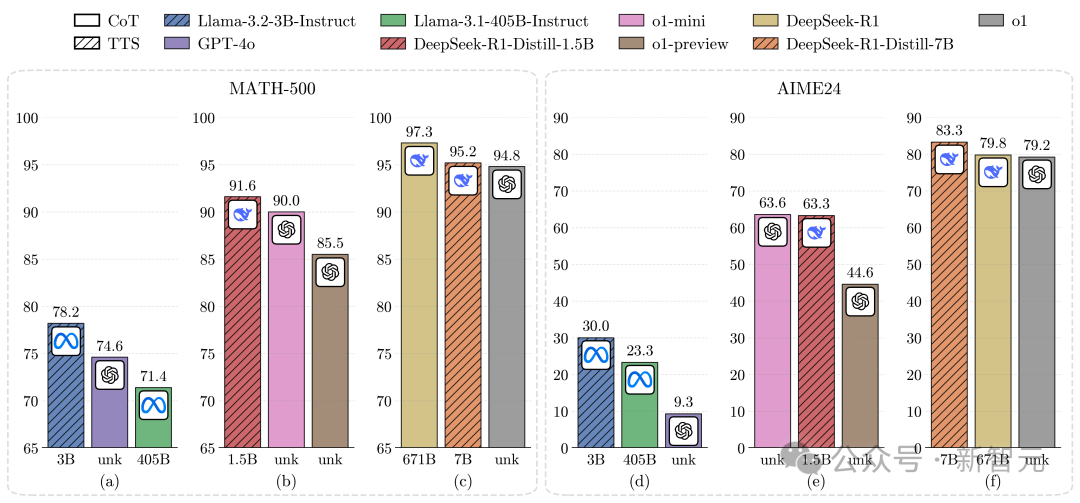
在MATH-500和AIME24上,0.5B模型的表現優於GPT-4o;3B模型超越了405B模型;7B模型直接勝過o1和DeepSeek-R1,還具有更高的推理性能。
 論文地址:https://arxiv.org/abs/2502.06703
論文地址:https://arxiv.org/abs/2502.06703這就表明,湯臣S是增強LLM推理能力的一種極有前途的方法。
同時,這也體現了研究真正的「弱到強」方法,而非當前的「強到弱」監督,對策略優化的重要性。
重新思考「計算最優」的測試時Scaling
計算最優的擴展策略應當是獎勵感知的
計算最優的測試時Scaling,旨在為每個問題分配最優計算資源。
根據此前的研究,一種方法是使用單一的PRM作為驗證器在策略模型的響應上訓練PRM並將其用作驗證器,以對同一策略模型進行湯臣S;另一種方法則是使用在不同策略模型上訓練的PRM來進行湯臣S。
從強化學習(RL)的角度來看,前者獲得的是在線PRM,後者則是離線PRM。
在線PRM能為策略模型的響應產生更準確的獎勵,而離線PRM由於分佈外(OOD)問題往往會產生不準確的獎勵。
對於計算最優湯臣S的實際應用而言,為每個策略模型訓練一個用於防止OOD問題的PRM在計算上是昂貴的。
因此,研究人員在更一般的設置下研究計算最優的湯臣S策略,即PRM可能是在與用於湯臣S的策略模型不同的模型上訓練的。
對於基於搜索的方法,PRM指導每個響應步驟的選擇,而對於基於采樣的方法,PRM在生成後評估響應。
這表明:(1)獎勵影響所有方法的響應選擇;(2)對於基於搜索的方法,獎勵還會影響搜索過程。
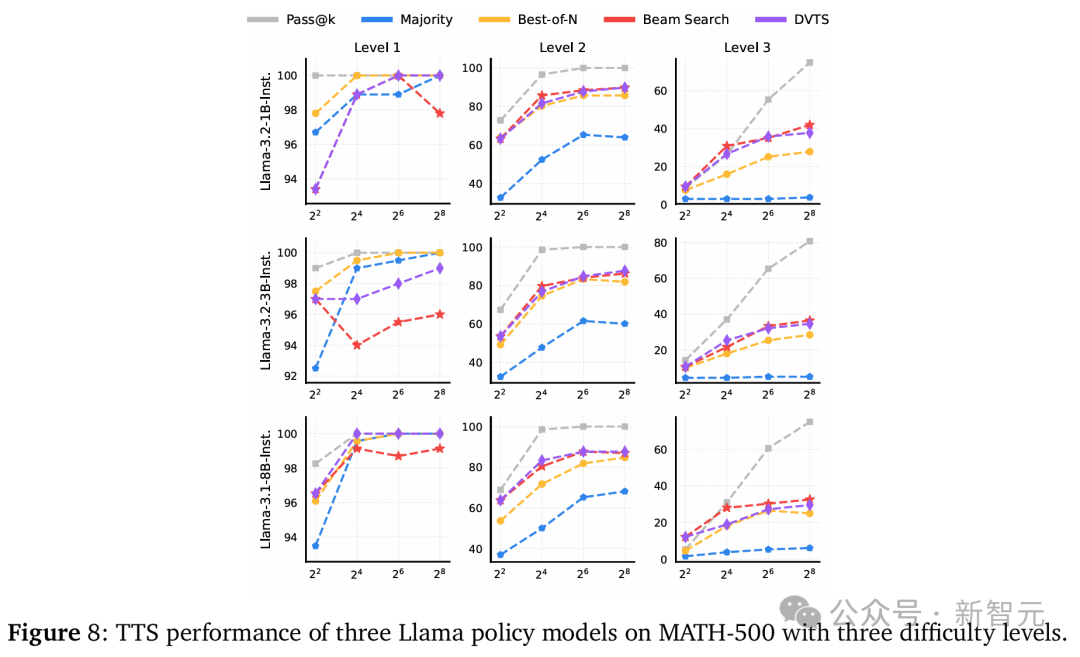
為分析這些要點,團隊使用Llama-3.1-8BInstruct作為策略模型,RLHFlow-PRM-Mistral-8B和RLHFlow-PRM-Deepseek-8B作為PRM,進行了一項初步的案例研究。
 獎勵會顯著影響生成的過程和結果
獎勵會顯著影響生成的過程和結果RLHFlow-PRM-Mistral-8B對短響應給予高獎勵,卻產生了錯誤的答案;而使用RLHFlow-Deepseek-PRM-8B進行搜索雖然產生正確答案,但使用了更多token。
基於以上發現,研究人員提出獎勵應該被整合到計算最優的湯臣S策略中。將獎勵函數表示為ℛ,獎勵感知計算最優湯臣S策略表述如下:
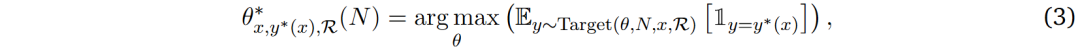
其中Target(𝜃, 𝑁, 𝑥, ℛ)表示在計算預算𝑁和提示詞𝑥條件下,由獎勵函數ℛ調整的策略模型𝜃輸出分佈。對於基於采樣的擴展方法,Target(𝜃, 𝑁, 𝑥, ℛ) = Target(𝜃, 𝑁, 𝑥)。
這種獎勵感知策略確保計算最優擴展能夠適應策略模型、提示詞和獎勵函數,從而為實際的湯臣S提供了一個更具普適性的框架。
絕對問題難度標準比數位數更有效
團隊發現,使用來自MATH的難度等級或基於Pass@1準確率分位數的oracle標籤並不有效,這是因為不同的策略模型存在不同的推理能力。
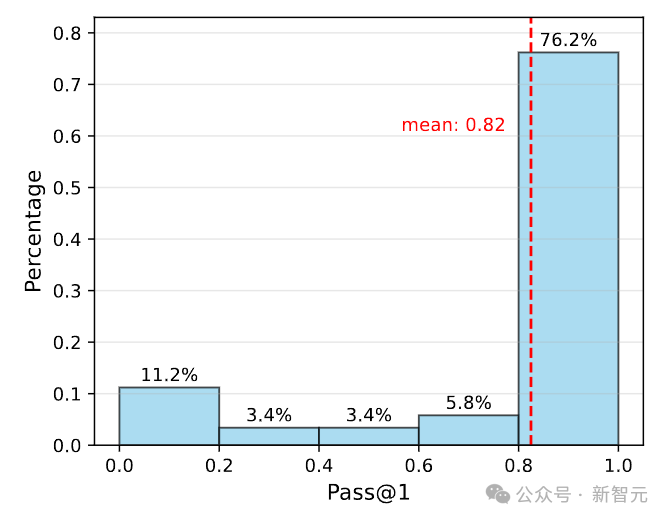
如下圖所示,Qwen2.5-72B-Instruct在76.2%的MATH-500問題上實現了超過80%的Pass@1準確率。
因此,團隊選擇使用絕對閾值,而不是分位數來衡量問題難度。即基於Pass@1準確率,定義三個難度等級:簡單(50%~100%)、中等(10%~50%)和困難(0%~10%)。
如何最優地Scaling測試時計算?
Q1:如何通過不同的策略模型和PRM來提升湯臣S?
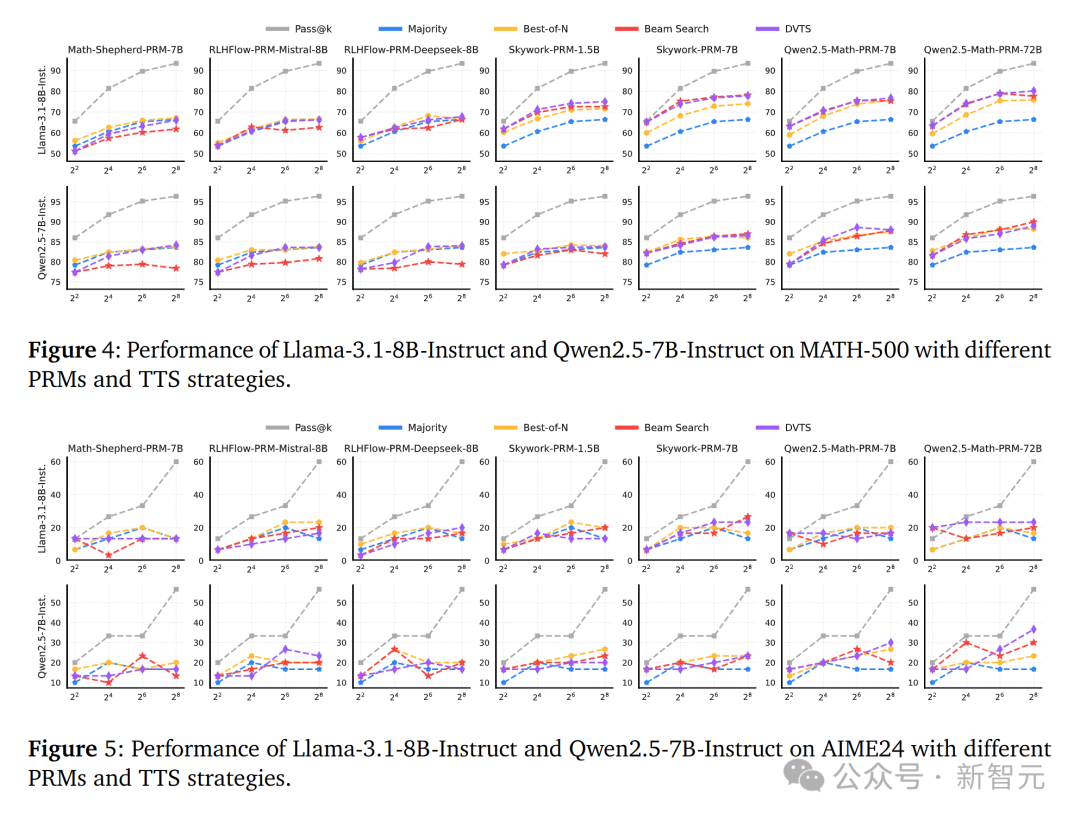
對於Llama-3.1-8B-Instruct模型,研究團隊使用Skywork和Qwen2.5-Math PRM的搜索方法在計算預算增延長性能顯著提升,而使用Math-Shepherd和RLHFlow PRM的搜索方法則效果較差。
對於Qwen2.5-7B-Instruct模型,使用Skywork-PRM-7B和Qwen2.5-Math PRM的搜索方法性能隨計算預算增加而提升,而使用其他的PRM性能仍然較差。
在AIME24數據集上,雖然兩個策略模型的Pass@k準確率隨著計算預算的增加而提高,但湯臣S的性能改進仍然有限。這表明PRM在不同策略模型和任務間的泛化能力是一個挑戰,尤其是在更複雜的任務上。
研究團隊發現當使用Math-Shepherd和RLHFlow PRM時,Best-of-N (BoN) 方法通常優於其他策略。而當使用Skywork和Qwen2.5-Math PRM時,基於搜索的方法表現更好。
這種差異可能源於PRM在處理OOD(超出分佈)策略響應時效果不佳,因為PRM在不同策略模型間的泛化能力有限。使用OOD PRM進行每一步的選擇時可能會導致答案陷入局部最優,從而降低性能。
不過,PRM的基礎模型也可能是一個影響因素,例如,使用Qwen2.5-Math-7B-Instruct訓練的PRM比使用Mistral和Llama作為基礎模型的PRM泛化能力更好。
下圖4和5說明了PRM的選擇對於湯臣S的效果至關重要,並且最佳的湯臣S策略會隨著使用的PRM的不同而改變,同時驗證了PRM在不同策略模型和數據集之間的泛化能力也是一個挑戰。
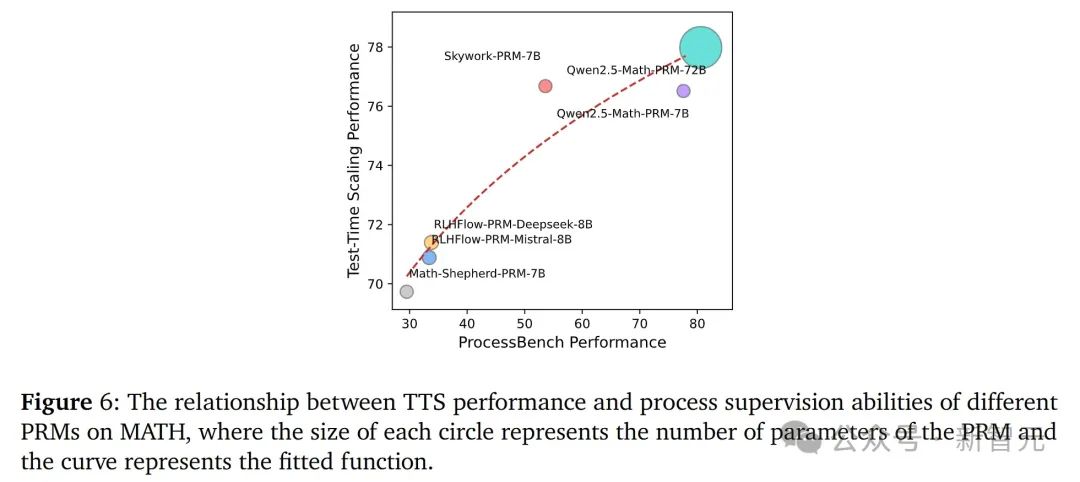
研究團隊發現,湯臣S的性能與PRM的過程監督能力之間存在正相關。具體來說,PRM的過程監督能力越強,其在湯臣S中通常能帶來更好的性能。
團隊擬合了一個函數來描述這種關係,結果說明了 PRM 的過程監督能力對湯臣S性能的重要性。
下圖6表明,PRM的過程監督能力是決定其在湯臣S中性能的關鍵因素。這為開發更有效的PRM提供了方向:應該注重提高PRM的過程監督能力,而不僅僅是增加參數量。
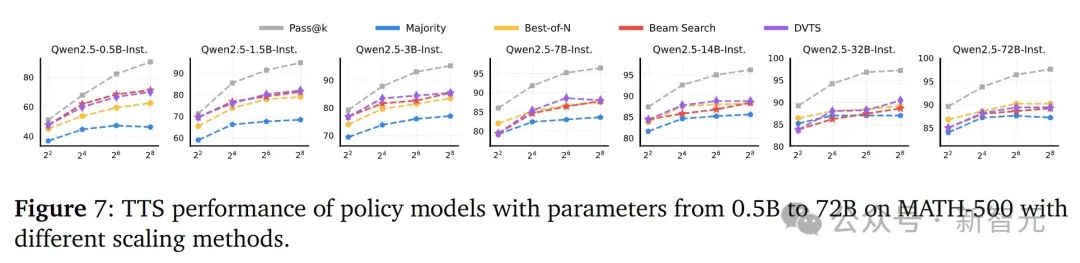
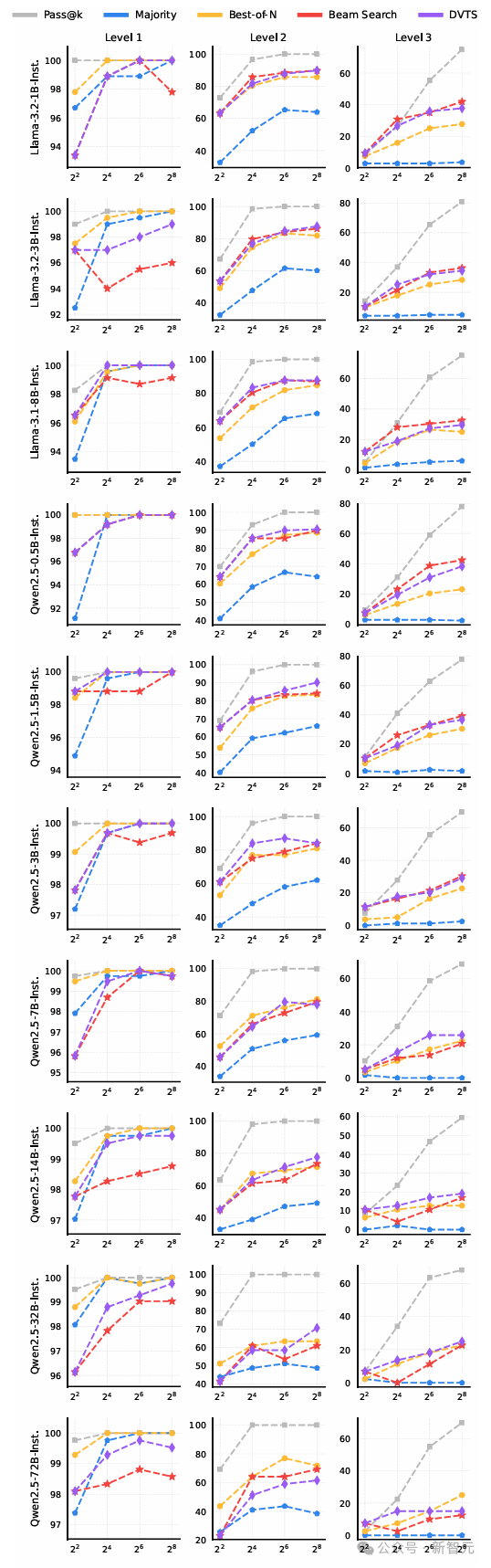
為了得到最優的湯臣S方法,研究中使用了Qwen2.5系列的不同大小LLM(從0.5B到72B)進行實驗。
結果顯示,對於小型策略模型,基於搜索的方法優於BoN3。而對於大型策略模型,BoN比基於搜索的方法更有效。
這可能是因為大型模型具有更強的推理能力,不需要驗證器逐步選擇。而小型模型則依賴於驗證器來選擇每一步,以確保中間步驟的正確性。
下圖7表明最優的湯臣S方法依賴於策略模型的大小,在選擇湯臣S方法時需要考慮模型的推理能力。
Q2:湯臣S在不同難度問題上的改進情況如何?
如前所述,團隊基於Pass@1準確率的絕對值將難度級別分為三組:簡單(50%~100%)、中等(10%~50%)和困難(0%~10%)。
最優的湯臣S方法隨難度級別的不同而變化,結果如下圖所示。
-
對於小規模策略模型(參數少於7B),BoN在簡單問題上表現更優,而束搜索在較難問題上效果更好。
-
對於參數在7B到32B之間的策略模型,DVTS在簡單和中等問題上表現出色,而束搜索更適合困難問題。
-
對於具有72B參數的策略模型,BoN是適用於所有難度級別的最佳方法。
Q3:偏好獎勵模型PRM是否對特定響應長度存在偏差或對投票方法敏感?
PRM對步驟長度存在偏差
研究團隊發現,即使在實驗中使用相同的計算預算進行湯臣S,使用不同PRM在推理中產生的token數量差異顯著。
例如,在相同預算和相同策略模型的情況下,使用RLHFlow-PRM-Deepseek-8B進行擴展的推理token數量始終比使用RLHFlow-PRM-Mistral-8B多近2倍。
這種差異與 PRM 的訓練數據有關。RLHFlow系列PRM的訓練數據來自不同的大語言模型,這可能導致它對輸出長度產生偏差。
為了驗證這一觀點,研究團隊分析了RLHFlow-PRM-Mistral-8B3和RLHFlow-PRM-Deepseek-8B4訓練數據的幾個特性。
如表1所示,DeepSeek-PRM-Data的每個響應平均token數和每個步驟平均token數都大於Mistral-PRM-Data,這表明RLHFlow-PRM-Deepseek-8B的訓練數據比RLHFlow-PRM-Mistral-8B的更長。這可能導致對輸出長度的偏差。
研究團隊還發現,使用Qwen2.5-Math-7B進行擴展的推理token數量大於使用Skywork-PRM-7B的數量,但性能非常接近,這表明使用Skywork-PRM-7B進行搜索更有效率。

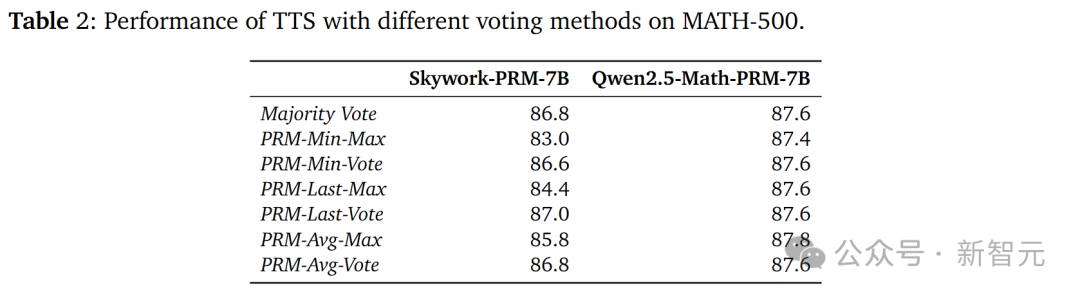
PRM對投票方法具有敏感性
從表2的結果可以看出,Skywork-PRM-7B使用PRM-Vote比使用PRM-Max效果更好,而Qwen2.5-Math-PRM-7B對投票方法不太敏感。
這主要是因為Qwen2.5-Math PRM的訓練數據經過了LLM-as-a-judge(將大語言模型作為判斷器)處理,該處理移除了訓練數據中被標記為正樣本的錯誤中間步驟,使得輸出的高獎勵值更可能是正確的。
這表明PRM的訓練數據對提升其在搜索過程中發現錯誤的能力具有重要意義。
「計算最優」的測試時Sclaing
在計算最優湯臣S策略下,研究人員就另外三大問題,進行了實驗評估。
Q4:較小的策略模型,能否在計算最優湯臣S策略下優於較大的模型?
對小型策略模型進行測試時計算的擴展,對提升LLM的推理性能至關重要。
那麼,較小的策略模型能否通過計算最優的湯臣S策略,超越更大的模型,如GPT-4o、o1、DeepSeek-R1?
如下表3所示,研究人員得出了4點關鍵的洞察:
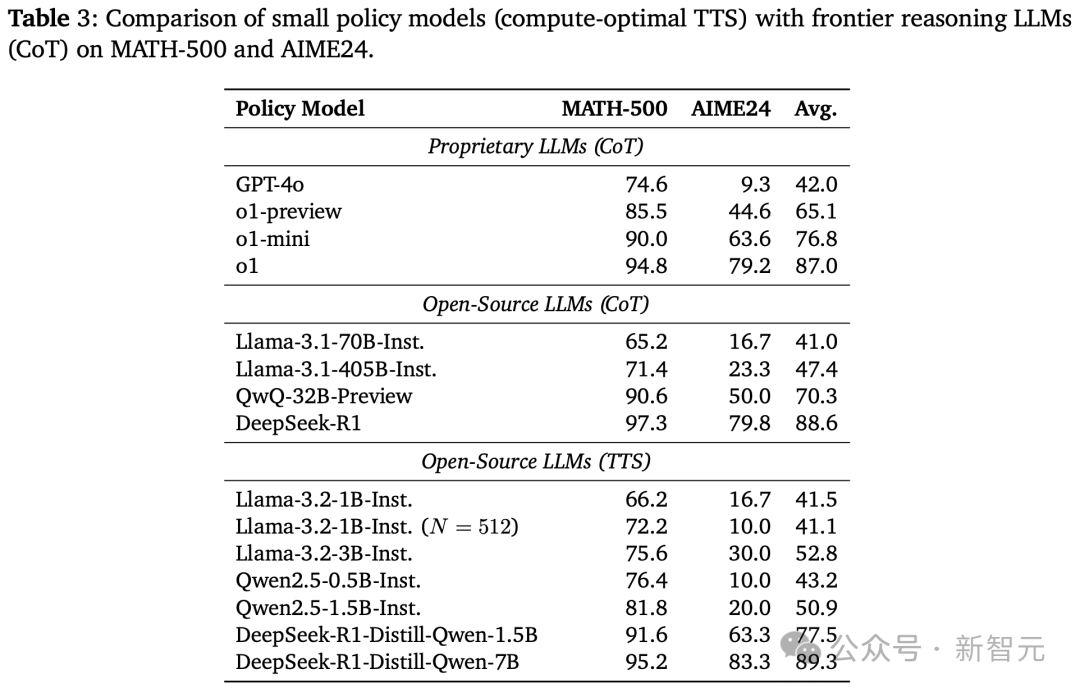
1. 採用計算最優湯臣S策略後,在兩大數學基準MATH-500和AIME24上,Llama-3.2-3B-Instruct性能碾壓Llama-3.1-405B-Instruct。
從這點可以看出,較小模型通過計算最優湯臣S策略,可超越大135倍的模型。
與此前GoogleCharlie Snell團隊等湯臣S相關研究相比,新方法將結果提升了487.0%(23倍→135倍)。
2. 將計算預算增加到N=512,同樣採用計算最優湯臣S的Llama-3.2-1B-Instruct,在MATH-500基準上擊敗了Llama-3.1-405B-Instruct。
奇怪的是,在AIME24上,它的性能又不如Llama-3.1-405B-Instruct。
3. 採用計算最優湯臣S,Qwen2.5-0.5B-Instruct、Llama-3.2-3B-Instruct均超越了GPT-4o。
這表明,小模型可以通過計算最優湯臣S策略,也能一舉超越GPT級別的大模型。
4. 在同樣策略和基準下,DeepSeek-R1-Distill-Qwen-1.5B竟能碾壓o1-preview、o1-mini。
同時,DeepSeek-R1-Distill-Qwen-7B還能擊敗o1和DeepSeek-R1。
以上這些結果表明,經過推理增強的小模型可以,通過計算最優湯臣S策略超越前沿推理大模型。
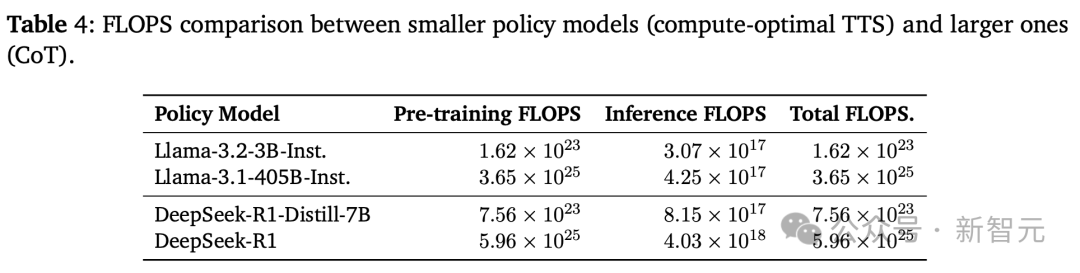
再來看下這些模型FLOPS比較,如下表4所示,小型策略模型即使在使用更少推理FLOPS的情況下,也能超越大型模型,並將總FLOPS減少了100-1000倍。
Q5:計算最優湯臣S與CoT和多數投票相比有何改進?
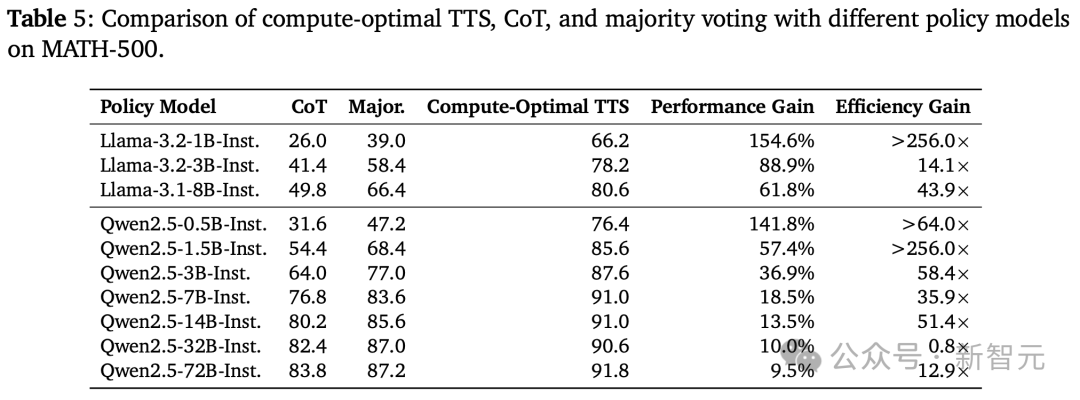
如下表5展示了,每個策略模型在MATH-500上的計算最優湯臣S結果。
結果發現,計算最優湯臣S的效率可以比多數投票高256倍,並且相比CoT提升了154.6%的推理性能。
這些結果表明,計算最優湯臣S顯著增強了LLM的推理能力。
然而,隨著策略模型參數數量的增加,湯臣S的改進效果逐漸減小。這表明,湯臣S的有效性與策略模型的推理能力直接相關。
具體來說,對於推理能力較弱的模型,Scaling測試時計算會帶來顯著改進;而對於推理能力較強的模型,提升效果則較為有限。
Q6:湯臣S是否比基於長CoT的方法更有效?
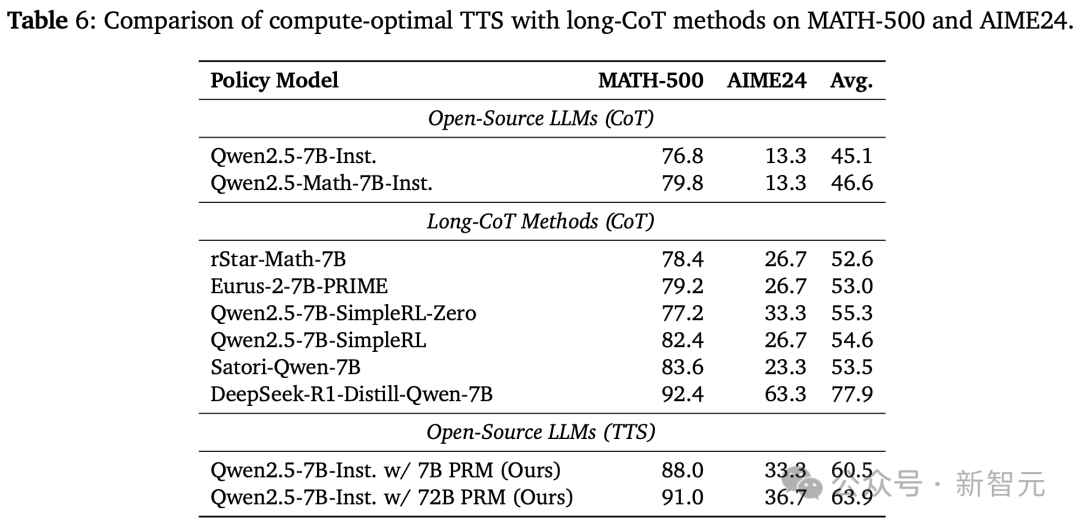
如下表6所示,研究人員發現,在MATH-500和AIME24基準上,使用Qwen2.5-7B-Instruct的湯臣S都優於rStar-Math、Eurus-2、SimpleRL和Satori。
然而,雖然湯臣S在MATH-500上的表現,接近DeepSeek-R1-Distill-Qwen-7B,但在AIME24上表現出明顯下降。
這些結果表明,湯臣S比直接在MCTS生成數據上,應用RL或SFT的方法更有效,但不如從強大的推理模型中進行蒸餾的方法有效。
另外,湯臣S在較簡單的任務上,比在更複雜的任務上更有效。
作者介紹
Runze Liu

Runze Liu是清華大學深圳國際研究生院的二年級碩士生,導師是Xiu Li教授。他曾於2023年6月獲得山東大學的榮譽學士學位。
目前,他也在上海AI Lab大模型中心擔任研究實習生,由Biqing Qi博士指導。
Runze Liu的研究重點是大模型和強化學習(RL)。目前,他對提高大模型的推理和泛化能力特別感興趣,同時也在探索將大模型整合以增強RL算法的潛力,特別是在人類/AI反饋強化學習(RLHF/RLAIF)情況下。
參考資料:
https://arxiv.org/abs/2502.06703
https://ryanliu112.github.io/compute-optimal-tts/