Claude 3.7 Sonnet發佈:別提什麼AGI,我Anthropic要賺企業客戶的錢!

作者|王兆洋郵箱|wangzhaoyang@pingwest.com
Anthropic 的最新模型在加班加點趕工後正式發佈。它被其稱為其迄今為止最智能的模型,以及首款「混合推理模型」 —— Claude 3.7 Sonnet。
Anthropic對這個新模型的一句話介紹是:
一個模型,兩種思考方式(One model, two ways to think)。
新的Claude增加了「標準思考」和「擴展思考模式」兩種不同選項:
「這是市場上首款混合推理模型。Claude 3.7 Sonnet能夠生成近乎即時的響應,也可以進行可被用戶看到的擴展式、分步推理。API用戶還可以對模型的思考時間進行精細控制。Claude 3.7 Sonnet在編程和前端網頁開發方面表現出顯著提升。與該模型一同推出的,還有用於代理編程的命令行工具——Claude Code。Claude Code目前處於有限的研究預覽階段,它能夠讓開發人員直接從終端將重要的工程任務委託給Claude。」
簡單說,你能最直接感受的變化是,Claude多了幾個選項,變得和其他有「Think」模式的ChatBot界面更像了。
刷新榜單排名,但明顯有取捨
此前Claude作為對標ChatGPT的模型工具,是一個強大的語言模型產品,隨著OpenAI的o系列和DeepSeek R1出現,推理能力成了Claude的短板。此次它終於補上了這個今天所有頂級模型必備的能力。
根據它的評測,在主流的幾個評測集上,它領先其他模型。比如在軟件能力 SWE-bench Verified 測試中,Claude 3.7 Sonnet 大幅領先Claude 3.5 Sonnet、OpenAI 的 o3-mini 以及 DeepSeek R1。
在 TAU-bench 測試中也表現不錯,在這個用來評估 LLM 在複雜真實場景中用戶與工具交互能力的基準測試平台上,它同樣實現了 SOTA 。
除了公佈了一系列傳統基準測試成績,有意思的是Claude 3.7 Sonnet還表示,它可以在寶可夢遊戲測試中超越其他模型。
「Claude的擴展思維和代理訓練使其在許多標準評估(如OSWorld)上的表現更佳。」官方寫道。而「玩《Pokemon》——特別是Game Boy經典遊戲《Pokemon 紅色版》——正是這樣一項任務。」
簡單說,就是讓Cluade在超出通常的上下文限制下,去玩《Pokemon》,通過數萬次互動維持遊戲進程。結果發現,Claude 3.0 Sonnet以前幾乎沒法離開故事起點的真新鎮的家,而Claude 3.7 Sonnet改進的代理能力幫助它取得了更大的進展,它成功挑戰了三位寶可夢道館館主(遊戲中的 boss),並贏得了他們的徽章。
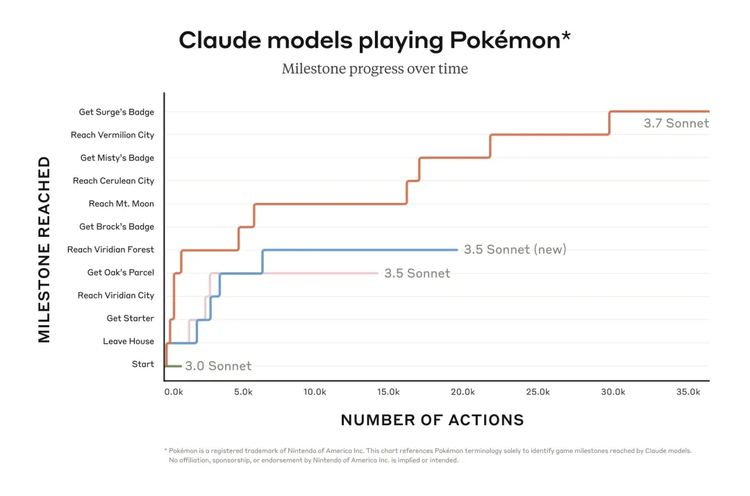
「Claude 3.7 Sonnet在嘗試多種策略和質疑先前假設方面非常有效,這使它能夠在進展過程中提升自身能力。」
Claude 3.7 Sonnet 目前可以通過所有 Claude 產品服務以及 Anthropic API、Amazon Bedrock 和 Google雲Vertex AI 使用。但免費用戶目前還是無法體驗擴展思考模式。
不過,仔細看它公佈的數據排名,會發現一個有意思的現象。
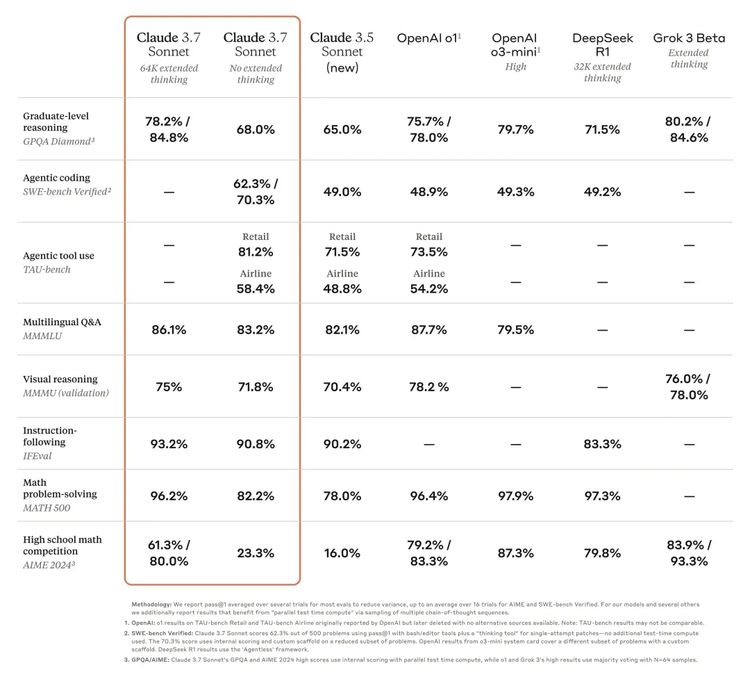
Claude 3.7 Sonnet的深度思考其實更適用於強邏輯推理和數學任務,在數據對比上,對於推理、數學競賽等任務,它並沒有把自己「刷到第一」 ,反而DeepSeek R1 和Grok 3 的模型成績依然得分更高。
甚至在數學上,Claude 3.7 Sonnet給自己測出的成績也不如開源的DeepSeek R1 。但在尤其是Agentic coding的測評上,它遙遙領先其他模型。
顯然Anthropic不只是對測評,也對Claude 3.7 Sonnet的能力建設有所取捨。
所謂「混合推理」,更像是「企業場景定製化」
此前的推理模型,往往是指一個基於某個基礎語言模型,用全新的方法訓練出來的行為方式完全不同的模型,比如OpenAI的o系列,和DeepSeek的R1。而Anthropic一直沒有選擇這個路線,而是認為基礎模型和推理模型的方法都應該屬於一整套模型訓練方法里的不同環節。在o系列發佈後,Anthropic官方也沒有針鋒相對的跟進,但在DeepSeek的開源衝擊下,Claude團隊開始加班加點壓力增加,在其創始人Dario Amodei預告了多次後,Claude 3.7 Sonnet終於發佈。
但在這次的官方文檔中並沒有對這個模型所謂的「混合」方法多做介紹,而更多是體現在功能設計上。新的Claude增加了「標準思考」和「擴展思考模式」兩種不同選項,使用API 的用戶則可以進一步對模型的思考時間進行更詳細的控制,甚至具體到token的用量上。
根據Anthropic的說法,「Claude 3.7 Sonnet 既是普通的 LLM,又是推理模型」。用戶可以選擇讓它正常回答,也可以讓它在回答之前思考更長時間,也就是所謂的推理。
而API 用戶使用 Claude 3.7 Sonnet 時,可以控制「思考預算」(the budget for thinking)。用戶可以要求模型的思考限制在 N 個 token以內,N不超過128K。
所以,看起來從產品層面,它的混合推理指帶的就是對token的控制,目前並沒有介紹更多在模型上混合的方法和帶來的能力的不同。
做個企業喜歡的推理模型
這種思路也直接體現在了對模型的具體場景的優化上。
據Anthropic介紹,在開發這款推理模型時,他們的優化重點並不像其他頂級推理模型那樣,重點放在對數學和編程競賽等數據的優化上。哪怕是在這款他們的首個混合推理模型上,Anthropic就已經將重點放在了「更能反映企業實際使用大模型的方式的現實任務」上了。
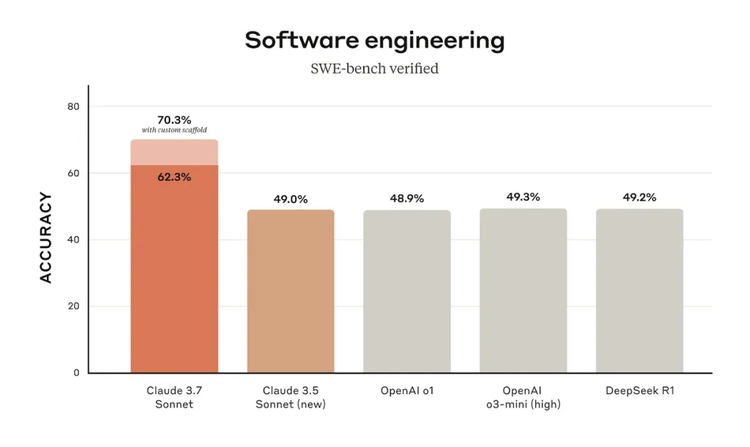
所以在公佈的評測指標上,Claude 3.7 Sonnet 其實在推理表現的某些指標上,依然不及 o3和Grok的模型。
而Anthropic特意強調的則是用來體現模型解決 GitHub 上真實軟件問題能力的 SWE-bench Verified上的表現,它超過了DeepSeek R1,和OpenAI 的 o3-mini 。
因此此次推出Claude 3.7 Sonnet的同時,Anthropic 更新了智能編碼工具 Claude Code。在 Claude.ai 上的編碼體驗也得到更新,比如把GitHub 集成提供給所有Claude付費用戶,他們可以把代碼存儲庫直接連接到 Claude。Claude code的目標也是讓開發人員把大量工程任務委託給 Claude。據其評估,它能一次完成需 45 分鐘以上的人工編程任務,在測試驅動開發、大規模調試和重構代碼的任務上有大幅度提升。
另一個值得注意的地方是,除了讓Claude 3.7 Sonnet 的價格與其前代3.5保持一致外,(每百萬輸入 token 3 美元,每百萬輸出 token 15 美元),而且Anthropic還強調了在標準模式和思考模式里,「模型的提示詞工作方式類似」——這也是一個針對企業級市場的重要的能力,企業用戶們需要一個穩定的使用環境,過往模型的迭代對提示詞的影響很大,不利於企業的部署。
看來,現在Anthropic想的很清楚了——在追求AGI的路上,模型已經沒有壁壘了,在找到技術競爭的新模式之前,必須先要搶實打實的市場,活下去,從Cursor這樣的工具開始,先把對手熬走,才能有機會贏下這場競賽。