飛槳框架3.0推理升級:支持多款主流大模型、DeepSeek-R1滿血版實現單機部署,吞吐提升一倍!
飛槳框架3.0大模型推理部署升級加碼,支持多款主流大模型,MLA、MTP、量化優化全面突破,4比特單機部署 DeepSeek-R1滿血版吞吐提升一倍,立即體驗請直接劃至下方「一鍵式腳本,快速啟動推理」。
飛槳新一代框架3.0全面升級了大模型推理能力,依託高擴展性的中間表示(PIR)從模型壓縮、推理計算、服務部署、多硬件推理全方位深度優化,能夠支持眾多開源大模型進行高性能推理,並在 DeepSeek V3/R1上取得了突出的性能表現。飛槳框架3.0支持了 DeepSeek V3/R1滿血版及其系列蒸餾版模型的 FP8推理,並且提供 INT8量化功能,破除了 Hopper 架構的限制。此外,還引入了4比特量化推理,使得用戶可以單機部署,降低成本的同時顯著提升系統吞吐一倍,提供了更為高效、經濟的部署方案。
在性能優化方面,我們對 MLA 算子進行多級流水線編排、精細的寄存器及共享內存分配優化,性能相比 FlashMLA 最高可提升23%。綜合 FP8矩陣計算調優及動態量化算子優化等基於飛槳框架3.0的 DeepSeek R1 FP8推理,單機每秒輸出 token 數超1000;若採用4比特單機部署方案,每秒輸出 token 數可達2000以上!推理性能顯著領先其他開源方案。此外,還支持了 MTP 投機解碼,突破大批次推理加速,在解碼速度保持不變的情況下,吞吐提升144%;吞吐接近的情況下,解碼速度提升42%。針對長序列 Prefill 階段,通過注意力計算動態量化,首 token 推理速度提升37%。

-
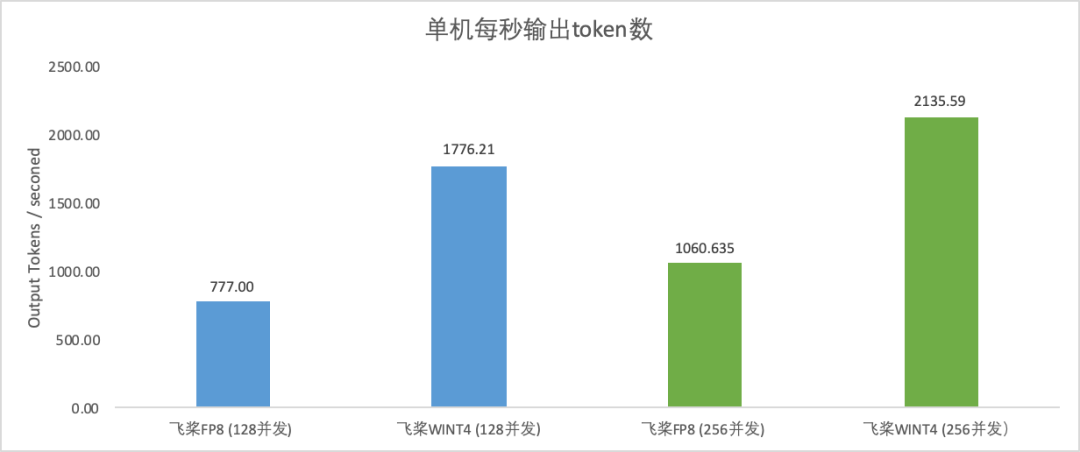
H800上256併發不含 MTP 測試,實驗複現請參考文檔:
https://paddlenlp.readthedocs.io/zh/latest/llm/docs/predict/deepseek.html
除了支持 DeepSeek V3/R1滿血版及其系列蒸餾版模型在 Hopper 架構 GPU 上部署,飛槳框架3.0 還實現了 Weight Only INT8量化,支持在 A800部署;此外,還通過 Weight Only INT4量化,支持單機部署;相比2機部署方案,大大節省了跨機通信耗時,相同併發下可加速101%~128%。
-
H800上256併發不含 MTP 測試,實驗複現請參考文檔:
https://paddlenlp.readthedocs.io/zh/latest/llm/docs/predict/deepseek.html
結合 Hopper 架構的特性,我們通過多級流水線編排、精細的寄存器及共享內存分配,深度調優 MLA 算子性能,相比業內最優方案 FlashMLA,性能領先4%~23%。下面將詳細介紹我們的優化方案。

首先,使用3個 Warp Group(WG),WG0作為 Producer,進行2階段的數據搬運操作;WG1與 WG2作為 Consumer,其中 WG1負責計算 QK GEMM 以及 Softmax 操作,並將結果存儲到共享內存中;而後 WG1與 WG2共同計算 PV GEMM 以緩解寄存器壓力;這種方式下,我們每次處理64長度的 KV,最終佔用了225KB 的共享內存。

其次,為了將 CPV 與 UPRS 操作進行 overlap,在上述的基礎上,將 WG0的流水線增加到四階段,將 PV GEMM 與 Softmax 操作進行 overlap。為了節省寄存器與共享內存,我們每次處理32長度的 KV,該套實現建議在 CUDA12.8版本下使用。

最後,為了進一步對不同操作進行 overlap,使用4個 Warp Group,其中 WG0作為 Producer 進行4階段的數據搬運,WG1作為 Consumer 進行2階段的 QK Gemm 與 Softmax 操作,WG2與 WG3負責 PV GEMM 計算;在使用4個 Warp Group 後,單線程最大寄存器佔用為128個,每次處理32長度的 KV;WG0與 WG1佔用寄存器數量小於72個;WG2與 WG3寄存器佔用數量約184個;因此,理論上通過更精細化的寄存器劃分該方案可行,該方案當前暫開源一套低精度累加實現,後續將持續優化。通過上述一系列的優化,在 Hopper 架構上,MLA 算子速度相較於 FlashMLA 取得了4%~23%的明顯提升。


測試說明:H800 CUDA12.8環境下 NCU 鎖頻統計 Kernel 耗時
飛槳框架3.0在大模型推理方面設計了一套全新的投機解碼通用機制,解耦基礎模型與投機解碼方法,統一了基於草稿模型(Draft Model)、多頭投機解碼(MTP/Eagle)、參考文獻匹配等多種投機解碼範式,僅少量代碼,即可適配新的投機解碼方法。為了極致的性能,我們還優化了注意力機制的實現,支持在解碼階段輸入的 token 長度大於1,在草稿 token 驗證階段,保持批次大小不變的情況下,可一次性完成對所有草稿 token 的推理驗證,解決了大批次下投機解碼劣化推理性能的問題。傳統的草稿 token 驗證,批次大小一般會膨脹草稿 token 數量的倍數,我們高效的注意力機制則可以保持原始批次大小,減少計算量,如下圖所示:
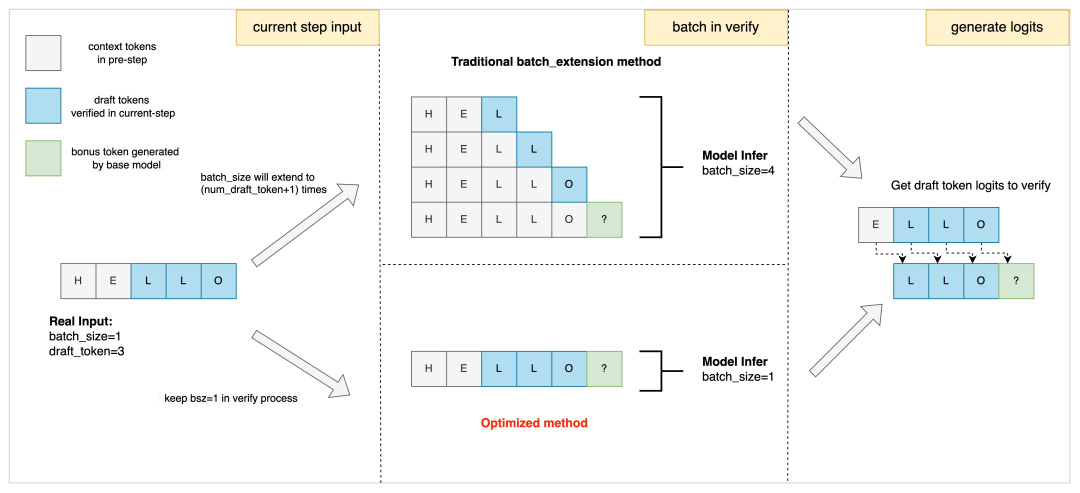
草稿 token 驗證階段注意力計算優化
基於 DeepSeekV3/R1提供的 MTP 權重,我們在多個數據集上統計,第二個 token 的接受率達到80%~90%,達到 DeepSeekV3論文效果。基於飛槳框架3.0的高性能優化:
-
基於實驗1與實驗4,保持解碼速度不劣化(此示例中解碼速度提升25%),QPS 提升144%。
-
基於實驗2與實驗3,保持 QPS 不劣化(此示例中 QPS 提升8%),解碼速度提升42%。
- 基於實驗2與實驗4,保持批次大小不變,在批處理大小為128較大的時候,依然可以保持 QPS 提升32%,解碼速度提升32%。

長序列推理,由於 Attention 計算量與序列長度的平方成正比,量化和稀疏都能取得非常好的加速。飛槳框架3.0大模型推理在基於 Hopper 架構 GPU 上,集成了 Attention 動態量化方案 SageAttention,並優化了 DeepSeek 模型中 Head Dim 為192的情況,在精度近乎無損的基礎上,實現了長序列輸入 Prefill 階段的高性能注意力計算實現,64K 長文輸入首 token 推理速度提升37.4%。

SageAttention 通過動態的將 Q、K 矩陣量化為 INT8,V 矩陣量化為 FP8來重新組織 Attention 計算各階段的數據類型;在 softmax 階段先將 INT32的 Q*K 轉換為FP32,之後進行 Q*K 的反量化,再採用 online softmax 加速計算;將結果 P 量化為 FP8,與經過 FP8量化的 V 矩陣相乘,之後在進行對 V 的反量化,得到 Attention 的計算結果 O。上述兩次量化和反量化過程在保證精度的前提下,大幅度提升了注意力計算的性能。

我們提供了一鍵式腳本,可以幫助開發者們基於飛槳框架3.0快速啟動 DeepSeek-R1服務,並進行推理請求。為了方便測試性能,在文檔「1」(見文末)中我們提供了 benchmark 腳本進行性能測試,下面我們將給出示例。為了避免模型過大導致的下載時間過長問題,我們直接提供了自動下載的腳本,支持下載後再啟動服務進行推理。進入容器後根據單機或多機模型參考文檔「2」(見文末)進行靜態圖下載。
▎單機WINT4推理
以1台 H800為例,部署單機4比特量化推理服務。
-
設置變量 model_name 聲明需要下載的模型,具體支持的靜態圖模型詳見文檔「3」(見文末)。
-
設置模型存儲路徑 MODEL_PATH,預設掛載至容器內/models 路徑下(請確認對存儲路徑 MODEL_PATH 具有寫權限)
export MODEL_PATH=${MODEL_PATH:-$PWD}export model_name="deepseek-ai/DeepSeek-R1/weight_only_int4"docker run --gpus all --shm-size 32G --network=host --privileged --cap-add=SYS_PTRACE \-v $MODEL_PATH:/models \-e "model_name=${model_name}" \-e "MP_NUM=8" \-e "CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7" \-dit ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.1 /bin/bash \-c -ex 'start_server $model_name && tail -f /dev/null'&& docker logs -f $(docker ps -lq)
▎兩機推理
以2台 H800機器為例,介紹如何基於 PaddlePaddle 啟動多機 DeepSeek-R1服務,首先需要保證2台機器互通,下面均以偽 IP 為例。
# 第一個節點(master)ping 192.168.0.1# 第二個節點(slave)ping 192.168.0.2
在2個節點上分別執行下列以下命令,一鍵啟動多機推理鏡像。
-
IP 設置:POD_IPS 為兩機的 IP,POD_0_IP 為第一個節點(master)的 IP,兩機的 POD_0_IP 完全相同。
-
針對兩機模型,預設設置為高吞吐下最優的 BATCH_SIZE 與 BLOCK_BS。關於其他環境變量的說明可以查看文檔「4」(見文末)。
export MODEL_PATH=${MODEL_PATH:-$PWD}export model_name="deepseek-ai/DeepSeek-R1-2nodes/weight_only_int8" #可更換FP8模型export MP_NNODE=${MP_NNODE:-2}export MP_NUM=${MP_NUM:-16}export POD_0_IP=${POD_0_IP:-"192.168.0.1"}export POD_IPS=${POD_IPS:-"192.168.0.1,192.168.0.2"}export BATCH_SIZE=${BATCH_SIZE:-128}export BLOCK_BS=${BLOCK_BS:-40}docker run --gpus all --shm-size 32G --network=host --privileged --cap-add=SYS_PTRACE \-v $MODEL_PATH:/models \-e "model_name=${model_name}" \-e "MP_NUM=${MP_NUM}" \-e "MP_NNODE=${MP_NNODE}" \-e "CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7" \-e "POD_0_IP=${POD_0_IP}" \-e "POD_IPS=${POD_IPS}" \-e "BATCH_SIZE=${BATCH_SIZE}" \-e "BLOCK_BS=${BLOCK_BS}" \-dit ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.1 /bin/bash \-c -ex 'start_server $model_name && tail -f /dev/null'&& docker logs -f $(docker ps -lq)
▎請求推理
curl 請求示例
curl 127.0.0.1:9965/v1/chat/completions -H 'Content-Type: application/json' \-d '{"model":"default","text":"Hello, how are you?"}'
▎API請求示例
鏡像已經提供 openai 的依賴,可以進入容器中進行測試
import openaiclient = openai.Client(base_url=f"http://127.0.0.1:9965/v1/chat/completions", api_key="EMPTY_API_KEY")# 非流式返回response = client.completions.create(model="default",prompt="Hello, how are you?",max_tokens=50,stream=False,)print(response)print("\n")# 流式返回response = client.completions.create(model="default",prompt="Hello, how are you?",max_tokens=100,stream=True,)for chunk in response:if chunk.choices[0] is not None:print(chunk.choices[0].text, end='')
以上就是本次推理升級中單機和兩機部署 DeepSeek-R1服務的示例,請見具體文檔「5」(見文末)。
下週一我們還將開展直播課程及實測活動,進一步幫助大家輕鬆上手體驗 DeepSeek 系列及更多熱門大模型的高性能推理部署。
飛槳框架3.0具備模型壓縮工具、高性能推理引擎、服務化部署全棧工具,除了支持 DeepSeek、Qwen、Llama、Mixtral 等眾多熱門大模型之外,還提供自研的精度無損的量化壓縮方法,支持 INT8、FP8、INT4多種精度類型的量化算法,包含 TensorCore 優化的高性能算子、上下文緩存能力,以及 KV Cache 8比特及4比特量化推理等。除英偉達 GPU 之外,還支持在崑崙芯、昇騰、海光、燧原、太初、Intel CPU 等多種硬件上進行大模型推理,歡迎前往多硬件部署文檔「6」(見文末)實際體驗。未來,飛槳將不斷優化推理部署性能,持續為大家提供高水平的技術服務。
▎官方課程與實測活動
■直播課程
3月17日(下週一)19:00,技術解析加代碼實戰,一線研發大佬為大家詳細解析強大性能提升背後的原理,並結合官方最新開源代碼案例,現場帶大家開箱體驗 DeepSeek-R1等熱門大模型的高性能推理部署!
■實測活動
技術知識的一切問題,代碼會給你答案!官方 case 開源代碼直給、直播課程現場 coding 手把手帶你開箱體驗、官方駐群答疑保駕護航,完成實測任務即可獲得小額獎學金等實用獎勵。
■有獎測評
基於飛槳框架3.0,在技術網站發佈本人真實的測評報告/使用 tips/實際場景應用實例等經驗貼,並提交至官方(下方海報二維碼),即可獲得50-500元獎學金。
文檔「1」:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/llm/benchmark/serving
文檔「2」:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/server/docs/deploy_usage_tutorial.md
文檔「3」:
https://paddlenlp.readthedocs.io/zh/latest/llm/docs/predict/deepseek.html
文檔「4」:
https://paddlenlp.readthedocs.io/zh/latest/llm/server/docs/deploy_usage_tutorial.html
文檔「5」:
https://paddlenlp.readthedocs.io/zh/latest/llm/docs/predict/deepseek.html
文檔「6」:
https://paddlenlp.readthedocs.io/zh/latest/llm/docs/predict/devices.html#