Gemini 2.0的「用嘴改圖」終於上線了,這是AI繪圖的新範式。
Google這兩天動作蠻多。
昨天剛開源Gemma3,然後今天夜裡,鴿了N久的Gemini 2.0的原生多模態生圖功能,也終於開放了。
這也是我對Gemini 2.0最期待的功能。
在出門回來,玩了一下午後,我覺得終於可以給你們分享一下,這玩意的有趣之處了。
先給你們直觀的感受一下,它能幹什麼。
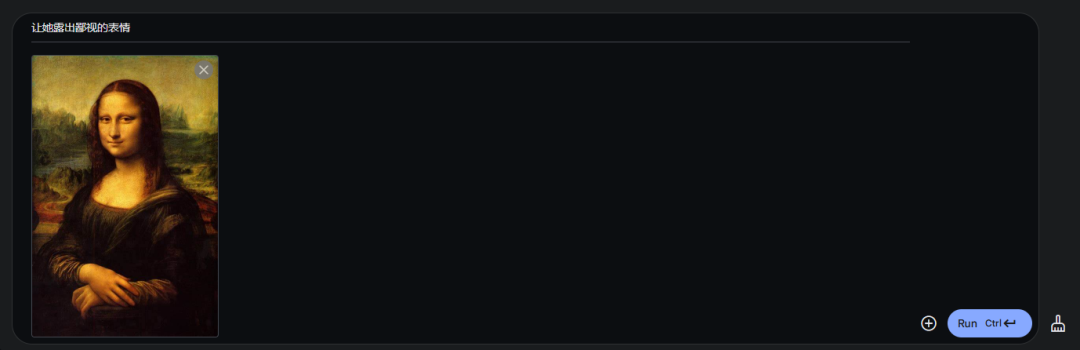
比如我現在有一張圖,是一個很酷的小姐姐。

我想讓這個小姐姐,變成長頭髮。
你無需PS,無需局部重繪,只需要一句話就行。
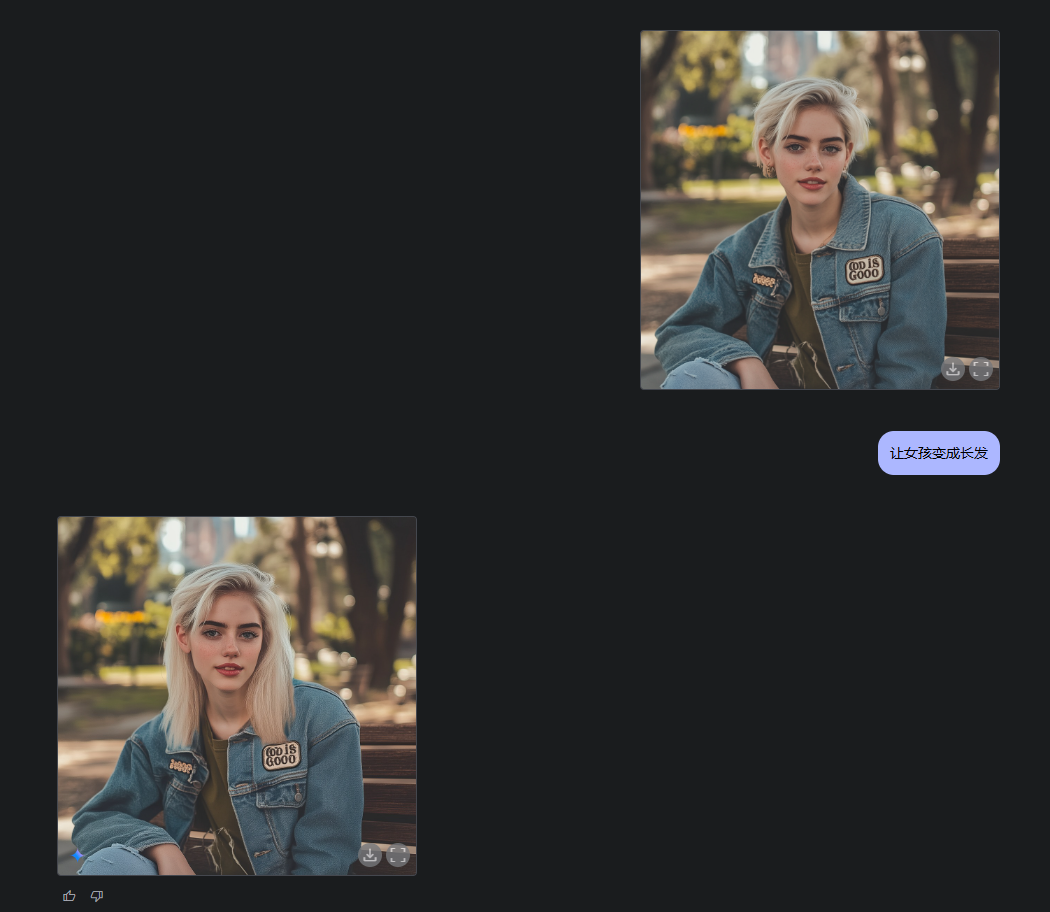
Gemini 2.0,就會瞬間保證所有的其他細節不變的情況下,把小姐姐變成長髮。
我們還可以,一句話,讓她把眼睛閉上。

再把她的臉,換成特朗普。。。

這個效果,emmmm,我無法評價。。。
又或者,這是一套撲克牌的圖。

我想把把最右邊的紅桃A撲克牌,變成梅花2。
一句話,就成。
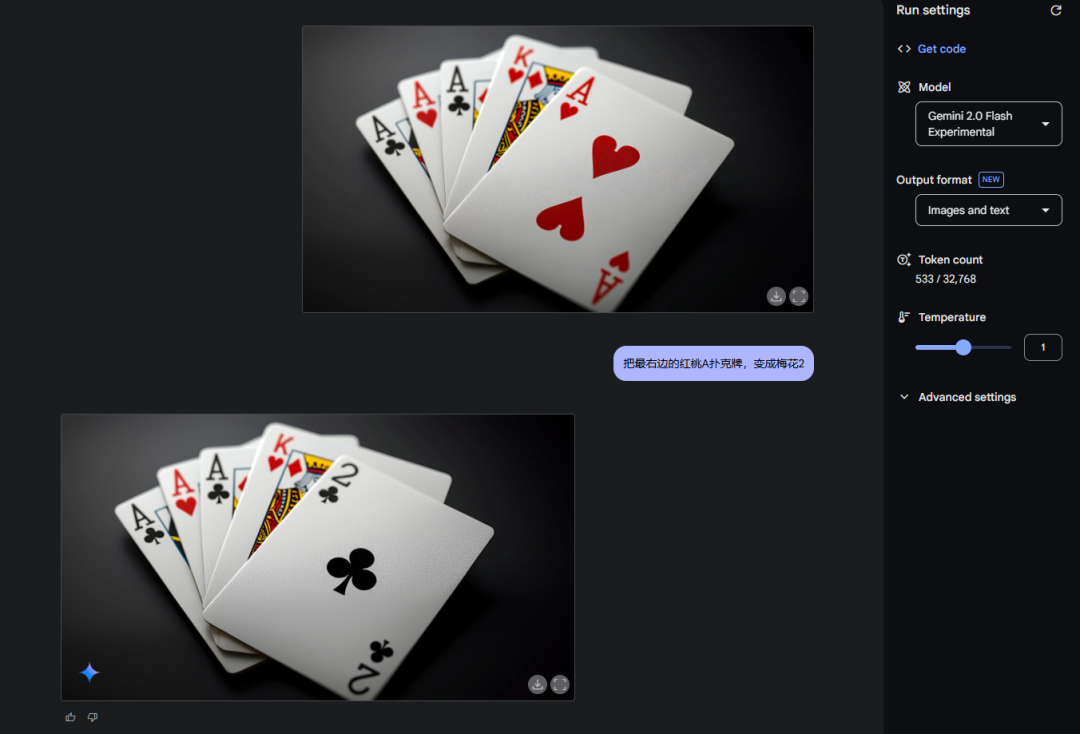
不過這個得roll,我roll了3次才roll出來。
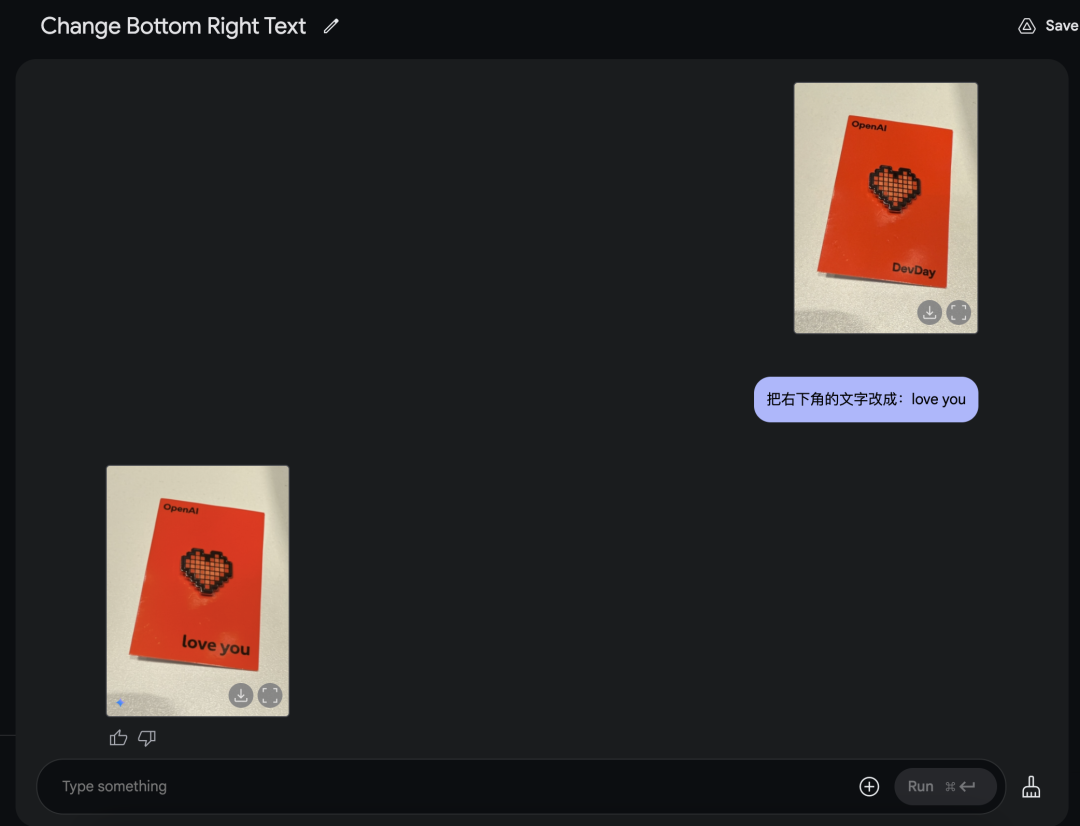
你也可以改文字。
甚至,可以扔一個草圖進去,然後說:
請你根據這張手繪線稿圖,生成對應的一張真實房屋渲染圖。
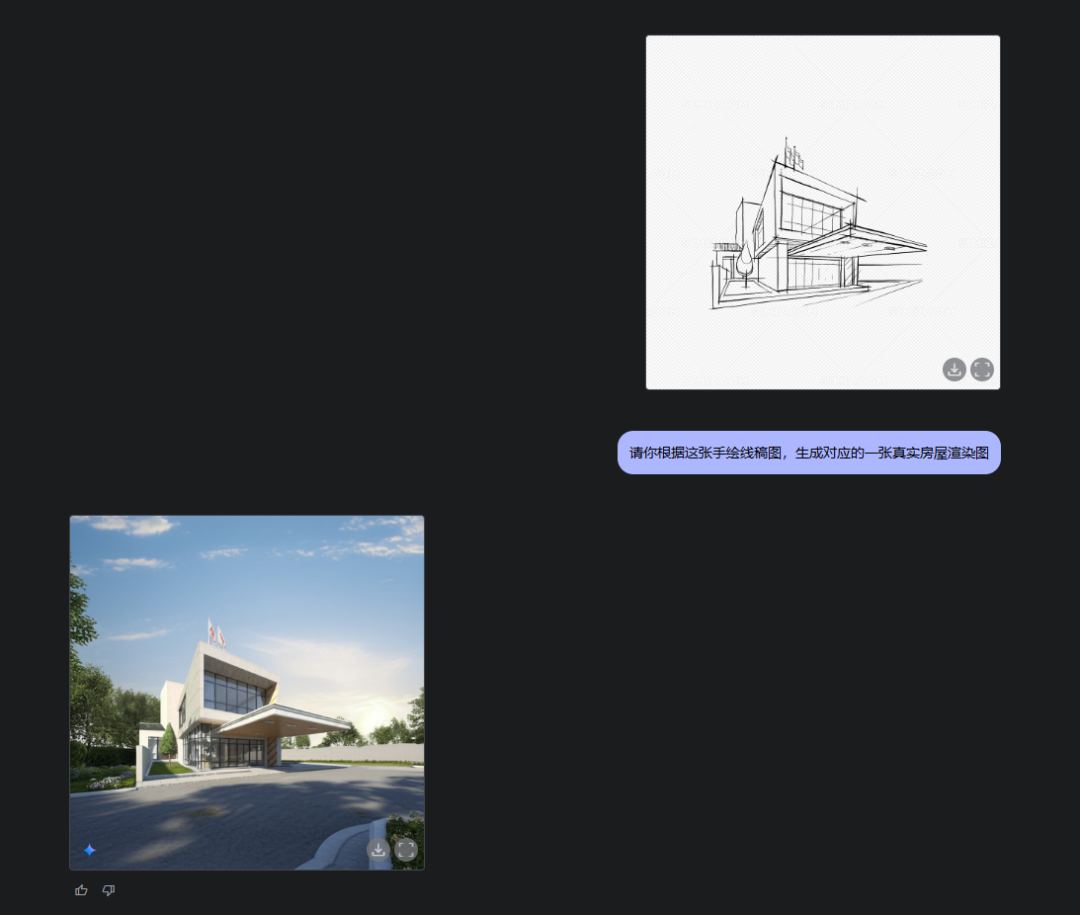
對這個屋子材質不滿意,你還可以,改成木質的。

這,就是言出法隨的力量。、
得益於Gemini 2.0的多模態能力,類似於之前的GPT4o,GPT4o是語音端到端,而Gemini 2.0,則是圖片端到端。
集圖片理解和生成為一身。
而且,畫出的圖,審美也還湊合,雖然還遠遠達不到類似MJ、Flux那種質量,泛化能力也差點意思,但,能用了。
在多模態大模型上,能用的言出法隨,是非常關鍵的一點。
說下怎麼用。
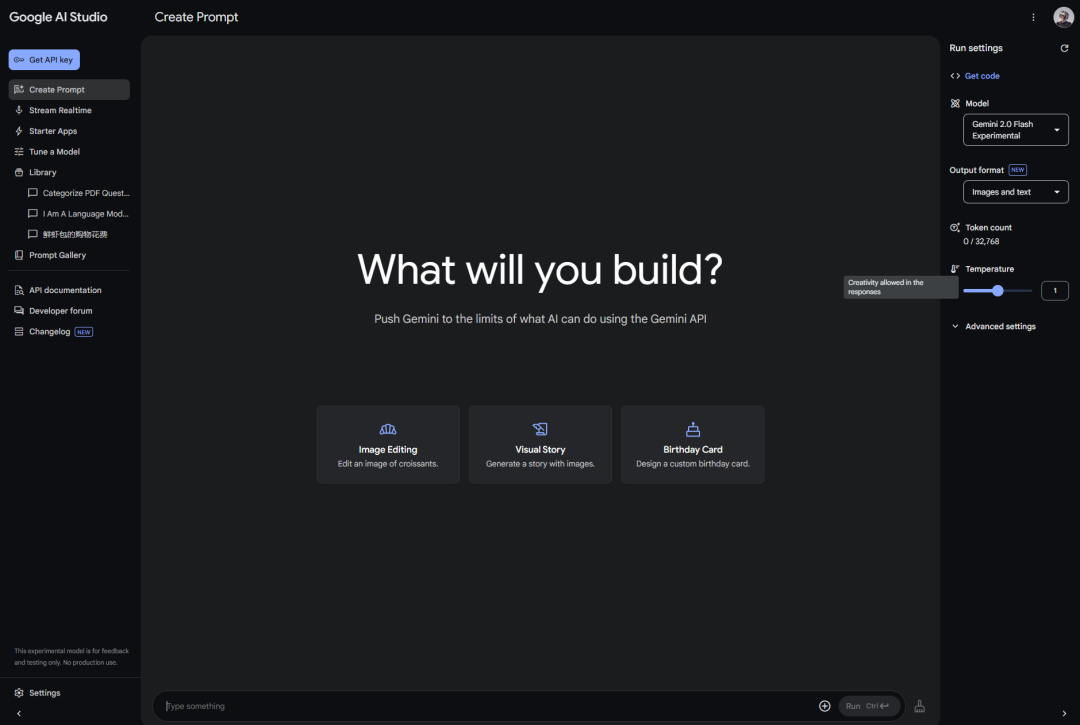
打開https://aistudio.google.com/
正常你登錄後會看到這個界面(需要魔法)。
然後,在右側把模型,切換成Gemini 2.0 Flash Experimental。
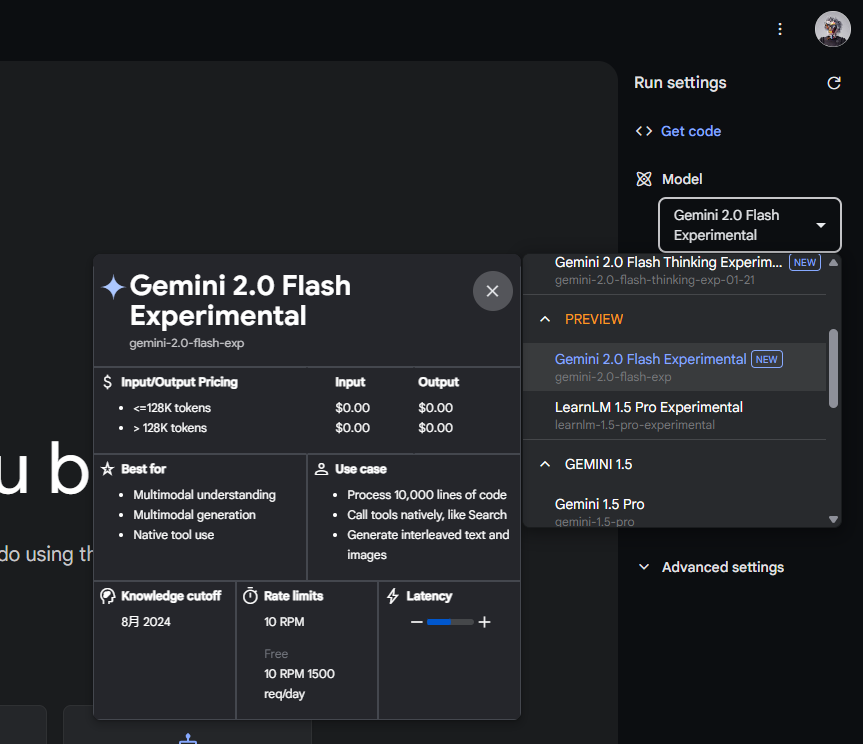
目前限免,可以隨意白嫖。
同時記得output這塊,一定是Images and text,千萬別只選Text,那你就生成不了圖了。
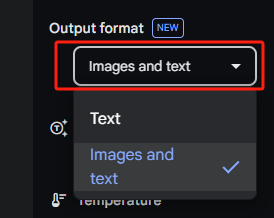
接下來,直接在對話框里,傳你圖片,加上文字描述就OK。
比如我把我的頭像,變成3D實物。

而且你不止可以傳一張圖,你也可以,傳兩張圖,然後,融圖。
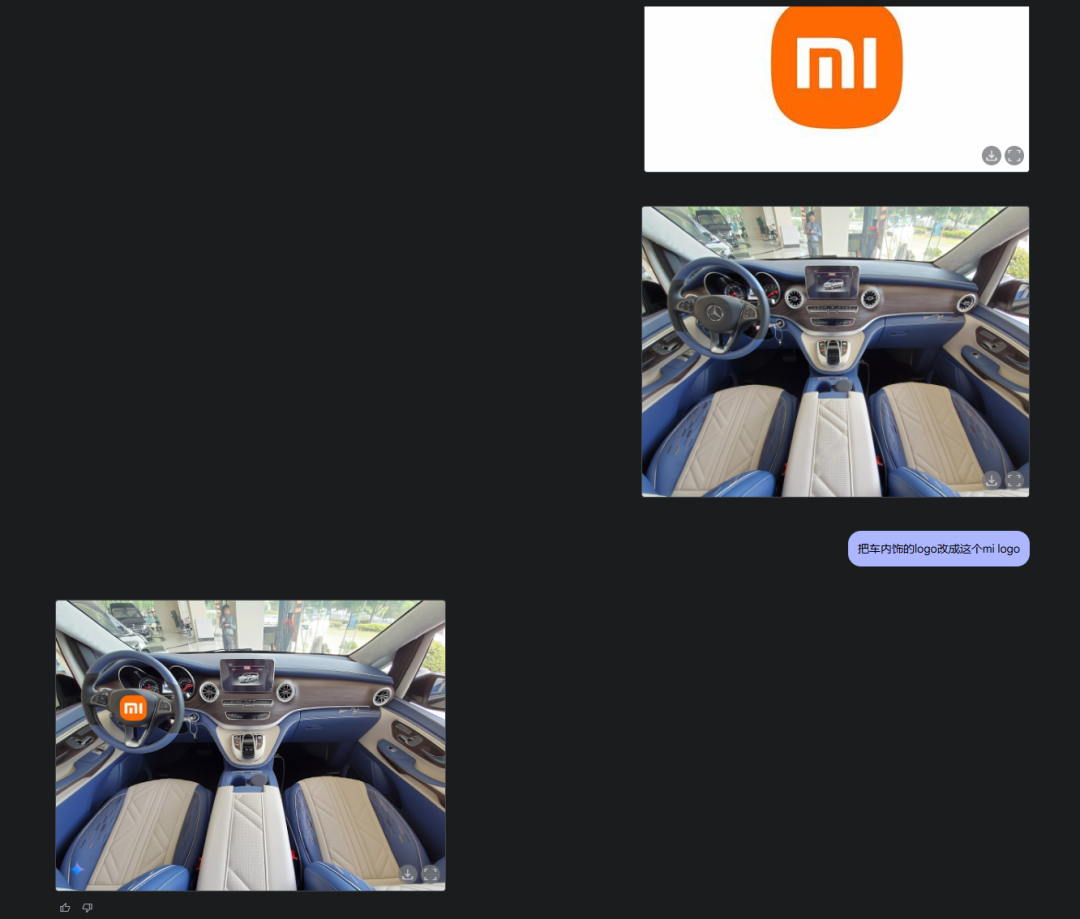
雖然它換logo換的還有點貼片感,比較這個太難了,但是產品圖,就會好很多了。
比如1和2結合。

光影還是有一些不匹配,有一些貼圖感,但不妨礙很準確。
再給半年時間迭代,我覺得,一切都不是問題。
甚至你還可以,不只是圖+文字進去,你還可以,直接讓它給你生成圖文混排的教程。
比如這個做番茄炒蛋的case。

你現在,是真的擁有一個圖文混排的教程了。。。
甚至,你還可以,給一個平面圖,直接做每個房間的渲染圖。
我隨手生成了一個兩室一廳的平面圖。
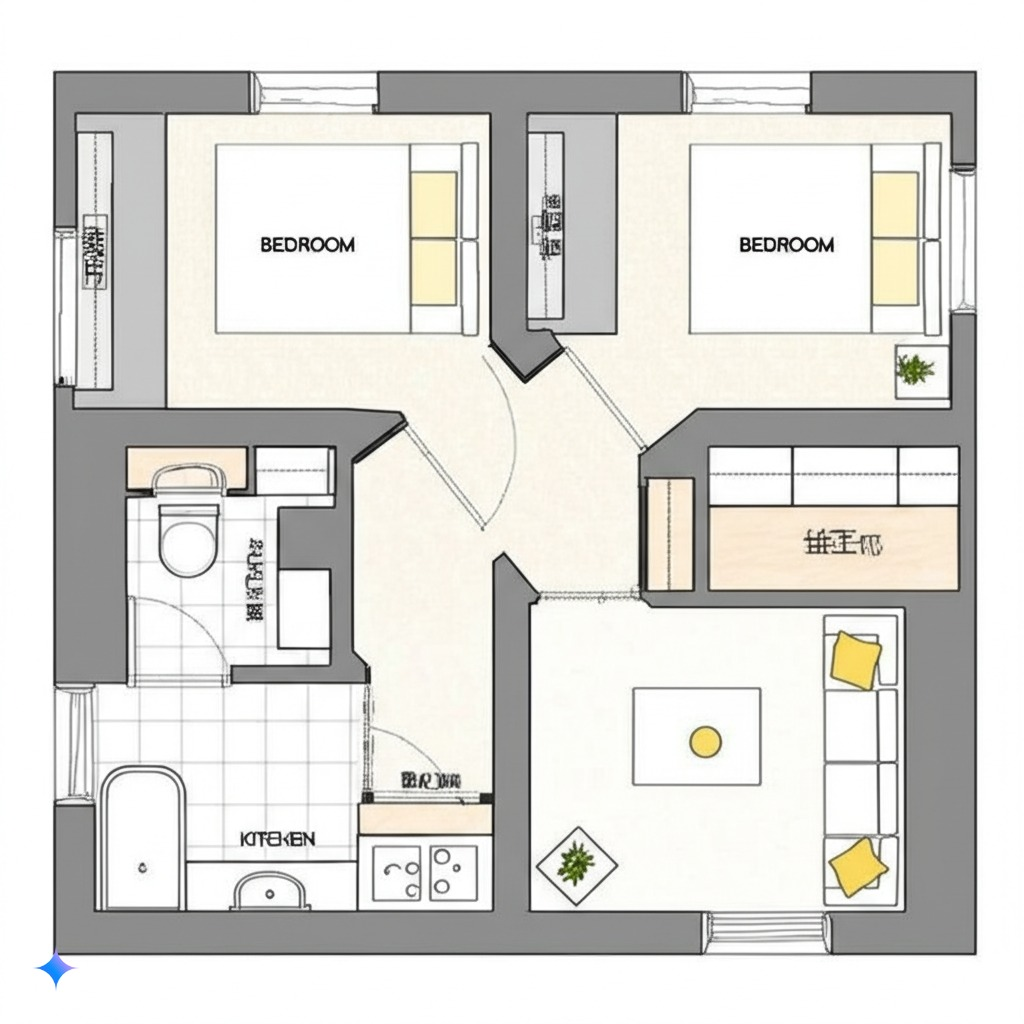
然後,扔給了Gemini。

怎一個離譜了得。。。
這種一致性,做故事、做分鏡,真的就是手到擒來。
兩年多了,生成式AI在圖像編輯領域的進步,真的也就像悄悄進行的大革命。
從最初需要苦學多年Photoshop和圖像處理技術,到如今只需一句話就能實現你的所有創意。
我們不再受限於專業技能的掌握程度,就算是從來沒用過PS的小白,也可以輕鬆地用嘴,將腦海中的創意轉化為現實。
言出法隨,從這一刻,成真了。
這或許。
就是AI時代。
它們給予我們最珍貴的禮物。


















