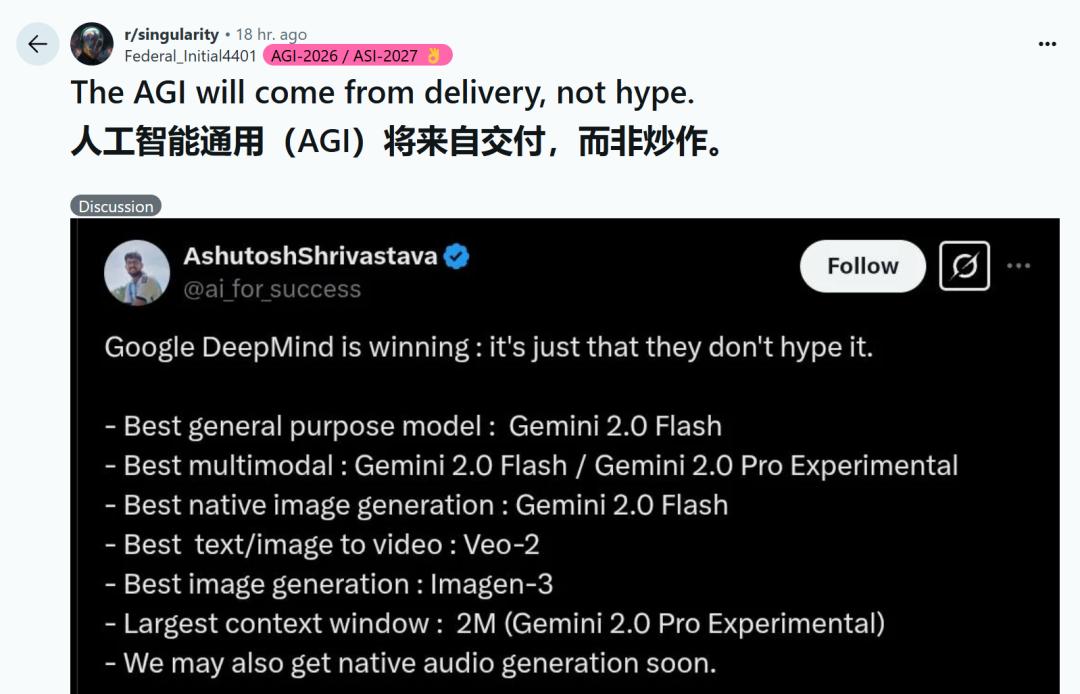
AI能自主出「競賽題」了!港大&螞蟻讓大模型學會生成難題,水平已接近AIME
趙學亮 投稿
量子位 | 公眾號 QbitAI
大模型架構研究進展太快,數據卻快要不夠用了,其中問題數據又尤其缺乏。
為此,港大和螞蟻的研究人員反向利用思維鏈,提出了PromptCoT方法,並基於Llama3.1-8B訓練了一個問題生成模型。
實驗結果表明,合成的問題難度較開源數據和已有算法有顯著提升,接近了AIME水平。

研究團隊利用問題生成模型構造了400k SFT數據。
基於這份數據,團隊訓練了DeepSeek-R1-Distill-Qwen-7B模型,在MATH-500、AIME 2024以及AIME 2025上的表現均超過了32B的s1模型。

並且相比DeepScaleR-1.5B-Preview,PromptCoT-DS-1.5B僅用1/15的GPU hours即可達到相似的結果。
所有模型和數據均已開源。社區可以根據自己需求合成任意問題數據,用於模型蒸餾或RL訓練。
大模型訓練缺乏「難題」
當大模型原理「越辯越明」、開源代碼越來越多時,數據的不足反而成了限制模型發展的瓶頸。
因為無論是SFT還是RL,一份高質量且頗具挑戰的問題數據都是必不可少的,其中,問題數據又尤為重要。
2024年8月,DeepMind的研究闡明了問題挑戰性對於模型能力的重要性,但如何能以一種可擴展的方式獲得高質量且足夠挑戰的問題數據呢?
開源社區中雖然有很多數據集(比如NuminaMath和 OpenMathInstruct),但這些數據中「難題」的比例卻不高。
簡單問題讓模型在訓練中快速飽和,而困難的問題又不多,這可能是當下研究者在構建推理模型時感到最為受限的地方。
因此,研究團隊感到相比又一份訓練方法的複現代碼,一個能夠規模化產生高質量困難問題的模型可能更重要。
那麼,能不能把「出題」的任務,也交給大模型呢?
讓大模型學會自己出題
開源數據到底夠不夠難?
在方法設計之前,研究團隊先調研了一下已有開源數據(包括開源方法)的問題難度。
由於「難度」是一個相對主觀的指標,研究團隊考慮了三個指標:
-
大模型在問題上的跑分:相當於找個「好學生」來做題,好學生都不會做,說明題目難。
-
深度思考模型完成題目所需的推理長度:類似的,如果「好學生」需要思考很久才能解一題,說明題目難。
-
用該數據精調一個大模型能帶來的收益。
 △開源數據(方法)問題難度研究
△開源數據(方法)問題難度研究上表給出了一些典型數據和方法的對比。
從前兩列可以看到,和AIME相比,已有數據(或方法)的問題在Qwen2.5-Math-72B-Instruct這樣強模型下是比較容易解決的,同時也不需太長的推理。
與之相對,PromptCoT給出的問題無論在跑分上還是在推理長度上都更接近AIME。
同時,PromptCoT也是唯一能讓Qwen2.5-Math-7B的base模型在精調後可以超過其Instruct版本的數據(第三、四列,Δ代表精調後和Instruct的差)。
怎樣才能合成難題?
在已有方法中,不乏用大模型合成問題的工作(如KPDDS、OpenMathInstruct等),但問題難度上不去,研究團隊認為是缺乏一個深入思考的過程。
就像一位經驗豐富的老師,不假思索可以給出一些問題,但這些問題要麼耳熟能詳,要麼過於直接。
如果想要出一些有挑戰的問題,就需要仔細思考。
因此,研究團隊考慮將思維鏈「倒過來」用於合成「難題」上。具體來說,PromptCoT包含三個步驟:
-
概念抽取;
-
出題邏輯生成;
-
問題生成模型訓練。
 △PromptCoT方法概覽
△PromptCoT方法概覽先看第一步,概念抽取。
PromptCoT是以一些數學相關的概念為生成起點的(比如組合數學、概率論等)。
首先從AoPS上抓取6000多個競賽級數學題作為種子數據,然後通過Prompt一個大模型從中抽取概念,最後將這些概念去重過濾得到概念池。
抽取完成後,就是邏輯生成。
具體來說,給定一組概念以及一個問題,問題生成的目標是最大化,其中對應一個出題邏輯。
通過一些簡單的推導,可以得出的最優後驗概率是與以及成正比的。那麼一個「好」的應該能同時讓和最大。
在這樣的理論指導下,本工作通過Prompt大模型的方式生成邏輯,具體如下圖所示。
 △邏輯生成Prompt
△邏輯生成Prompt確定邏輯之後,就可以對模型進行訓練。
首先利用邏輯生成為每條種子數據構造一個問題合成的思考邏輯,得到數據集。
在這些數據基礎上,通過模型精調和拒絕采樣的方式來訓練一個問題生成模型。
其中模型精調(SFT)可以看作是預熱階段,讓模型初步掌握合成問題的能力;
而拒絕采樣(rejection sampling)可以看作是質檢階段,利用兩個額外的大模型給合成的問題打分,只將最高分的問題留下並用作下一輪訓練,以讓模型在預熱階段後能進一步自我提升,確保生成的問題質量。
訓練效果顯著增強
合成的問題有用嗎?
回答這個問題最直接的辦法就是用生成的問題數據構造蒸餾數據集,然後觀察訓練強模型的收益。
這裏採用的訓練方法是SFT,評估數據採用的是GSM8K,MATH-500,以及AIME 2024,分別代表了小學、高中、以及競賽級的數學難度。
為了公平比較,Evol-Instruct和KPDDS採用Llama3.1-70B-Instruct做底座。
評估考慮了short-CoT以及long-CoT兩種情形。Short-CoT用Qwen2.5-Math-72B-Instruct做教師模型,Qwen2.5-Math-1.5B和7B的base版本做學生模型;
而long-CoT則用DeepSeek-R1-Distill-Qwen-7B做教師模型,DeepSeek-R1-Distill-Qwen-1.5B和7B做學生模型。
下展示了評測結果,可以看到,無論是1.5B模型還是7B模型,PromptCoT都能帶來非常顯著的增益。

合成數據有無規模效應?
下圖展示了隨著問題數據規模變大,Qwen2.5-Math-1.5B base模型在MATH-500上的效果變化。
可以看到,與OpenMathInstruct相比,PromptCoT合成的數據具備更加顯著的規模效應,這也側面反映了問題難度對於模型效果的作用。
 △PromptCoT的數據規模效應
△PromptCoT的數據規模效應作者簡介
該工作第一貢獻者為香港大學計算機系博士生趙學亮;
螞蟻技術研究院武威、關健為共同貢獻者。
論文地址:
https://arxiv.org/abs/2503.02324
Github:
https://github.com/inclusionAI/PromptCoT