人類秒懂,AI卻懵圈:VLM²-Bench揭示視覺語言模型「視覺關聯」能力短板

本文來自港科與 MIT 教授團隊。本文有兩個共同一作:張鑒殊為武漢大學本科四年級,本篇為其在港科大訪問期間完成,將於 2025 秋季前往美國西北大學攻讀 CS PhD。姚棟宇目前就讀於 CMU CS 系下的 MSCV 項目。

-
論文鏈接:https://arxiv.org/pdf/2502.12084
-
項目主頁:https://vlm2-bench.github.io/
當前,視覺語言模型(VLMs)的能力邊界不斷被突破,但大多數評測基準仍聚焦於複雜知識推理或專業場景。本文提出全新視角:如果一項能力對人類而言是 「無需思考」 的本能,但對 AI 卻是巨大挑戰,它是否才是 VLMs 亟待突破的核心瓶頸?
基於此,該團隊推出 VLM²-Bench 來系統探究模型在 「人類級基礎視覺線索關聯能力」 上的表現。
本文將如下的兩點作為本工作的出發點:
-
什麼能力對於人類來說是在日常生活中非常重要,且這種能力還得是對人們來說非常容易的,不需要龐大的知識儲備也能完成。
我們在瀏覽不同的照片時可以找到出現在多張照片的同一個人,但是我們並不需要在之前就見過這個人,叫得知名字或者對這個人很瞭解,而是簡單的在不同的圖片間通過臉部特徵在視覺上的比對和關聯。同理我們還會拿著喜歡球鞋的圖片去線下門店比對挑選出一樣的款式(如下圖),而不需要知道這個鞋的具體產品型號,只需要把鞋的花紋這一視覺特徵給關聯起來即可。這種視覺關聯的能力顯然是不依賴於先驗知識,是純粹基於視覺側的關聯。

日常生活中我們經常利用「視覺關聯」,比如圖中這個男孩正拿著手機上的圖片去線下門店一一比對,來挑選出一樣的球鞋款式(圖片由AI生成)
-
為什麼這種能力對於現在 VLMs 也是非常重要的?
隨著 VLMs 從單圖處理擴展到多圖、影片輸入,其視覺感知的廣度和深度顯著提升。然而,視覺內容的擴展並未帶來對視覺線索關聯能力的同步提升,而 VLMs 時需要具有 「回頭」 關聯視覺線索的能力來幫助在其更一致且和諧的理解世界。
VLM²-Bench 的設計
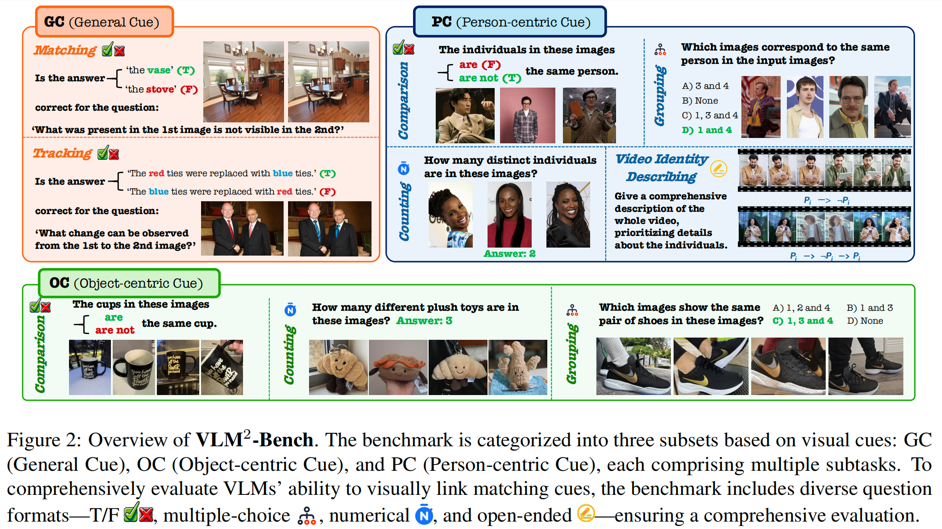
-
全面考察 VLMs 對於通用線索 GC(General Cue)、物體線索 OC(Object-centric Cue)和人物線索 PC(Person-centric Cue)三個大類的基礎關聯能力,總共可分為 9 個子任務,同時涵蓋多圖和影片的測試數據,共計 3060 個測試案例。
-
評測問題的形式包含了判斷題、多選題、數值題、開放題,其中對於每種形式我們都設計了特定的評估方式來更好的反應模型的性能。
-
結合人工驗證與自動化過濾,同時確保數據質量與挑戰性。
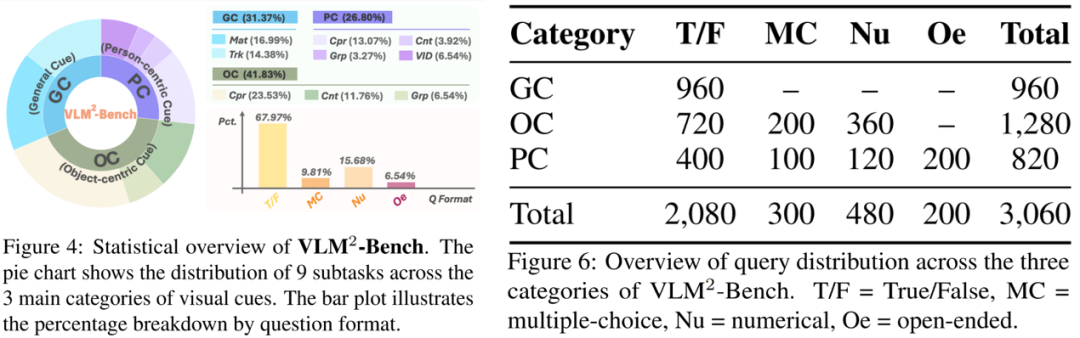
以上是 VLM²-Bench 統計數據。
實驗與發現
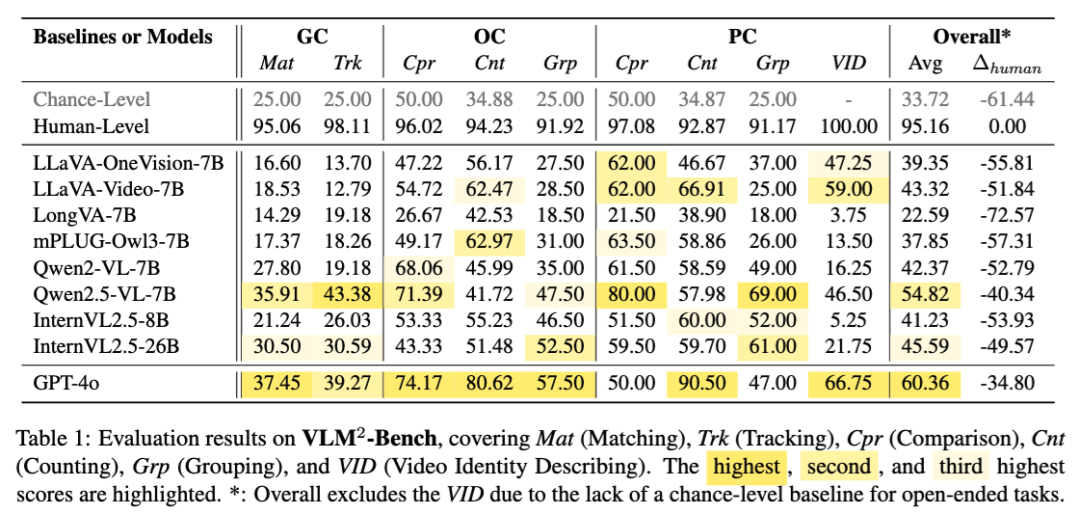
這裏我們引入了蒙題(Chance-Level)和人類做答(Human-Level)的兩個基準來更好的衡量 VLMs。根據表 1,可以發現 VLM²-Bench 對於人類來說幾乎沒有什麼難度,但絕大多數模型的準確率甚至比不上亂蒙,和人類表現差距甚大。尤其是在描述影片中出現的人(VID)這一任務上,模型很容易把變化的人當作同一個來描述,把第二次出現的人當作一個新出現的人介紹。
同時我們還觀察到模型在關聯人物線索 PC 上的表現比物體線索 OC 更好,這個可能是因為關於人的圖文數據上有提供區分度較大的不同的人名作為人物視覺線索的文本錨點,而在物體有關的數據上訓練時往往都是用寬泛的類別這一作為錨點,從而模型更擅長區分不同人。
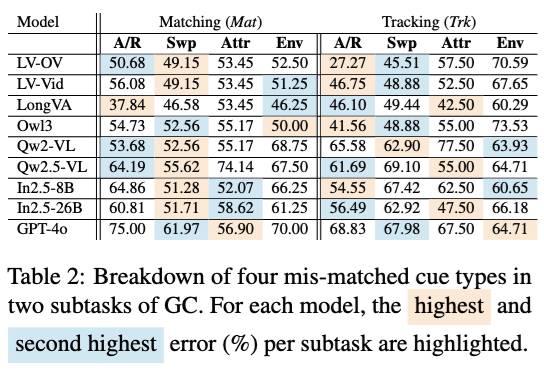
通過在通用線索 GC 這個大類中的進一步的分析,可以看到在匹配線索(Matching)這一子任務上,模型匹配兩個由於替換(Swp)導致的不一致的能力較弱;而在跟蹤線索(Tracking)這一子任務上,模型匹配兩個由於添加或去除(A/R)時很難給出線索的變化順序。這一發現說明模型在視覺線索關聯任務中的短板存在一定的共性 —— 過度依賴於線索的 「連續可見性」,缺乏全局關聯這一動態視覺理解的能力。
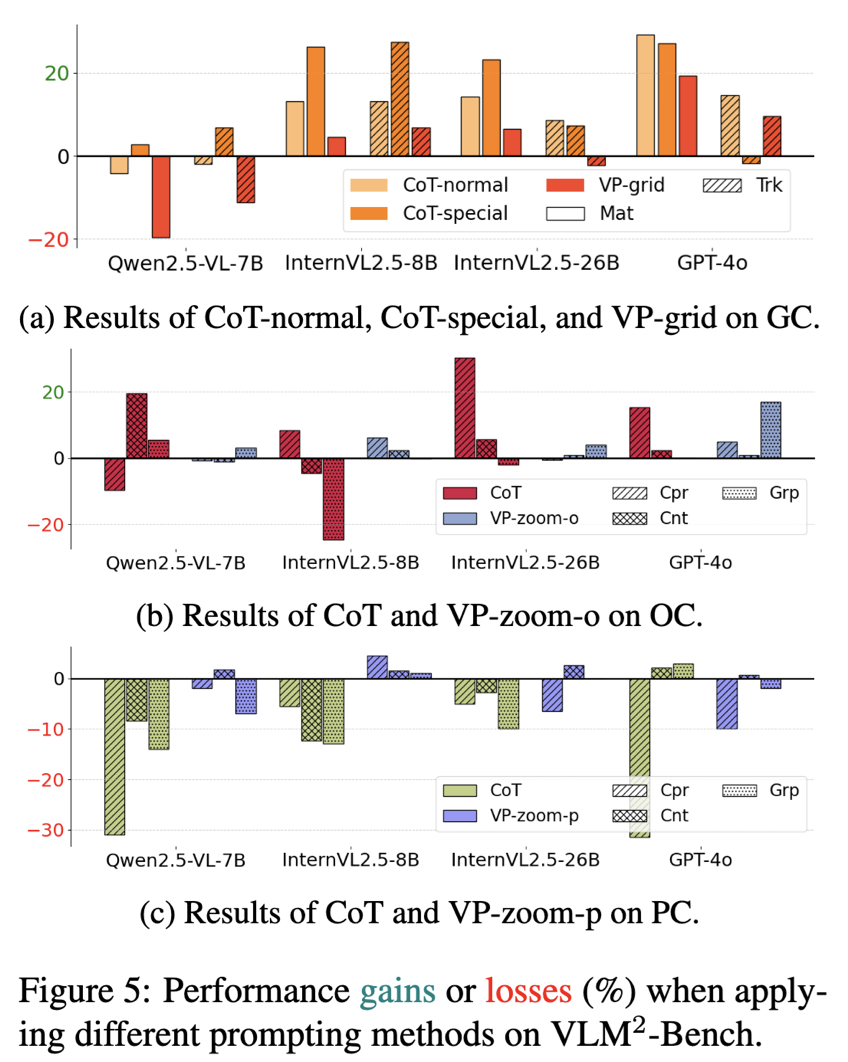
不僅僅局限於簡單的評測,本文還探究了以語言為中心(CoT-)和以視覺為中心(VP-)的 prompting 方法能否促進模型在這種視覺關聯能力。有以下的幾點發現:
-
將語言為中心的推理(如逐步說出解決問題的過程),可以在一定程度上促進關聯時的邏輯,但是前提是視覺線索適合用語言進行表達,對於抽像的視覺線索,以語言為中心的推理會因為表達的開放性從而嚴重影響表現。
-
將視覺為中心的提示(如放大關鍵的視覺線索),在物體線索 OC 的場景下幫助較大,而在人物線索 PC 上反倒會 「幫倒忙」。
-
以視覺為中心的提示帶來的效果和模型的視覺基礎能力呈現正相關的關係。只有在模型能夠先後理解視覺提示帶來的額外的輔助信息以及圖中本身的信息時,視覺為中心的提示才能起到較好的效果。
未來方向
-
增強基礎視覺能力:提升模型的核心視覺能力不僅能直接提升性能,還能增強適應性。更強的視覺基礎可以最大化視覺提示的效果,並減少對先驗知識的依賴,使模型在以視覺為核心的任務能夠實現獨立和可拓展。
-
平衡基於語言的推理在視覺任務中的作用:在視覺任務中引入語言推理需要謹慎調整。未來研究應明確哪些情況下語言推理可以增強視覺理解,哪些情況下會引入不必要的偏差,以確保模型合理地利用語言側的優勢。
-
新的訓練範式:當前的訓練方法主要關注視覺和語言的關聯,但隨著模型視覺上下文窗口的擴展,單純在視覺域內進行推理的能力變得越來越重要。未來應優正選展能夠在視覺線索之間進行結構化、組織和推理的模型。