人大北郵等團隊解視觸覺感知統一難題,模型代碼數據集全開源 | ICLR 2025
人大團隊 投稿
量子位 | 公眾號 QbitAI
機器人怎樣感知世界?
相比於「看得見」,「摸得著」能夠提供更直接且細膩的物理反饋,有助於準確判斷物體特性,還在精確操控和複雜操作中發揮關鍵作用。
長期以來,通過各種觸覺傳感器賦予機器人類似人類的觸覺感知能力,始終是具身智能重要研究方向。其中,由於具有與人類皮膚相匹配的高解像度,視觸覺傳感器展現出了巨大的潛力。
那麼是否存在一個適用於多種傳感器、多種任務的通用視觸覺表徵學習範式?
來自中國人民大學高瓴人工智能學院GeWu-Lab實驗室、北京郵電大學和武漢科技大學最近的合作研究提出從動靜結合的新視角建模統一的多傳感器觸覺表徵空間,通過多層級的學習框架,有效融合靜態觸覺信息(如材質、形狀)與動態觸覺特徵(如滑動、形變),從而獲得適應包含真實世界操縱在內的豐富觸覺場景的通用表徵。
論文已被ICLR2025接收,並對數據集、模型和代碼進行了全部開源。

本文第一作者馮若軒為中國人民大學二年級碩士生,主要研究方向為多模態具身智能,師從胡迪副教授。作者來自於中國人民大學GeWu-Lab,北京郵電大學以及武漢科技大學,其中方斌教授和胡迪副教授作為共同通訊
視觸覺面臨什麼挑戰?
即便具有那麼多潛力,構建基於視觸覺傳感器的強大觸覺感知系統仍面臨諸多挑戰。由於發展時間較短,視觸覺傳感器種類繁多且缺乏統一標準,不同的傳感器在感知相同的觸覺信息時存在一定差異。
這種異構性使得當前的視觸覺數據採集和模型訓練通常依賴於特定傳感器,導致單一傳感器模型的數據規模受限,難以涵蓋豐富的觸覺場景,從而製約了觸覺感知系統的泛化能力和魯棒性。
此外,人類的觸覺感知是一個動態與靜態信息交織的過程,能夠從紋理、滑動和形變變化等多種信號精準地理解物體特性。這種對動態觸覺細節的敏銳捕捉能力在精細機器操縱中同樣至關重要,也是當前多傳感器觸覺感知模型所欠缺的。
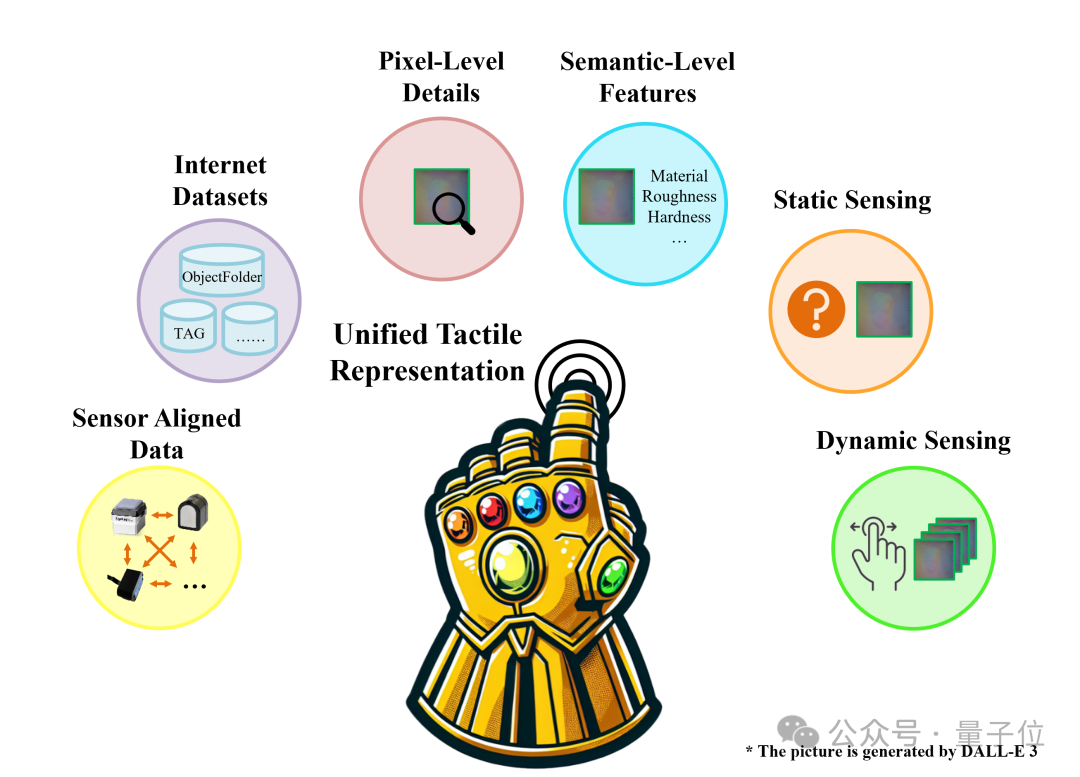
本論文針對視觸覺感知所面臨的核心挑戰,提出了一個配對的多傳感器多模態觸覺數據集TacQuad,為利用數據驅動方法顯式整合多種觸覺傳感器奠定基礎。
更進一步地,本文提出動靜結合的多傳感器統一觸覺表徵學習框架AnyTouch,為包含真實世界操縱的多種任務和多種視觸覺傳感器提供有效的觸覺感知。
TacQuad:配對的多傳感器多模態觸覺數據集
想像一下,假如不同的照相機拍同一個物體,但由於鏡頭、光線、顏色處理方式等不同,最後的照片卻各不相同——這會讓AI很難直接理解它們其實是同一個物體。
類似地,不同的視觸覺傳感器使用的技術原理也略有不同,相當於「看世界的方式」各不相同,導致它們採集的數據很難直接遷移使用。究其根本,在於缺乏一個顯式地配對多傳感器數據,並允許模型從其他模態獲取更全面的觸覺知識、借助多模態數據彌合傳感器差異的可靠觸覺數據集。
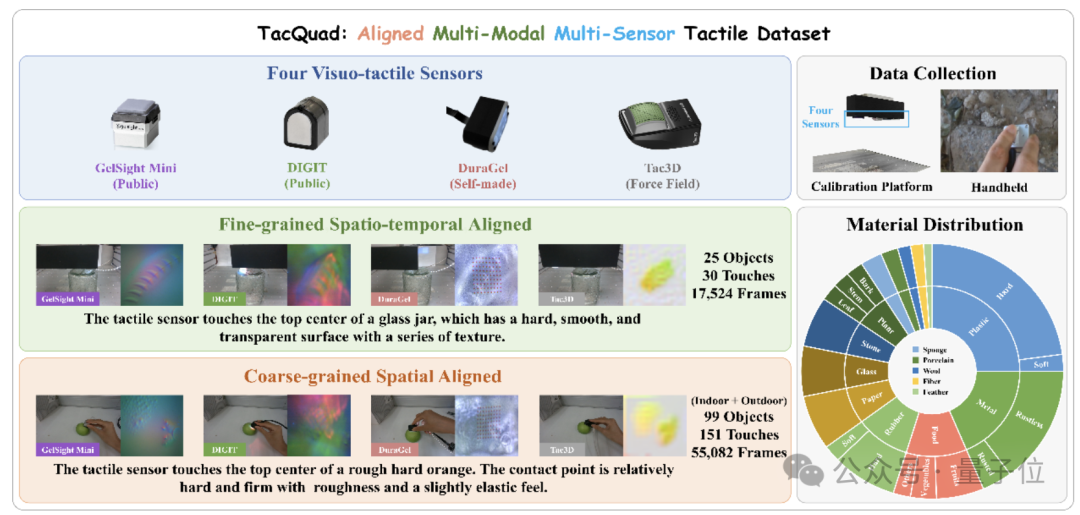 △圖1 配對的多傳感器多模態觸覺數據集TacQuad
△圖1 配對的多傳感器多模態觸覺數據集TacQuad為了讓AI更聰明地「摸清世界」,本工作採集了配對的多傳感器多模態觸覺數據集TacQuad,通過提供包含文本描述和視覺圖像的配對多傳感器數據,支持以數據驅動的方式構建統一的多傳感器觸覺表徵空間,從而為這一問題提供一個更全面的解決方案(如圖1所示)。
為了確保數據的豐富性,團隊精心挑選了四種觸覺傳感器:來自公開平台的GelSight Mini和DIGIT,實驗室自製的DuraGel,以及能夠感知力場的Tac3D。
然而,考慮到收集細粒度多傳感器配對數據成本高昂,為擴大數據採集的規模,同時儘可能地保證數據的對齊質量,團隊使用粗粒度和細粒度兩種方法採集了兩組多傳感器配對數據:
-
細粒度時空對齊數據:該部分數據通過將四個傳感器以相同的速度按壓同一物體的相同位置採集,共包含來自25個物體的17524個接觸幀,可用於細粒度觸覺任務,如跨傳感器生成。
-
粗粒度空間對齊數據:該部分數據由人分別手持四個傳感器,在同一物體上按壓同一位置,儘管不能保證時間對齊,但可以儘可能地保證採集空間上的一致。該部分包含來自99個物體的55082個接觸幀,包括室內和室外場景,可用於跨傳感器匹配任務。
在TacQuad數據集中,每次觸覺接觸都會同時記錄來自第三視角的視覺圖像,並由GPT-4o生成對應的觸覺屬性描述。
這樣,AI不僅能「摸」到物體,還能「看到」並「理解」它的觸感。
為進一步利用更多傳感器的大量已有數據,本工作還利用GPT-4o對多個開源觸覺數據集生成或擴展文本描述,讓這些原本只包含傳感器數據的數據集也擁有豐富的語言信息
AnyTouch:動靜結合的多傳感器統一觸覺表徵學習框架
在日常生活中,團隊的觸覺不僅僅是「摸一摸」那麼簡單,而是一個包含靜態和動態過程的綜合體驗。比如,輕輕按壓一塊海綿可以感受到它的柔軟(靜態觸覺),而用手指滑動還能感知它的紋理和彈性(動態觸覺)。
這兩種感知方式相輔相成,讓團隊能夠更準確地理解周圍的物理世界並與之交互。受此啟發,本工作提出了AnyTouch——一個動靜結合的多傳感器統一觸覺表徵學習框架,分別使用觸覺圖像和影片,從靜態和動態感知結合的角度學習統一的多傳感器觸覺表徵(如圖2所示)。
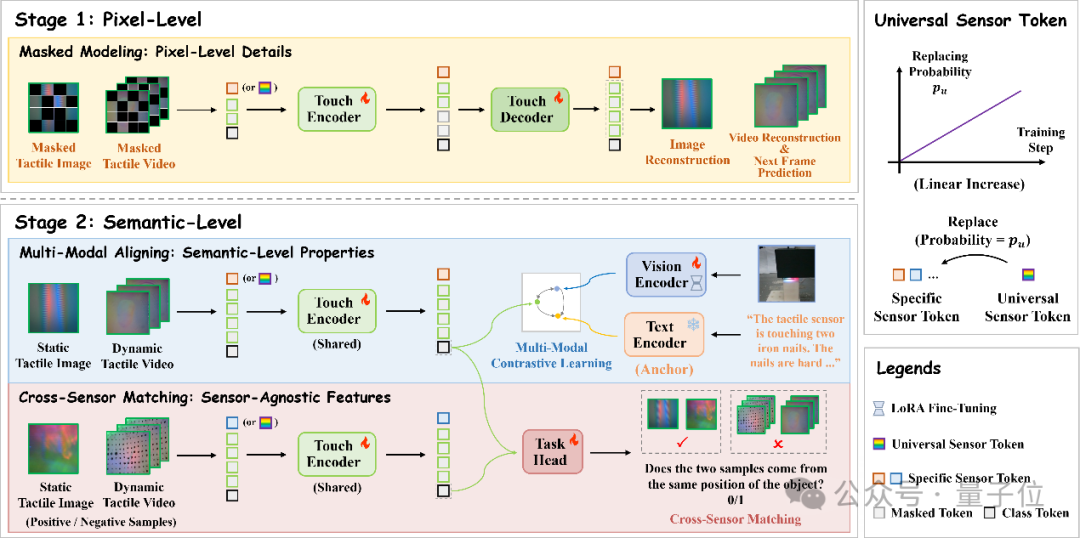 △圖2 動靜結合的多傳感器統一觸覺表徵學習框架AnyTouch
△圖2 動靜結合的多傳感器統一觸覺表徵學習框架AnyTouch為了適應不同的觸覺場景的感知需求,AnyTouch採用了多層級架構,分階段提升模型的觸覺感知能力。
在第一階段中關注像素級的觸覺細節,而第二階段則學習傳感器無關的語義級特徵,使AI能更全面地理解和處理觸覺信息:
-
掩碼圖像/影片建模(階段1):為增強觸覺感知模型的細粒度感知能力,本框架採用掩碼自編碼器(MAE)技術,訓練模型在多種傳感器的數據輸入中捕捉像素級細節。該框架隨機遮擋觸覺圖像和影片的Token序列的一部分,並構建一個解碼器來獲得重建的靜態圖像和動態影片。為進一步強化模型對動態連續形變的理解,在重建動態影片時還引入未來幀預測的額外任務。
-
多模態對齊(階段2):本框架通過觸覺-視覺-文本多模態對齊,對包含其他配對模態的多傳感器觸覺數據進行整合,以獲得更全面的語義級觸覺知識,並借其他模態作為橋樑減少傳感器之間的感知差異。由於不同數據集視覺模態存在場景差異,本框架選擇語義更一致的文本模態作為錨點,並為每個批次數據內的每種模態組合選擇最大的數據子集進行對齊,從而最大限度地利用多模態配對數據。
-
跨傳感器匹配(階段2):為充分地利用多傳感器配對數據,並通過對錶示相同觸覺信息的多傳感器觸覺表徵進行聚類來構建統一的空間,本框架引入了一個新的跨傳感器匹配任務。在此任務中,模型需要確定輸入的一對觸覺圖像或影片是否採集自同一對象上的同一位置。該任務的目標是在執行多模態對齊的同時,對來自不同傳感器的相同觸覺信息的表示進行聚類,從而增強對傳感器無關特徵的學習,形成一個統一的多傳感器表徵空間。
本框架還使用通用傳感器Token來整合併存儲與各傳感器相關的信息,從而在泛化到新傳感器時最大限度地利用多傳感器訓練數據。
實驗與分析
為探究每種傳感器數據對下遊任務的貢獻,本工作將GelSight、GelSlim、DIGIT和GelSight Mini的數據整合到AnyTouch訓練中,獲得四種模型,並在四個下遊任務中比較。
如表1所示,與未接觸觸覺數據的CLIP模型相比,使用GelSight數據的訓練顯著提升了模型在所有任務上的性能,表明觸覺表徵預訓練對新傳感器的遷移至關重要。將其他傳感器的數據整合後,模型在三個未見數據集上的性能提升,特別是在未見傳感器的數據集上表現更好,證明這些數據的知識能夠遷移到其他觸覺傳感器。
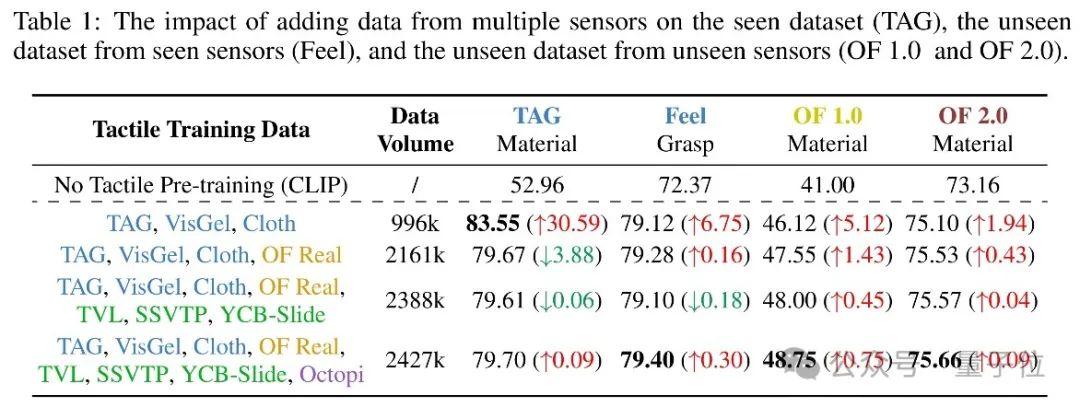 △表1 整合各觸覺傳感器數據對模型性能的影響
△表1 整合各觸覺傳感器數據對模型性能的影響為驗證AnyTouch是否能將來自不同傳感器的相同觸覺信息聚集在一起,本工作從TacQuad細粒度子集的30次觸摸中抽取每種傳感器的一個接觸幀,並輸入CLIP模型以及逐步引入掩碼建模、多模態對齊和跨傳感器匹配的AnyTouch模型進行對比可視化(見圖3)。
CLIP以及引入掩碼建模後的模型難以辨別來自不同傳感器的相同觸覺信息,直接按傳感器類型對樣本進行聚類,這對於跨傳感器泛化來說並不理想。加入多模態對齊後,表徵開始基於觸覺信息混合和聚類,但仍存在按傳感器類型的聚類趨勢。通過跨傳感器匹配任務,來自不同傳感器的觸覺表徵在共享空間中完全混合,能夠明顯地觀察到表徵根據觸覺信息進行聚類,觸覺表徵逐漸從傳感器依賴的特徵轉向更加通用的跨傳感器信息。
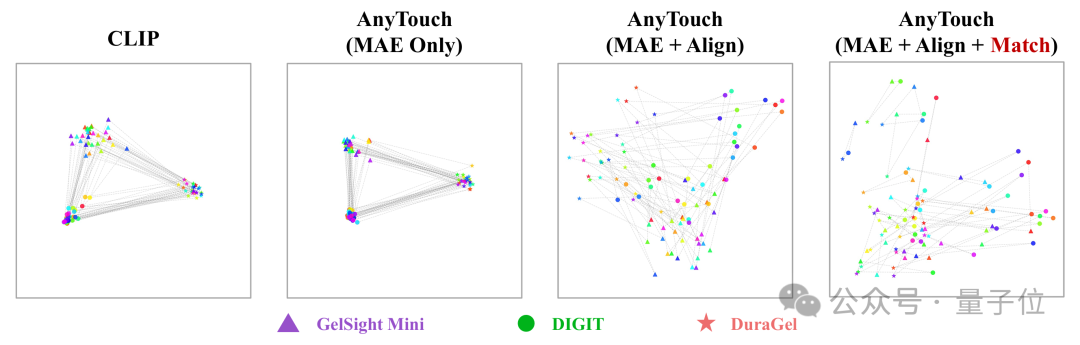 △圖3 AnyTouch中各組件對多傳感器表徵空間的影響
△圖3 AnyTouch中各組件對多傳感器表徵空間的影響為驗證統一多傳感器表徵在遷移觸覺知識到已見與未見傳感器上的優勢,本工作將 AnyTouch與現有的單傳感器和多傳感器模型,分別在已見與未見傳感器的兩個數據集上進行比較。
如表2、表3所示,AnyTouch在所有數據集上均優於現有方法,證明了其在靜態感知能力上的優勢。
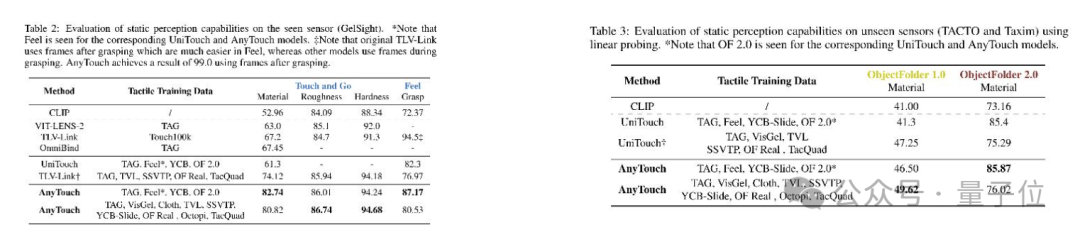 △表2(左)已見傳感器數據集性能對比 表3(右)未見傳感器數據集性能對比
△表2(左)已見傳感器數據集性能對比 表3(右)未見傳感器數據集性能對比為測試AnyTouch在真實物體操縱任務中的動態感知能力,本工作在細粒度傾倒任務上進行了實驗。在此任務中,機械臂需依靠觸覺反饋從含100克小鋼珠的量筒中倒出60克,如圖4所示。各模型在10次真實世界測試中的平均誤差對比如表4所示。結果表明,從動靜結合角度學習統一的多傳感器表示對於完成包括現實世界任務在內的各種任務至關重要。
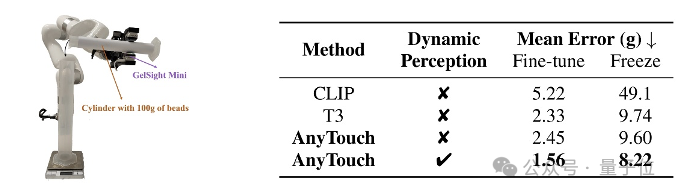 △圖4(左)真實世界傾倒任務示意圖 表4(右)傾倒任務性能對比
△圖4(左)真實世界傾倒任務示意圖 表4(右)傾倒任務性能對比本文從全新的動靜結合角度構建統一的多傳感器觸覺表徵空間,提出配對的多傳感器多模態觸覺數據集TacQuad以提供顯式整合多傳感器的數據支撐,並在此基礎上提出動靜結合的多傳感器統一觸覺表徵學習框架,通過多層級的方式學習適用於各種任務的通用觸覺表徵。
團隊表示,相信從靜態與動態結合的角度學習統一的多傳感器表徵的方法能夠為視觸覺感知建立一個標準化的學習範式,並進一步激發多傳感器表徵學習的研究。
目前工作還在進一步拓展中,歡迎更多觸覺設備的加入,共同構建並擴大觸覺表徵世界,如有興趣請郵件聯繫dihu@ruc.edu.cn。
論文鏈接:https://arxiv.org/abs/2502.12191
項目主頁:https://gewu-lab.github.io/AnyTouch/