CVPR 2025:長Prompt對齊問題也能評估了!當前最大AIGC評估數據集,模型評分超越當前SOTA
AGI-Eval團隊 投稿
量子位 | 公眾號 QbitAI
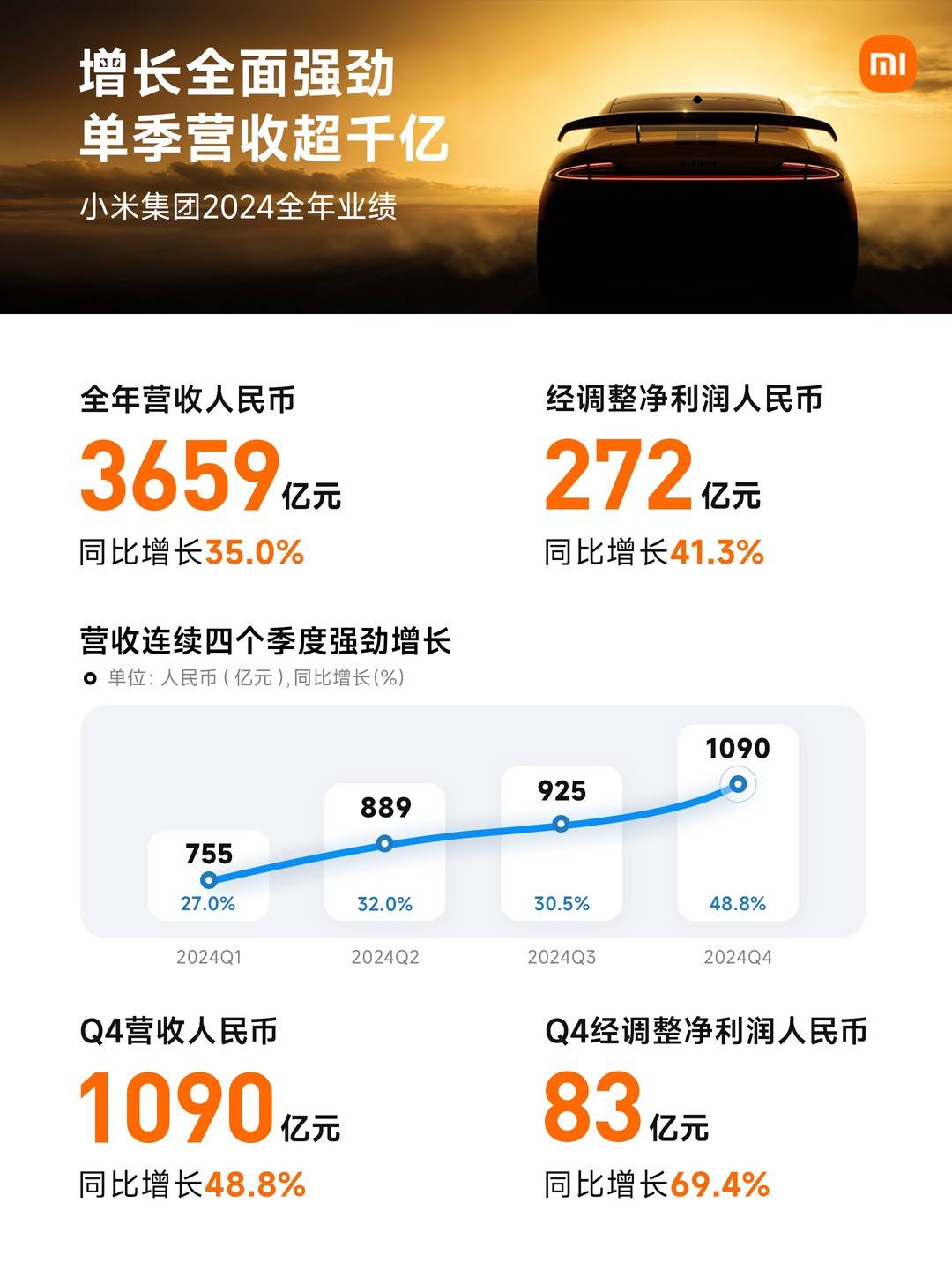
今年,CVPR共有13008份有效投稿並進入評審流程,其中2878篇被錄用,最終錄用率為22.1%。
錄用論文上來看,多模態相關內容仍是關注重點。
上海交通大學-美團計算與智能聯合實驗室發佈的論文也被錄用,論文提出了Q-Eval-100K數據集與Q-Eval-Score評估框架。
論文致力於解決以下問題:
-
現有的文本到視覺評估數據集存在關鍵評估維度缺乏系統性、無法區分視覺質量和文本一致性,以及規模不足等問題;
-
評估過程複雜、結果模糊,難以滿足特定評估需求,限制了基於大模型的評估模型在實際場景中的應用
相關實驗也表明數據集和方法在評估結論和泛化性方面都做到的當前業界的領先水準。
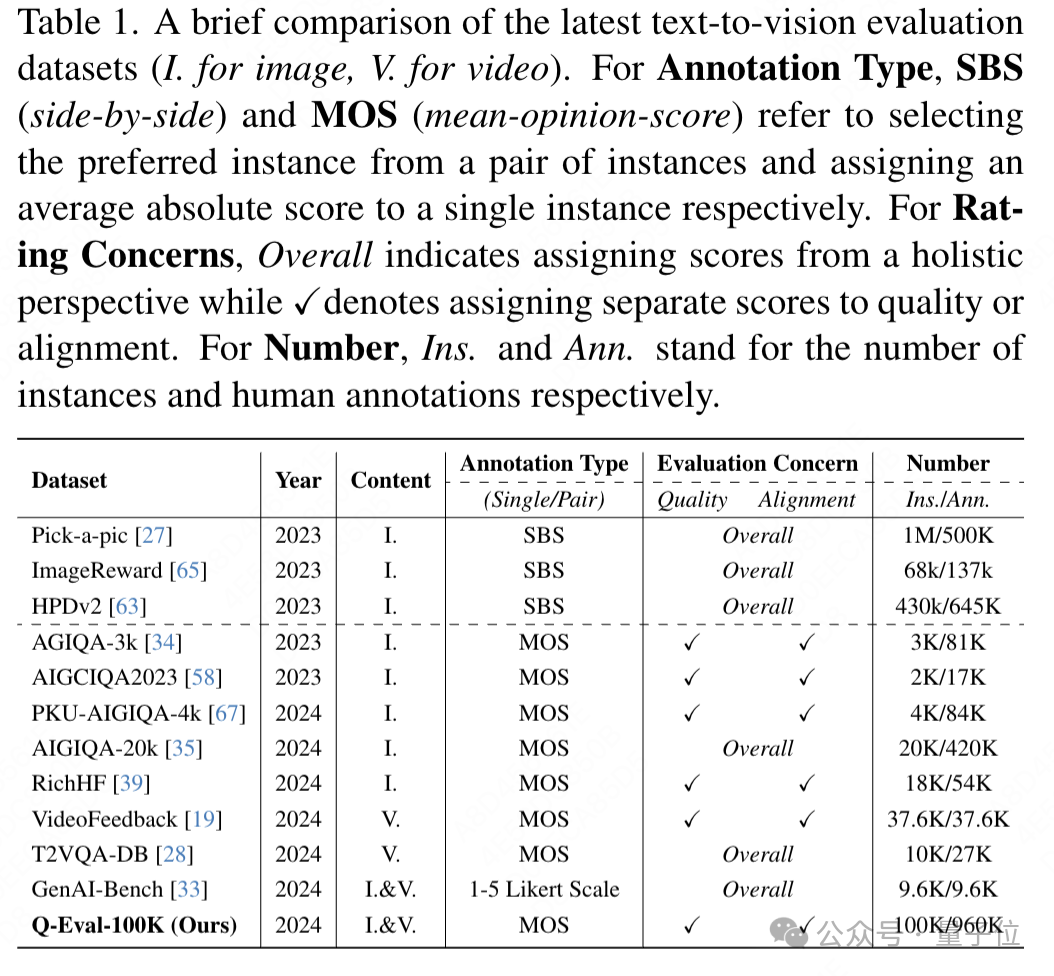
在下表中可以看到數據集Q-Eval-100K的實例數量和人工標註數量遠超其他數據集,可以說Q-Eval-100K是當前最大的AIGC評估數據集。
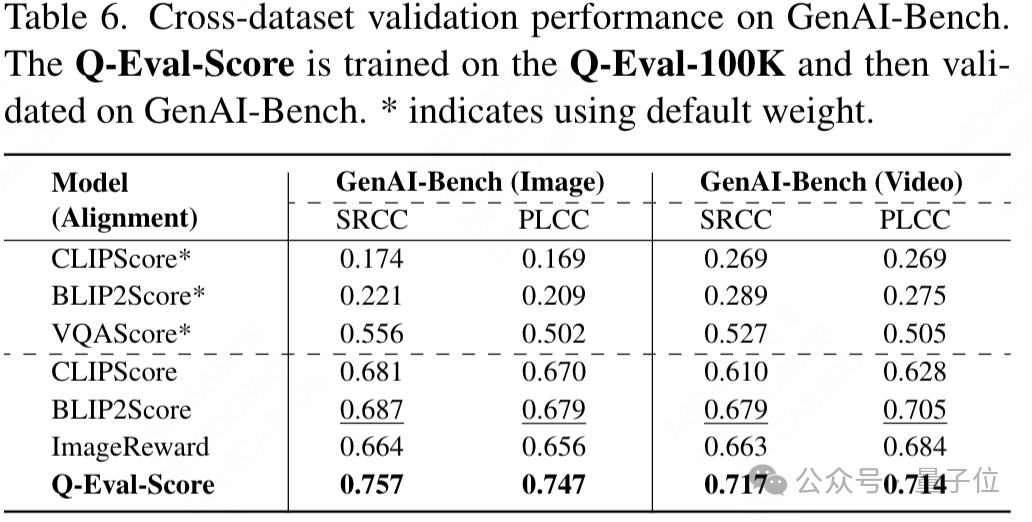
同時跨數據集驗證顯示,在Q-Eval-100K上訓練的模型在GenAI-Bench數據集上表現出色,遠超當前先進方法,充分證明了Q-Eval-100K數據集的泛化價值。
數據集Q-Eval-100K開啟了文本到視覺內容評估的新時代,同時Q-Eval-Score提供一個開源的較為準確客觀的AIGC打分框架,可用於對AIGC圖片影片生成類模型的評估。
Q-Eval-100K數據集共計包含了100K的AIGC生成數據(其中包含60k的AIGC圖片以及40k的AIGC影片)。
接下來,將對Q-Eval-100K數據集與Q-Eval-Score評估框架進行詳細介紹。
數據集構建
在數據集構建上,團隊確保遵循三個原則:
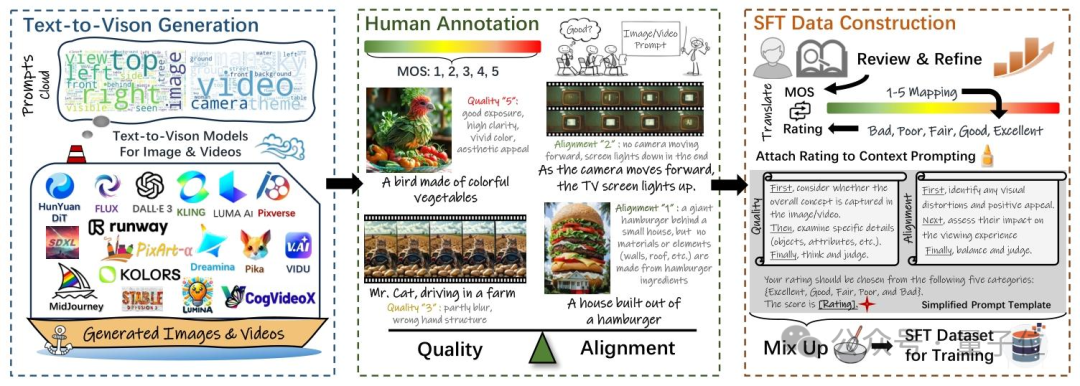
1)保證數據多樣性。為了收集到接近真實場景下多樣性的數據集,團隊從三個大的維度出發構建了對應的prompt集,這三個大的維度可以被劃分為實體生成(people,objects,animals,etc.),實體屬性生成(clothing,color,material,etc.),交叉能力項(backrgound,spatialrelationship,etc.),通過對於不同維度數據的比例控制,確保了prompt數據的多樣性。同時,團隊還使用了當前SOTA開源或者API的AIGC模型進行數據生成,從而確保了生成數據的高質量。這些AIGC模型包括FLUX,Lumina-T2X,PixArt,StableDiffusion 3,CogVideoX,Runway GEN-3,Kling等。
2)高質量的數據標註。團隊招募了200多名經過培訓的人員進行人工打分標註,從這些人員手中收集了超過960k條相關數據的打分信息。經過人工嚴格的篩選和過濾後,最終得到了這100k AIGC數據以及其對應的一致性/質量標註數據。通過這樣的方式,可以確保標註數據與人類偏好的高度一致性,從而提升了Q-Eval-Score評估框架的一致性與泛化能力。
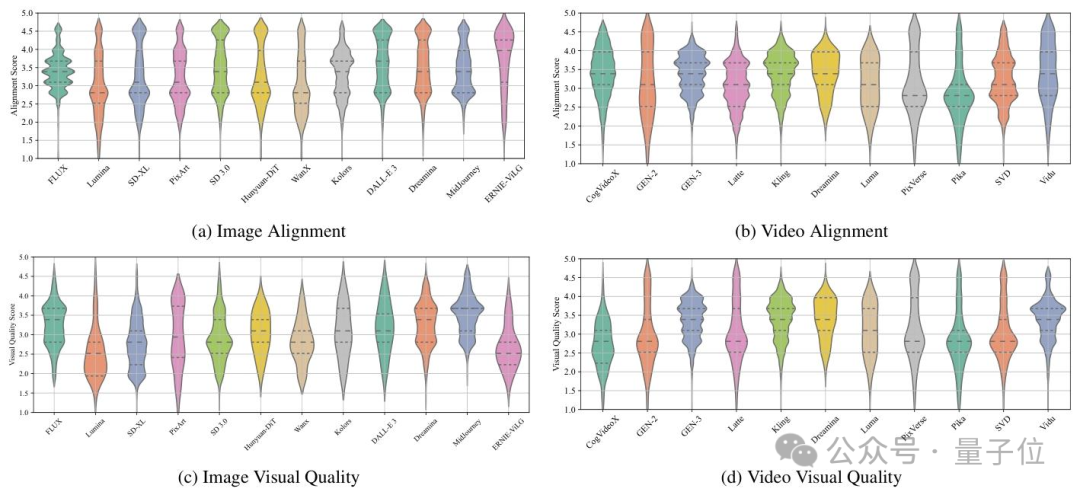
3)視覺質量和文本一致性解耦標註。團隊觀察到當前對於AIGC模型質量的研判主要聚焦於視覺質量和文本一致性兩個方面,因此,在數據集構建的過程當中將兩個維度拆分開標註,以確保Q-Eval-Score可以同時對這兩個維度進行評估。如下圖所示,在統計了多個AIGC模型的視覺質量和文本一致性mos分後,團隊發現兩個維度上模型的表現存在一定的差異性,因此也說明了將兩個維度解耦的必要性。
以上數據集已在AGI-Eval社區評測集專區上線。
統一評估框架
在Q-Eval-100k的基礎上,團隊訓練得到了Q-Eval-Score評估框架,該框架將數據集轉換為監督微調(SFT)數據集,以特定上下文prompt格式訓練大語言模型(LMM),使其能夠獨立評估視覺質量和文本一致性。
模型訓練
首先,團隊構建一個上下文prompt數據集用於大模型的SFT過程,模版如下:

再將人工標註打分按照1-5分分別映射到5個檔位{Bad,Poor,Fair,Good,Excellent}上,以確保數據可用於大模型SFT,人工標註打分映射的過程如下所示。
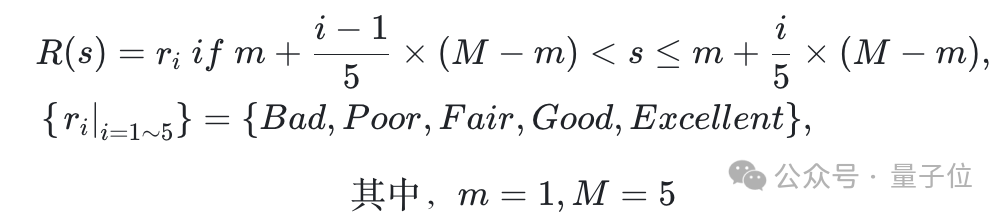
通過將五檔得分的logits概率與權重加權得到最終得分,權重1-0分別表示從Excellent到Bad的得分映射。
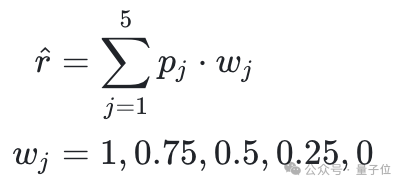
在模型上,團隊選擇了當前在圖像影片理解上性能較為優異的Qwen2-VL-7B-Instruct模型進行SFT微調,在微調時同時啟用CE Loss和MSELoss,用於監督模型打分能力的提升。
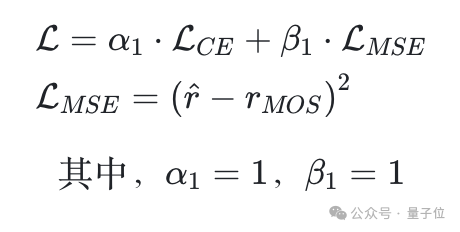
長prompt對齊問題

在文本一致性上,團隊發現在處理長prompt(超過25個詞長)的場景時,常會低估對應的分數,這通常是由於訓練集當中出現的較長提示詞佔比較少導致。
因此,針對長提示詞對齊評估難題,團隊創新性地提出「Vague-to-Specific」策略,將長提示詞拆分為模糊提示詞和多個具體提示詞分別評估,再綜合計算最終得分。
對於模糊提示詞,團隊按照常規方式計算對齊度得分。
然而,對於特定提示詞來說這個策略並不合適,因為每個特定提示詞只涉及視覺內容的一部分。
受VQAScore方法的啟發,團隊將問題修改為更溫和的形式,例如「Doestheimage/videoshow[prompt]?」,以此來評估每個特定提示詞的對齊度。
最後,團隊使用加權方法結合模糊提示詞和特定提示詞的結果,計算最終的對齊分數:
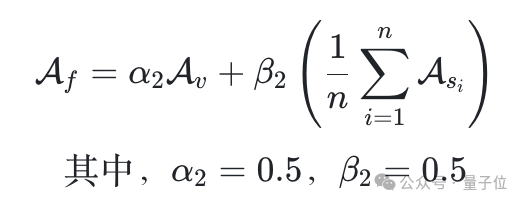
實驗結論
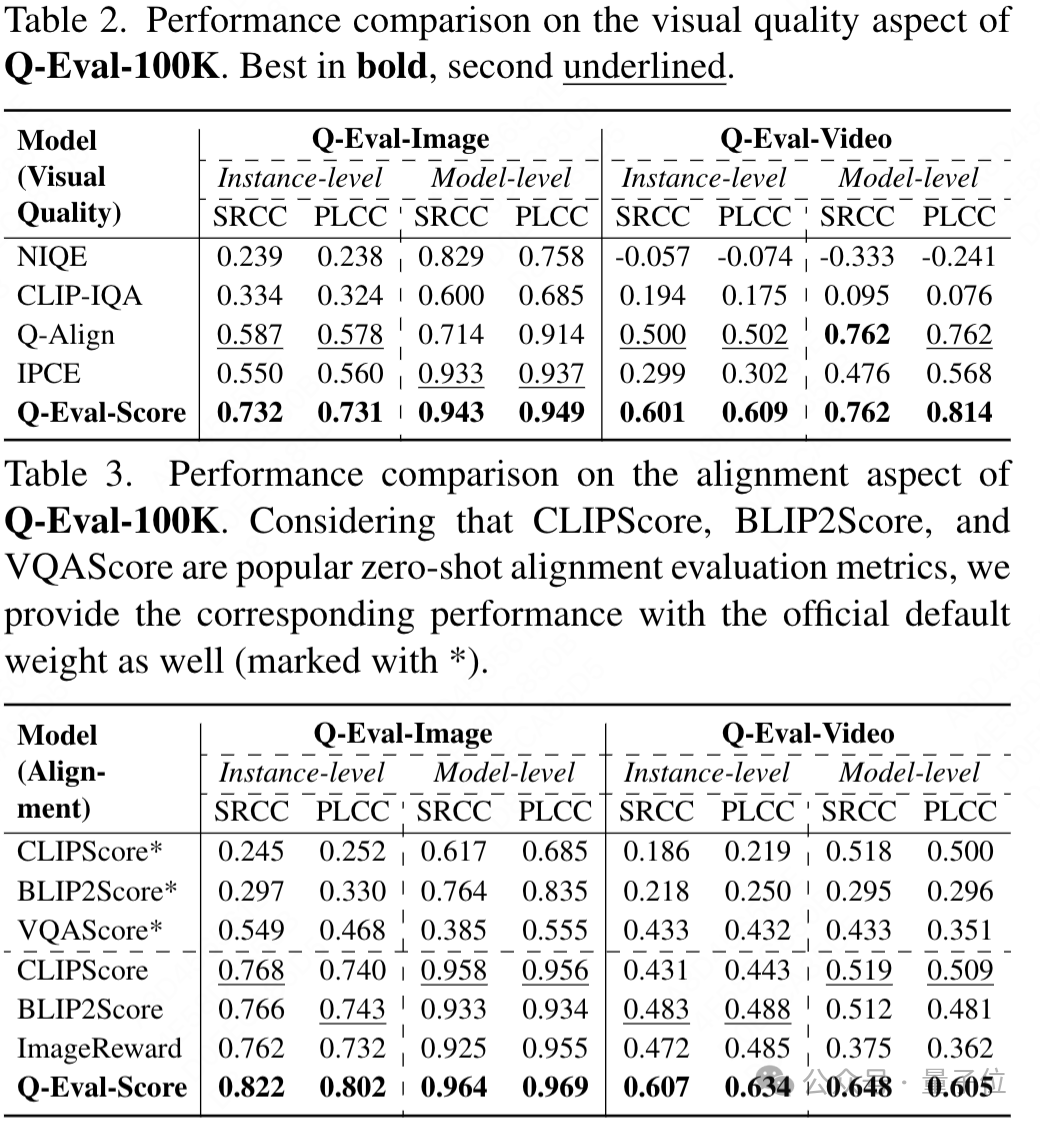
在視覺質量評估方面,Q-Eval-Score在圖像和影片的測試中均表現優異,其預測得分與人工打分的斯皮爾曼等級相關係數(SRCC)和皮爾遜線性相關係數(PLCC)超越了當前所有的SOTA模型。
在文本一致性上,Q-Eval-Score同樣優勢顯著,在圖像和影片的測試中,其Instance-level的SRCC分別領先其他的sota模型6%和12%。
消融實驗表明,研究中提出的各項策略和損失函數對模型性能提升貢獻顯著。
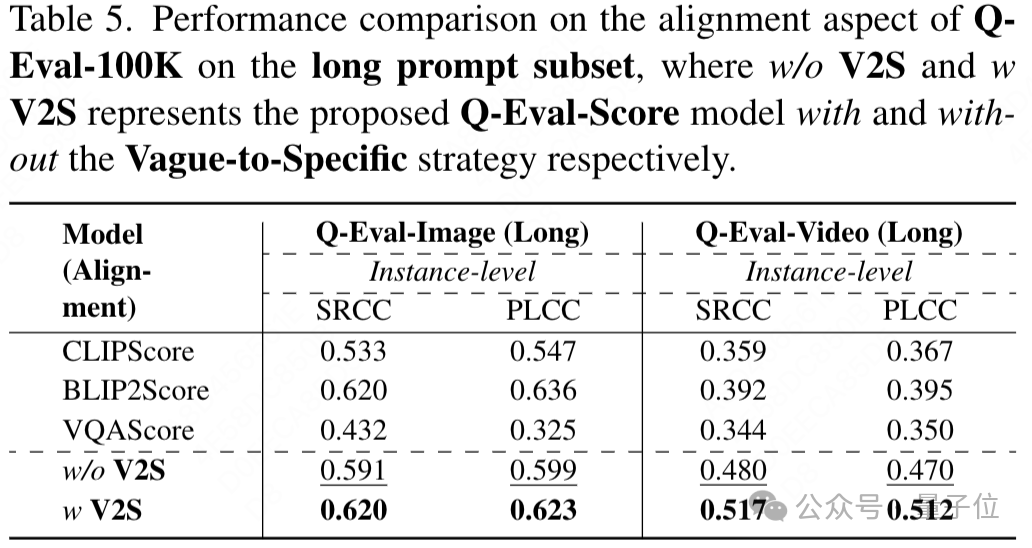
在長提示詞子集測試中,「Vague-to-Specific」策略有效提高了評估性能;
Q-Eval-100K和Q-Eval-Score的出現意義重大。它們為文本到視覺模型的評估提供了更可靠、全面的方案,有助於推動生成式模型的進一步發展和實際應用。未來,這一研究成果有望為相關領域的發展奠定堅實基礎,助力文本到視覺技術邁向新高度。
AGI-Eval評測社區也一直致力於共創如「Q-Eval-100k數據集」這樣優秀的數據集,在模型評測領域深耕,旨在打造公正、可信、科學、全面的評測生態以「評測助力,讓AI成為人類更好的夥伴」為使命。
在評測集社區板塊有行業公開學術評測集,支持用戶下載使用;官方自建評測集,涉及多領域的模型評測;以及用戶自建評測集,平台支持用戶上傳個人評測集,共建開源社區。
論文鏈接:
https://arxiv.org/abs/2503.02357
AGI-Eval評測集專區:https://agi-eval.cn/evaluation/Q-Eval-100K?id=55