AI 已經在編造歷史,別把 DeepSeek 們當權威
最近,一條「有頂流明星在澳門輸了 10 億」的傳聞火了,個中細節寫得繪聲繪色,網民們紛紛猜測,能抵押豪宅和私人飛機填補賭債的明星到底是誰。

漩渦之中,多位明星被推上了風口浪尖,傑威爾音樂、黃曉明本人下場闢謠。


最終由公安網安部門查明,此事是有人用了 AI 造謠。

而昨天我們體驗的最新 Gemini 2.0,突破了 AI 文生圖可控性問題,指哪改哪,但也意味著圖文並茂的以假亂真在使用上的門檻已經極低。
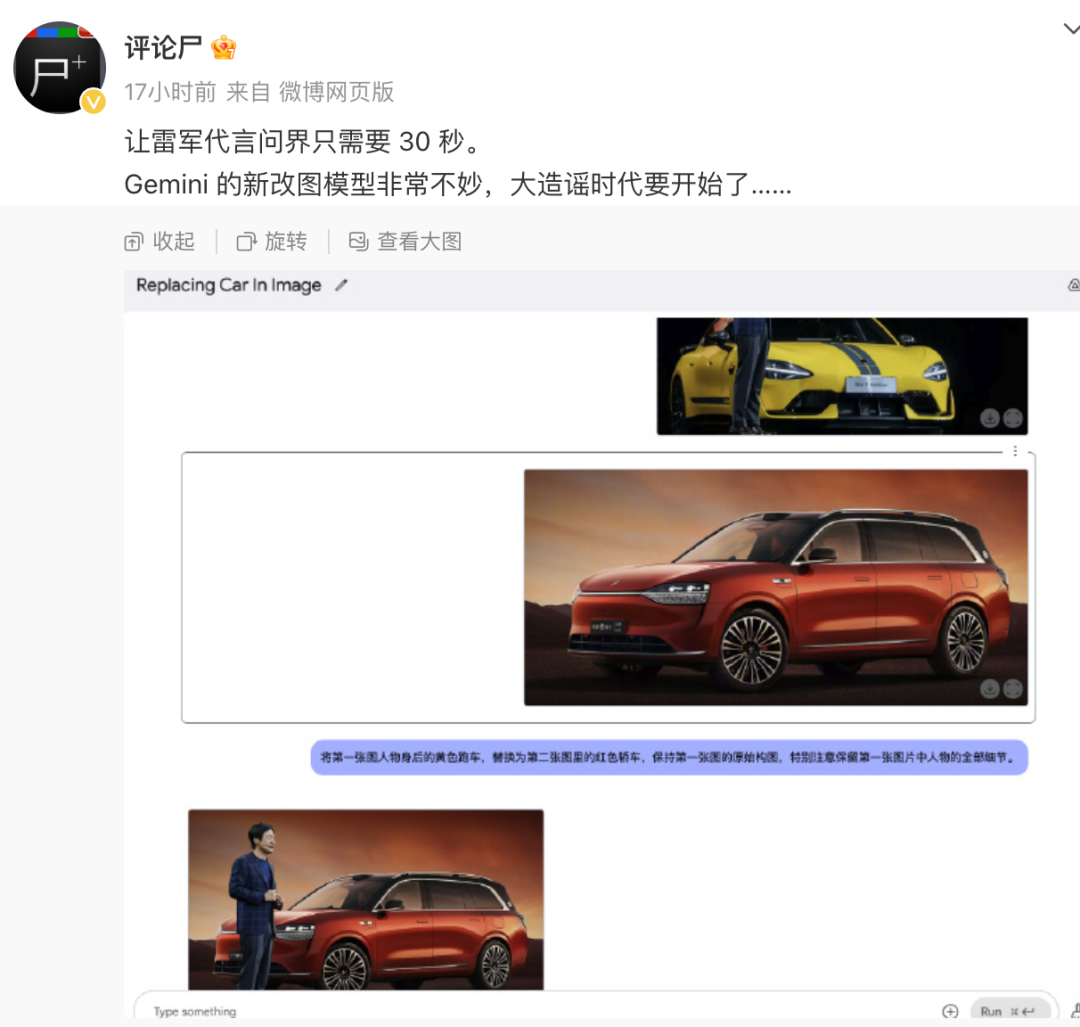
太陽底下沒有新鮮事,生成式 AI 的本質決定了,AI 有概率生成看似合理但不正確的內容。
但當 AI 越來越能自圓其說,越來越多的用戶將 AI 生成的答案奉為圭臬,越來越多的有心人故意用 AI 編造事實,那麼 AI 幻覺的影響,也就更加無法想像。
本就存在很多空白和創造空間的時事歷史、社會熱點,已經成了 AI 幻覺的重災區。
AI 拿捏文筆和故事,但容易編造歷史
AI容易產生幻覺,是一個客觀事實。文筆出眾的 DeepSeek,同時也有著高幻覺率。
根據 Vectara HHEM 的 AI 幻覺測試,DeepSeek-R1 的幻覺率達到 14.3%,遠高於 DeepSeek-V3 的 3.9%。

當我讓 DeepSeek-R1 以三國真實的歷史背景寫故事時,發現它的文筆和情節設計得不錯,但很容易出現時間點的錯誤。
一個例子是,DeepSeek-R1 寫的魏文帝曹丕臨死前的場景,提到曹丕死時是「建安二十五年冬」,然而,曹丕在黃初七年(226 年)去世,建安二十五年(220 年)是曹操逝世和曹丕稱帝的年份。

文中提到的「十五歲那年……銅雀台大宴群臣」也是錯的,曹丕 15 歲時是建安七年(202 年),司馬懿在曹操手下擔任文學掾是建安十三年(208 年),鄴城銅雀台始建於建安十五年(210 年),前後差了好幾年,所以不可能發生這樣一幅畫面。
同樣的問題,出現在 DeepSeek 寫蜀國將領薑維的時候。這個故事的背景是成都之亂,發生在 264 年,薑維在 228 年投奔蜀國,成為諸葛亮的部下,但文中提到「二十七年前」,暗示 237 年薑維還在魏國,顯然是不對的。

更離譜的是,當我讓 DeepSeek 幫我想像,在烏孫生活了半個世紀、70 歲返回長安兩年後就病逝的西漢和親公主劉解憂,可能會留下什麼遺言,雖然奏疏寫得情真意切,但它居然提到了東漢末年的蔡文姬,不符合歷史順序。

我這般咬文嚼字,確實有些為難 AI。為什麼大模型有幻覺呢?這是生成式 AI 的預測機制決定的。大模型不是數據庫,它們學習的是語言模式和概率分佈,而非明確存儲事實,預測「下一個詞最可能是什麼」,而不是查詢「這個事實是否正確」,它們也並不理解,輸出的信息是否是真實的。
而在創意寫作時,模型被激勵發揮創造性,為了讓故事流暢,模型會主動「填補空白」,在歷史記錄不足的地方創造場景和對話,不會明確區分「我確定知道的歷史事實」和「為了故事合理而假設的情節」,又增加了出錯風險。
AI 出錯很正常,但被有心人利用,就是另一回事了。歷史博主@知北遊就遇到過這樣的糟心事,一個網民發給她 AI 編的文獻資料,行文風格符合當時的年代,直到她發現時間人事對不上,並動用線下的人脈去驗證,才肯定都是偽造的。
 圖片來自:豆瓣@知北遊
圖片來自:豆瓣@知北遊每個人物的一生,都是歷史的一部分。然而,一種使用 AI 的方式,已經打破了基本的底線。每當明星過世,會出現很多的紀念文章回顧他們的職業生涯,但其中不乏用 AI 渾水摸魚的。
比如寫方大同的這篇,行文一股 DeepSeek 味,「最後一條微博」的內容明顯是和現實不符的事實錯誤,文末甚至明目張膽地提及,參考了材料,但進行了文學化改編,揣摩了人物的心理活動。

互聯網是有記憶的,更早之前,一篇自稱「梁文鋒」的知乎回應,也疑似 DeepSeek 寫就。2 月 6 日,DeepSeek 團隊出來打假,表示官方帳號只有三個,微信公眾號、小紅書、X(Twitter),其他以 DeepSeek 或者相關負責人名義發佈信息的,都是仿冒帳號。
怎麼治理惡意傳播不實信息的 AI 生成內容,已經成了微博等平台的新問題。

然而,可以想像,以後產出這類信息的速度只會越來越快,越來越多的營銷號抱上 AI 的大腿張口就來,同時,辨別的成本也會變得越來越高,因為我們不可能在每個領域都是專業人士,總有一款虛假信息適合你。
AI 的答案不等於知識,追溯源頭的事實核查成了剛需
DeepSeek 的爆火,真正地讓很多用戶知道和用上了生成式 AI,同時出現了一個奇怪的現象:認為 AI 說的就是對的,熱搜上隔三差五地出現以 DeepSeek 為主語的熱搜,替代了從前的「專家說」。
大模型給出的信息不等同於知識,輕信 AI、將 AI 作為權威的結果是,不走心的人類容易上當受騙。
最近就有一個現身說法的例子,上海譯文出版社的陀思妥耶夫斯基精選集,推廣文案里引用了「魯迅」的評價,但這句話並不是魯迅說的。博主@史芬稗類查證了一番,雖然沒有原始出處,但一個模擬魯迅的文心智能體的回答里,提到了這一句。
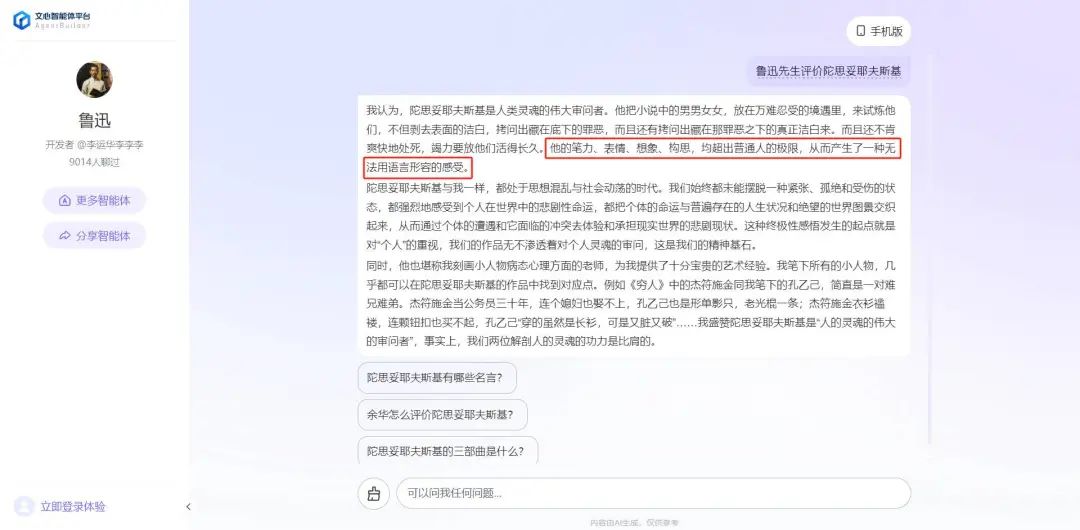 圖片來自:微博@史芬稗類
圖片來自:微博@史芬稗類幽默的事情發生了,意識到問題後,引用了虛假評價的營銷推文,把「魯迅說」編輯成了「有人說」。

然而,以訛傳訛,傳的人多了,假的也就成真的了。這條所謂的「名言」已經汙染了互聯網,去問 AI 搜索,AI 搜索認為是魯迅說的。

如果虛假信息是有意為之的,那麼危害就更加微妙。追蹤新聞網站可靠性的NewsGuard,發現了一種引導輿論的新方式:通過大量虛假信息滲透 AI 模型的檢索數據,從而影響這些模型對特定話題的回應。他們調查的一起事件中,AI 引用錯誤信息的概率高達 33%。
這也說明,雖然加了聯網搜索之後,可以降低 AI 的幻覺,但也並不是絕對的。
聯網搜索可以讓 AI 獲取實時信息,克服知識截止時間的局限,對於模型訓練數據中罕見的主題,也能獲取更準確的信息,但它也引入了新的問題,如果搜索到的信息本身就是錯誤的,AI 可能會放大這些錯誤,並且難以充分評估檢索內容的可靠性。
AI 固然能提高效率,但查找資料這件事,反而應該變得更謹慎。我們需要更在意,某篇文章是誰寫的,信息的最早出處是哪裡。
更值得警惕的,是 AI 改變了獲得情緒價值的方式
AI只是工具,它所導致的問題,根源在於人類自己。生成式AI之前,胡編亂造的信息也並不少,AI起到的作用是,讓真假參半的內容生產得更快、成本更低,甚至行文更加有模有樣,質量高於很多營銷號內容的下限。
AI 幻覺,反過來看便是 AI 的創造力。或者,我們可以將 AI 幻覺理解為「有邏輯的合理補白」。它的幻覺內容,通常符合語言、邏輯、知識的一般結構,基於訓練數據分佈,填補了信息空白處的「最可能內容」。
這不禁讓我聯想,歷史有時候比想像的還荒謬、還沒有邏輯,不能以常理揣度,鍾會為什麼反了,曹丕為什麼學驢叫,爾朱榮怎麼會被元子攸刺殺了……AI 的補白,或許就是某種平行時空的可能性、某種歷史的如果。

有時候,我們閱讀文章和故事,不是為了汲取信息,而是為了獲得情緒價值。AI 就能很好地承擔這個角色,彌補真實歷史的遺憾,以及我們內心的「意難平」。就像一位教授所說,「歷史的盡頭就是文學的開始」。
我曾讓 DeepSeek 模仿李白的風格,給杜甫的《天末懷李白》回一首詩。

我也曾讓 DeepSeek 嘗試想像,如果元稹沒有死在 831 年的武昌任上,而是和白居易在洛陽養老,他們會怎樣以詩相和。

那些用 AI 造假明星生平和時事熱點的內容,本質也是用情緒挑動讀者的神經。
AI 提供答案的即時性、吐出各種文體的創造力,總讓人著迷。它是很多人的焦慮來源,卻也是方便快捷的告慰渠道。這也提醒著我們,警惕一個變本加厲的「後真相時代」。
「後真相」指的是,客觀事實在塑造公眾輿論方面的影響力,反而低於訴諸情感和個人信仰的內容。它被《牛津詞典》評為 2016 年年度詞彙,至今依然適用,甚至變得更加準確——AI 內容寫得出彩,就存在被傳播的可能性,真實與否反而顯得不重要了。
當 AI 可以用更快的速度製造不限量的內容,更輕鬆,更無痛,更真假難辨,更容易讓人高度依賴單一的信息獲取方式,比任何的造假信息更值得我們警惕。但這並不是 AI 的問題,容易失真的鏡子裡,照見的還是人類對於情緒價值的渴望。
我們正在招募夥伴
 簡曆投遞郵箱
簡曆投遞郵箱
hr@ifanr.com
 郵件標題「姓名+崗位名稱」(請隨簡曆附上項目/作品或相關鏈接)
郵件標題「姓名+崗位名稱」(請隨簡曆附上項目/作品或相關鏈接)