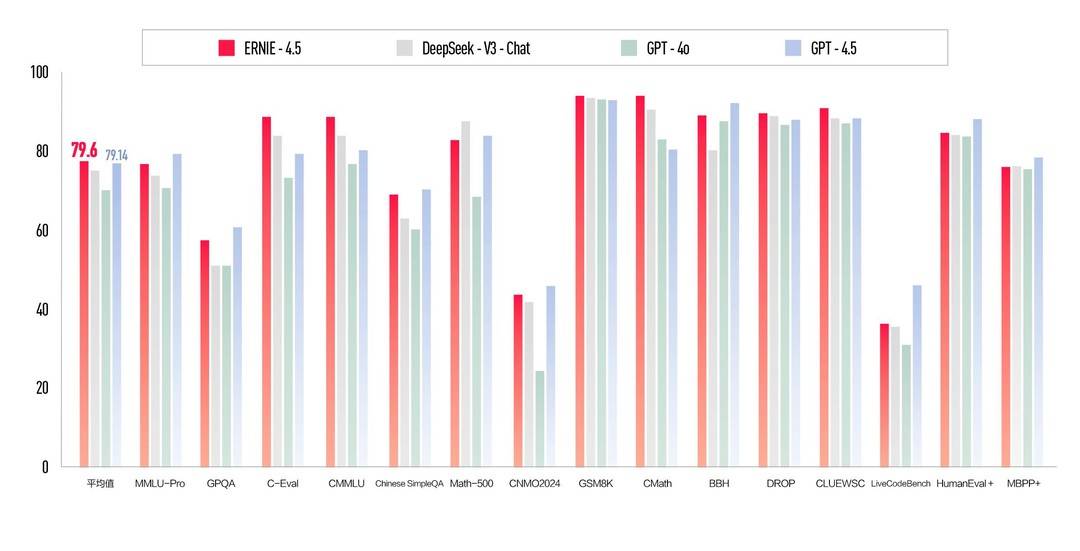
27個大模型混戰電商領域,DeepSeek-R1&V3仍是最強丨首個中文電商問答基準評估結果
淘天未來生活實驗室 投稿
量子位 | 公眾號 QbitAI
全面評估大模型電商領域能力,首個聚焦電商基礎概念的可擴展問答基準來了!
ChineseEcomQA,來自淘天集團。
此前,大模型常因生成事實性錯誤信息而受限,而傳統基準又難以兼顧電商任務的多樣性與領域特殊性。
但隨著大模型在電商領域的廣泛應用,如何精準評估其對專業領域知識的掌握成為關鍵挑戰。
為此,ChineseEcomQA針對性進行了3大核心設計:
-
基礎概念覆蓋:覆蓋20大行業,聚焦10類核心電商概念(如行業分類、品牌屬性、用戶意圖等),包含1800組高質量問答,適配多樣電商任務;
-
混合數據構建:融合LLM生成、檢索增強(RAG)與人工標註,確保數據質量與領域專業性;
-
平衡評估維度:兼顧行業通用性與專業性,支持精準領域能力驗證。

ChineseEcomQA構建流程
從電子商務基本元素(用戶行為、商品信息等)出發,團隊總結出電子商務概念的主要類型。
最終定義了從基礎概唸到高級概念的10個子概念(具體詳見論文):
行業分類、行業概念、類別概念、品牌概念、屬性概念、口語概念、意圖概念、評論概念、相關性概念、個性化概念。

然後,研究人員採用混合的數據集構建過程,結合LLM驗證、RAG驗證和嚴格的人工標註,確保基準符合三個核心特性:
-
專注基礎概念
-
電商知識通用性
-
電商知識專業性
具體來說,構建ChineseEcomQA主要分為自動化問答對生成和質量驗證兩個階段。
第一階段,問答對生成。
研究者收集了大量知識豐富且涵蓋各種相關概念的電子商務語料庫。
然後,提示大模型(GPT-4o)根據給定的內容忠實地生成問答對;對於比較開放的問題,要求大模型同時提供非常混亂和困難的候選答案。
從而自動化地構建出大量問答對作為初始評測集。
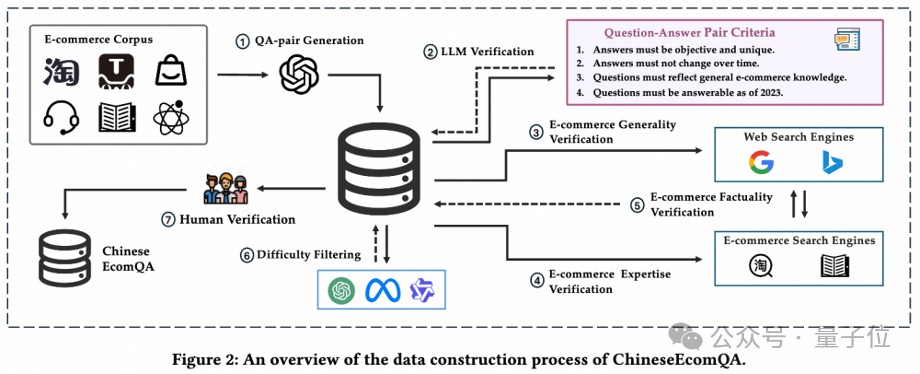
第二階段,質量驗證。
我們開發了一個多輪自動化流程對生成的問答對進行驗證,重新生成或過濾不符合標準的問題。
具體包括大模型驗證、電子商務通用知識驗證、電子商務專業知識驗證、電子商務事實性驗證、難度篩選、人工驗證。
經過多重嚴格篩選,最終得到均勻覆蓋10大類電商子概念的1800條高質量問答對作為終版數據集。

DeepSeek-R1和V3表現最佳
評估了11個閉源模型和16個開源模型,得出如下排名榜:
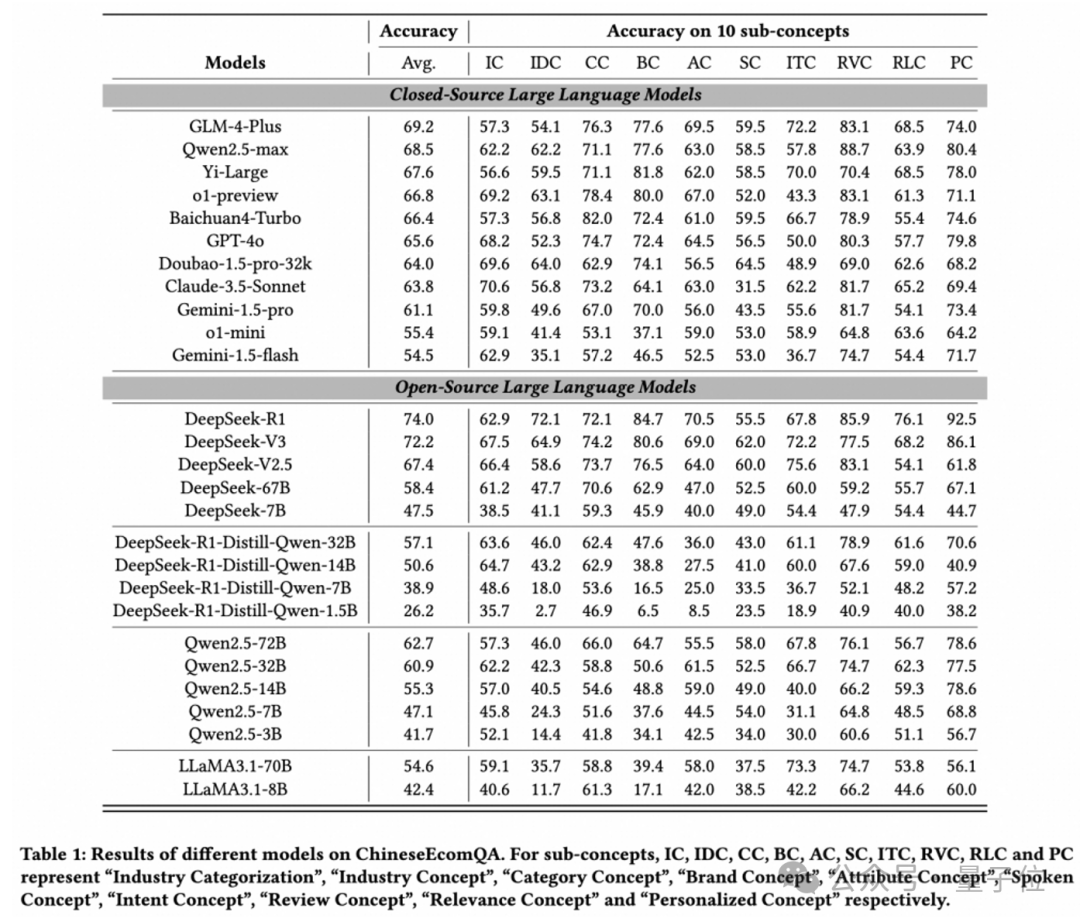
(註:對於子概念,IC、IDC、CC、BC、AC、SC、ITC、RVC、RLC 和 PC 分別代表「行業分類」「行業概念」「類別概念」「品牌概念」「屬性概念」「口語概念」「意圖概念」「評論概念」「相關性概念」和「個性化概念」)
總的來看,DeepSeek-R1和DeepSeek-V3是表現最好的模型,展示了強大的基礎模型(推理模型)在電子商務領域的巨大潛力。
此外,研究團隊對主流模型表現分析並得出了以下發現:
-
更大的模型在高級電商概念上表現更好,遵循Scaling Law,但小模型在特定電商任務上仍面臨顯著挑戰。
-
中文社區模型(如Qwen系列、GLM-4)在電商場景適應性上表現突出,尤其是在高級電子商務概念上。雖然O1-preview在基本概念上表現更好,但在更高級的概念上面臨困難。
-
某些類型的電子商務概念(如相關性概念)仍然對 LLM 構成重大挑戰。大參數量模型由於其強大的通用能力,可以泛化到電商任務上,而小參數量模型則更有困難。這些特點體現了專門開發電商領域模型的必要性。
-
Deepseek-R1-Distill-Qwen系列的表現不如原始的Qwen系列,主要原因是在推理過程中引入知識點錯誤,進而導致最終結論出錯。
-
開源模型和閉源模型之間的性能差距很小。以Deepseek為代表的開源模型使二者達到了相似的水平。
-
通過引入RAG策略,模型的性能顯著提升,縮小了不同模型之間的性能差距。
-
LLM的自我評估能力(校準)在不同模型中存在差異,更大的模型通常表現出更好的校準能力。
-
Reasoning LLM需警惕「思維鏈中的事實性錯誤累積」,尤其是蒸餾模型。
同時,團隊還在ChineseEcomQA上探索了模型校準、RAG、推理模型思維過程等熱門研究課題(具體詳見論文)。
模型往往對回答「過於自信」
一個完美校準的模型應該表現出與其預測準確度一致的置信度。
ChineseEcomQA團隊通過提示模型在回答問題的同時給出其對回答內容的置信度(範圍0到100),探索模型的事實準確性與置信度之間的關係。
結果顯示,o1-preview表現出最佳對齊性能,其次是o1-mini。
然而,大多數模型始終低於完美對齊線,表明模型普遍存在過度自信的趨勢。
這凸顯了改進大型語言模型校準以減輕過度自信產生錯誤響應的巨大空間。
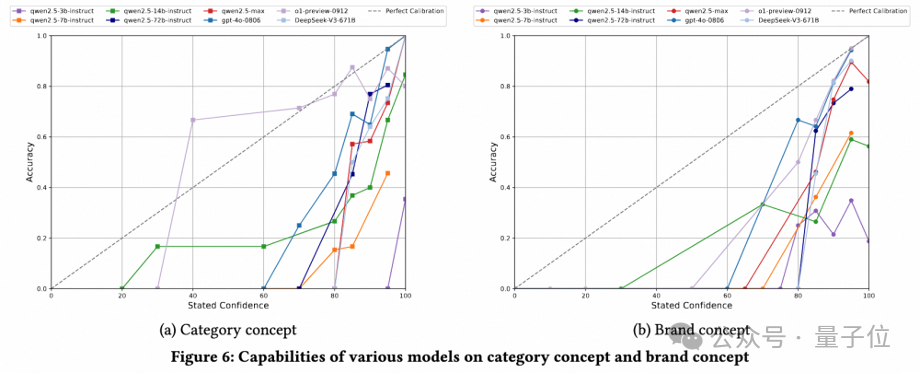
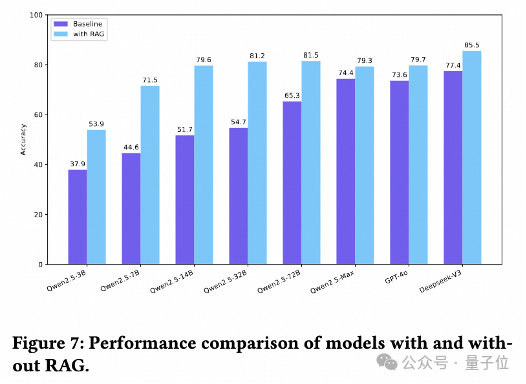
RAG仍是快速提升模型能力的捷徑
研究過程中,團隊探討了RAG策略在ChineseEcomQA數據集上增強LLM領域知識的有效性。
具體來說,研究者在類別概念和品牌概念上的設置重現了一個RAG系統。
結果顯示,所有模型都通過RAG都得到了顯著提升。研究人員總結出三個詳細的結論。
第一,對於小型LLM,引入RAG信息可以顯著提高評估指標的絕對值。
例如,Qwen2.5-14B實現了27.9%的改進。
第二,對於大型LLM,RAG也可以實現顯著的相對改進。
例如,DeepSeek-V3的平均相對改進達到了10.44%(準確率從77.4提高到85.5)。
第三,在RAG設置下,模型之間的性能仍然遵循縮放規律,但差距迅速縮小。
例如,Deepseek-V3和Qwen2.5-72B之間的準確率差異從12.1%縮小到 4%。
總之,RAG仍是增強LLM電子商務知識的有效方法。
警惕「思維鏈中的事實性錯誤累積」
在主要結果中,Deepseek-R1取得了最佳結果,充分展示了Reasoning LLM在開放領域中的潛力。
然而,在從Deepseek-R1蒸餾出的Qwen系列模型上,準確率明顯低於預期。
由於開源Reasoning LLM揭示了它們的思維過程,研究者進一步調查其錯誤的原因,並將推理模型的思維過程分為以下四種類型:
-
Type A:Reasoning LLM通過自我反思反復確認正確答案。
-
Type B:Reasoning LLM最初犯了錯誤,但通過自我反思糾正了錯誤。
-
Type C:Reasoning LLM通過自我反思引入知識錯誤,導致原本可能正確的答案被修改為不正確的答案。
-
Type D:Reasoning LLM反復自我反思。雖然最終得出了答案,但並沒有通過反思獲得高度確定和自信的答案。
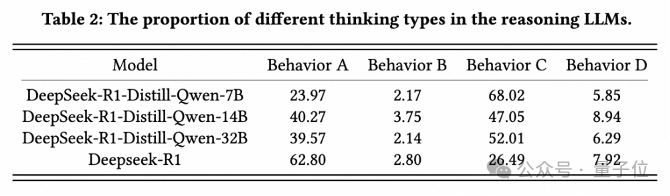
總體而言,Type A和Type B是通過擴大test-time計算量獲得的推理能力;Type C和Type D是膚淺的自我反思,導致最終答案不正確。
由於Deepseek-R1強大的buase模型能力表現出更好的泛化能力。
相比之下,在某些特定領域蒸餾的DeepSeek-R1-Distill-Qwen系列似乎在膚淺的自我反思方面遇到了困難。中間推理步驟中事實錯誤的積累增加了整體錯誤率。
對於較小的推理LLM,開放領域的推理能力不能直接通過數理邏輯能力來泛化,需要找到更好的方法來提高它們的性能。
One More Thing
該論文核心作者包括陳海斌,呂康滔,袁愈錦,蘇文博,研究團隊來自淘天集團算法技術 – 未來生活實驗室。
該實驗室聚焦大模型、多模態等AI技術方向,致力於打造大模型相關基礎算法、模型能力和各類AI Native應用,引領 AI 在生活消費領域的技術創新。
淘天集團算法技術 – 未來生活實驗室團隊將持續更新和維護數據集及評測榜單,歡迎廣大研究者使用我們的評測集進行實驗和研究~
論文鏈接:
https://arxiv.org/abs/2502.20196
項目主頁:
https://openstellarteam.github.io/ChineseEcomQA/
代碼倉庫:
https://github.com/OpenStellarTeam/ChineseEcomQA
數據集下載:
https://huggingface.co/datasets/OpenStellarTeam/Chinese-EcomQA