馴服AI,更懂物理!何愷明團隊提出全新DHN「去噪哈密頓網絡」

新智元報導
編輯:英智
【新智元導讀】何愷明團隊提出的去噪哈密頓網絡(DHN),將哈密頓力學融入神經網絡,突破傳統局部時間步限制,還有獨特去噪機制,在物理推理任務中表現卓越。
近日,何愷明團隊提出了去噪哈密頓網絡(Denoising Hamiltonian Network,DHN),就像給物理知識開了掛。

傳統的機器學習方法雖然能處理一些簡單的物理關係,但面對複雜的物理系統時,卻顯得力不從心。
來自MIT、史丹福、西北大學等的研究者將哈密頓力學算子推廣到神經網絡中,不僅能捕捉非局部時間關係,還能通過去噪機制減輕數值積分誤差。
 論文鏈接:https://arxiv.org/abs/2503.07596
論文鏈接:https://arxiv.org/abs/2503.07596現有的方法對相鄰時間步之間的局部關係進行建模,這就像是只看到了樹木,卻忽略了整個森林。
這種局限性使模型在處理複雜物理系統時,難以把握系統的全局特徵和高級別的相互作用。
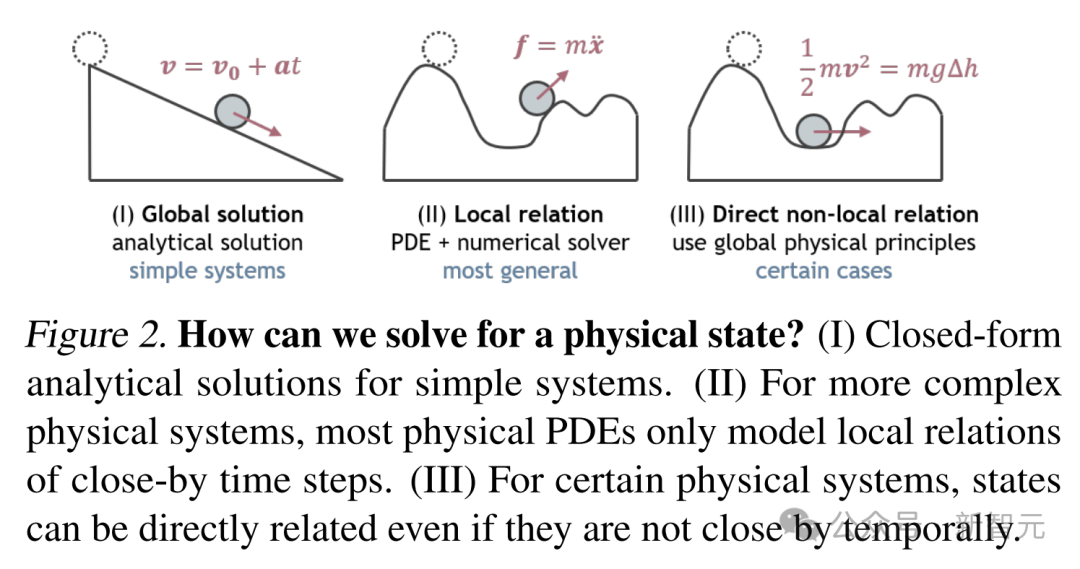
另一方面,它們專注於正向模擬,而忽視了更廣泛的物理推理任務。
實際應用中,往往還需要解決許多其他問題,比如從稀疏的觀測數據中推斷物理參數,對不完整的軌跡進行修復,或者提高軌跡數據的解像度等。
DHN:物理推理的創新引擎
DHN的出現突破了傳統機器學習在物理推理中的局限,它將哈密頓力學巧妙地推廣到神經網絡。
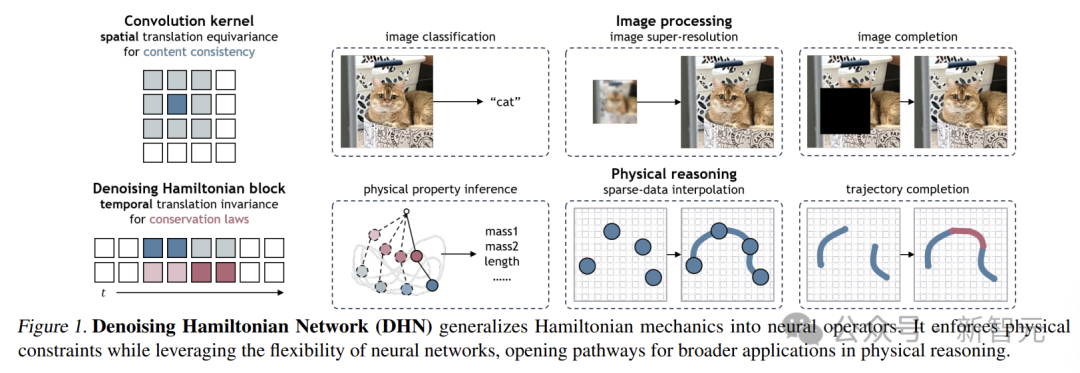
哈密頓力學是經典力學的一種重要表述形式,它通過哈密頓量來描述系統的能量和狀態變化。
DHN引入了塊式離散哈密頓的概念。它把系統狀態按照時間維度劃分為一個個狀態塊,每個狀態塊包含多個時間步的狀態信息。
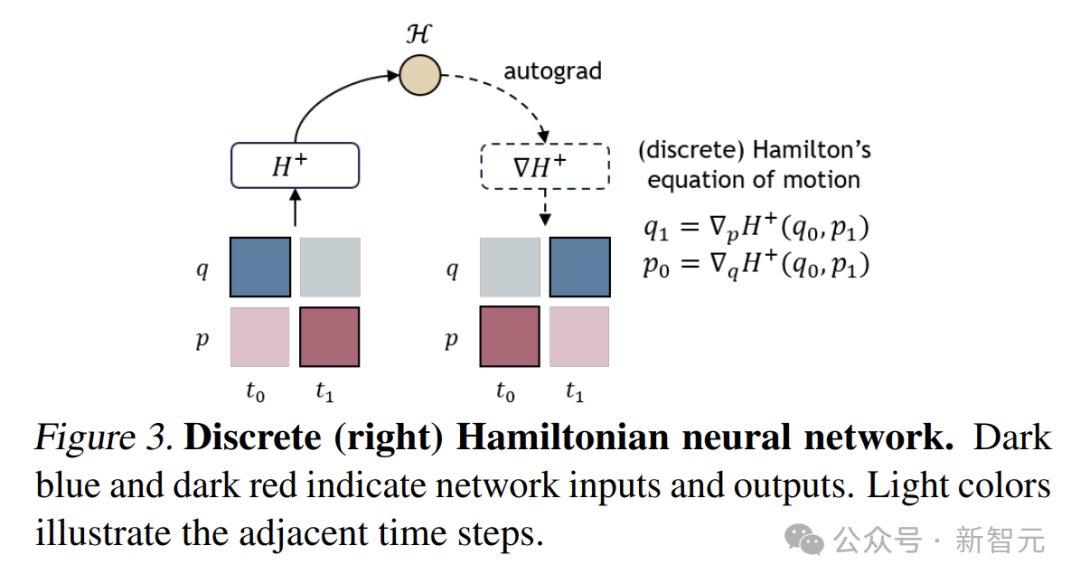
通過這種方式,DHN可以捕捉到更長時間範圍內的狀態關係,突破了傳統方法只能關注局部時間步的限制。
就像看一段舞蹈表演,不再是只關注每一個瞬間的動作,而是能夠連貫地看到舞者在一段時間內的整體動作變化和節奏韻律。
塊式離散哈密頓
將狀態塊定義為沿時間維度連接的(p,q)狀態堆疊,即
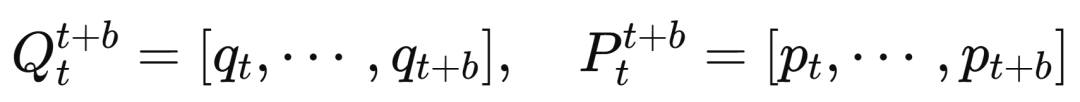
其中b為塊大小。引入步長s作為一個可定義的超參數,取代固定的時間間隔Δt。
這種方法使網絡能夠捕捉更廣泛的時間相關性,同時保持哈密頓結構的不變性。
通過關聯兩個重疊的狀態塊(每個塊大小為b,偏移步長為s)來定義分塊離散哈密頓量:
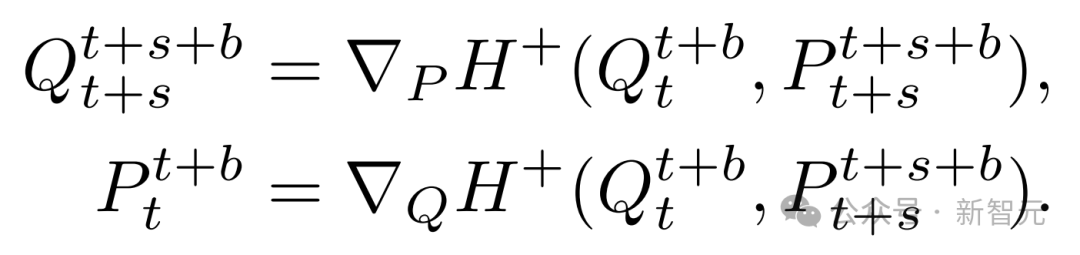
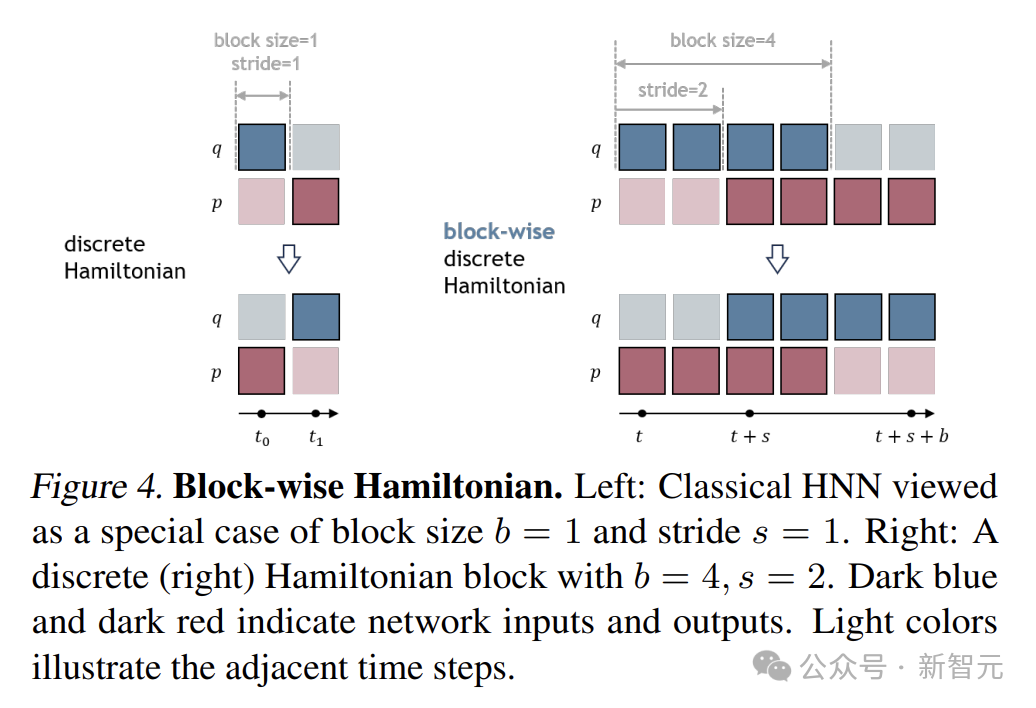
下圖展示了一個塊大小b=4且步長s=2的分塊離散哈密頓量。經典HNN可被視為塊大小b=1且步長s=1的特例。
類似於HNN,分塊離散哈密頓網絡

可通過以下損失函數訓練:
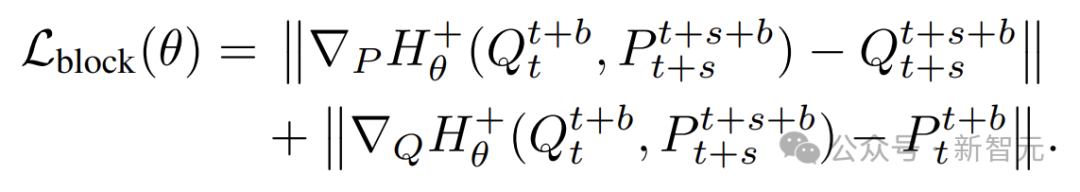
去噪機制
DHN的去噪機制是其一大亮點。
受到去噪擴散模型的啟發,DHN在訓練過程中會對輸入狀態添加不同程度的噪聲,然後通過網絡自身的學習能力,逐步去除這些噪聲,恢復出真實的物理狀態。
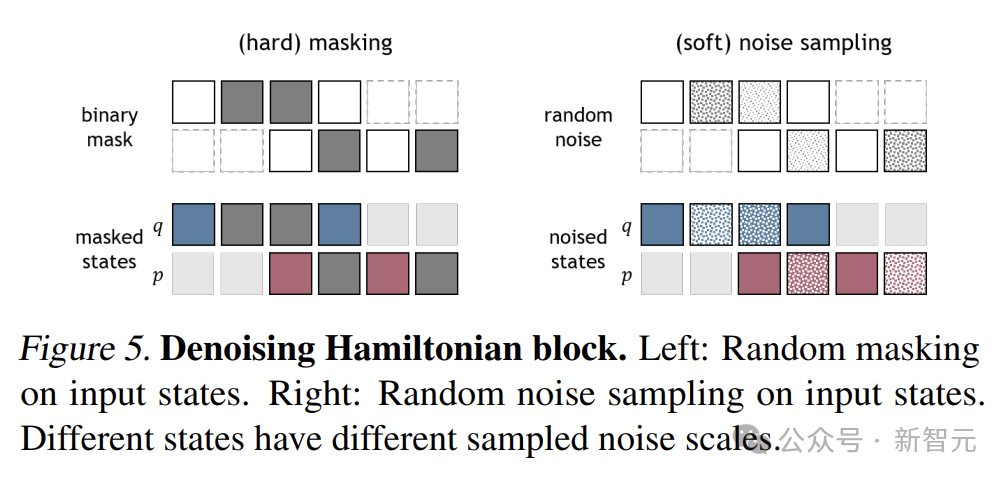
通過這種方式,DHN能有效減輕數值積分誤差,提高模型在長期預測中的穩定性。不同的噪聲模式能讓DHN在各種噪聲條件下保持良好的適應性。
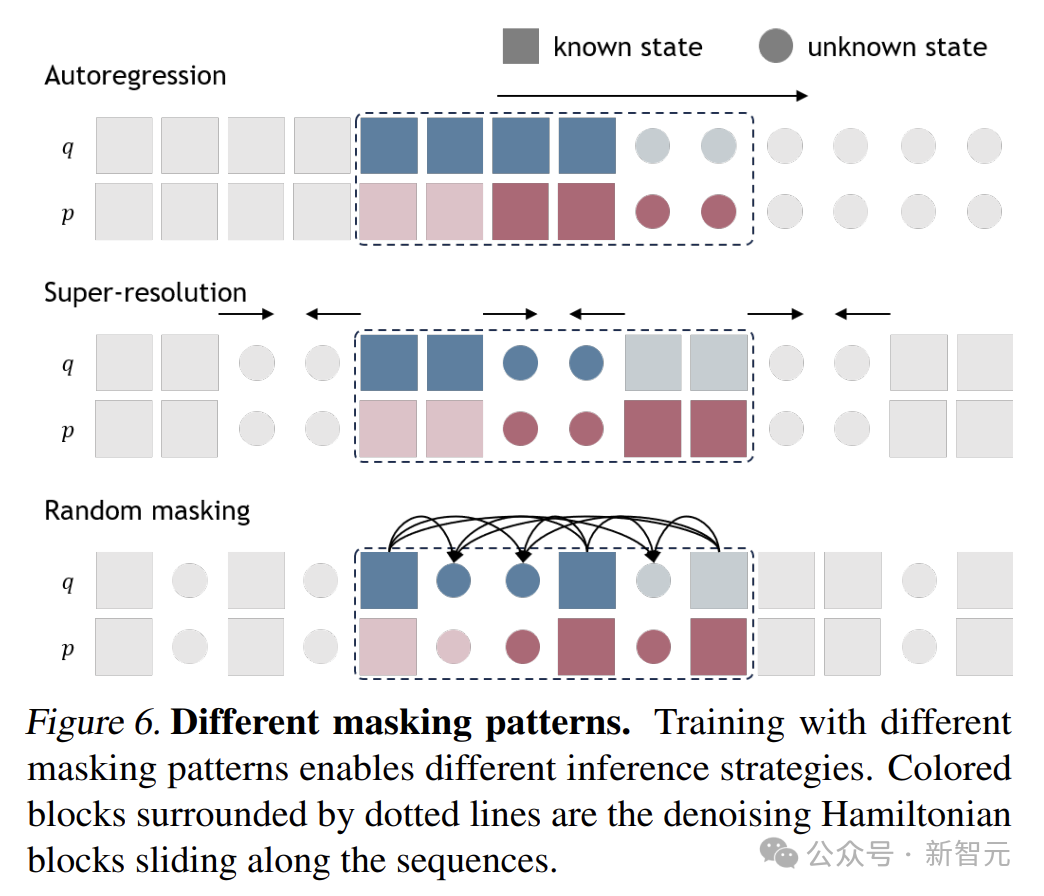
不同掩碼模式
通過在訓練過程中設計不同的掩碼模式,研究團隊實現了靈活的推理策略,以適應不同的任務。
圖中展示了三種不同的掩碼模式:
-
自回歸(autoregression):對塊的最後幾個狀態進行掩碼,這類似於物理模擬中的前向建模,用於下一狀態預測。
-
超解像度(super-resolution):對塊中間的狀態進行掩碼,可用於數據插值。
-
任意階(arbitrary-order):包括隨機掩碼,掩碼模式可根據任務需求自適應設計。
DHN網絡架構
僅解碼Transformer架構
對於每個哈密頓塊,網絡的輸入由不同時刻的
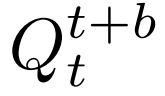
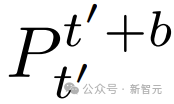
堆疊組成,同時引入一個全局潛在編碼z,用於對整個軌跡進行條件控制。
堆疊以及
僅解碼Transformer採用類似於GPT的僅解碼架構,但不包含因果注意力掩碼。
對所有輸入token
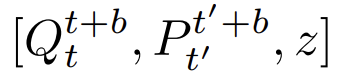
應用自注意力機制,將其作為長度為2b+1的序列處理。
其中,全局潛在編碼z作為查詢token,用於輸出哈密頓值。
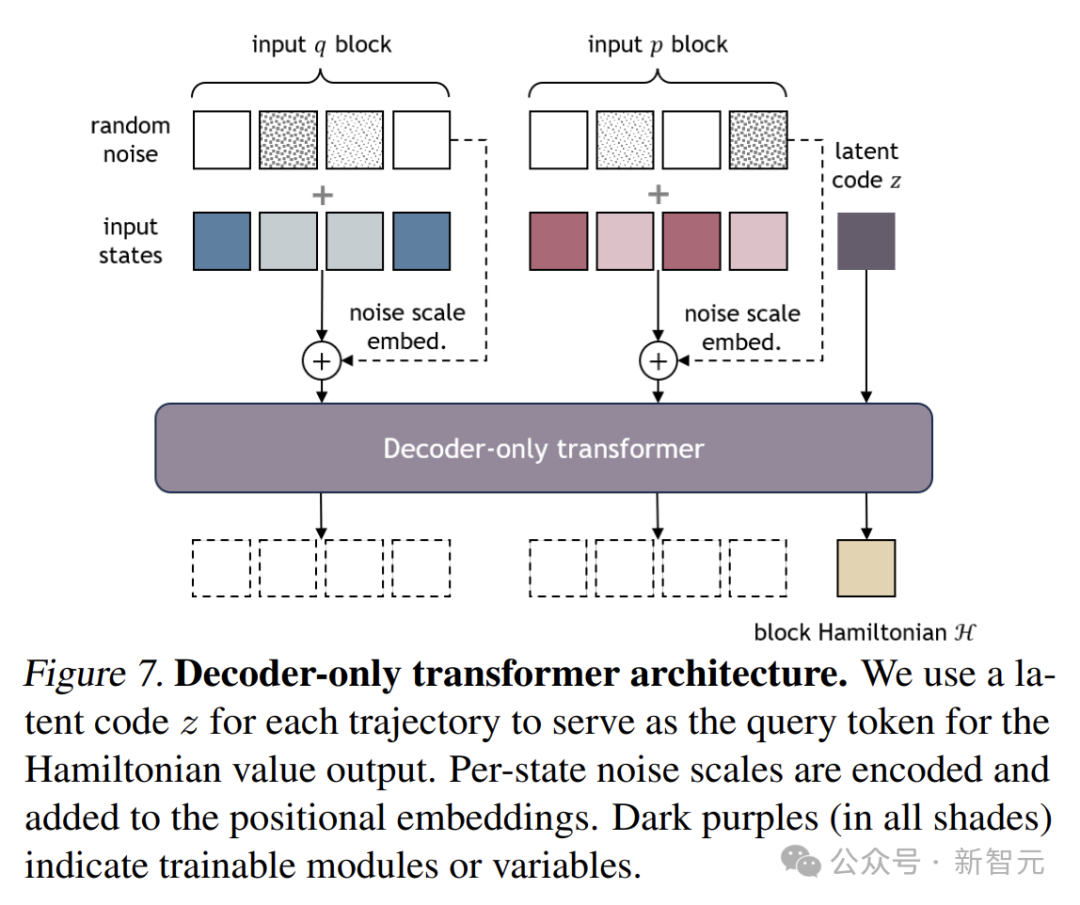
DHN還將每個狀態的噪聲尺度編碼到位置嵌入中,讓網絡更好地感知噪聲對狀態的影響。
研究者實現了一個簡單的兩層Transformer,在單個GPU上就能高效運行。
自動解碼
為了高效地存儲和優化系統特定的嵌入,DHN採用了自動解碼架構。
與傳統的依賴編碼器網絡來推斷潛在編碼的方法不同,DHN為每個軌跡維護一個可學習的潛在編碼z。
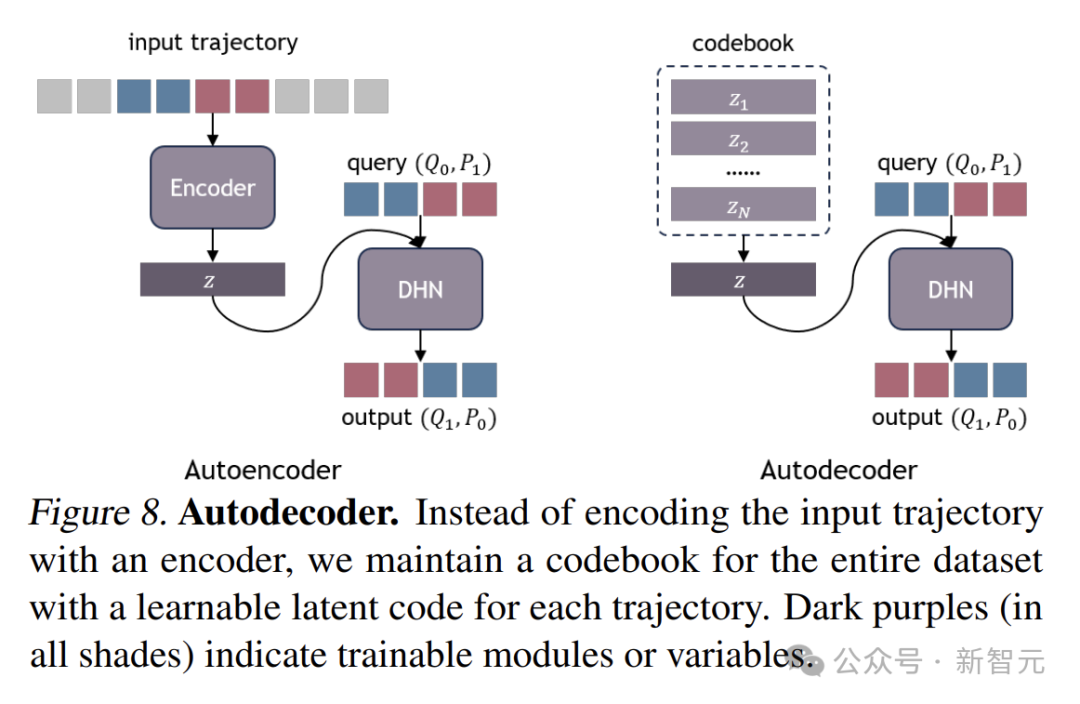
這就好比為每個軌跡建立了一個專屬的「記憶庫」,在訓練過程中,網絡權重和潛在編碼會聯合優化,不斷地調整和完善這個「記憶庫」。
訓練完成後,當遇到新的軌跡時,只需凍結網絡權重,對新軌跡的潛在編碼進行優化,就能快速適應新的情況。
實驗中的卓越表現
為驗證DHN的有效性,研究人員進行了一系列實驗,涵蓋了多個不同的物理推理任務。
正向模擬
在正向模擬任務中,DHN需根據初始條件,逐步預測物理系統的未來狀態。
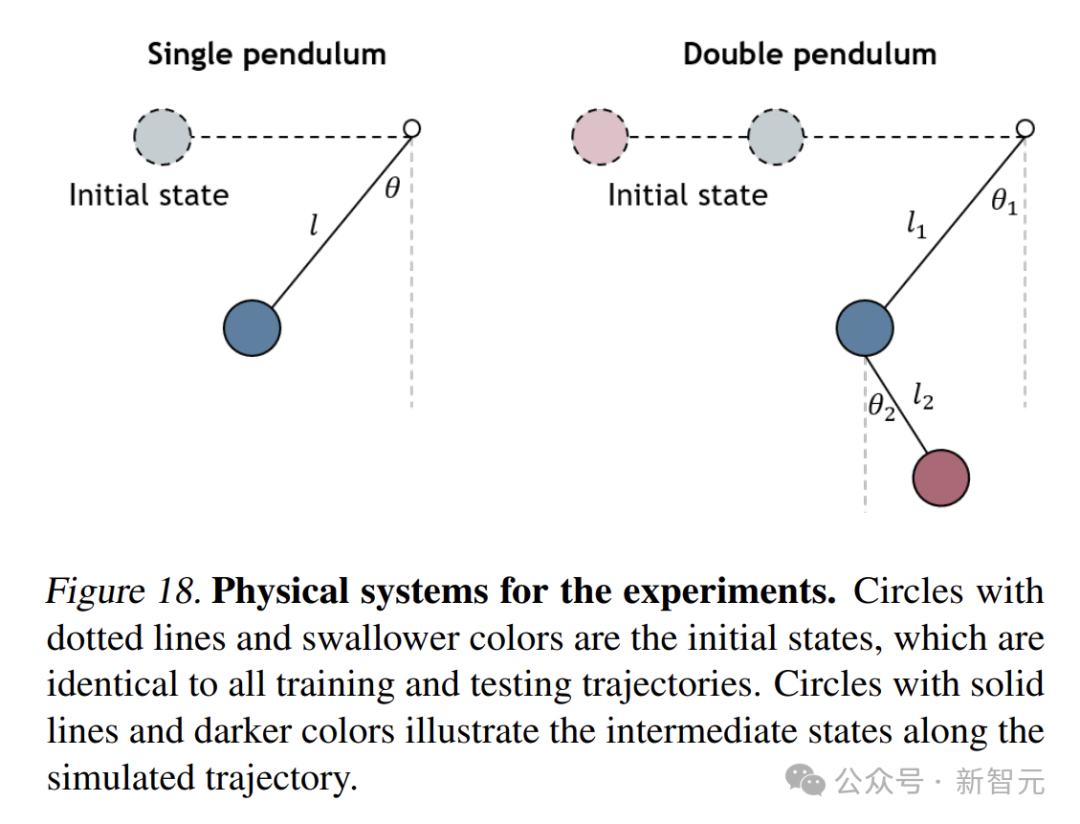
在單擺和雙擺系統中,通過在DHN塊內應用掩碼策略,讓模型學習預測未來狀態。
在擬合已知軌跡的實驗中,與傳統的HNN相比,DHN在預測單擺和雙擺的狀態時,誤差更小。
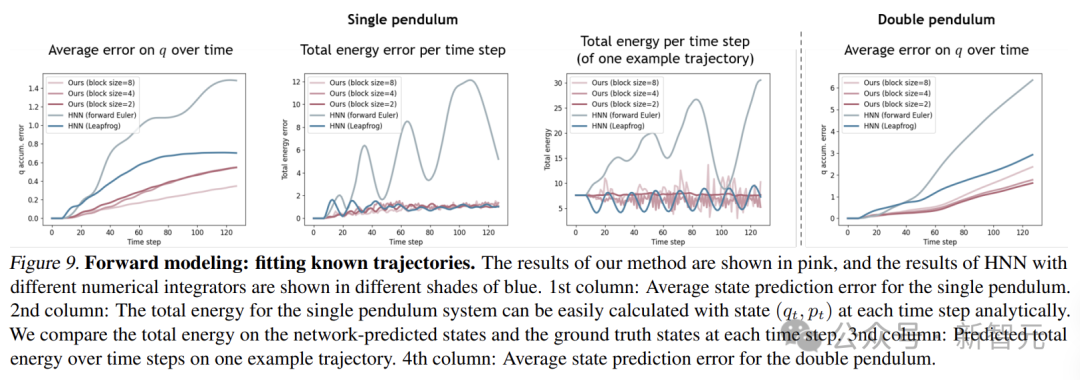
當塊大小為2時,DHN能穩定地守恒總能量,而HNN雖然是一個保證能量守恒的網絡,但由於數值積分器的影響,仍然會出現不可控的能量漂移。
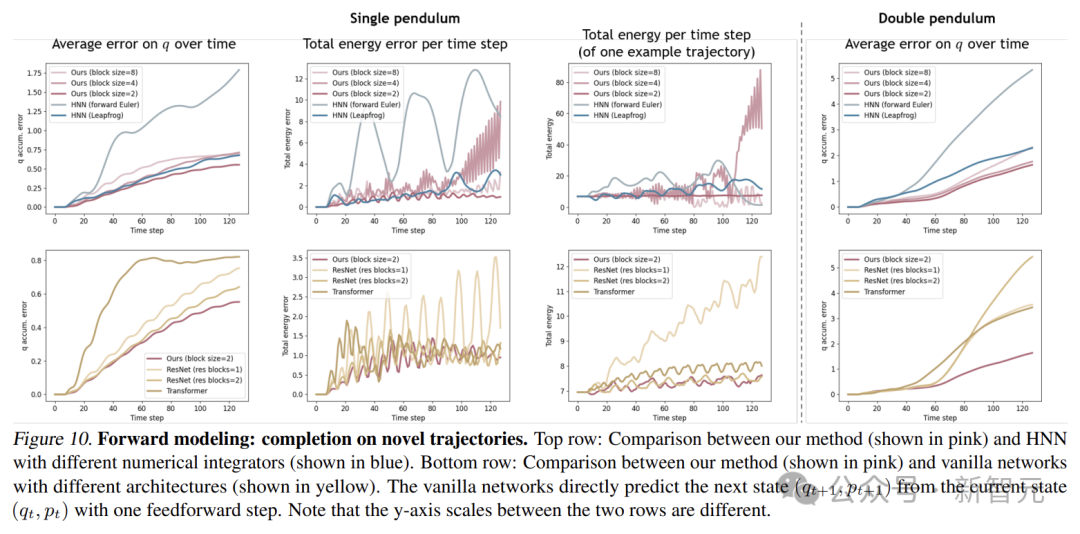
在對新軌跡進行補全的實驗中,DHN同樣表現優異。它能從稀疏的初始觀測中準確地推斷系統動力學,並預測未來狀態。
相比之下,HNN和其他沒有物理約束的基線模型在處理新軌跡時,誤差較大,難以準確預測未來狀態。
表示學習
表示學習是評估模型對物理系統參數編碼和區分能力的重要任務。
DHN用隨機掩碼模式,利用去噪和隨機掩碼這兩種自監督學習技術,來增強在動態物理系統中的表示學習能力。
研究人員在雙擺系統上進行實驗,預測擺長比
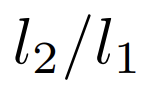
通過對自動解碼器和代碼進行預訓練,然後用線性回歸層對潛在代碼進行線性探測,結果顯示,DHN在學習表示物理屬性方面很出色。
與HNN和普通網絡相比,DHN的均方誤差更低,能夠更準確地捕捉到物理系統的潛在特徵。
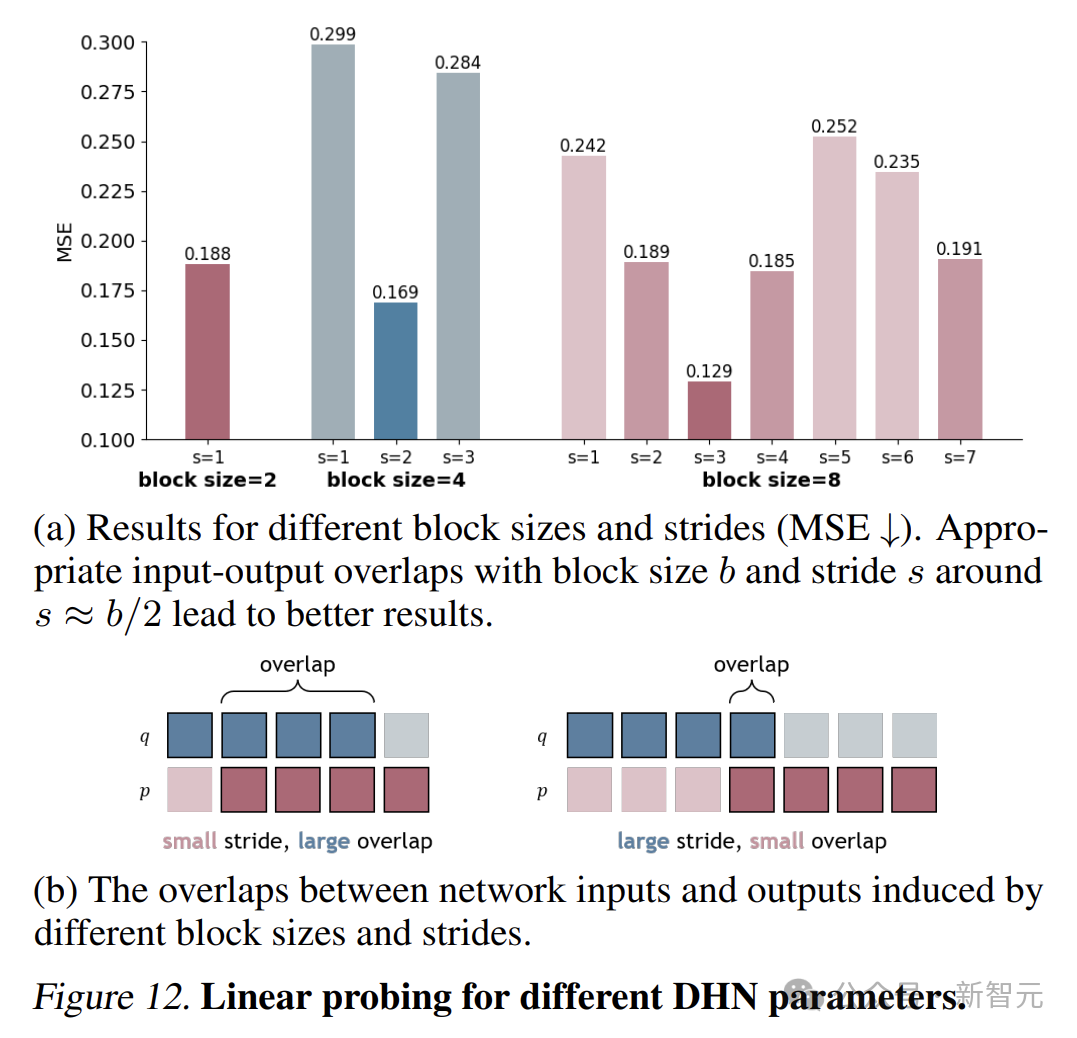
研究還發現,在雙擺系統中,塊大小為4是推斷其參數的最佳時間尺度。
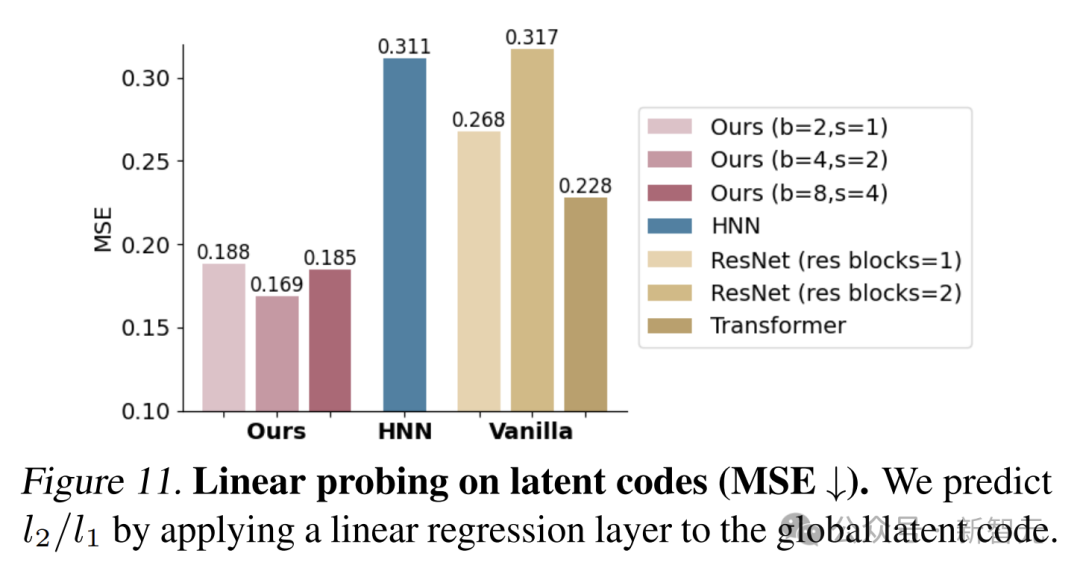
下圖展示了不同塊大小和步長的DHN的結果。對於簡單的雙層Transformer,最佳的塊大小和步長約為
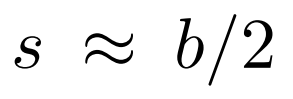
,具有適度的重疊。
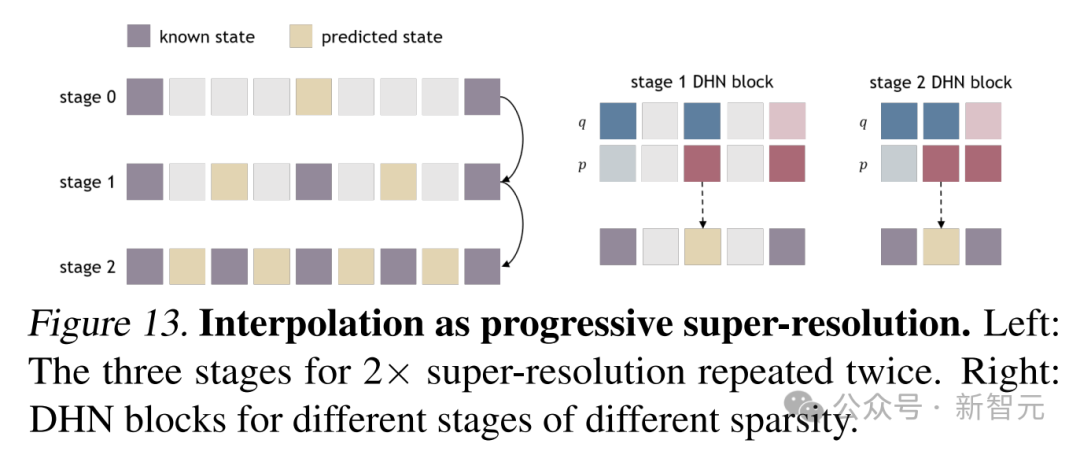
軌跡插值
軌跡插值是DHN展示靈活性的另一個重要任務。DHN用漸進式超解像度技術,通過重覆應用2倍超解像度來實現4倍超解像度。
研究人員構建了塊大小b=2、步長s=1的DHN塊,對不同稀疏度的軌跡進行插值。
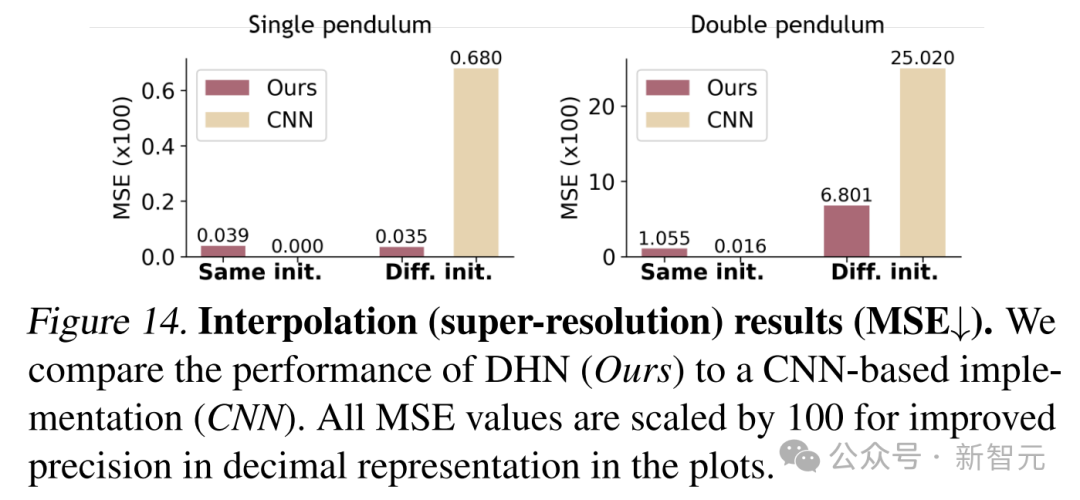
實驗結果表明,在處理與訓練集初始狀態相同的軌跡時,DHN和基於CNN的方法都能取得較好的插值效果。
但在處理具有未見過初始狀態的軌跡時,CNN由於嚴重依賴訓練分佈,難以泛化,而DHN憑藉其受物理約束的表示,能夠推斷出合理的中間狀態,展現出了強大的泛化能力。
儘管DHN在物理推理領域取得了顯著的成果,但它也面臨著一些挑戰。
其中一個主要挑戰是計算成本較高,相比傳統Transformer,DHN需要更密集的梯度計算,這也限制了它的應用範圍。
參考資料:
https://x.com/CongyueD/status/1899296857819697324
https://arxiv.org/abs/2503.07596