逐字生成非最優?試試逐「塊」生成!Block Diffusion打通了自回歸與擴散
機器之心報導
編輯:杜偉、王佳琳
去年初,OpenAI 的影片生成模型 Sora 帶火了擴散模型。
如今,擴散模型被廣泛用於生成圖像和影片,並在生成文本或生物序列等離散數據方面變得越來越有效。從技術上講,與自回歸模型相比,擴散模型具有加速生成和提高模型輸出可控性的潛力。
目前,離散擴散模型目前面臨至少三個限制。首先,在聊天系統等應用中,模型必須生成任意長度的輸出序列(例如對用戶問題的回答)。但是,大多數最新的擴散架構僅能生成固定長度的向量。其次,離散擴散模型在生成過程中使用雙向上下文,因此無法使用 KV 緩存重用以前的計算,這會降低推理效率。第三,以困惑度等標準指標衡量的離散擴散模型,質量落後於自回歸方法,進一步限制了其適用性。
本文中,來自 Cornell Tech、史丹福大學、Cohere 的研究者提出通過塊離散去噪擴散語言模型(Block Discrete Denoising Diffusion Language Models,BD3-LMs)來解決以上限制,該模型在擴散和自回歸模型之間進行插值。
具體來講,塊擴散模型(也是半自回歸模型)定義了離散隨機變量塊的自回歸概率分佈,而給定先前塊的條件概率由離散去噪擴散模型指定。

-
論文標題:Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
-
論文地址:https://arxiv.org/pdf/2503.09573
-
項目主頁:https://m-arriola.com/bd3lms/
下圖為 Block Diffusion 與自回歸、擴散模型的生成效果對比:

研究者表示,開發有效的 BD3-LM 面臨以下兩個挑戰:一是使用神經網絡的一次標準前向傳遞無法有效地計算塊擴散模型的訓練目標,需要開發專門的算法。二是擴散目標梯度的高方差阻礙了訓練,導致 BD3-LM 即使在塊大小為 1 的情況下(當兩個模型等效時)也表現不佳。
因此,研究者推導出梯度方差的估計量,並證明它是自回歸和擴散之間困惑度差距的關鍵因素。然後,他們提出了自定義噪聲過程,以實現最小化梯度方差並進一步縮小困惑度差距。
實驗部分,研究者在多個語言建模基準上評估了 BD3-LM,並證明它們能夠生成任意長度的序列,包括超出其訓練上下文的長度。此外,BD3-LM 在離散擴散模型中實現了新的 SOTA 困惑度。與對嵌入進行高斯擴散的替代半自回歸方法相比,本文離散方法實現了易於處理的似然估計,並在少一個數量級生成步驟的情況下,生成的樣本在困惑度方面得到了改進。
論文一作 Marianne Arriola 發推稱,擴散語言模型在並行文本生成領域正在崛起,但與自回歸模型相比,它們存在質量、固定長度限制和缺乏 KV 緩存等問題。本文 Block Diffusion 將自回歸和擴散模型結合了起來,實現了兩全其美。

BD3-LMs 模型概覽
研究者結合建模範式,從自回歸模型中獲得更好的似然估計和靈活的長度生成,並從擴散模型中獲得了快速的並行生成效果。
塊擴散似然
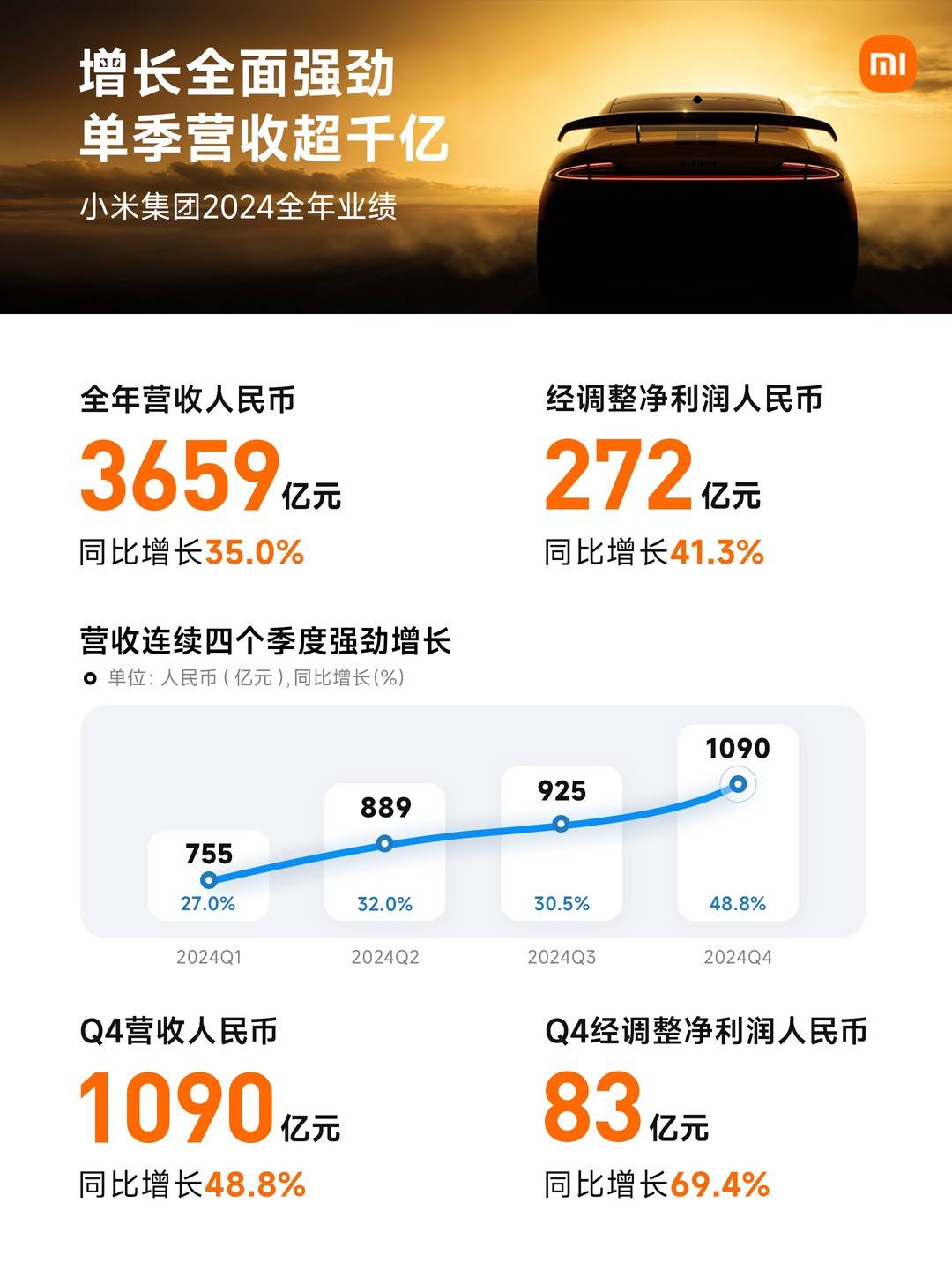
研究者提出了一個建模框架,該框架對 token 塊進行自回歸建模,並在每個塊內執行擴散操作。他們對長度為 L′ 的 B 個塊進行似然分解,如下所示:
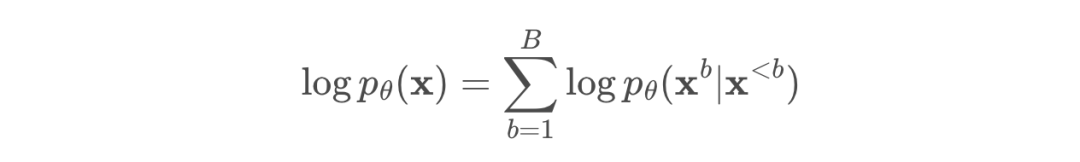
每個 pθ(x^b|x^
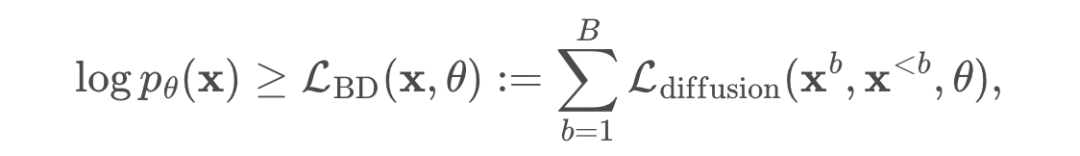
研究者使用簡單的離散擴散參數化對每個塊的似然進行建模,最終目標是對交叉熵項進行加權總和:
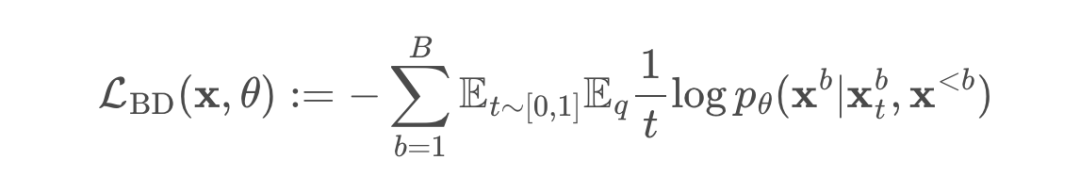
高效的訓練與采樣算法
簡單來說,研究者想要通過在一個 loop 中應用
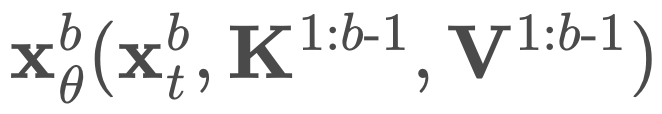
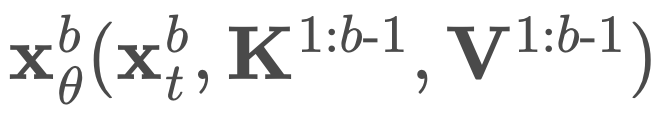
同時計算所有塊的去噪預測。
B 次來計算 logits。不過,他們只需要兩次前向傳遞。第一次傳遞分別預計算完整序列 x 的鍵和值 K^1:B、V^1:B,在第二次前向傳遞中使用
為了從 BD3-LM 中采樣,研究者以先前采樣的塊為條件,一次生成一個塊。生成塊後,他們緩存其鍵和值,類似於 AR。同時在每個塊的 T 個采樣步下,使用任何擴散采樣流程 SAMPLE
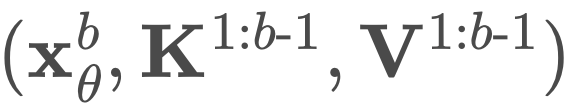
中進行采樣。來從條件分佈 pθ
算法 1(塊擴散訓練)和算法 2(塊擴散采樣)分別如下圖(左)和(右)所示。

BD3-LM 訓練和采樣算法。
理解擴散模型與自回歸模型之間的似然差距
案例研究:單 Token 生成
該研究中的塊擴散參數化在期望上等同於自回歸負對數似然 (NLL),特別是在 L′=1 的極限情況下。令人驚訝的是,當在 LM1B 數據集上訓練兩種模型時,研究發現塊擴散模型 (L′=1) 與自回歸模型之間存在兩點困惑度差距。研究確定擴散目標的高訓練方差是導致這一困惑度差距的原因。
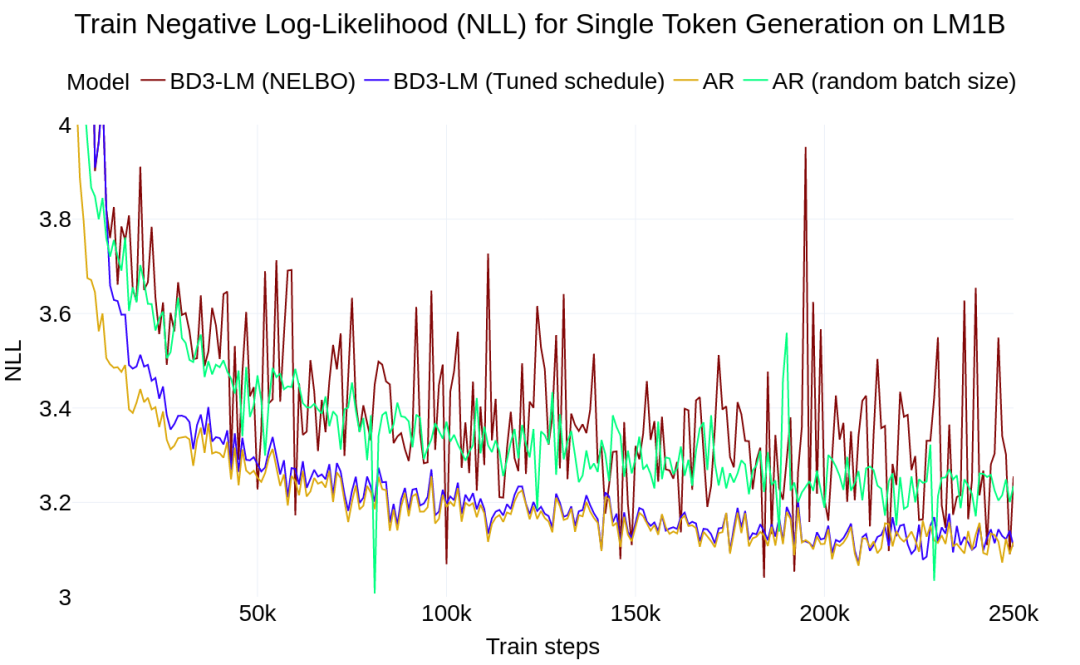
在離散擴散 ELBO 下進行訓練時,存在高方差。
高方差訓練導致的擴散差距
直觀來說,如果采樣的掩碼率
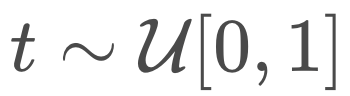
過低,重構 x 會變得容易,這不能提供有用的學習信號。如果掩碼全部內容,最優的重構就是數據分佈中每個標記的邊際概率,這很容易學習,同樣也沒有用處。
研究需要找到能夠最小化擴散目標引起的訓練方差,並進一步減少困惑度差距的噪聲調度方案。
基於數據的低方差訓練噪聲調度
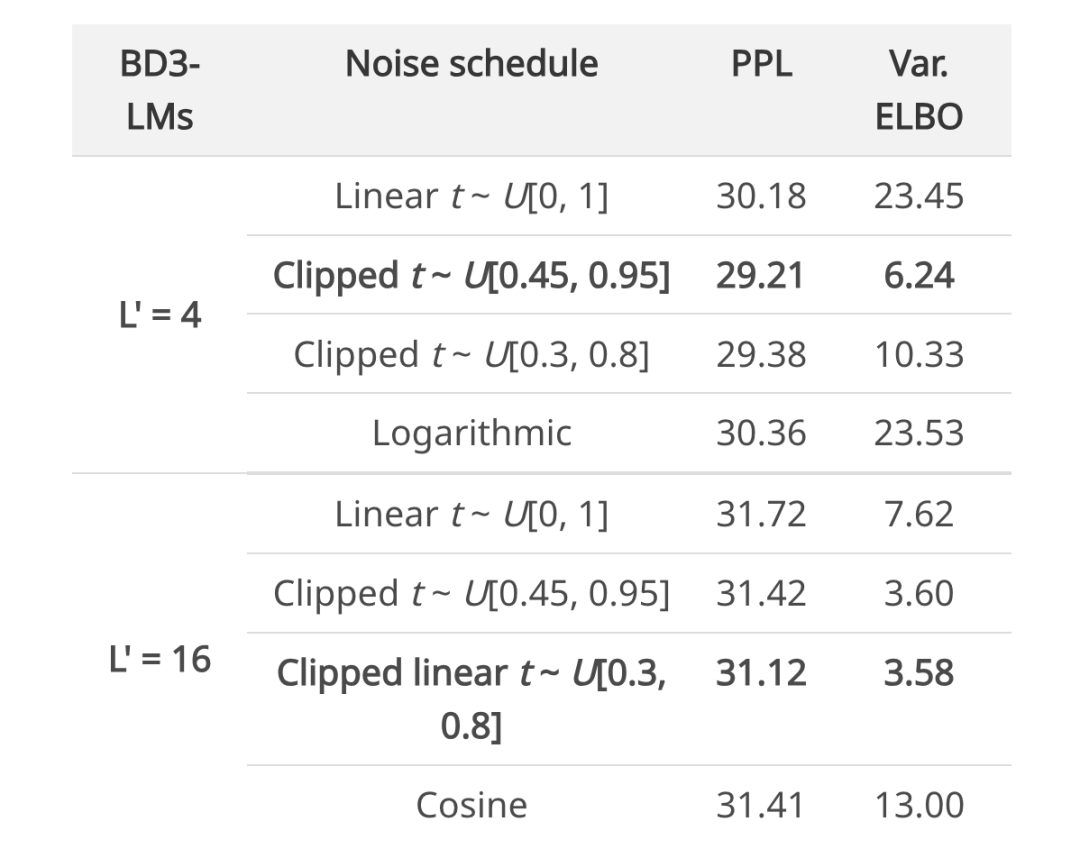
為了避免導致高方差訓練的掩碼率,研究者在「裁剪的』掩碼率下來訓練 BD3-LMs。通過降低訓練方差,研究者在均勻采樣的掩碼率評估下改善了似然度。
由於最佳掩碼率可能會根據塊大小 L′的不同而變化,他們在訓練期間自適應地學習 β,ω。在實踐中,研究者在每個驗證步驟後(經過 5K 次梯度更新)使用網格搜索來優化
在下文中,研究者展示了針對每個塊大小優化噪聲調度可以減少損失估計器的方差,並與其他替代調度方案相比實現最佳困惑度。
實驗結果
似然評估
BD3-LMs 在擴散模型中實現了最先進的似然水平。研究表明,通過調整塊長度 L′,BD3-LMs 可以在擴散和自回歸似然之間實現插值。
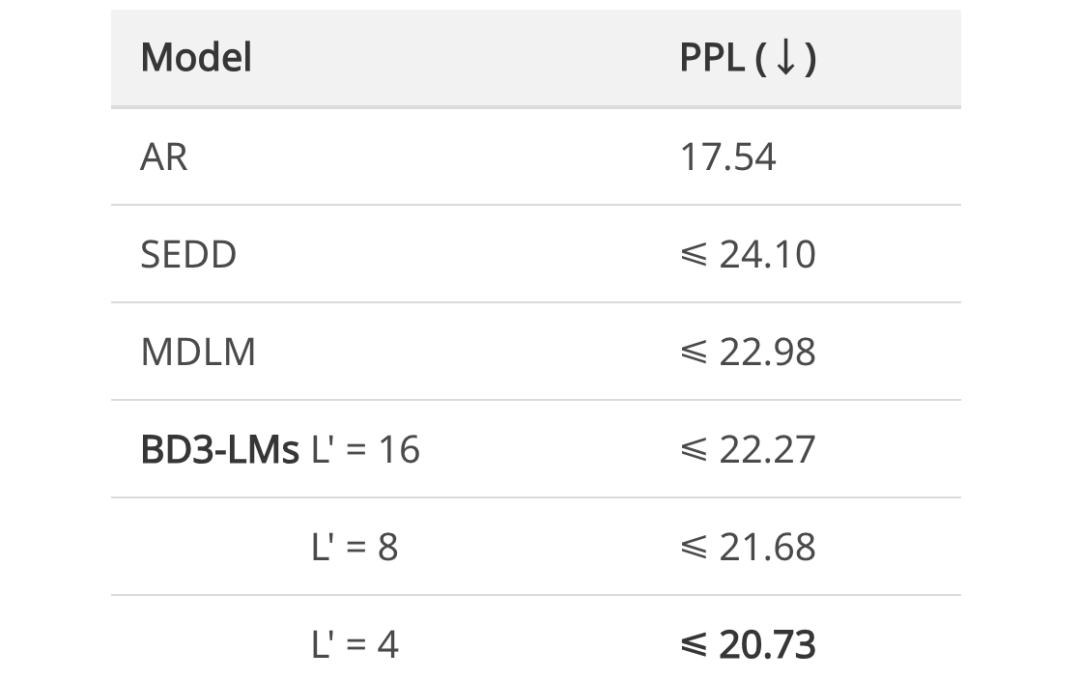
在 OWT 上測試針對 262B 標記訓練的模型的困惑度 (PPL; ↓)。
任意長度序列生成
許多現有擴散語言模型的一個主要缺點是,它們無法生成超過訓練時選擇的輸出上下文長度的完整文檔。例如,OpenWebText 包含最長達 131K tokens 的文檔,而離散擴散模型 SEDD(Lou 等人)僅限於生成 1024 tokens。研究表明,BD3-LMs 能夠通過解碼任意數量的塊來生成可變長度的文檔。
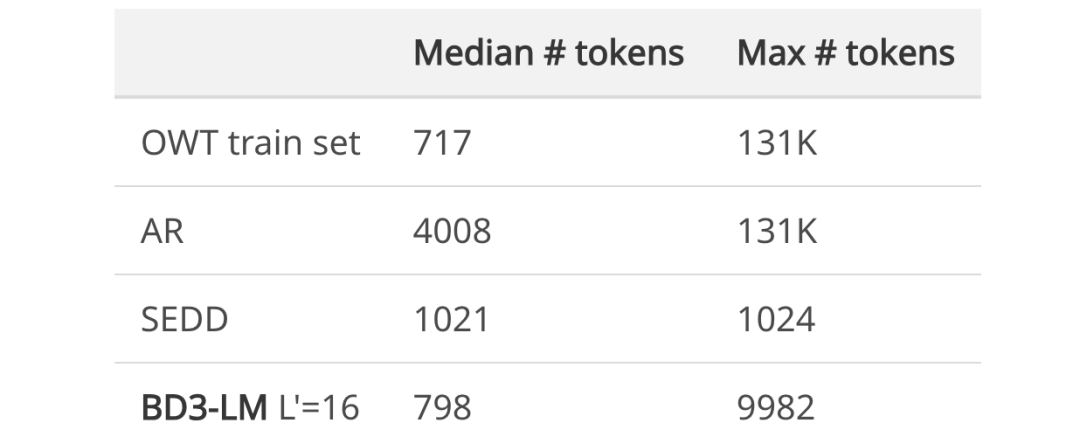
從在 OWT 上訓練的模型中抽樣 500 個文檔得出的生成長度統計信息。
研究者評估了 BD3-LMs 在變長序列上的生成質量,使用相同數量的生成步驟(NFEs)比較了所有方法。他們用 GPT2-Large 模型測量生成序列的困惑度。結果表明,與之前所有的擴散方法相比,BD3-LMs 實現了最佳的生成困惑度。
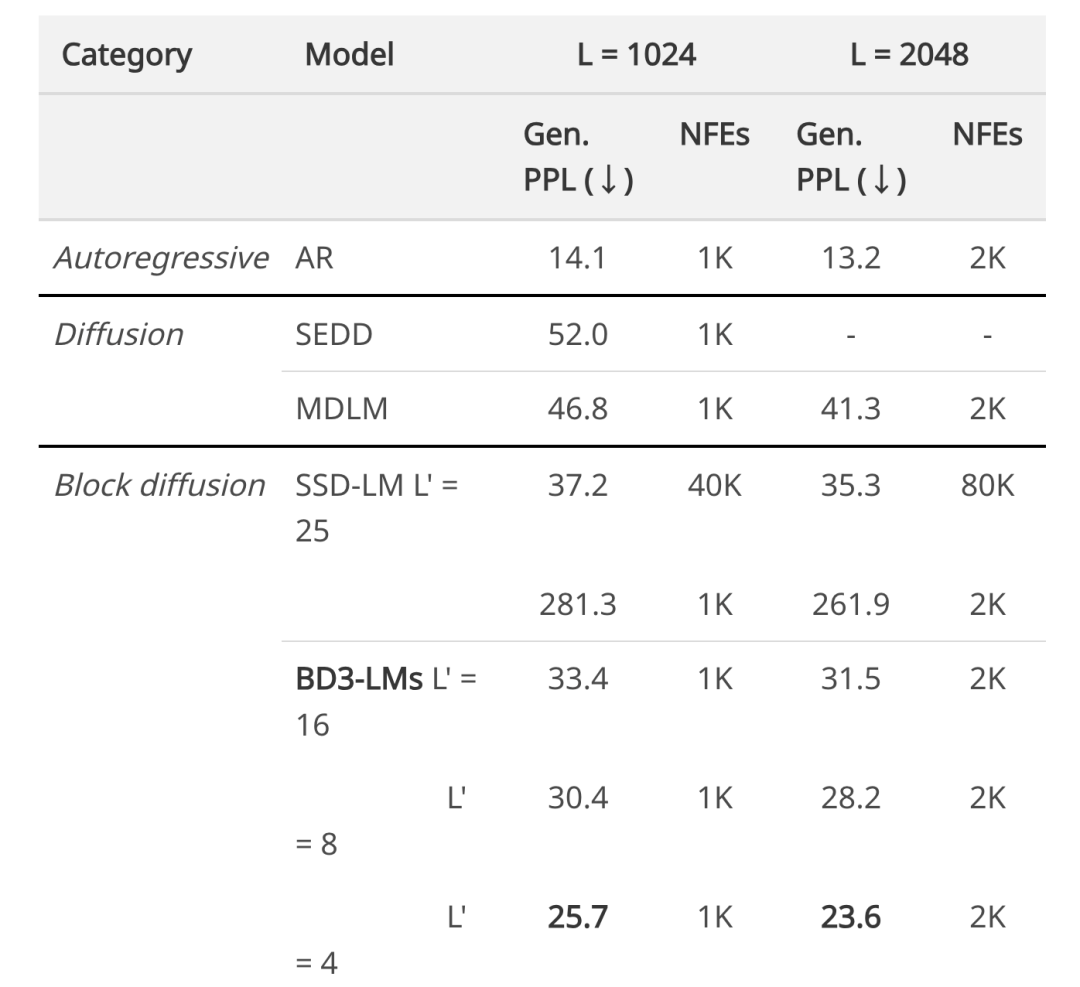
300 個可變長度樣本的生成困惑度 (Gen. PPL;↓) 和功能評估次數 (NFE;↓)。所有模型都在 OWT 上進行訓練,上下文長度為 L = 1024,並使用核采樣。
對於 MDLM,研究者使用了其分塊解碼技術(該技術不同於 BD3-LMs 中的分塊擴散訓練)處理 L=2048 的序列。研究者還與 SSD-LM(Han 等人提出)進行了比較,後者是一種替代性的分塊自回歸方法(也稱為半自回歸),它對詞嵌入執行高斯擴散,但無法進行似然估計。該研究的離散方法使用比其他方法少一個數量級的生成步驟,產生了具有更好生成困惑度的樣本。
更多細節請參閱原論文。