【深度】從Manus到MCP:25年AI的三大新趨勢
文 | AlphaEngineer,作者 | 費斌傑(北京市青聯委員 熵簡科技CEO)
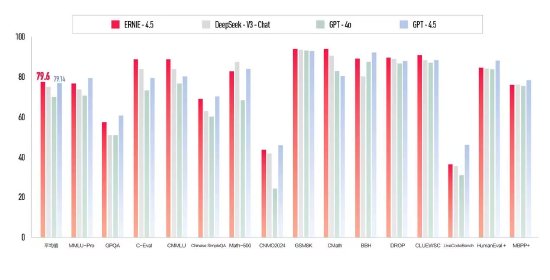
25年開年以來,AI發展如火如荼,DeepSeek R1、OpenAI CUA、Manus等重要創新層出不窮,眼花繚亂。
這裏我將最近一個月以來的思考總結一下,對25年AI發展趨勢做幾點預判。
(1)Manus:Agent元年的一次搶跑
Manus推出之後,我們第一時間拿到了體驗帳號,進行了充分的體驗測評。
先說結論:雖然Manus目前還有種種不足,但它的產品設計思路創意滿滿,值得我們給予充分的肯定。
Manus的核心架構基於「虛擬機+多Agent協同」模式,通過整合多個底層大模型(如GPT-4、Claude 3等)的API,實現任務的動態分配與模型調用。
Manus突破了傳統AI助手僅生成建議的局限,實現了從「需求輸入」到「成果交付」的端到端閉環。
Manus提出「Less Structure, More Intelligence」的交互理念,通過無代碼化的自然語言接口降低用戶使用門檻。

與此同時,Manus使用一個外置的markdown文件來管理Agent的任務規劃,並且將階段性的工作成果存儲為獨立文件,這也是一個非常有趣的創新點。
(2)Manus的不足與缺陷
Manus在MultiAgent的道路上提供了一種非常有趣的思路,但現在依然存在一些顯而易見的不足之處。
首先是「幻覺累加」的問題。
Agent的本質是多次大模型問答的串並聯。如果單次大模型問答的準確率是90%,串聯10次的話,最終Agent回答準確的概率是0.9^10,只有1/3左右了。
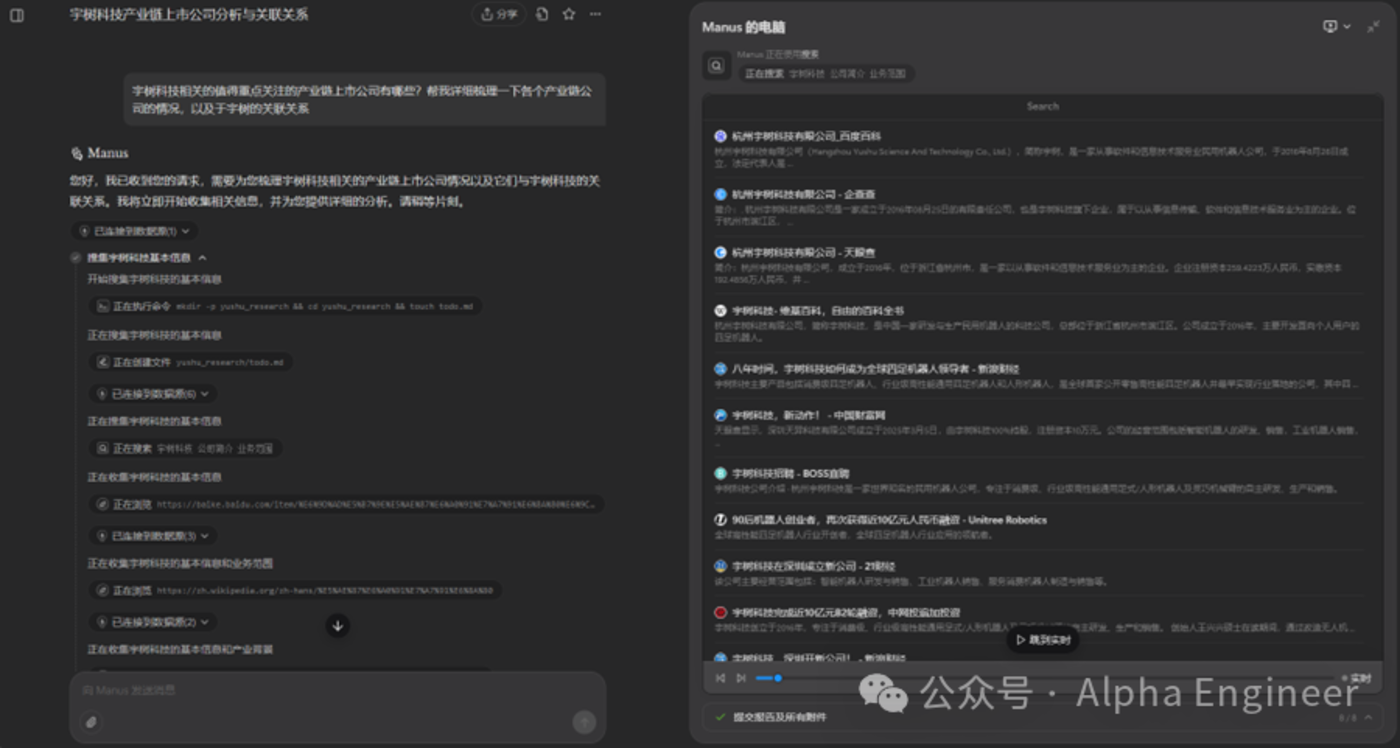
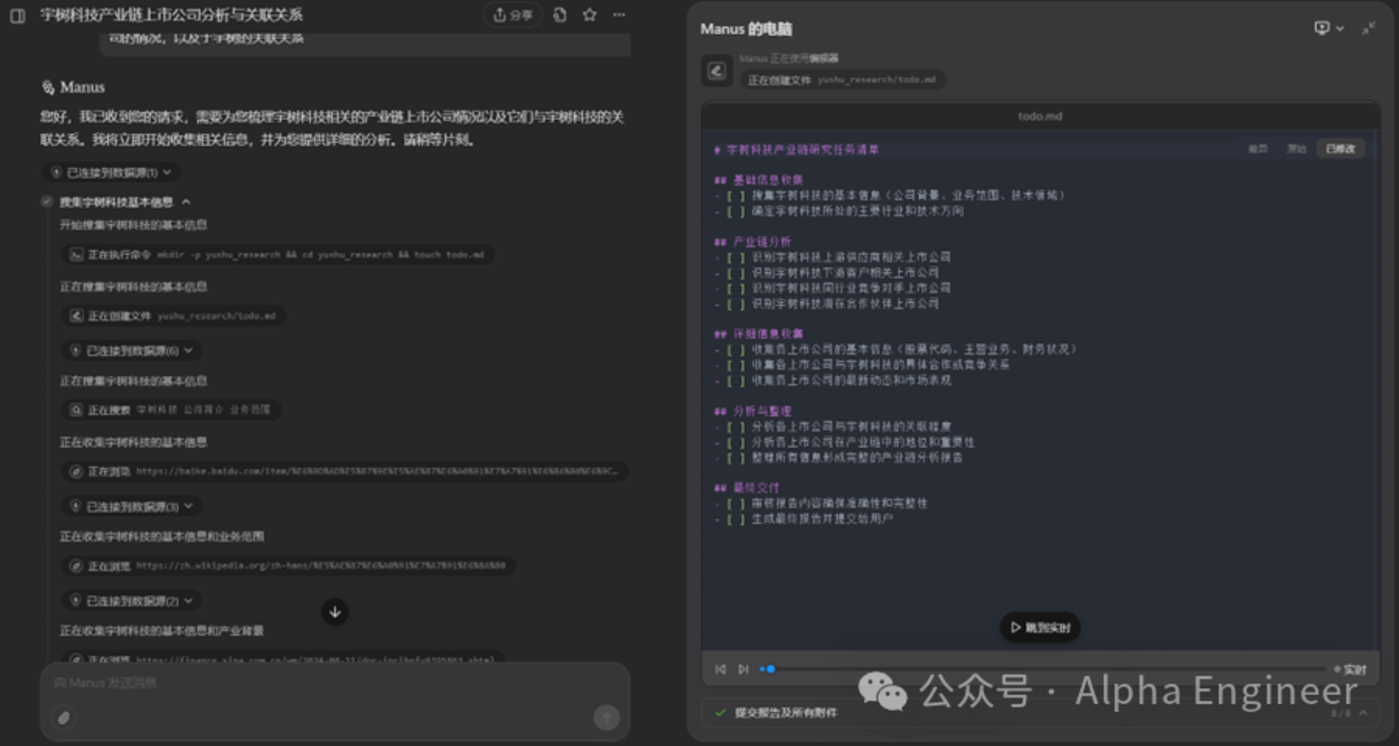
在下面的案例中,Manus的任務是針對某上市公司進行財務數據分析。Manus很聰明的import了data_api模塊,準備從雅虎提供的接口中調取財務數據。
但是在process_financial_data函數中,manus竟然把revenue、gross_profit等數據直接「硬編碼」到了代碼中,讓人猝不及防。而且經過驗證,這裏的數據有部分是錯誤的。
如果原始數據出錯了,那麼後續無論分析得多麼深入、圖表做得多麼fancy都失去了意義。

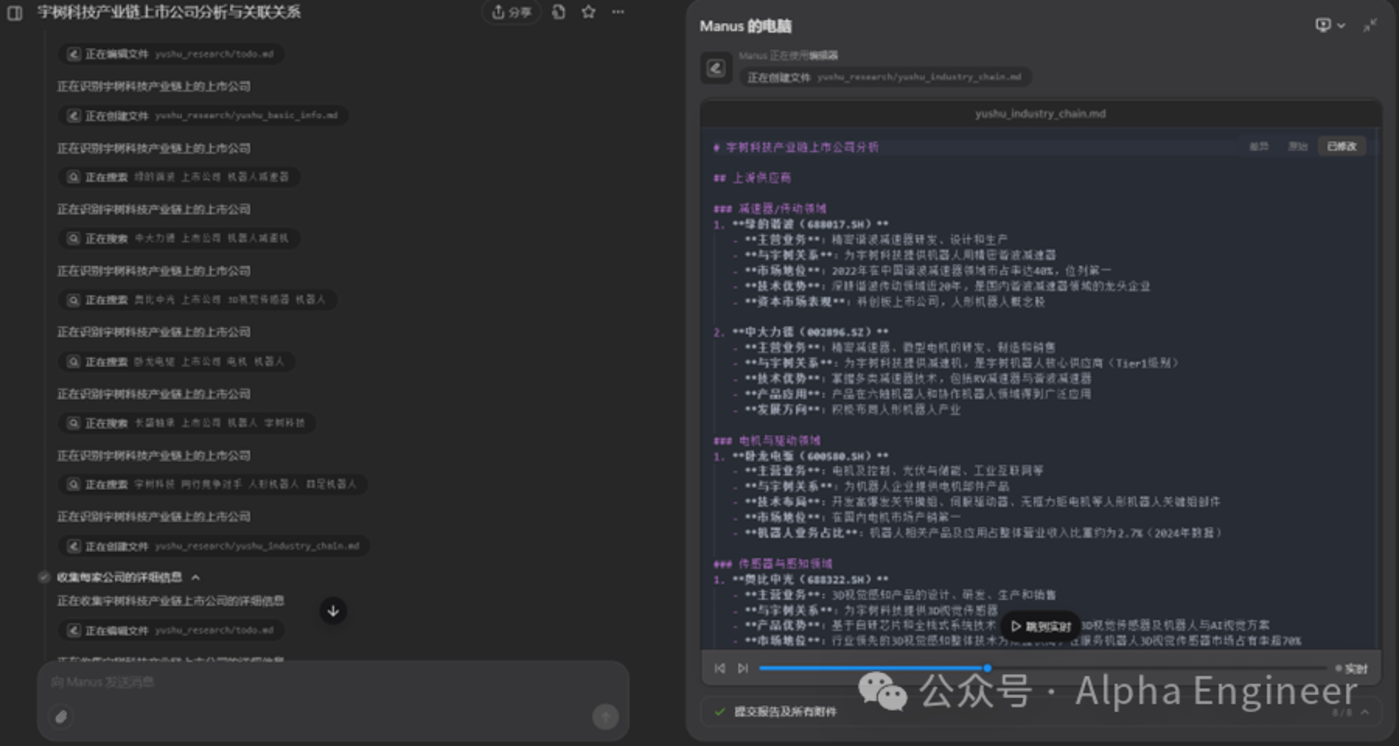
Manus的第二個問題是可供大模型調用的工具不足。
下面這個例子中,Manus的任務是寫一篇關於「小米Su7」的市場分析報告PPT。
Manus完美的拆分了任務,並且檢索了大量新聞,但是最後它無法生成一份PPT,因為它無法調用Office軟件。
目前Manus輸出的內容形式多為純文本或者網頁,還無法和人類工作流進行完美融合。
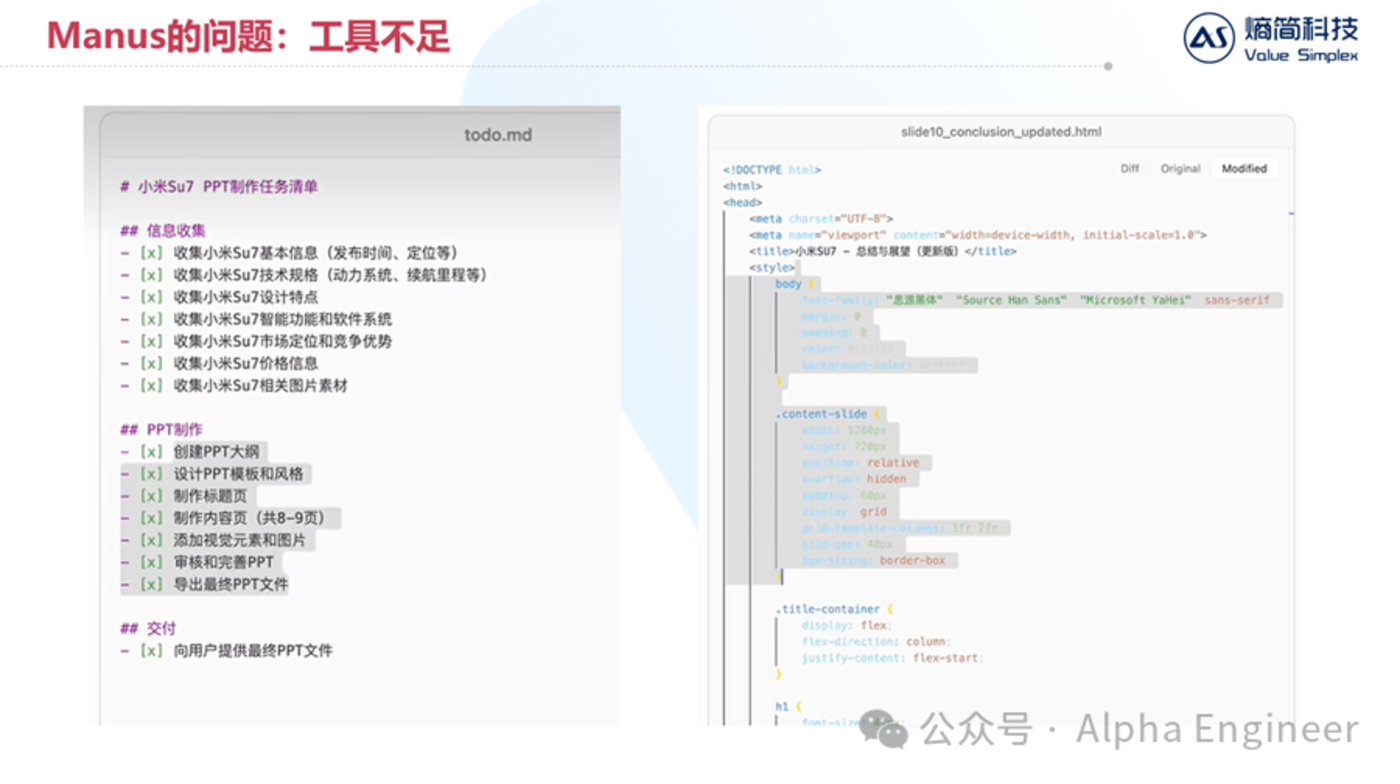
Manus遇到的第三個挑戰是小院高牆的互聯網生態。
互聯網上有很多優質信息是存放在「圍欄」中的。
比如當我們讓Manus去分析比較市面上所有AI智能眼鏡的性價比時,它聰明的找到了對應商品的淘寶網頁。
但是當Manus想要打開具體產品頁面獲取價格性能等詳細信息時,淘寶判定它為機器人,並拒絕了Manus的訪問。
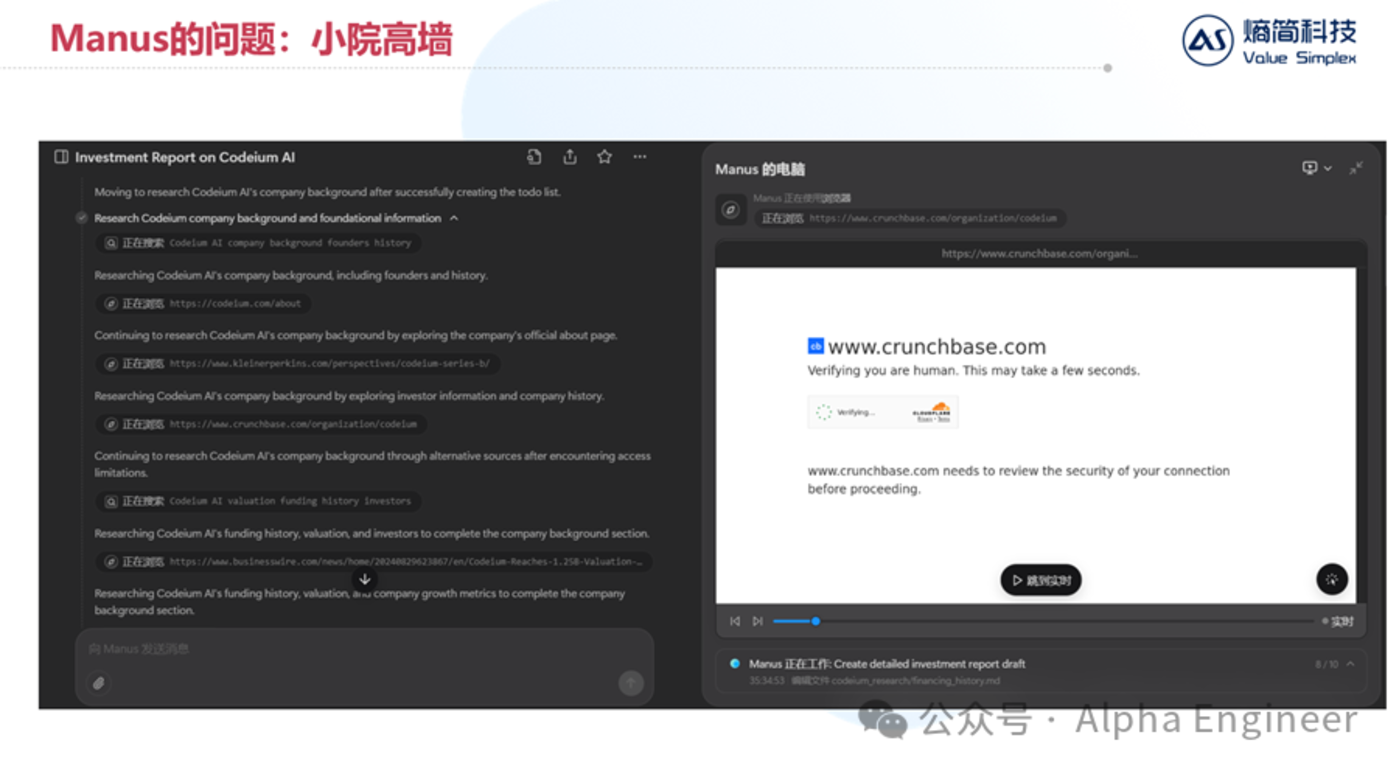
無獨有偶,當我們讓Manus為一家非上市公司進行出具商業分析報告時,Manus為了獲取公司的最新融資進展,訪問了CrunchBase數據庫。
但是Manus的訪問被CrunchBase判定為機器人,隨後被無情的拒絕了。
互聯網看似公開透明,實則存在大量類似小院高牆的情況,優質信息往往就存放在這些高牆之內,Manus無法直接獲取,這無疑阻礙了Manus的工作效果。
儘管有著種種問題和挑戰,Manus依然給大家描繪了MultiAgent的巨大前景,打響了Agent元年的第一槍,值得我們給予充分的肯定。
在Manus佔據大家視野的同時,海外AI大廠究竟做了哪些技術儲備呢?
(3)OpenAI CUA:一個會自主操作電腦的Agent
在今年的1月底,OpenAI發佈了由其新模型CUA(Computer-Using Agent)驅動的AI智能體Operator。
CUA模型融合了GPT-4o的視覺能力和通過強化學習實現的高級推理能力,能夠將任務分解為多步驟計劃,並在遇到挑戰時進行在我調整和糾正。
簡而言之,CUA就是一個會操作電腦的Agent,它的運作原理非常直白且簡潔,如下圖所示。
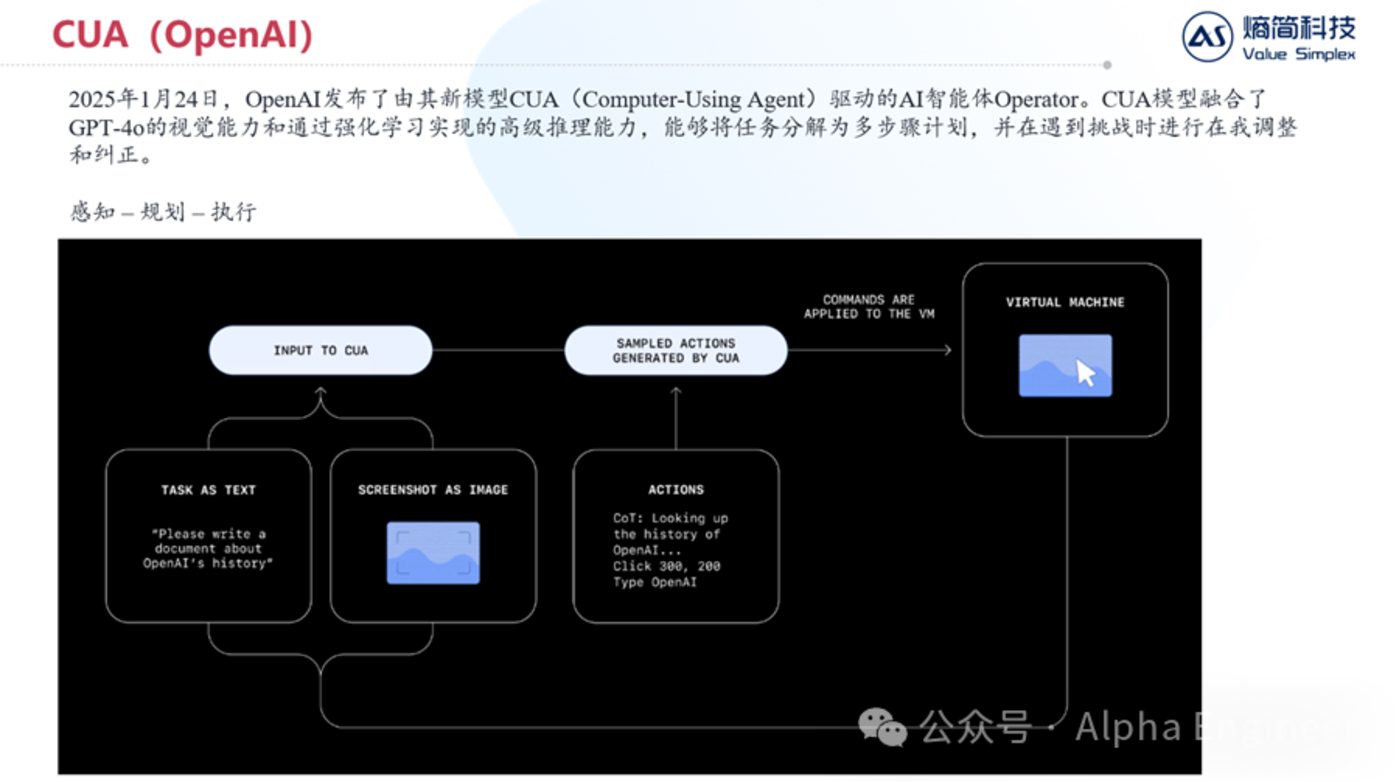 首先,CUA會同時接受兩種模態的輸入:其一是文本指令,其二是屏幕截圖。
首先,CUA會同時接受兩種模態的輸入:其一是文本指令,其二是屏幕截圖。CUA會同時處理這兩種信息,並且生成一系列動作指令,比如「點擊屏幕上坐標為(300,200)的點,並且輸入XXX,按回車」。
電腦接受到指令並完成操作後,會將新的屏幕截圖與新的任務指令返回給CUA,如此循環往複,直到獲得最終答案。
那麼CUA目前操作電腦的能力達到了怎樣的水平呢?
根據OpenAI的官方測評,CUA在操作電腦和操作瀏覽器這兩個場景上,相比上一代SOTA都有了巨大的性能提升。
但是相比人類而言,依然有著較大的差距。換句話來說,目前頂級的Agent依然沒有辦法像一個成年人一樣正確的操作電腦,但我相信這個現狀在今年內就會發生質變。

(4)Anthropic MCP:AI時代下的TCP/IP協議
剛才在分析Manus的缺陷時,提到了「工具不足」的問題。
Anthropic顯然也意識到了這個問題,並在去年年底推出了MCP來從根源上解決這個問題。
MCP的全稱是Model Context Protocol,它定義了應用程序和AI模型之間交換上下文信息的方式,這使得開發者能夠以一致的方式將各種數據源、工具和功能連接到 AI 模型。
MCP之於AI,有點類似於TCP/IP之於互聯網。
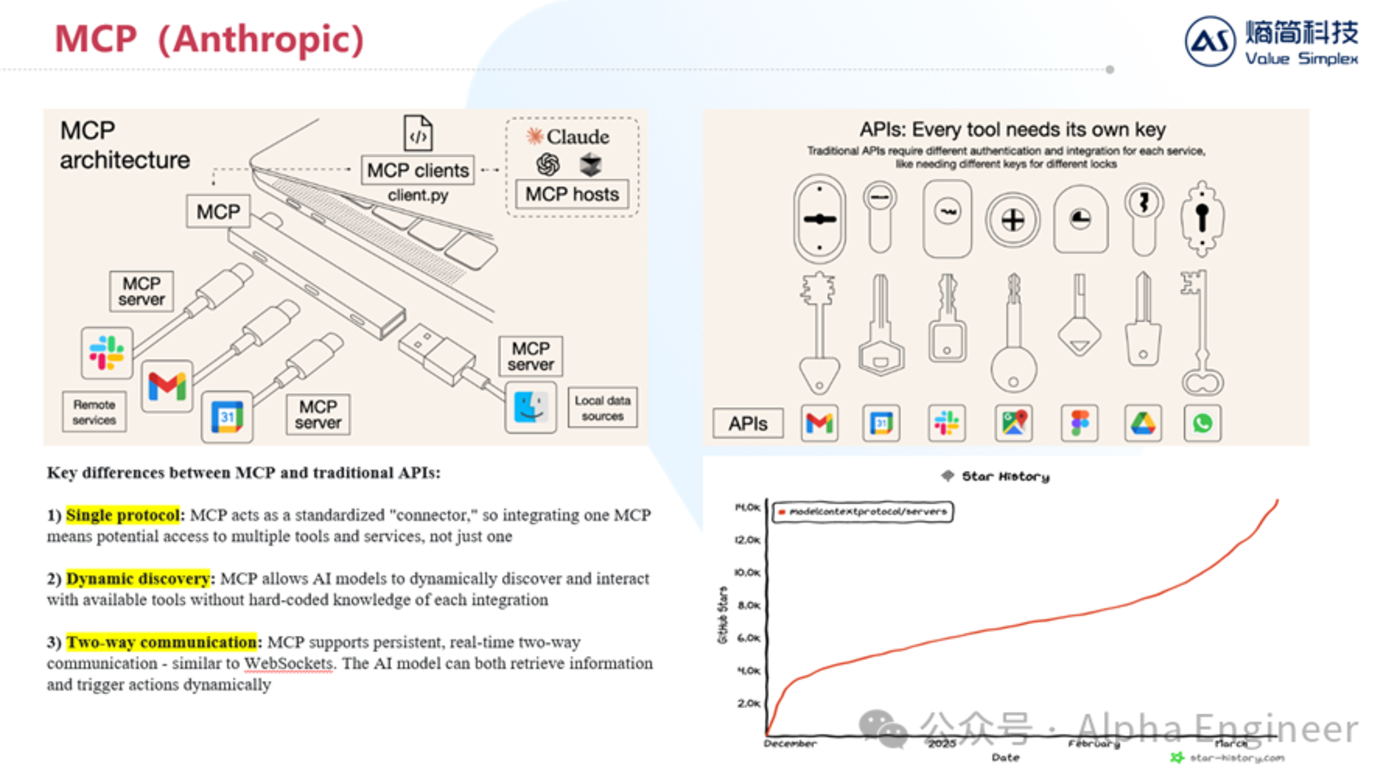
MCP有三個重要特點:
當前越來越多的工具及服務開始接入MCP,呈現愈演愈烈之勢,包括Google Maps、PGSQL、ClickHouse(OLAP數據庫)、Atlassian、Stripe等等。
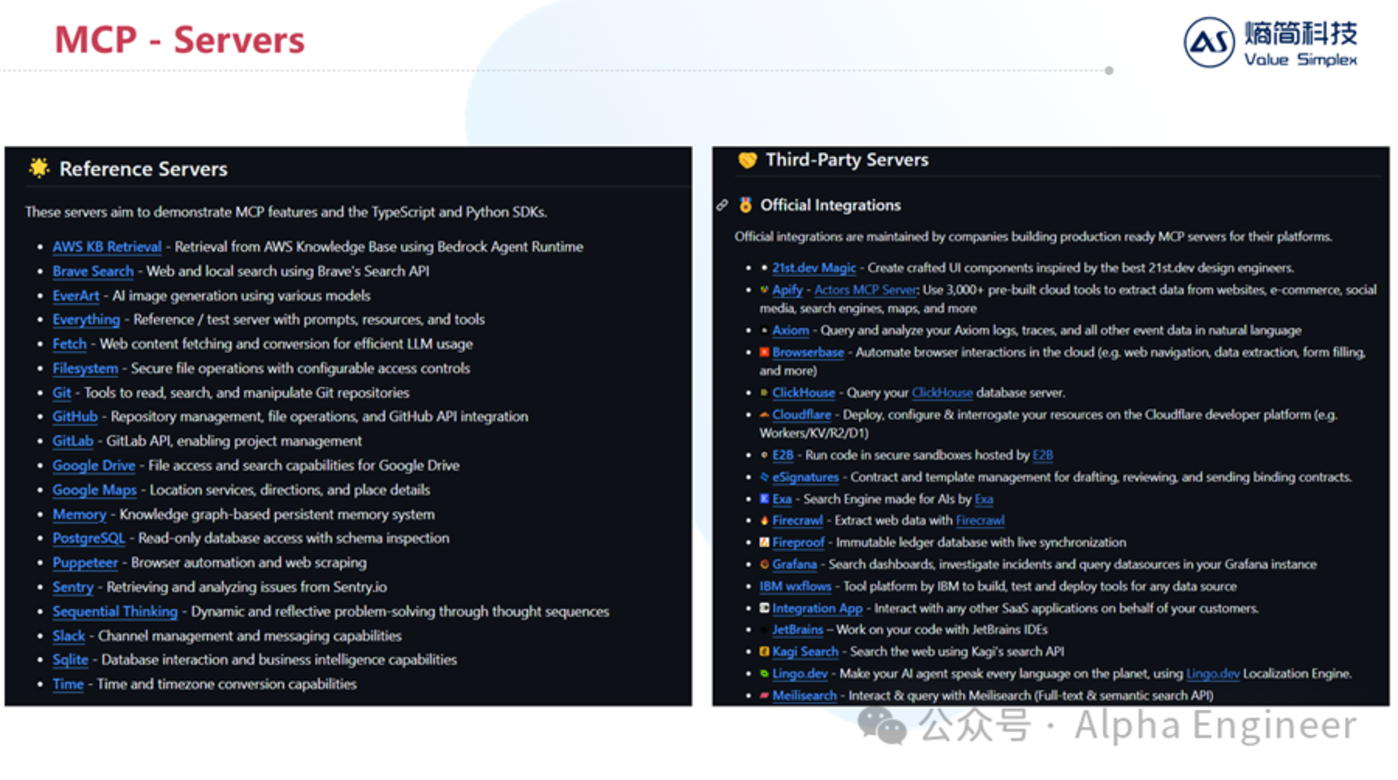

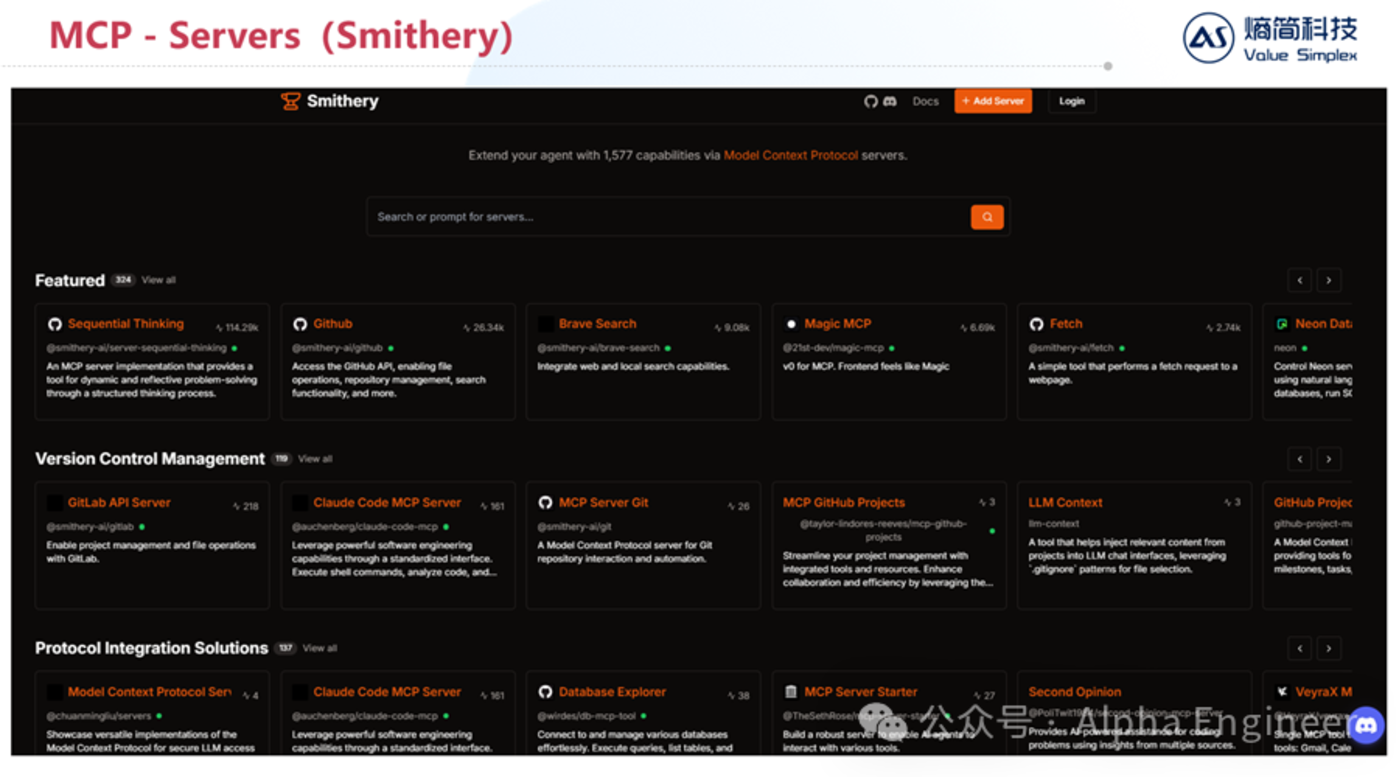
在Smithery平台上你可以輕鬆查找不同功能對應的工具及服務。隨著越來越多的Server接入MCP協議,未來AI能夠直接調用的工具將呈現指數級增長,這能從根源上打開Agent能力的天花板。
(5)2025年AI發展新趨勢:後訓練、RL、MultiAgent
這裏我結合最近幾個月以來的觀察和思考,總結一下25年AI發展的幾點重要趨勢。
第一,預訓練即將終結,後訓練成為重點。
這其實已經是行業共識。去年年底時,Ilya在NeurIPS大會上提到一個重要觀點:數據是AI時代的化石燃料,因為我們人類只有一個互聯網。
與此同時,在今年DeepSeek R1的論文中,提到了後訓練將成為大模型訓練管線中的重要組成部分。

第二,針對後訓練而言,強化學習將成為主流,監督學習的重要性逐漸下降。
DeepSeek R1帶來最重要的啟發是:純粹的RL可能是通向AGI的正確路徑。
隨著湯臣S的增加,大模型會自我湧現出複雜的推理行為,而無需刻意引導。
如下邊右圖所示,橫軸是大模型RL的迭代步數,縱軸是單次問答的token長度。我們可以看到,隨著大模型RL步數的增加,大模型會自主的從「快思考」變成「慢思考」,從最開始每次回答100個token,到最後每次回答接近10000個token。
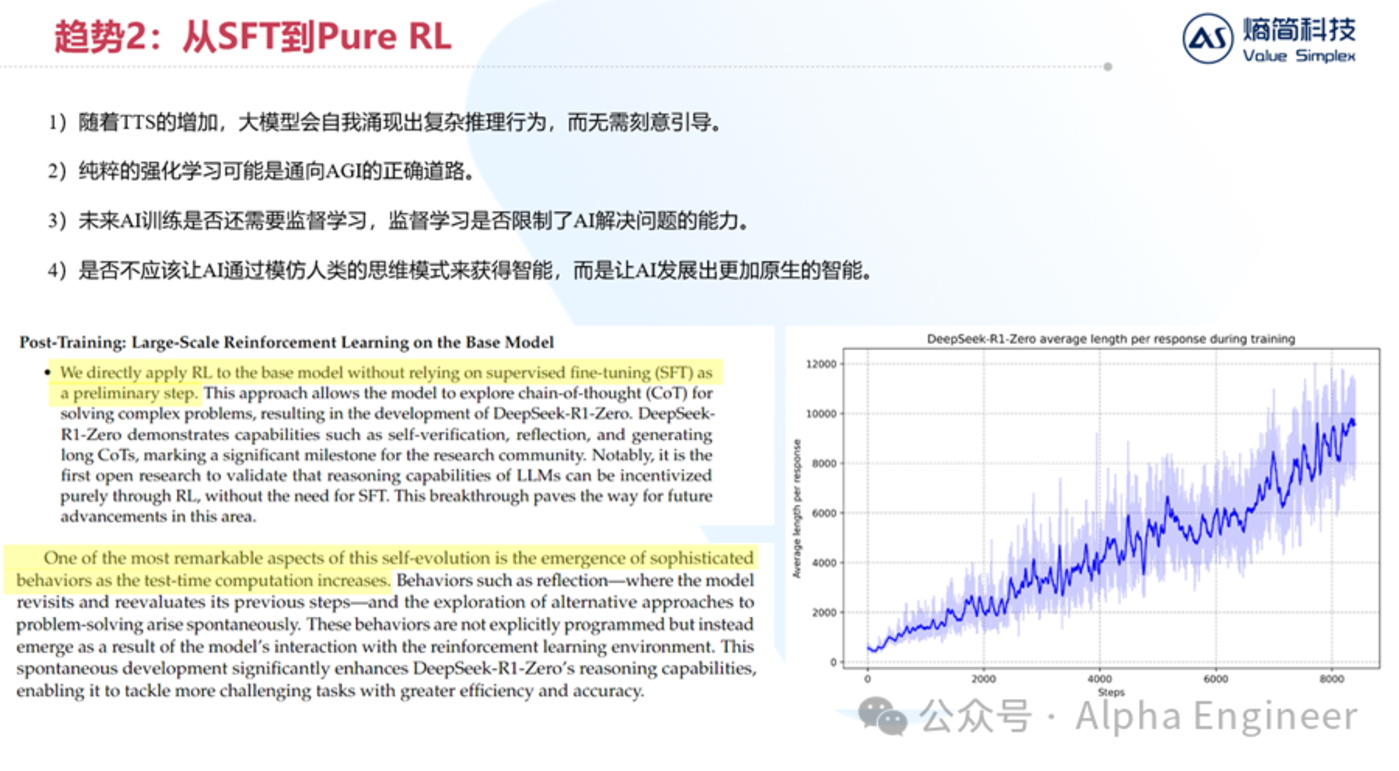
DeepSeek團隊將這種現象稱為「self-evolution」,並認為它是「the emergence of sophisticated behaviors」。
具體是哪些複雜行為的湧現呢?DeepSeek也給出了答案,比如:self-verfication, reflection等。
這個發現對於我們來說有著重要的啟發。未來監督學習在AI訓練中究竟應該扮演怎樣的角色?監督學習是否反而限制了AI解決問題的能力?
是否不應該讓AI通過模仿人類的思維方式來獲得智能,而是讓AI發展出更加原生的智能?
這些問題,都有待整個AI行業通過實踐來給出答案。
第三,MutiAgent是確定性的大趨勢。
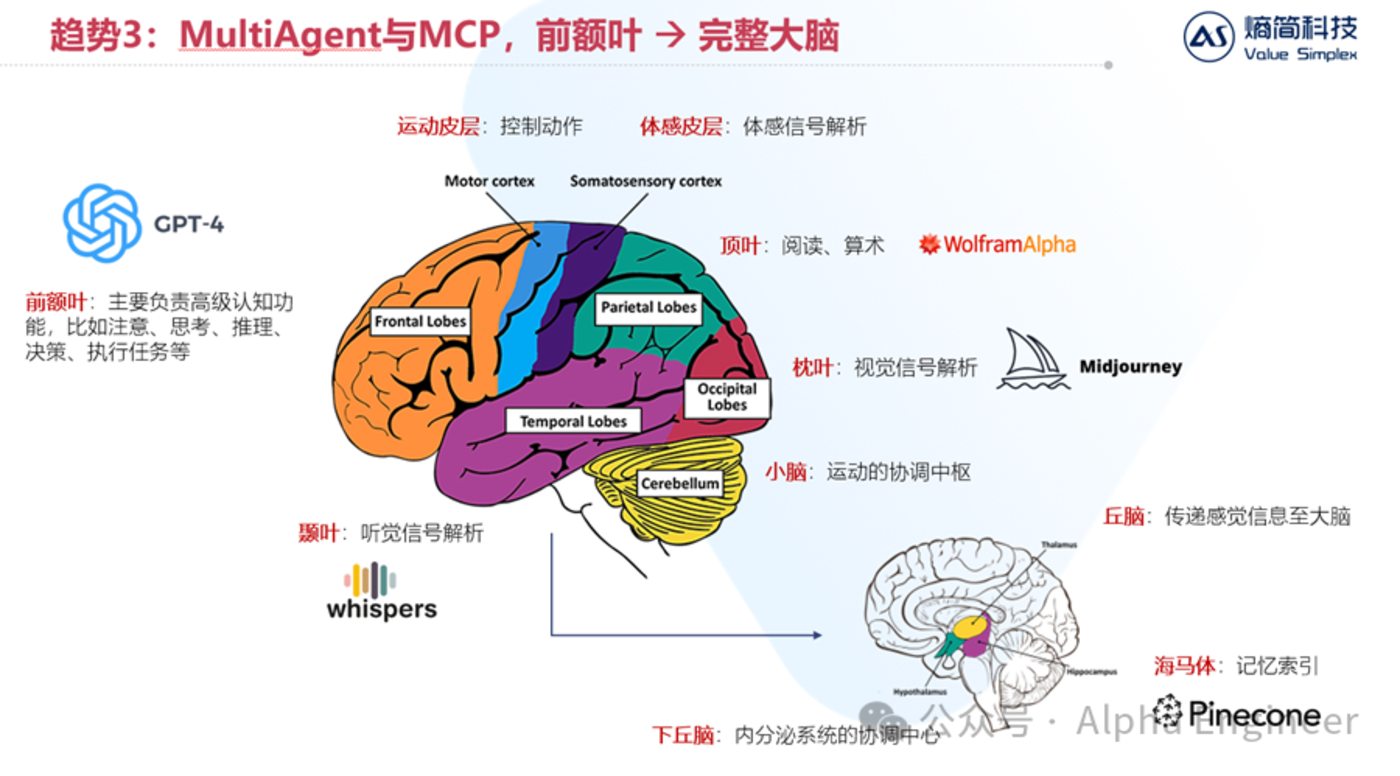
如果將AI和人腦進行類比的話,大模型就像是人腦中的「前額葉」。
眾所周知,前額葉主要負責高級認知功能,比如注意力的分配、思考推理、決策等。
但是僅僅有前額葉,大腦是無法處理複雜任務的。我們需要有顳葉來進行聽覺信號的解析,需要頂葉進行閱讀和算術,需要小腦來進行運動協調,需要海馬體來進行記憶索引。
MultiAgent的定義恰恰就是讓多個不同的模型之間互相協調,從單獨的「前額葉」走向「完整的大腦」,從而處理更加複雜的現實任務。
在這個藍圖中,MCP就起到了非常重要的作用:協調統一大模型與各工具之間的數據通信接口。
(6)結語:抓好扶手,未來已來!
2025年是AI Agent元年,Manus的出現打響了第一炮。
無論是OpenAI的CUA還是Anthropic的MCP都指向了一個共同的未來,未來2年AI的發展速度將非常陡峭。
抓好扶手,未來已來!