Google重磅推出全新Scaling Law,搶救Transformer!3萬億美元AI面臨岔路

新智元報導
編輯:編輯部 NJY
【新智元導讀】Google團隊發現了全新Scaling Law!新方法DiLoCo被證明更好、更快、更強,可在多個數據中心訓練越來越大的LLM。
測試時計算之後,Google三大團隊集眾人之力,發現了全新的Scaling Law!
剛剛,Google研究員Zachary Charles宣佈:「在越來越大的模型上,分佈式訓練取得重大突破」。
這個核心算法,便是——DiLoCo的Scaling Law。
新的訓練方法無懼模型規模,未來,在「多個數據中心」訓練大模型的規模不再是問題。

論文得出四大發現,DiLoCo訓練方法的Scaling law,效果遠超「數據並行」:
更穩健(Harder):在不同模型規模下,DiLoCo的超參數依然保持穩定且可預測。
更優越(Better):隨著模型規模擴大,DiLoCo相較於數據並行訓練的優勢進一步提升。
更高效(Faster):DiLoCo所需的帶寬比數據並行訓練少幾個數量級。
更強大(Stronger):DiLoCo能夠容忍比數據並行訓練大得多的批大小。

值得一提的是,這篇巨作集結了Google三大團隊:GoogleResearch、GoogleSearch、GoogleDeepMind。
 論文地址:https://arxiv.org/pdf/2503.09799
論文地址:https://arxiv.org/pdf/2503.09799在固定計算預算下,研究人員探討了DiLoCo在訓練大模型時的Scaling law。
論文中,重點分析了算法因素(如模型副本數量、超參數設置、token預算)如何影響訓練過程,並證明這些影響可通過Scaling law準確預測。
結果表明,DiLoCo在模型規模增長時,表現出穩定且可預測的擴展性。論文合著者Arthur Douillard再次強調:DiLoCo生效了!

 智能的未來將是分佈式的,而DiLoCo可能正是那個關鍵的要素
智能的未來將是分佈式的,而DiLoCo可能正是那個關鍵的要素在合理調優的情況下,DiLoCo比數據並行訓練更具擴展優勢,即使在小規模模型上也可能優於數據並行訓練。
這些發現,揭示了DiLoCo的強大優勢:不僅解決了通信瓶頸,還為大規模模型訓練開闢了全新的可能。
有網民驚歎地表示,「DiLoCo可能會重新定義LLM Scaling的方式!更少的帶寬需求,更高的效率」。


左右滑動查看
「數據並行」訓練終結?
數據並行訓練在大模型上表現出色,前提是在計算資源集中分散的情況下,才能實現。
如果計算分佈較廣,通信就可能成為巨大的瓶頸,尤其是當模型規模增長時,問題會更加嚴重!
機器學習採用的解決方案,例如在聯邦學習和數據中心訓練中,就是讓多個獨立模型進行訓練,並定期同步。
隨著機器學習模型規模的擴大,數據並行方法固有的頻繁同步需求會導致顯著的性能下降,這對進一步擴展模型構成了關鍵挑戰。
那麼,如何在保持模型質量的同時,降低同步需求,以突破這一瓶頸呢?
答案或許就在,DiLoCo(Distributed Low-Communication)這一創新方法中。
 論文鏈接:https://arxiv.org/abs/2311.08105
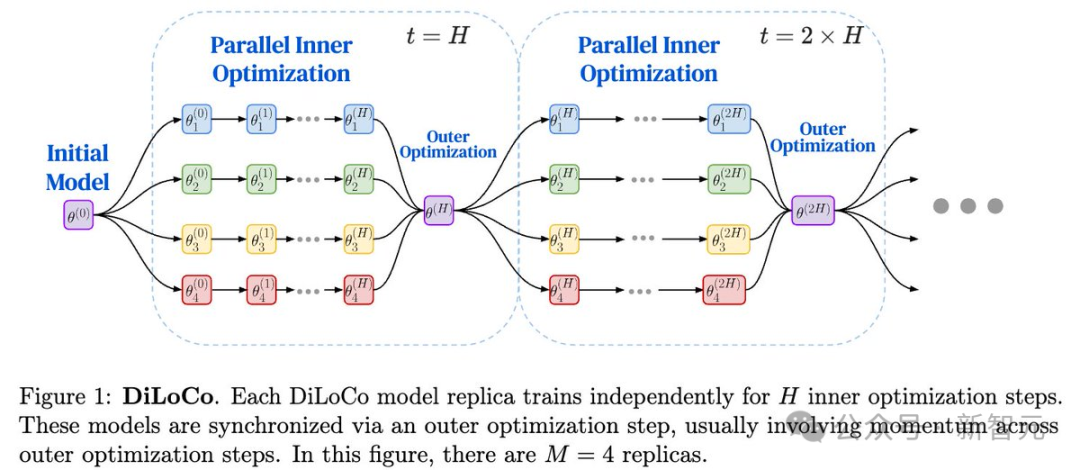
論文鏈接:https://arxiv.org/abs/2311.08105每個DiLoCo模型副本都會獨立訓練H個內部優化(inner optimization)步驟。
這些模型通過外部優化(outer optimization)步驟進行同步,通常在外部優化步驟之間引入動量機制。
在下圖中,示例中共有M=4個模型副本。
DiLoCo的成功已經被反復驗證。它的運作方式與聯邦學習的FedOpt方法類似。
此外,研究人員也多次證明DiLoCo在大模型(LLM)訓練中的卓越表現。
那麼DiLoCo有什麼問題?簡單來說——規模。
DiLoCo與數據並行訓練不同,它引入了額外的「外部」超參數,並且實際上的表現和理論上明顯不同。
這正是研究scaling laws的目的!
這次研究從零開始構建了DiLoCo和數據並行訓練的Scaling law,用於預測它們在大規模模型上的表現對比。
在數據並行訓練中,每個訓練步長都會處理一個大小為B的數據批。
在本研究中,批大小指的是批中的token數量(而不是序列數量)。
計算批梯度,並使用學習率γ進行優化。
在DiLoCo訓練過程中,每個時間步t處理一個全局批大小為B的數據,並在序列級別將其均勻分配到M個DiLoCo副本中。
因此,全局批大小仍然是B,而每個DiLoCo副本的本地批大小為B/M。與數據並行訓練類似,每個副本都會計算批梯度,並使用學習率γ執行一次內部優化(inner optimization)。
但與數據並行不同的是,DiLoCo每H步會執行一次「外部優化」(outer optimization),基於參數空間計算的外部梯度(outer-gradients),並使用學習率η進行更新。
一個重要的對比是數據並行vs.DiLoCo(M=1)。
雖然它們相似,但並不完全相同。
DiLoCo在M=1的情況下,仍然包含一個外部優化器(OuterOpt)步驟,因此它可以被視為Lookahead優化器的變體。
而在DiLoCo中,OuterOpt通常使用帶有Nesterov動量的GD,這意味著DiLoCo(M=1)實際上是數據並行訓練的一個變體,但動量操作僅每H步執行一次。

還進行了大量實驗,涵蓋訓練過程的各個方面,全面分析了它們的擴展行為。
實驗方法
大部分實驗里,研究團隊使用C4數據集的訓練集來訓練模型,評估指標用C4的驗證集。
另外,還在三個下遊任務上算了零樣本評估指標:HellaSwag、Piqa和Arc-Easy。
模型架構:Chinchilla變體
研究團隊用的是一個類似「Chinchilla」的純解碼器Transformer架構,加入了QK-LayerNorm,還使用了z-loss正則化來讓訓練更穩定。
他們把多個序列打包到每個批里,最大序列長度全程固定為2,048。
所有模型都是從零開始訓練的,因為這次主要想研究預訓練階段的規模規律。
研究團隊訓練了一堆模型,調整了Transformer層數、注意力頭的數量、QKV維度和前饋層的隱藏維度。
除非特別說明,他們都用Chinchilla的token預算,並且對除了最大的兩個模型(4B和10B參數)外,其他模型都做了大量的超參數調整。
算法和優化器
研究團隊用AdamW作為數據並行(Data-Parallel)的優化器,也是DiLoCo的內層優化器。兩個算法的β1設為0.9,β2設為0.99。
訓練開始有1000步的預熱,然後用餘弦學習率衰減。權重衰減參數λ設為T⁻¹,其中T是總訓練步數(取決於批大小和token預算)。到訓練結束時,學習率衰減到峰值的5%。
為了訓練穩定,他們把(內層)梯度的全局ℓ2範數剪裁到1,外層梯度不剪裁。
對於DiLoCo,他們用帶Nesterov動量的SGD作為外層優化器。動量設為0.9,外層學習率保持不變。
從0構建,全新Scaling Law已來
發現1:規模
DiLoCo的評估損失隨著N的增加,相對於數據並行(Data-Parallel)有所改善。
Scaling law預測,當M=2時,DiLoCo在參數達到幾十億以上時,損失會比數據並行更低。這一現像在研究調優的最大模型以及4B和10B模型的訓練中都得到了驗證。
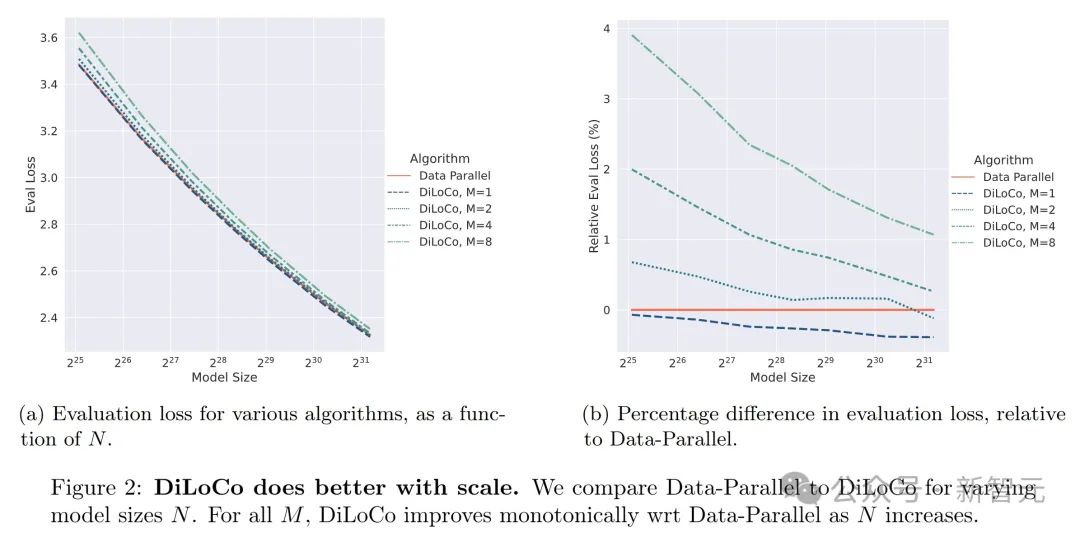
下圖2展示了DiLoCo和Data-Parallel兩種算法在不同模型規模(N)下的表現對比。
圖(a)顯示,隨著模型規模從2^25到2^31逐漸增大,DiLoCo(分別在M=1、2、4、8時)和Data-Parallel的評估損失(EvalLoss)都在下降,但DiLoCo的損失下降得更明顯,尤其是在M值較大時。
圖(b)進一步展示了DiLoCo相對於Data-Parallel的評估損失的百分比差異,可以看出,隨著模型規模增加,DiLoCo的損失比Data-Parallel低得越來越多,說明DiLoCo在模型規模擴大時表現更優越。
這個發現有兩個獨立但相關的部分:
DiLoCo(M=1)表現更好:就像上面提到的,DiLoCo在M=1時,所有模型規模的評估損失都比Data-Parallel低。而且隨著模型參數規模N增加,Data-Parallel和DiLoCo(M=1)之間的差距越來越大。
DiLoCo(M≥2)的表現:在大多數模型規模下,DiLoCo在M≥2時評估損失會更高。不過,如果看DiLoCo和Data-Parallel之間的百分比差異(帶正負號),會發現隨著N增大,DiLoCo相對Data-Parallel的表現越來越好,甚至在M=2、N=2.4億參數時超過了Data-Parallel。
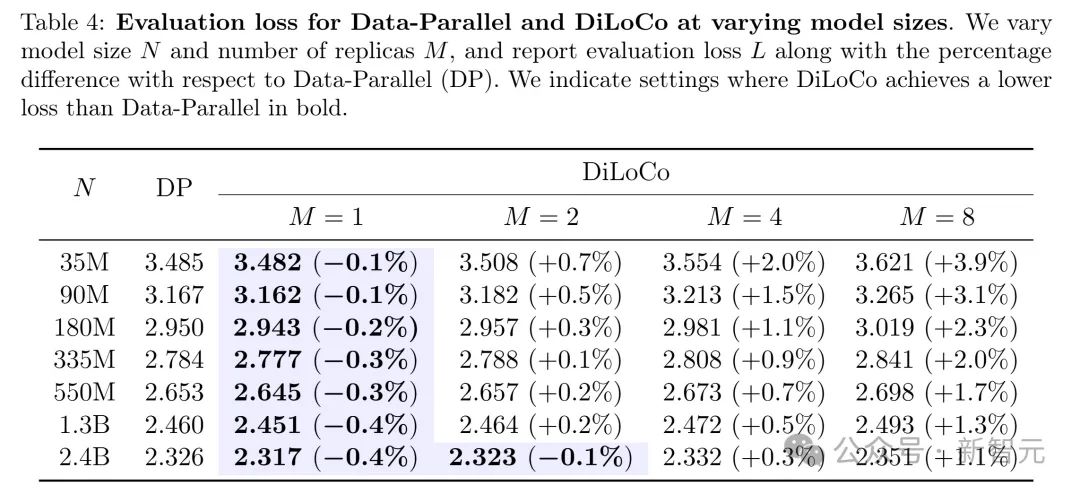
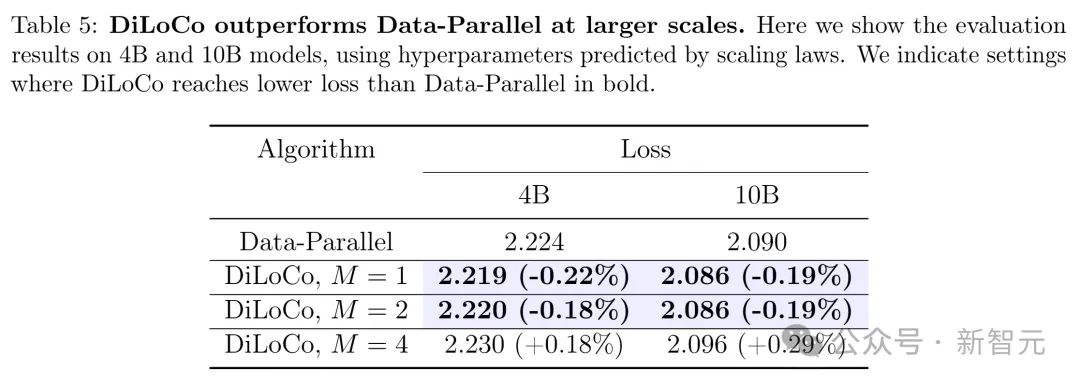
比如,研究團隊在下表4中列出了Data-Parallel和DiLoCo在不同模型規模N下的評估損失。
可以看出,不管M是多少,百分比差異都隨著N增加嚴格減小。
這個趨勢在圖2中也有展示:隨著N增加,DiLoCo的相對評估損失逐漸降低。
研究團隊還通過用縮放法則調好的超參數,訓練了40億和100億參數的模型來驗證這一點。
雖然圖2顯示的是「插值」範圍的結果(基於大量實驗掃瞄),但這些發現也可以推廣到外推狀態,能在M=1或2時用DiLoCo訓練出評估損失更低的40億和100億參數模型。
下表5展示了用外推超參數訓練的結果,展示了在較大規模的4B和10B模型上,DiLoCo和Data-Parallel算法的評估損失對比,表明DiLoCo在更大規模下整體表現出色。
發現2:單副本DiLoCo
當副本數M=1時,DiLoCo在不同模型規模下獲得的評估損失都比Data-Parallel低。
下圖3展示了當副本數M=1時,DiLoCo與Data-Parallel在不同模型規模(35M、550M、1.3B、2.4B)和全局批大小(以token計,從2^16到2^20)下的評估損失和HellaSwag零樣本準確率對比。
圖(a)顯示DiLoCo的評估損失始終低於Data-Parallel,且差距隨著批大小增加而擴大;圖(b)表明DiLoCo在HellaSwag零樣本準確率上也優於Data-Parallel,趨勢相似。
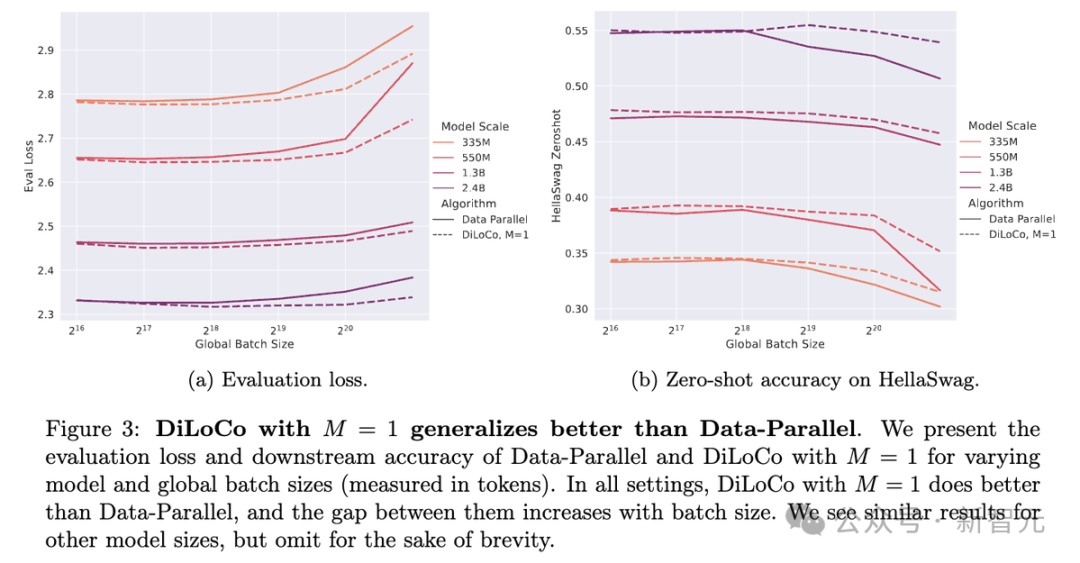
在幾乎所有情況下,在M=1時,DiLoCo不僅評估損失更低,下遊任務的零樣本準確率也比Data-Parallel高。
而且,DiLoCo(M=1)的表現對批大小(batch size)的穩定性更強:把批大小翻倍或翻四倍,對Data-Parallel的性能影響很大,但對DiLoCo(M=1)幾乎沒什麼影響,圖3里畫得很清楚。
發現3:批大小對性能的影響
DiLoCo提高了最佳批大小,而且最佳全局批大小隨著副本數M的增加而變大。這意味著DiLoCo相比Data-Parallel改善了橫向擴展能力。
雖然DiLoCo在批大小M>1時,挑選所有超參數中最好的實驗結果,評估損失往往略遜一籌,但它在批大小方面的表現顯著提升。
Data-Parallel和DiLoCo(M=1)在小批時表現都不錯,但隨著批大小增加,Data-Parallel的性能下降很快。
相比之下,不管批大小M是多少,DiLoCo的表現對批大小都穩定得多。
下圖4展示了評估損失的例子,結果表明,對於所有M值,DiLoCo的最佳批大小都比Data-Parallel更大,且隨著M的增加,DiLoCo的最佳批大小進一步增大。
例如,在550M模型中,Data-Parallel的評估損失在批大小較小時最低,而DiLoCo在批大小更大時表現更優,類似趨勢在1.3B和2.4B模型中也成立。

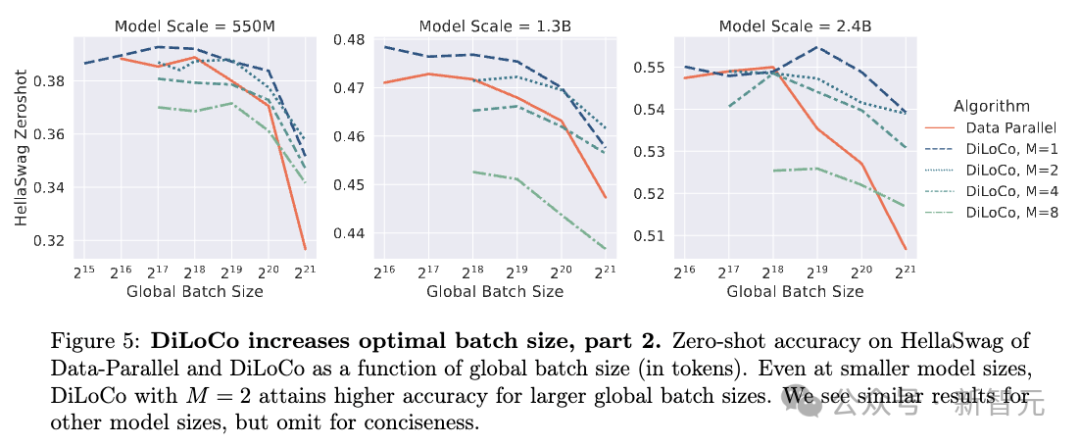
下圖5展示了在HellaSwag數據集上的零樣本準確率。結果顯示即使在較小的模型規模下,DiLoCo在M=2時也能在更大的全局批大小下實現更高的準確率。
例如在550M模型中,DiLoCo的準確率曲線在批大小增延長優於Data-Parallel;1.3B和2.4B模型也表現出類似趨勢。
發現4:外部學習率
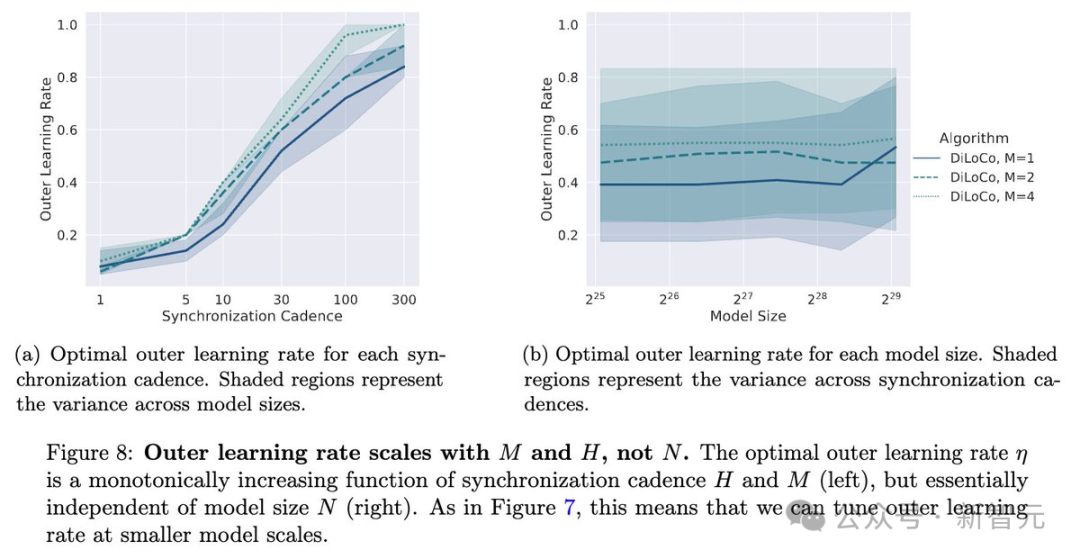
最佳外部學習率基本上與模型規模N無關,但會隨著副本數M的變化而變化。
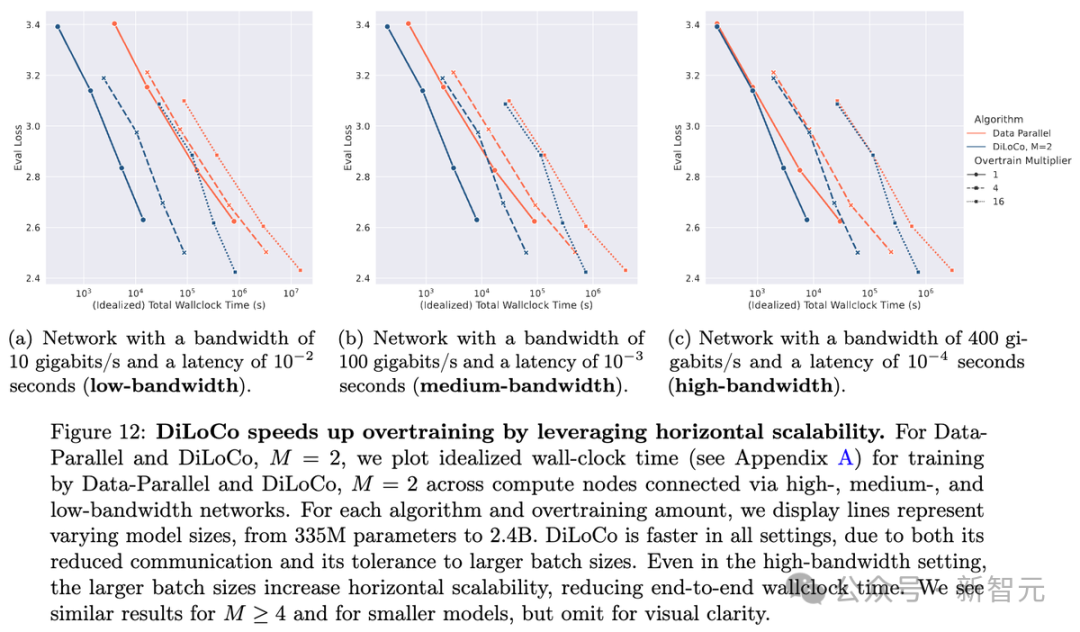
一個重要結果是,DiLoCo在水平擴展上更自然。在所有情況下,token預算D,只跟模型規模N有關。這意味著如果用4倍大的批大小,訓練步數會減少到1/4。
對DiLoCo來說,這依然能保持不錯的性能,還能一次性用更多資源,縮短總訓練時間。而Data-Parallel似乎更依賴串行訓練。這種訓練時間的減少還因為通信量降低而加倍明顯。
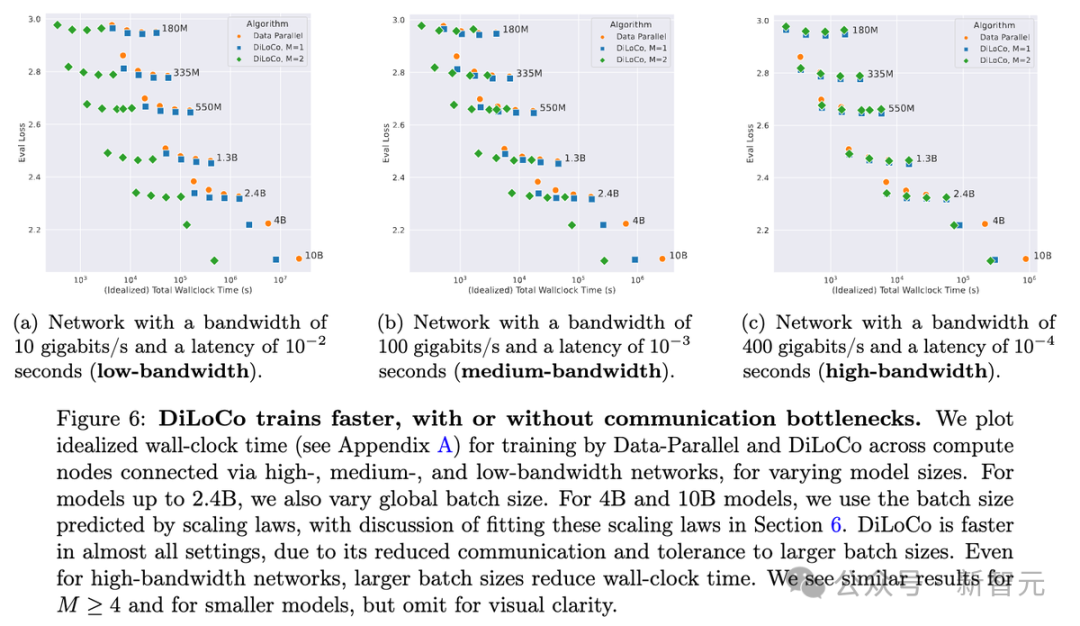
下圖6展示了理想的訓練時間(wall-clock time),模擬不同網絡帶寬下的情況。
可以看到,DiLoCo對較大批大小的容忍度使其能夠顯著更快地實現與Data-Parallel相當的性能損失,而且在低帶寬設置中這種效果更為明顯。
發現5:外部學習率
如下圖7所示,對於足夠大的模型(N≥3.35億參數),每個M的最佳η是固定的。M越大,η似乎也越大。這跟之前聯邦學習的研究一致:外層學習率應該隨著客戶端數量增加而增加。
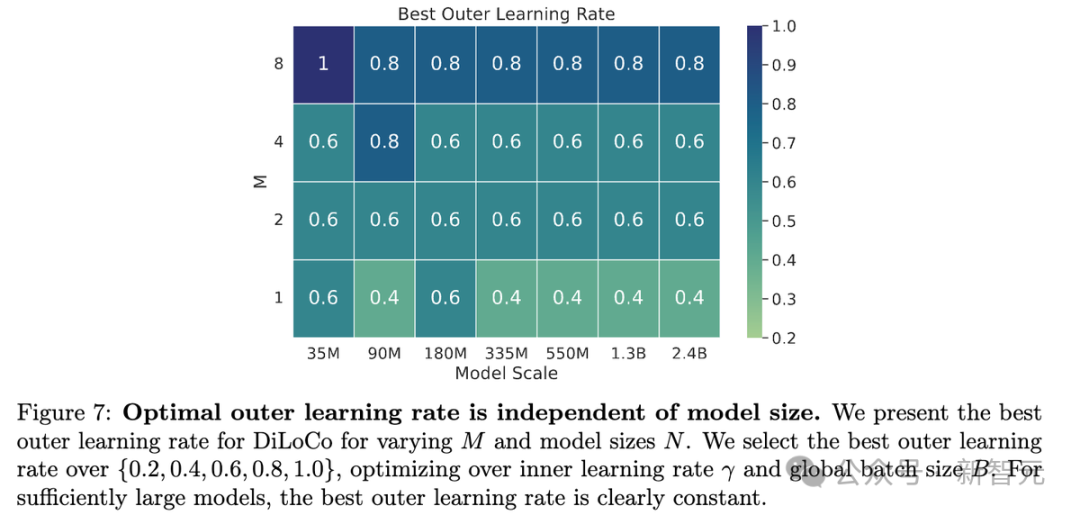
實際上,外部學習率僅取決於DiLoCo模型的數量以及同步的頻率。
也就是說,雖然最優的內層學習率會隨模型規模N變化,但DiLoCo的最優外層學習率η不依賴N,只跟M有關。
DiLoCo同樣有助於解決過度訓練的問題!
過度訓練可能會相當昂貴,但是增加了批大小並減少了通信量意味著,通常可以在相同的時間內用DiLoCo進行4倍的過度訓練(OT),而使用數據並行訓練只能進行1倍的過度訓練。
論文中還有更多內容。其中包括Scaling law本身,以及甚至提供了預測最優超參數的方法。
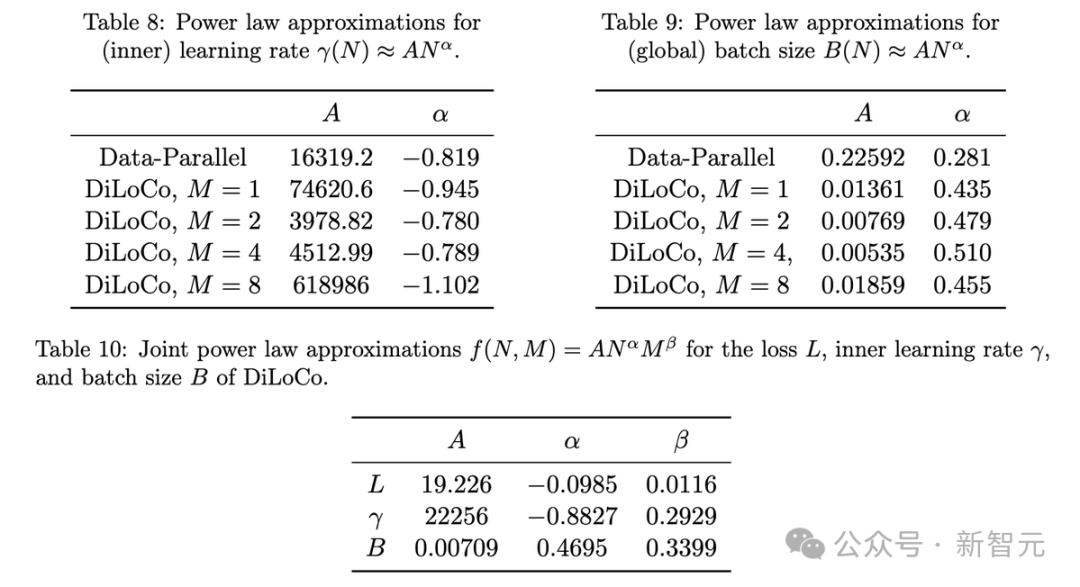
Scaling law表明,對於參數超過20億的模型,使用2個模型的DiLoCo優於數據並行方法
更多實驗細節和內容,請參閱原文。
Chinchilla將死?AI 3萬億美元的岔路
DiLoCo使得調整超參數和訓練模型變得更加簡單。但問題在於,AI模型本身「換湯不換藥」——還是Chinchilla那一套。
畢竟,過去的預訓練Scaling Law已進入尾聲,而新的AI Scaling Law與訓練無關。
如今,隨著新型「推理模型」的興起,一個問題浮出水面:如果Chinchilla死了,AI未來會怎樣?
大約5年前,OpenAI研究員發現,將更多的算力、數據投入到大規模訓練中,可以顯著提升AI模型的性能。

幾年後,Google研究人員更進一步,通過構建名為「Chinchilla」的模型證明,增加數據量能帶來更好的效果。
這種「計算+數據」的組合催生了如今的巨型模型,比如GPT-4。
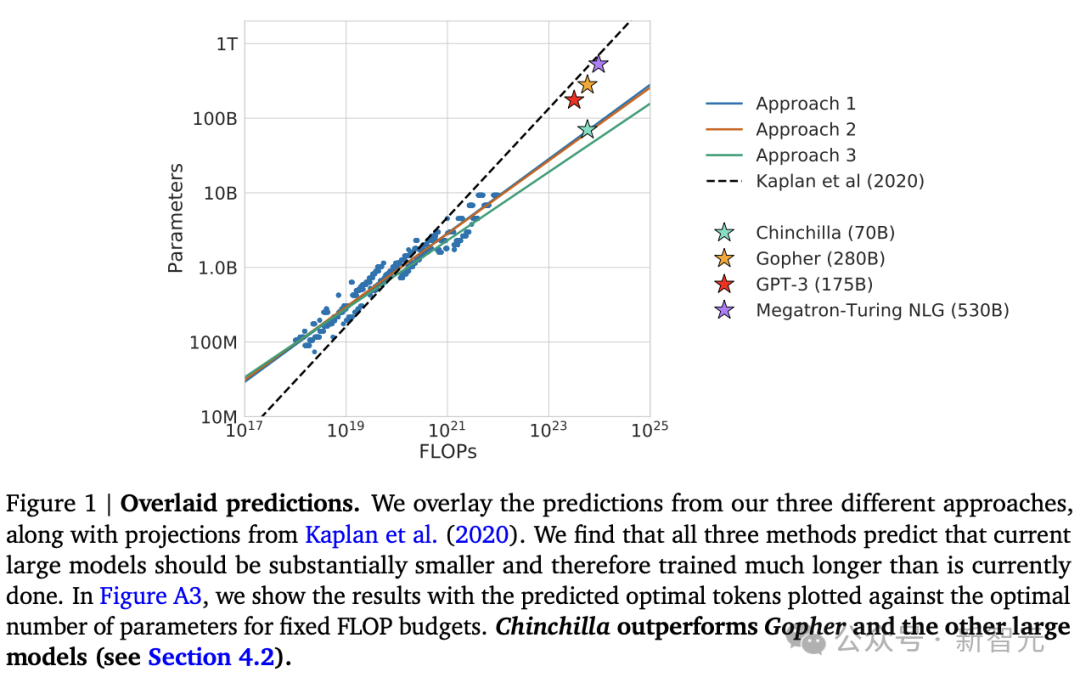
論文地址:https://arxiv.org/pdf/2203.15556
然而,這種策略的成功依賴於巨大的前期投入。
海量數據被塞進複雜且耗能的預訓練過程,科技大廠瘋狂建造數據中心,塞滿了英偉達GPU。
但問題來了:這種砸錢砸數據的模式,還能走多遠?
J.巴克萊資本的頂級分析師Ross Sandler指出,未來可能面臨兩種截然不同的情景:
一是,「Chinchilla」繼續主導,巨額算力和數據投入持續攀升;
二是,「停滯」替代方案,新型技術和模型以更少的資源實現更強性能。
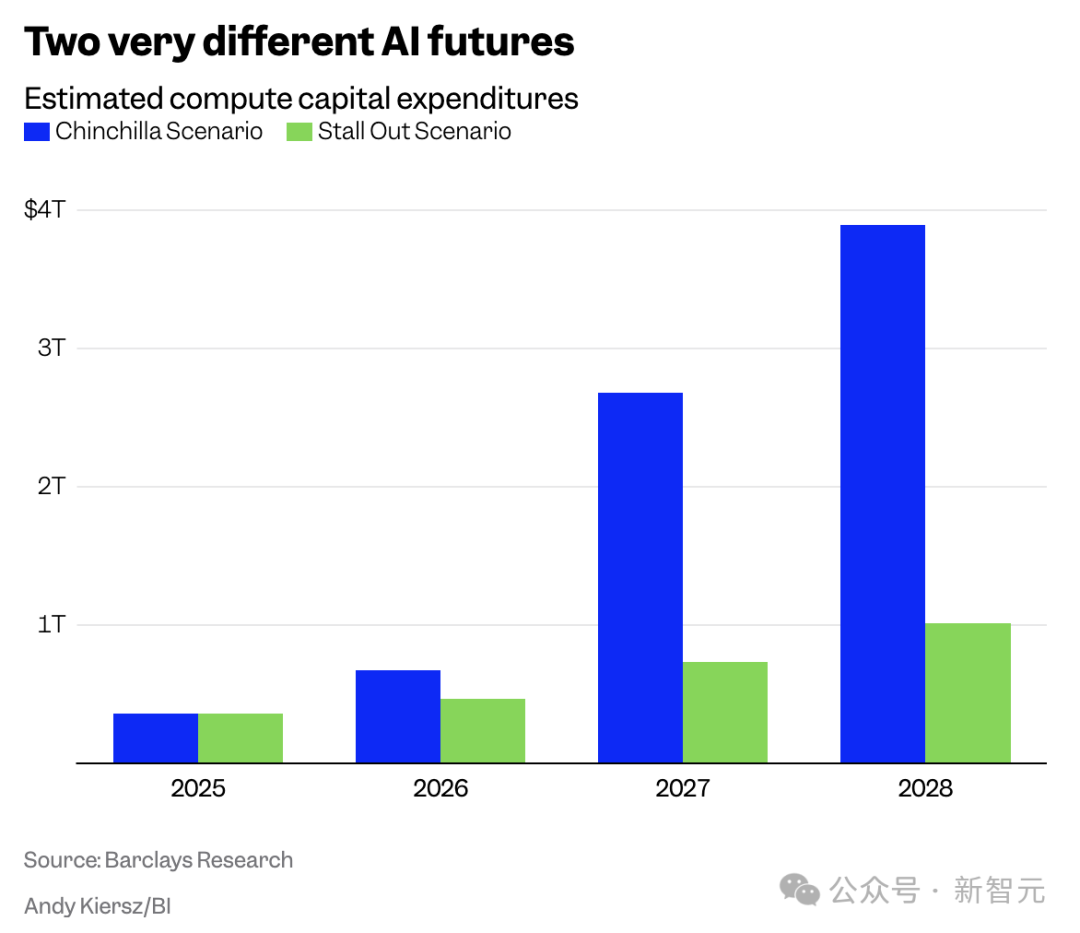
這兩種路徑的資本支出差距高達3萬億美元以上,足以影響整個行業的走向。
「推理模型」崛起
推動這一潛在變革的,是「推理模型」的興起。
OpenAI的o1、o3、DeepSeek R1、GoogleGemini 2.0 Flash Thinking等新模型,採用了一種名為「測試時計算」(test-time compute)的技術。
這種方法將複雜查詢分解為小任務,逐一處理,不再依賴長時間的預訓練。
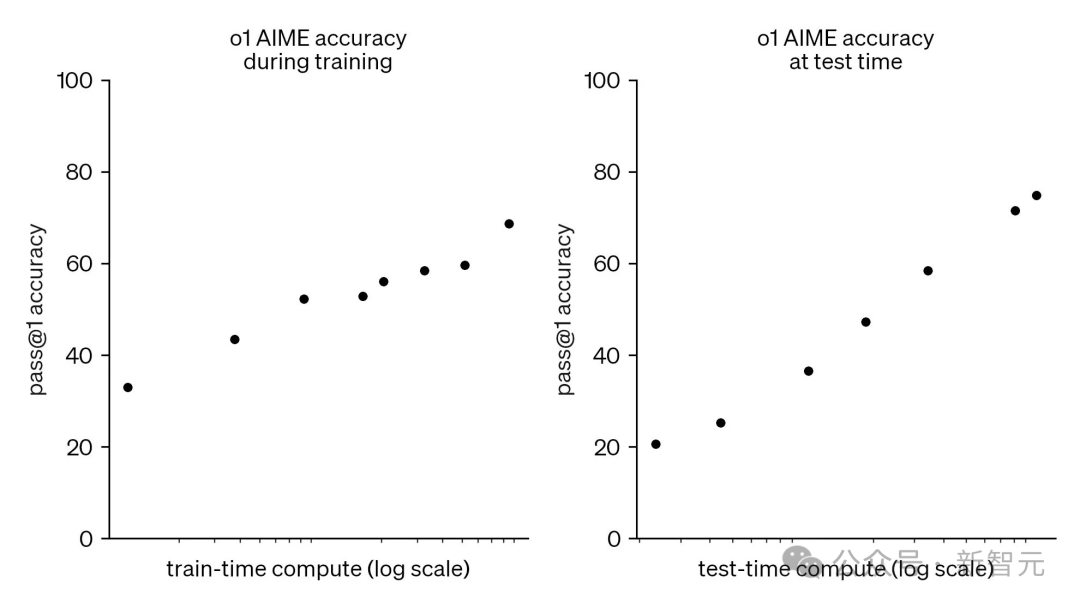
相較於傳統模型,推理模型可能響應稍慢,但它們輸出更準確,運行成本也更低。
更重要的是,它們擺脫了對大規模預訓練的依賴。
DeepSeek R1甚至展示了一種可能:開源推理模型能在短時間內實現性能飛躍。
這意味著,AI公司可能不再需要花費18-24個月和巨資去打造下一個「巨無霸」模型。
此外,混合專家模型(MoE)也成為被廣泛採用的技術,通過訓練多個小型「專家」模型,讓它們與大模型協同工作,只在需要時調用部分算力。
這種方式,一步降低了基礎設施需求。
Chinchilla何去何從?
過去五年,Chinchilla策略推動了AI供應鏈的繁榮,許多公司股價因此飆升。
但如今,它的可持續性正受到質疑。
J.巴克萊分析師指出,「隨著投入成本激增,比如一次預訓練耗資100億美元,性能增益卻可能越來越小,這種模式的性價比正在下降」。

更嚴峻的是,訓練數據可能正在枯竭。
高質量數據的供應有限,而AI對數據的「胃口」卻越來越大。如果沒有足夠的「食物」,Chinchilla還能活多久?
甚至,業內一些大佬預測,像OpenAI這樣的公司,可能會在GPT-5之後停止無休止的規模Scaling。
面對數據枯竭,AI行業將希望寄託於「合成數據」。研究者認為,這種「自給自足」的反饋循環能讓模型不斷自我進化,推動技術邁向新高度。
Chinchilla們本質上可以通過「自我喂養」來生存。
「如果AI行業在合成數據和遞歸自我改進方面取得突破,那麼我們將重新走上Chinchilla scaling路徑,計算需求將繼續迅速上升」。
Chinchilla死了嗎?這個問題,AI市場會給出最終答案。
如果推理模型、MoE技術成熟,AI可能走向輕量化,高效率的未來,數萬億美金的基礎設施投資,或許不再必要。
但,如果「合成數據」讓Chinchilla重煥生機,算力競賽將捲土重來。
無論哪種未來到來,AI的演進都在重塑整個世界。
參考資料:
https://arxiv.org/pdf/2503.09799
https://x.com/MatharyCharles/status/1900593694216253827
https://www.businessinsider.com/ai-chinchilla-openai-google-anthropic-compute-demand-capex-scaling-laws-2025-3