CVPR 2025:無需物理引擎,一個模型搞掂圖像渲染與分解
Uni-Renderer團隊 投稿
量子位 | 公眾號 QbitAI
無需物理引擎,單個模型也能實現「渲染+逆渲染」了!
在計算機圖形和視覺領域,渲染是指將3D模型變成逼真的2D圖片,逆渲染則是從2D圖片分析出3D模型的各種屬性(如材質、光照等)。
現在,從材質分解(逆渲染)——材質編輯——物體渲染的整個流程,都被統一到了一個框架中,且在性能方面達到了新SOTA。

該研究出自港科大廣州以及趣丸科技,他們首創雙流擴散框架Uni-Renderer,將渲染(生成圖像)與逆渲染(分解材質、光照、幾何)統一到單一擴散框架,實現「生成即分解」的閉環能力。
相關成果已被CVPR 2025接收,代碼與數據全面開源。
研究團隊表示,這一成果未來將重塑影視、遊戲、AR/VR等產業的視覺生成管線。

首創雙流擴散框架
正如開頭提到,渲染是通過光線追蹤或路徑追蹤,生成高質量的圖像;逆渲染是在RGB圖像中提取出對象屬性,比如金屬度、粗糙度以及光照細節。
傳統方法需獨立建模訓練渲染器與逆渲染器,計算成本高效率低泛化差,兩個過程也缺乏聯繫,精度和屬性分解效果都有限。
而Uni-Renderer的雙流擴散架構將兩個過程建模為雙條件生成任務,生成時以材質、光照為條件輸出圖像,分解時以圖像為條件反推內在屬性:
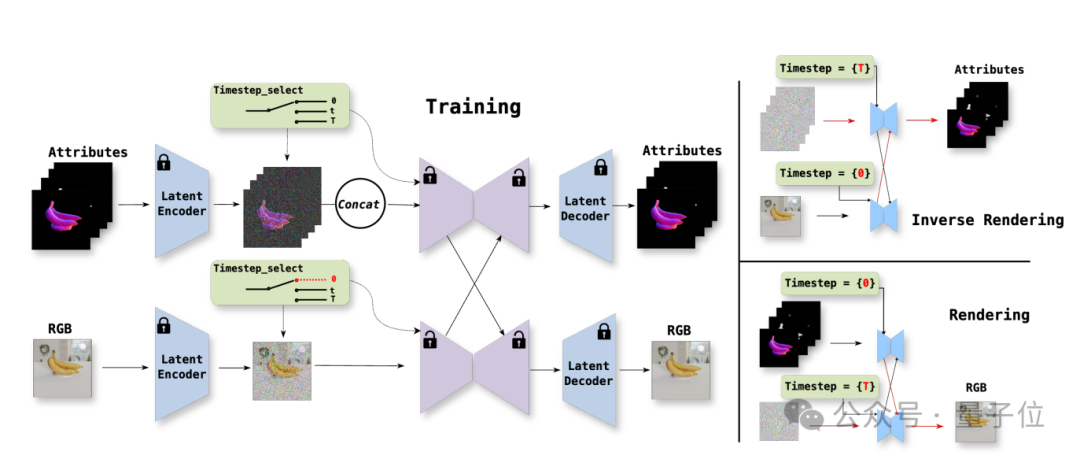
其中渲染流負責生成RGB圖像:以VAE編碼材質、法線、光照為條件,通過擴散過程生成圖像,支持動態調整粗糙度/金屬值(如「光滑棒球」秒變「金屬質感」)。

而逆渲染流負責處理內在屬性:以圖像為輸入,通過噪聲預測網絡分解屬性, 並在網絡內部進行跨流交互,實現信息傳遞融合優化協同。
此外,團隊還採用了差異化的timestep調度策略,通過不同的timestep使模型區分渲染和逆渲染的映射關係,讓這兩者能更好協同。
最後,鑒於傳統逆渲染因「材質-光照-幾何」耦合性導致分解模糊。
因此,他們將逆渲染分解得到的屬性,再次輸入到渲染模塊進行再渲染,並借助循環約束確保分解結果可重新生成一致圖像,徹底告別「分解即失真」。
實測對比,性能碾壓SOTA
1、材質編輯
對比Subias(過曝)、InstructPix2Pix(背景錯誤),Uni-Renderer精準控制高光與漫反射,如下圖中「金屬橙子」表面反射環境光照,細節逼真。

2、重光照
如下圖所示,輸入單張圖像,直接替換環境光為「夕陽/霓虹」,模型自動調整漫反射與鏡面反射,光影過渡自然,超越NvDiffRec的生硬效果。

3、真實場景
下圖中,「水壺」逆渲染成功解析高頻環境光,金屬質感與粗糙度誤差僅3%。

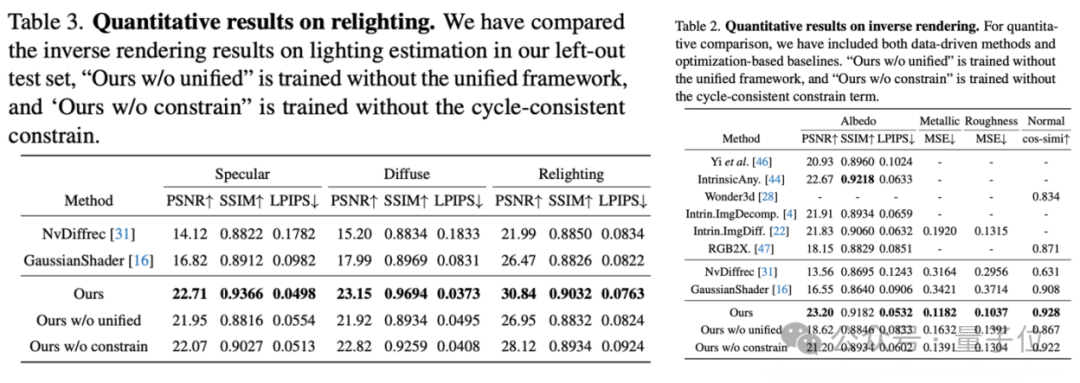
概括而言,通過在生成階段,以材質、光照為條件輸出圖像;分解階段,以圖像為條件反推內在屬性,效率提升了200%。
同時,Uni-Renderer強製內在屬性與圖像的一致性,在公開測試集上材質估計誤差降低40%,光照分解PSNR提升30%。
另外,研究基於Objaverse構建業界最大規模多材質合成數據集,涵蓋20萬3D對象、121種材質/光照組合,支持高解像度(1024×1024)訓練。模型在未見過的真實場景中(如金屬水壺、手機支架)仍能精準分解高光、粗糙度與複雜光照。
在渲染任務中,PSNR達30.72(對比基線28.09),逆渲染任務中,材質估計MSE僅0.118(優化方法0.316);重光照效果超越GaussianShader等方案,真實感拉滿。
開源即用
目前團隊對Uni-renderer同步進行了開源,包括:
-
代碼庫:支持一鍵訓練/推理,兼容PyTorch生態;
-
合成數據集:20萬對象+百萬級材質-光照組合,涵蓋數理化生多領域;
-
預訓練模型:即插即用於遊戲資產生成、影視後期、工業設計等場景。
這項研究的作者為陳知非, 許添碩以及葛汶杭,他們是來自於香港科技大學(廣州)ENVISION實驗室的博士生,師從陳穎聰教授。
(ENVISION實驗室專注於視覺生成模型的研究,致力於探索其基本原理,以提高模型的質量、效率、多樣性和可控性。)

小結一下,Uni-Renderer的提出,標誌著視覺生成與解析從「分而治之」邁入「統一智能」時代。
其雙流架構與循環約束機制,為跨任務聯合優化提供了全新範式。
未來,團隊將進一步融合真實數據,攻克複雜動態場景,讓人工智能成為「全能視覺工程師」。
論文鏈接:
https://arxiv.org/pdf/2412.15050
GitHub代碼:
https://yuevii.github.io/unirenderer-page/
實驗室官網:https://envision-research.hkust-gz.edu.cn/index.html#news