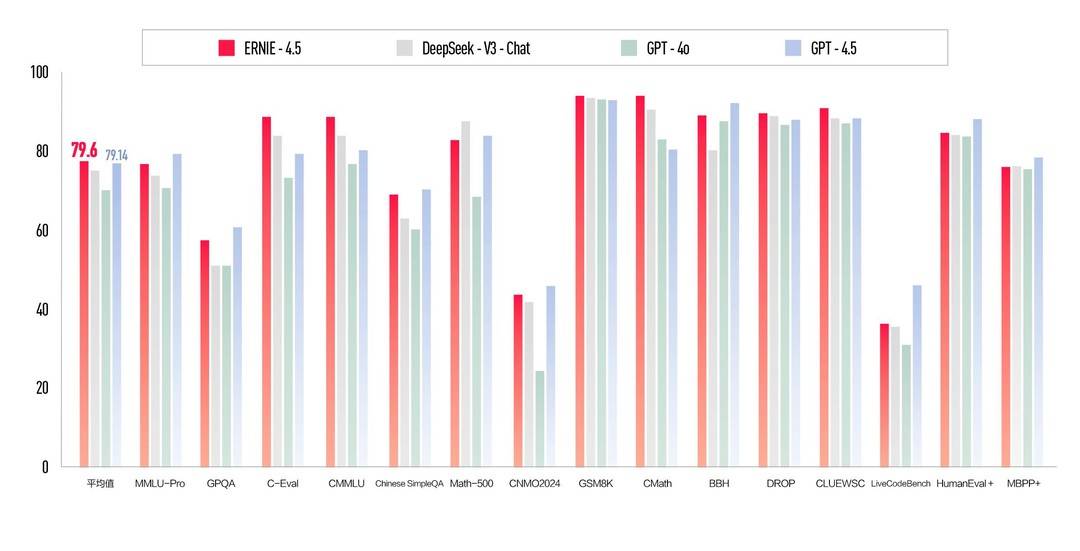
剛剛,2024 圖靈獎頒給了強化學習之父 Richard Sutton 與導師 Andrew Barto | 文末贈書
轉自 | 機器之心
強化學習先驅 Andrew Barto 與 Richard Sutton 獲得今年的 ACM 圖靈獎。
人工智能學者,再次收穫圖靈獎!

剛剛,計算機學會(ACM)宣佈了 2024 年的 ACM A.M. Turing Award(圖靈獎)獲得者:Andrew Barto 和 Richard Sutton。
他們都是對強化學習做出奠基性貢獻的著名研究者,Richard Sutton 更是有「強化學習之父」的美譽。Andrew Barto 則是 Sutton 的博士導師。自 1980 年代起,兩位學者在一系列論文中提出了強化學習的主要思想,還構建了強化學習的數學基礎,並開發了強化學習的重要算法。兩人合著的《Reinforcement Learning: An Introduction》一直是強化學習領域最經典的教材之一。

Andrew Barto 是馬莎諸塞大學阿默斯特分校信息與計算機科學榮休教授。Richard Sutton 是阿爾伯塔大學計算機科學教授,同時也是 Keen Technologies 的研究科學家。
ACM 圖靈獎常被稱為「計算機領域的盧保獎」,獎金為 100 萬美元,由Google公司提供資金支持。該獎項以提出計算數學基礎的英國數學家艾倫・圖靈命名。
強化學習,當今 AI 突破的原點
說起強化學習,我們可以想起最近引爆全球 AI 技術爆發的 DeepSeek R1,其中的強化學習算法 GRPO 賦予了大模型極強的推理能力,且不需要大量監督微調,是 AI 性能突破的核心。
再往前看,在圍棋上超越人類的 AlphaGo 也是利用強化學習自我博弈訓練出的策略。可以說最近的幾次 AI 突破,背後總有強化學習的身影。
人工智能領域通常會比較關注智能體的構建 —— 即可以感知和行動的實體。更智能的智能體能夠選擇更好的行動方案。因此,想出比其他方案更好行動方案概念,對 AI 非常關鍵。借用自心理學和神經科學的「獎勵」— 詞,表示向智能體提供的與其行為質量相關的信號。強化學習(RL)是在這種信號下學習更成功行為的過程。
通過獎勵學習的理念對動物訓練師來說已有數千年歷史。後來,艾倫・圖靈 1950 年的論文《計算機械與智能》提出了「機器能思考嗎?」的問題,並提出了基於獎勵和懲罰的機器學習方法。
圖靈報告說他進行了一些初步實驗,Arthur Samuel 也在 1950 年代後期開發了一個能通過自我對弈學習的跳棋程序。但在接下來的幾十年里,AI 的這一方向進展甚微。
直至 1980 年代初,受心理學觀察的啟發,Andrew Barto 和他的博士生 Richard Sutton 開始將強化學習作為一個通用問題框架進行構建。
他們借鑒了馬爾可夫決策過程(MDP)提供的數學基礎,在這個框架中,智能體在隨機環境中做出決策,每次轉換後收到獎勵信號,並最大化其長期累積獎勵。
與標準 MDP 理論假設智能體知道一切不同,RL 框架允許環境和獎勵是未知的。RL 的最小信息需求,結合 MDP 框架的通用性,使 RL 算法可以應用於廣泛的問題。
Andrew Barto 和 Richard Sutton 聯手或者協同他人,都開發了許多 RL 基本算法。其中包括他們最重要的貢獻 —— 時間差分學習(該算法為解決獎勵預測問題取得了重要進展),以及策略梯度方法和使用神經網絡作為表示學習函數的工具。他們還提出了結合學習和規劃的智能體設計,展示了獲取環境知識作為規劃基礎的價值。
同樣有影響力的是他們的教科書《Reinforcement Learning: An Introduction》(1998),它仍然是該領域的標準參考,被引用超過 79,000 次。這本書讓數千名研究人員理解並為這一新興領域做出貢獻,至今仍激發著計算機科學領域的許多重要研究活動。

儘管 Barto 和 Sutton 的算法是數十年前開發的,但通過將強化學習與深度學習(由 2018 年圖靈獎獲得者 Bengio、Hinton、LeCun 開創)相結合,強化學習的實際應用已在過去十五年中取得重大進展。於是,深度強化學習技術應運而生。
強化學習最著名的例子是 AlphaGo 計算機程序在 2016 年和 2017 年戰勝了頂級人類圍棋選手。另一個近期重大成就是聊天機器人 ChatGPT。
ChatGPT 是一個經過兩階段訓練得到的大型語言模型(LLM),其中第二階段採用了一種名為「基於人類反饋的強化學習(RLHF)」的技術,其作用是可以讓模型輸出符合人類期望。
強化學習在許多其他領域也取得了成功,其中之一是機器人運動技能學習。通過強化學習,機器手可以學會操作物體和解決物理問題;並且這種學習過程可在模擬中完成,然後再遷移到現實世界。
強化學習適用的領域還包括網絡擁堵控制、芯片設計、互聯網廣告、優化、全球供應鏈優化、改進聊天機器人的行為和推理能力,甚至改進矩陣乘法算法 —— 這是計算機科學中最古老的問題之一。
最後,強化學習還反過來助力了神經科學的發展 —— 強化學習正是受到了該學科的啟發。最近的研究,包括 Barto 的研究成果,已經表明 AI 領域開發的某些強化學習算法可為涉及人類大腦中多巴胺系統的廣泛發現提供最佳解釋。
「Barto 和 Sutton 的工作展示了將多學科方法應用於我們領域長期挑戰的巨大潛力,」ACM 主席 Yannis Ioannidis 解釋道。「從認知科學和心理學到神經科學的研究領域啟發了強化學習的發展,這為 AI 領域的一些最重要進展奠定了基礎,並讓我們更深入地瞭解大腦如何工作。Barto 和 Sutton 的工作不是我們已經超越的墊腳石。強化學習繼續發展,並為計算和許多其他學科的進一步發展提供了巨大潛力。用我們領域最負盛名的獎項表彰他們是非常恰當的。」
「在 1947 年的一次演講中,艾倫・圖靈表示『我們想要的是一台能從經驗中學習的機器』」,Google高級副總裁 Jeff Dean 指出。「Barto 和 Sutton 開創的強化學習直接回應了圖靈的挑戰。他們的工作是過去幾十年 AI 進步的關鍵。他們開發的工具仍然是 AI 繁榮的中心支柱,帶來了重大進步,吸引了大量年輕研究人員,並推動了數十億美元的投資。RL 的影響將持續到未來。Google很榮幸贊助 ACM 圖靈獎並表彰那些塑造了改善我們生活的技術的個人。」
作者背景
Andrew G. Barto
Andrew Barto 是馬莎諸塞大學阿默斯特分校信息與計算機科學系榮譽退休教授。他於 1977 年作為博士後研究助理在馬莎諸塞大學阿默斯特分校開始職業生涯,此後擔任過多個職位,包括副教授、教授和系主任。Barto 在密歇根大學獲得數學學士學位(優等),並在那裡獲得了計算機與通信科學的碩士和博士學位。
Barto 的榮譽包括馬莎諸塞大學神經科學終身成就獎、IJCAI 研究卓越獎(Research Excellence Award)和 IEEE 神經網絡學會先驅獎。他是電氣和電子工程師協會(IEEE)會士和美國科學促進會(AAAS)會士。
Richard S. Sutton
Richard S. Sutton 是阿爾伯塔大學計算機科學教授、Keen Technologies(一家總部位於德克薩斯州達拉斯的通用人工智能公司)的研究科學家,以及阿爾伯塔機器智能研究所(Amii)的首席科學顧問。Sutton 從 2017 年到 2023 年是 DeepMind 的傑出研究科學家。在加入阿爾伯塔大學之前,他曾於 1998 年至 2002 年在紐澤西州 Florham Park 的 AT&T 香農實驗室人工智能部門擔任首席技術人員。
Sutton 與 Andrew Barto 的合作始於 1978 年,當時在馬莎諸塞大學阿默斯特分校,Barto 是 Sutton 的博士和博士後導師。Sutton 在史丹福大學獲得心理學學士學位,在馬莎諸塞大學阿默斯特分校獲得計算機與信息科學的碩士和博士學位。
Sutton 的榮譽包括獲得 IJCAI 研究卓越獎、加拿大人工智能協會終身成就獎和馬莎諸塞大學阿默斯特分校的傑出研究成就獎。Sutton 是倫敦皇家學會會士、人工智能促進協會會士和加拿大皇家學會會士。
參考鏈接
https://x.com/TheOfficialACM/status/1897225672935735579
https://amturing.acm.org/
圖書介紹
▊《強化學習(第2版)》
【加】Richard S. Sutton(李察·辛頓) 【美】Andrew G. Barto(安德魯·巴圖) 著
-
強化學習領域奠基性經典著作!
-
人工智能行業的強化學習聖經!
《強化學習(第2版)》作為強化學習思想的深度解剖之作,被業內公認為是一本強化學習基礎理論的經典著作。它從強化學習的基本思想出發,深入淺出又嚴謹細緻地介紹了馬爾可夫決策過程、蒙地卡羅方法、時序差分方法、同軌離軌策略等強化學習的基本概念和方法,並以大量的實例幫助讀者理解強化學習的問題建模過程以及核心的算法細節。適合所有對強化學習感興趣的讀者閱讀、收藏。
在第2版中,隨著強化學習近來的蓬勃發展,作者補充了很多新的內容:人工神經網絡、蒙地卡羅樹搜索、平均收益最大化……涵蓋了當今最關鍵的核心算法和理論。不僅如此,作者還以真實世界的應用為例闡述了這些內容。

限時優惠,快快搶購吧!
關於強化學習或者本書你有什麼看法或者理解?歡迎在評論區留言,我將挑選出留言點讚數量最多的2位讀者贈送這本《強化學習》,到3月18日中午12:00截止。(注意是用心和優質的留言哦)