CVPR’25跨模態因果對齊,讓機器更懂視覺證據丨中大南洋理工等聯合開源
CRA團隊 投稿
量子位 | 公眾號 QbitAI
跨模態因果對齊,讓機器更懂視覺證據!
來自中山大學、新加坡南洋理工大學等團隊提出跨模態因果對齊框架(CRA),通過因果乾預和跨模態對齊,顯著提升時空定位的準確性與可解釋性。
相關論文已被CVPR 2025接收,代碼已開源。

事情是這樣的——
近年來隨著多模態大模型的發展,影片問答(VideoQA)任務——要求模型根據影片內容回答自然語言問題——性能顯著提升。
然而,現有模型往往依賴訓練數據中的統計偏差(如語言關鍵詞與答案的虛假關聯),而非真正的因果視覺證據,導致回答缺乏可解釋性。
舉個栗子~
例如下圖中,當影片中出現「嬰兒」和「女性」時,模型可能僅因二者高頻共現而給出答案,卻忽略真實因果事件(如「女性抱起嬰兒」)。
也就是說,雖然結果答對了,但過程中模型採納的是錯誤的視覺依據。
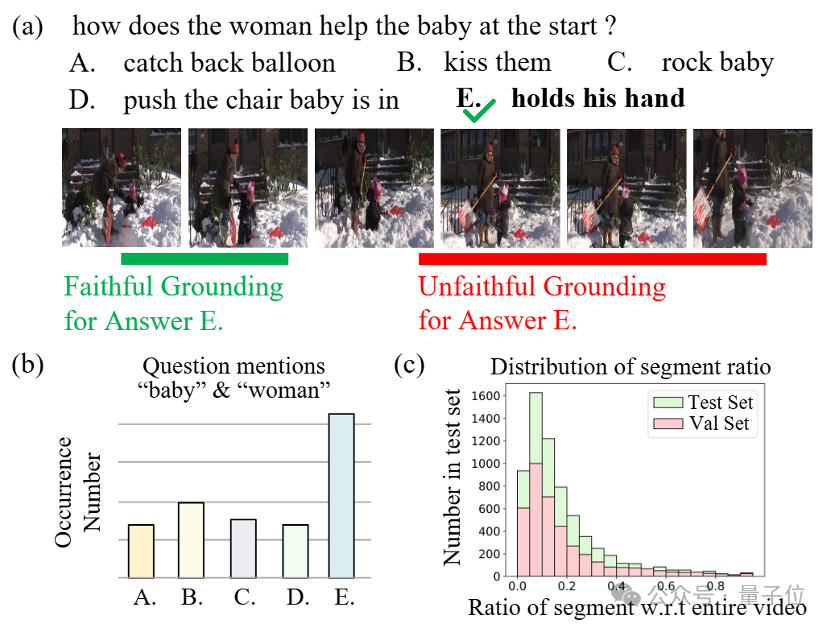
針對類似情況,為提供可靠的視覺證據支持,影片問答定位(VideoQG)任務應運而生,要求模型同時輸出答案及其對應影片片段的時間區間。
但現有方法面臨兩大挑戰:
-
多模態偏差:影片與語言中的混淆因素(如高頻關鍵詞、短時視覺特徵)導致模型學習虛假關聯;
-
弱監督限制:標註影片片段成本高昂,現有模型依賴影片問答(VideoQA)的弱監督信號,難以精準定位。
以上就是CRA框架誕生的背景。

此外,中山大學HCP-Lab團隊已將關鍵的因果模塊集成到開源因果框架CausalVLR中。
該框架是一個基於PyTorch的python開源工具包,用於因果關係發現,因果推理,為各種視覺語言推理任務實現最先進的因果學習算法。
三模塊驅動因果推理
現有方法常因依賴於訓練數據中的統計偏差,導致模型無法準確識別與問題相關的因果視覺場景,進而產生不準確的時空定位結果。
為克服這一問題,CRA框架通過三個核心模塊實現了從噪聲抑制、特徵對齊到因果關係建模的全流程優化。
該框架在NextGQA和STAR數據集上的實驗結果表明,CRA能夠顯著提升模型的時空定位能力和因果推理的準確性,為影片問答定位任務提供了更可靠的技術解決方案。
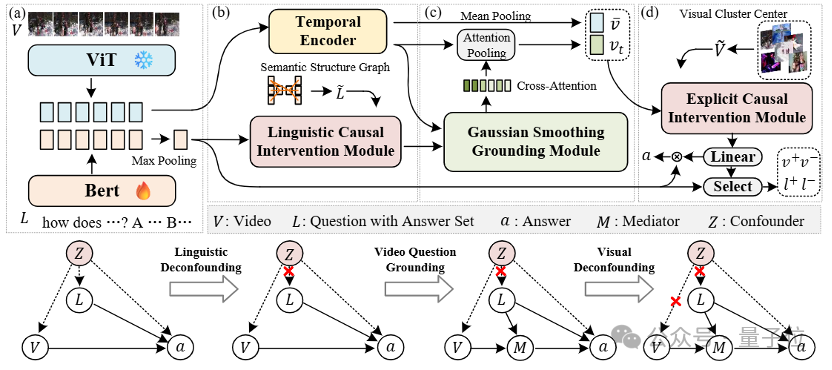
三個核心模塊具體展開如下:
GSG:抑制噪聲,聚焦關鍵幀
第一個,高斯平滑定位模塊(GSG)。
GSG模塊通過自適應高斯濾波去噪,精準估計影片片段的時間間隔。
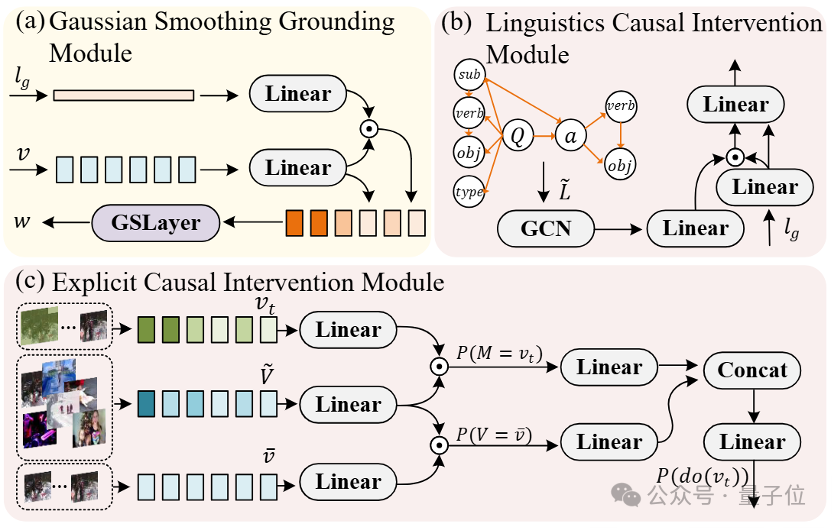
它的核心功能,是基於跨模態注意力估計時間區間,通過自適應高斯濾波去噪,生成魯棒的影片片段特徵。
技術亮點主要有仨:
1、跨模態注意力計算:利用CLIP影片特徵與RoBERTa語言特徵的交互,生成初始時間注意力權重;2、自適應高斯濾波:引入可學習參數的高斯核,抑制時序上的不穩定噪聲(如無關背景幀),突出關鍵事件區域(下圖);

3、動態閾值分割:根據平滑後的注意力分佈,動態截取高響應區間,提升定位精度。
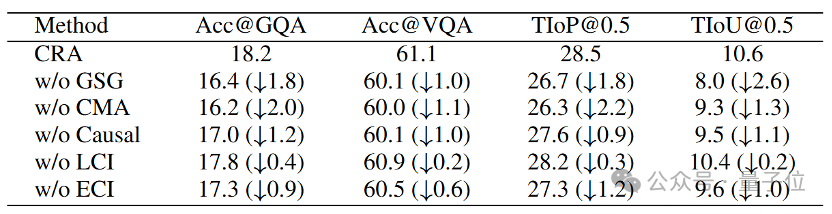
消融實驗顯示,移除高斯濾波(GSG w/o GS)會導致IoU@0.5下降2.2%(下表),證明其對噪聲抑制的關鍵作用。
 △GSG消融實驗,其中SGG w/o GS†表示GSG在訓練過程中具有高斯平滑,但在推理過程中沒有高斯平滑
△GSG消融實驗,其中SGG w/o GS†表示GSG在訓練過程中具有高斯平滑,但在推理過程中沒有高斯平滑CMA:弱監督下的雙向對齊
第二個,交叉模態對齊模塊(CMA)。
CMA模塊利用雙向對比學習,增強影片與問答特徵的對齊效果。
它的核心功能,是通過雙向對比學習,對齊影片片段特徵與問答特徵,增強跨模態一致性。
技術亮點有二:
-
雙向InfoNCE損失:從同一批次中采樣正/負樣本,分別對齊視覺→語言和語言→視覺特徵(公式1-2);
-
動態難樣本挖掘:優先選擇語義差異大的負樣本,迫使模型關注細粒度因果關聯。
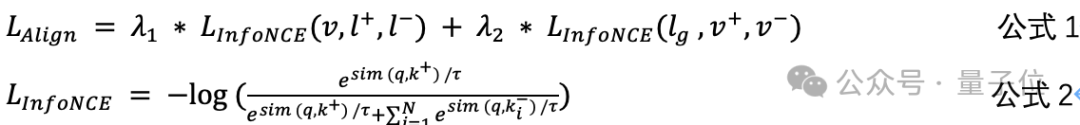
移除CMA模塊後,Acc@GQA下降2%,IoP@0.5下降2.2%(下表),凸顯其對弱監督訓練的重要性。
ECI:切斷虛假因果鏈
第三個,顯式因果乾預模塊(ECI)。
ECI模塊則通過前門和後門干預,消除多模態偏差,提升因果一致性。
它的核心功能,是針對視覺和語言模態分別設計前門干預與後門干預,消除多模態混淆因素。
技術亮點有二:
-
語言後門干預:解析問答語義結構圖(如主謂賓關係),阻斷關鍵詞與答案的虛假路徑;
-
視覺前門干預:以影片片段為中介變量,通過特徵聚類模擬混雜因子分佈,重構因果鏈(公式3-4)。
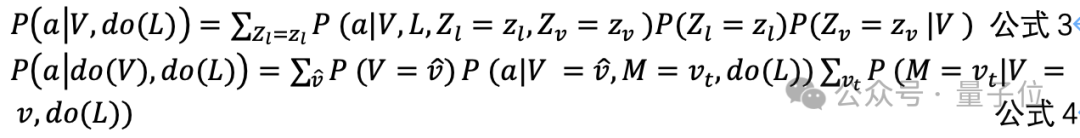
實驗結果顯示,在NextGQA數據集上,去除了Causal模塊後相對於CRA在Acc@GQA造成了1.2%的性能損失。
實驗結果:多維度性能領先
在NextGQA數據集中,CRA以18.2%超越Temp[CLIP](NG+)2.2%,且在使用FrozenBiLM大模型時仍保持優勢。
此外,IoP@0.5達28.5%,顯著優於基於LLM偽標註的TimeCraft(27.8%),證明其無需額外數據的高效性。
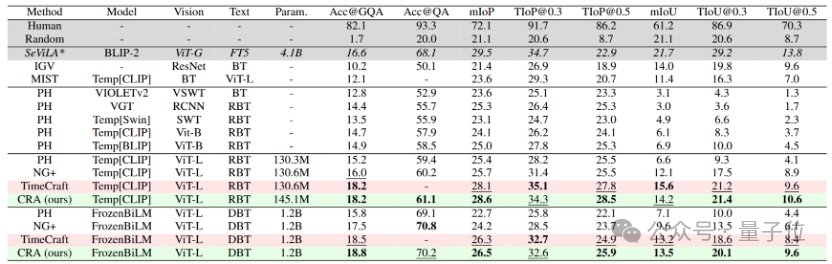
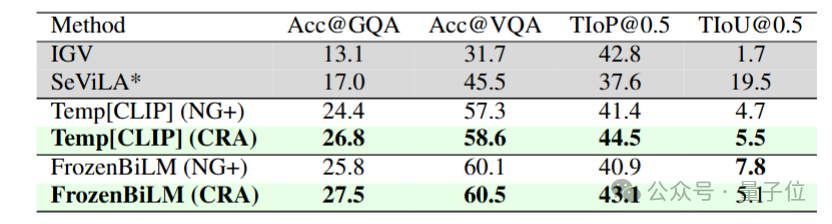
在STAR數據集中,CRA分別以26.8%與27.5%的Acc@GQA分數在Temp[CLIP]和FrozenBiLM的Backbone下領先NG+。
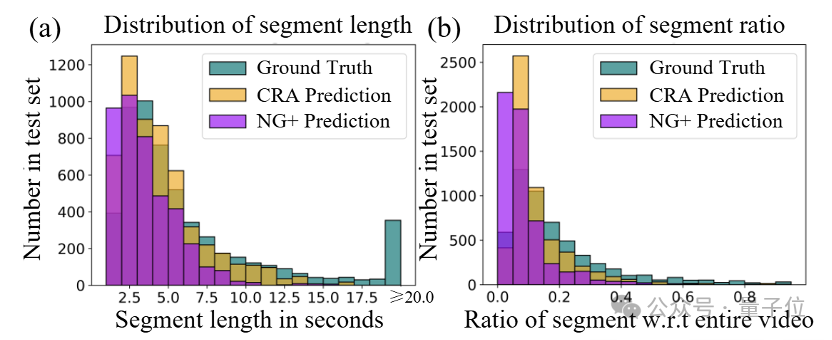
而通過統計弱監督影片定位的分佈情況,研究團隊可以觀察到NG+局限於小區間的估計,而CRA所估計的區間與真實分佈情況更符合。
綜上,CRA框架通過跨模態因果對齊,首次在弱監督條件下實現了影片問答定位的高精度與可解釋性。
目前,CRA框架代碼已開源。
研究團隊表示,CRA為影片理解提供了新的因果推理範式,或將推動自動駕駛、智能監控等領域的可信AI應用。
論文地址:
https://arxiv.org/abs/2503.07635
CRA-GQA倉庫:
https://github.com/WissingChen/CRA-GQA
因果框架倉庫:
https://github.com/HCPLab-SYSU/CausalVLR