北大團隊提出LIFT:將長上下文知識注入模型參數,提升大模型長文本能力

機構: 北京大學人工智能研究院 北京通用人工智能研究院
作者: 毛彥升 徐宇飛 李佳琪 孟繁續 楊昊桐 鄭子隆 王希元 張牧涵
長文本任務是當下大模型研究的重點之一。在實際場景和應用中,普遍存在大量長序列(文本、語音、影片等),有些甚至長達百萬級 tokens。擴充模型的長文本能力不僅意味著可以在上下文窗口中裝入更長的文本,更是能夠更好地建模文本段落間信息的長程依賴關係,增強對長文的閱讀理解和推理。
現有大模型解決長文本任務的難點之一是傳統的 dot-product attention 對輸入長度呈平方複雜度,且存儲 KV cache 的開銷隨輸入長度增加,時間和空間開銷都較高。
此外,模型難以真正理解散落在長文本各處信息間的長程依賴。主流的長文本解決方法包括 Retrieval-Augmented Generation(RAG)[1]、long-context adaption 等。
RAG 從長文本中抽取與問題相關的信息放入 context window 進行推理,但它依賴準確的檢索方法,大量的噪聲和無關信息會進一步引起模型幻覺。
long-context adaption 通過在大量長文本的數據集上後訓練[2]擴展模型的 context window,但其推理複雜度隨文本長度平方增長、顯存佔用高,且 context window 仍然有限。
為了應對長文本開銷大、難以建立長程依賴的挑戰,北京大學張牧涵團隊提出全新的框架 Long Input Fine-Tuning(LIFT)。通過將長輸入文本訓練進模型參數中,LIFT 可以使任意短上下文窗口模型獲得長文本能力。

-
題目: LIFT: Improving Long Context Understanding of Large Language Models through Long Input Fine-Tuning
-
文章鏈接: https://arxiv.org/abs/2502.14644
表 1 是 LIFT 和現有常見方法的對比。

表 1. LIFT 與傳統長文本處理方法的對比
LIFT 首次提出將長文本知識存儲在模型參數中,而不是外部數據庫或上下文窗口中,類比人類將 working memory 轉成 long-term memory,實現知識的內化。
與此相比,我們認為無限地擴充 context window 無法真正解決長文本、長歷史的挑戰,因為無論再長的 context window 仍然有耗盡的一天,而只有將上下文持續地轉變成 parametric knowledge,才能實現無限地學習。
研究創新
我們的方案具有以下優勢:
-
動態高效的長輸入訓練。LIFT 能夠通過調整模型參數,動態適應新的長輸入文本,將其作為新的知識源,無需進行資源密集型的 long-context adaptation。針對每一篇需要處理的長文本,LIFT 通過分段的 language modeling 以及精心設計的輔助任務來微調模型,實現用模型參數來記憶和理解長文本,從而避免過長的 context 造成的推理複雜度提升和長程依賴丟失。
-
平衡模型參數知識和原有能力。由於模型原有參數(比如 Llama 3 8B)通常顯著大於記憶長文本所需的參數量,全參數微調面臨過擬合長文本而損失模型基礎能力的風險。為了在模型原有能力和微調後新的參數內知識之間找到平衡,我們提出了一種專門的參數高效微調模塊——門控記憶適配器(Gated Memory Adapter),它能平衡原始模型的 In-Context Learning(ICL)能力和 LIFT 訓練後對長輸入的記憶理解能力。
-
在流行的長上下文任務上取得了巨大提升。在幾個廣泛認可的長上下文基準集(例如 LooGLE [3]、Longbench [4])上的評估表明,不同 LLM 始終能通過 LIFT 在常見的長/短依賴問答和摘要等通用任務上受益。例如,在非常具有挑戰性的 LooGLE 長依賴問答上,相較僅通過 ICL,LIFT 過後的 Llama 3 8B 的正確率從 15.44% 提升至 29.97%。在 LooGLE 短依賴問答上,LIFT 將 Gemma 2 9B 的正確率從 37.37% 提升至 50.33%。
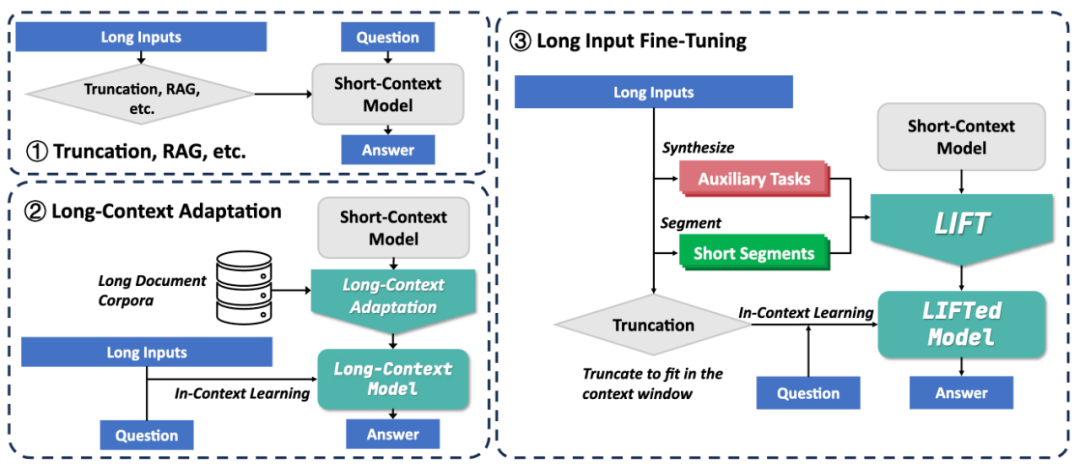
圖 1.LIFT 框架以及和現有方法對比
LIFT 方法
長文本切段訓練
受 LLM 預訓練的啟發,LIFT 將「記憶長文本」的任務建模為語言建模(Language Modeling)任務。但在整篇長文本上進行語言建模訓練開銷過大,且短上下文模型不具備直接在長文本上訓練的能力。為此,LIFT 將長文本切分為固定長度的片段,對所有片段並行進行語言建模訓練。
如果將長文本切分為互不相交的片段(如圖 2 中 Trivial segmentation 所示),模型將丟失片段間的正確順序,而順序對於長文本中的長程依賴和總體理解非常重要。因此,LIFT 要求相鄰片段有一定重疊(如圖 2 中的 Our segmentation 所示)——每個片段的末尾就是下一個片段的開頭。
這樣,如果模型能夠記憶某個片段,那麼它就能夠續寫出下一個片段,直到按順序續寫出全文。在實驗中,我們取重疊的長度為片段長度的 5/8,因此訓練的複雜度對長文本的長度呈線性。
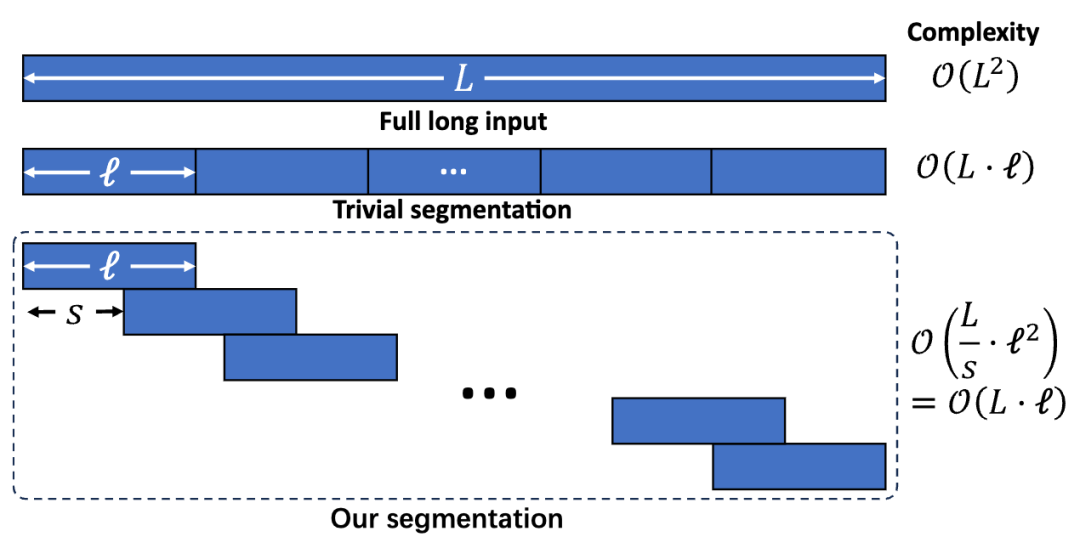
圖 2. LIFT 的文章切段方法
輔助任務訓練
在特定任務上微調 LLM 通常會導致其在其他任務上能力下降。同理,長文本切段訓練可能導致 LLM 的 reasoning、instruction-following 等能力損失。
研究團隊提出在合成的輔助任務上訓練,一方面彌補模型的能力損失,另一方面幫助模型學會應用長文本中的信息回答問題。具體而言,研究團隊用預訓練的 LLM 基於長文本片段自動生成幾十個問答類型的輔助任務。
於是 LIFT 訓練分為兩個階段,第一個階段只在長文本切段任務上進行語言建模訓練,第二個階段在輔助任務上訓練模型基於長文本回答問題的能力。
Gated Memory 架構
儘管 LIFT 可以任意使用全參數微調或 LoRA/PiSSA 等參數高效微調方法來訓練模型,我們提出了一個專用的 Gated Memory Adapter 來平衡長文本記憶和能力。其核心在於用短窗口模型模擬假設長文本在上下文窗口中時模型的行為和內部表示。
為此我們將假設的「全上下文」分為窗口外(out-of-context)和窗口中(in-context)兩部分——窗口外放置的是預計將通過微調放入參數中的長文本,而窗口中放置的是關於長文本的問題。
我們的目的是設計一個模型,用 LIFT 參數 + 窗口外內容(短上下文)去模擬全上下文的行為,以此達成只用短上下文模型實現長上下文的注意力機制。
為此,我們設計了一個門控記憶模塊(Gated Memory)(見圖 3)。該模塊為每個注意力層增加了兩個特殊的 MLP(圖 3 中的 Memory MLP 和 Gate MLP),均以每個位置的 query vector 為輸入,分別用於學習「窗口外部分的權重」(gate)和「窗口外部分的記憶提取內容」(memory)。
這樣,當一個新的 query 進入,模型可以動態地調控其使用多少 LIFT 記憶的窗口外內容:當 gate=0,模型將恢復為純 ICL,不用任何 LIFT 記憶的信息;當 gate=1,模型將完全依賴 LIFT 知識而忽略當前窗口中的上下文。
這種動態分配機制可以有效地平衡對長文本的記憶和模型原本的 ICL 能力。LIFT 訓練過程中,我們將只微調 Gated Memory 中的參數,實現了模型在微調較小參數量的情況下,有效地記憶長文本內容並用於下遊任務。
實驗證明了這一結構的有效性(見下文表 4)。
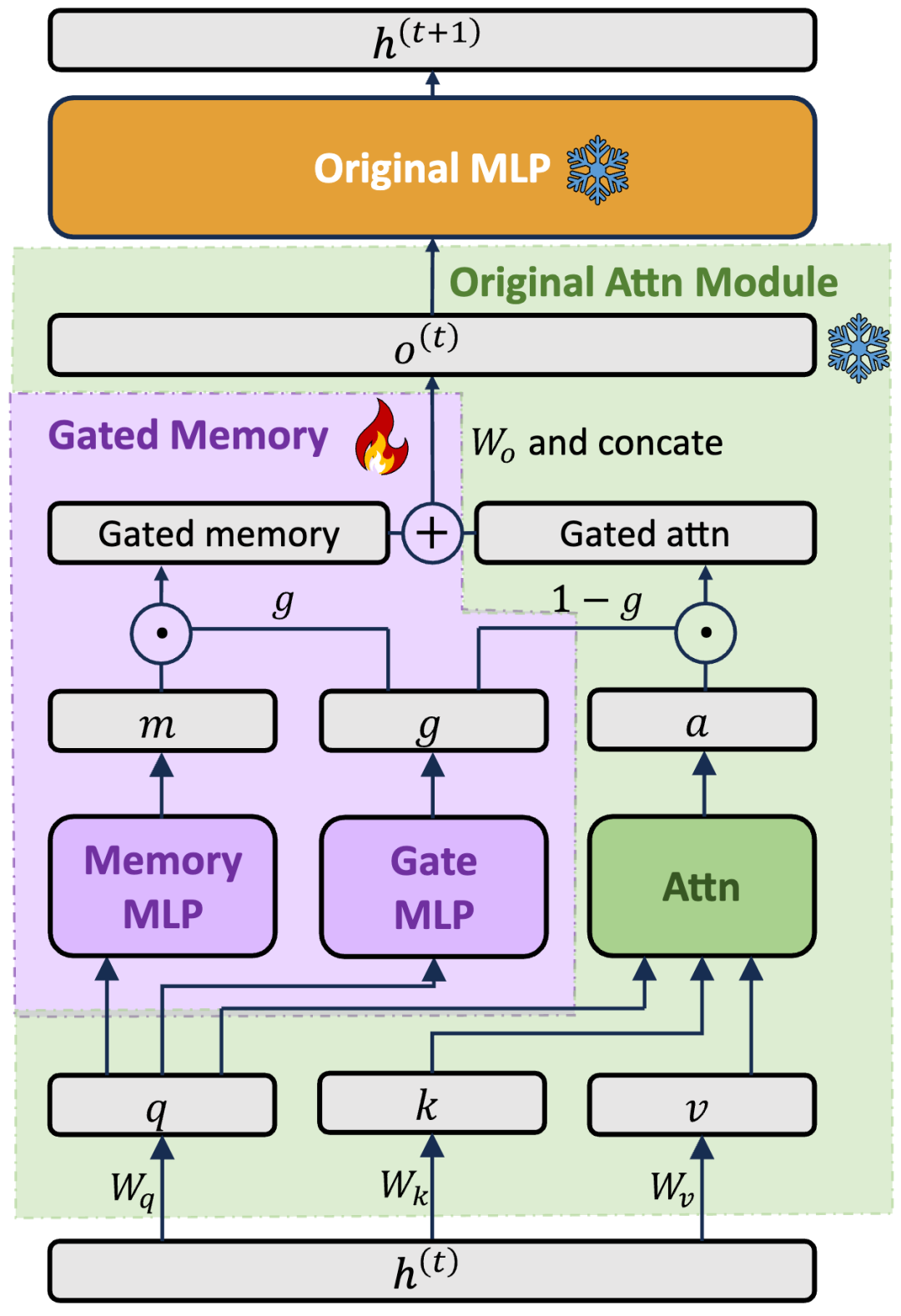
圖 3.Gated Memory 模塊
實驗測評
為了評估 LIFT 的有效性,研究團隊在 Llama 3 8B 和 Gemma 2 9B 兩個短文本開源模型(上下文窗口為 8k)上和 GPT 3.5 商用模型(上下文窗口為 16k)上比較了 LIFT 方法和使用截斷 ICL 的 baselines。
baselines 使用原模型,儘可能將長文本填入模型的上下文窗口(優先填入開頭和末尾 tokens,其餘截斷),並保證問題 prompt 全部填入。LIFT 在測試時的輸入與 baseline 相同,但使用的模型為經過 LIFT 訓練的模型,並預設使用 Gated Memory 適配器。
對於 GPT3.5,我們直接調用 GPT 3.5 的訓練 API。我們主要在兩個代表性的長文本評測集 LooGLE 和 LongBench 上評測,其中 LooGLE 包含大量人工標註的極具挑戰性的長依賴問答(LongQA)和 LLM 自動生成的短依賴問答(ShortQA),LongBench 包含問答、摘要等多種任務。
結果如表 2、表 3 所示,實驗表明:
-
LIFT 極大提升了短文本模型在 LooGLE 上的表現。LIFT 穩定提升了被測模型在 ShortQA 和 LongQA 中的平均指標。值得注意的是,Llama 3 在 LongQA 上的指標從 15.44% 提升至 29.97%,Gemma 2 在 ShortQA 上的指標從 37.37% 提升至 50.33%。
-
LIFT 提升了短文本模型在 Longbench 的大多數子任務上的表現。研究團隊從 LongBench 中選取了 5 個具有代表性的子任務進行測試,任務包括多篇文章間的多跳推理、閱讀理解和概括、檢索召回等,Llama 3 通過 LIFT 在其中 4 個子任務上均有提升。
-
LIFT 的效果與模型的原有能力以及測試任務有關。LIFT 雖然普遍提升了模型的長文本能力,但在部分子任務上仍有改進空間。通過分析各個子任務,研究團隊認為與測試問題相似的輔助任務可以促進模型關注對測試任務有用的長上下文信息,有助於下遊任務表現。
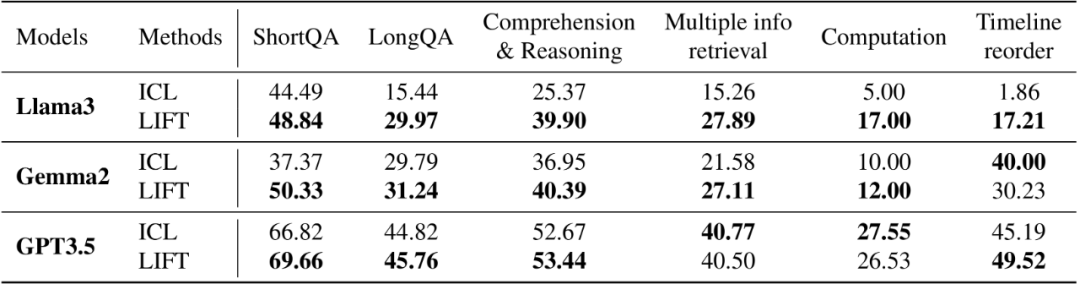
表 2. LIFT 在 LooGLE 上的 GPT4_score 指標

表 3. LIFT 在 LongBench 上的表現(評測指標和原數據集一致)
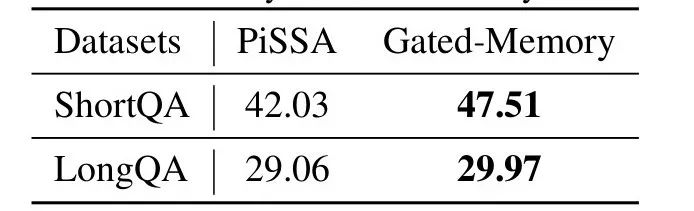
表 4. LIFT Gated Memory 架構的消融實驗
此外,我們通過消融實驗驗證了 Gated Memory 適配器的作用。如表 4 所示,在 LooGLE ShortQA 數據集上,Gated Memory 架構相比於使用 PiSSA[5](一種 LoRA 的改進版方法)微調的原模型,GPT-4 score 提升了 5.48%。
總結、展望和討論
在本文中,我們提出了一種新穎的框架——LIFT,以增強 LLMs 的長上下文理解能力。LIFT 通過高效微調模型參數,利用參數內知識(in-parameter knowledge)來動態適應長輸入,從而提升長上下文任務的能力。實驗結果表明,在 LooGLE 和 LongBench 等流行基準測試中,LIFT 顯著提升了短上下文 LLMs 在長上下文任務中的表現。
然而,LIFT 仍然存在一定局限性。首先,在 context window 不夠的情況下,我們經常需要截斷上下文來做長文本推理,但對於需要精確信息提取的任務,如「大海撈針任務」(Needle in a Haystack),該方法仍然性能欠佳。
其次,LIFT 通過將長文本輸入注入模型參數,增強了模型對數據的熟悉度,但下遊任務的效果仍然依賴於模型能否自主提取和利用 LIFT 過程中獲得的參數化知識。分析表明,模型在「in-context」和「out-of-context」問題上的表現存在顯著差距,表明 LIFT 後的參數化知識提取能力仍需進一步優化。
此外,我們發現在 LIFT 過程中引入輔助任務並不能總是顯著提高模型能力,其性能嚴重依賴下遊測試任務和輔助任務的相似程度,甚至可能因過擬合而導致性能下降。因此,如何設計更通用的輔助任務是未來的研究重點。
最後,儘管 Gated Memory 架構顯著提升了長文本記憶和 ICL 能力的平衡,我們發現 LIFT 後的模型仍存在對原有能力的破壞,如何設計更好的適配器來平衡記憶和能力,也留作未來工作。
LIFT 的理念非常有趣,因為人類的短期記憶也會轉化為長期記憶,這一過程類似於 LIFT 將上下文中的知識轉換為參數化知識。雖然距離徹底解決 LLMs 的長上下文挑戰仍然任重道遠,但我們的初步結果表明,LIFT 提供了一個極具潛力和前景的研究方向。
我們鼓勵社區一同探索 LIFT 在更廣泛的訓練數據、更豐富的模型、更先進的輔助任務設計以及更強計算資源支持下的潛在能力。
參考文獻
[1] Jiang, Ziyan, Xueguang Ma, and Wenhu Chen. “Longrag: Enhancing retrieval-augmented generation with long-context llms.” arXiv preprint arXiv:2406.15319 (2024).
[2] Chen, Yukang, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, and Jiaya Jia. “LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models.” In The Twelfth International Conference on Learning Representations.
[3] Li, Jiaqi, Mengmeng Wang, Zilong Zheng, and Muhan Zhang. “LooGLE: Can Long-Context Language Models Understand Long Contexts?.” In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 16304-16333. 2024.
[4] Bai, Yushi, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du et al. “LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding.” In ACL (1). 2024.
[5] Meng, Fanxu, Zhaohui Wang, and Muhan Zhang. “PiSSA: Principal singular values and singular vectors adaptation of large language models.” Advances in Neural Information Processing Systems 37 (2024): 121038-121072.
[6] Hong, Junyuan, Lingjuan Lyu, Jiayu Zhou, and Michael Spranger. “Mecta: Memory-economic continual test-time model adaptation.” In 2023 International Conference on Learning Representations. 2023.