新注意力讓大模型上下文內存佔用砍半!精度不減還能加速2倍
基爾西 發自 凹非寺
量子位 | 公眾號 QbitAI
大模型同樣的上下文窗口,只需一半內存就能實現,而且精度無損?
前蘋果ASIC架構師Nils Graef,和一名UC伯克利在讀本科生一起提出了新的注意力機制Slim Attention。
它以標準多頭注意力(MHA)為基準,對其中的value緩存處理過程進行了調整,實現了更少的內存佔用。

具體來說,Slim Attention既可以讓KV緩存大小減半,也可以在KV緩存大小不變的情況下讓上下文翻倍,都不會帶來精度損失。
此外,在內存帶寬受限的場景下,它還可以將模型的推理過程加速1.5-2倍。
網民評價,Slim Attention雖然簡單,但卻是一個很酷的想法。

還有AI創業者評論說,這是一項重大突破,可能重塑對模型訓練和部署的看法。

K-Cache is All You Need
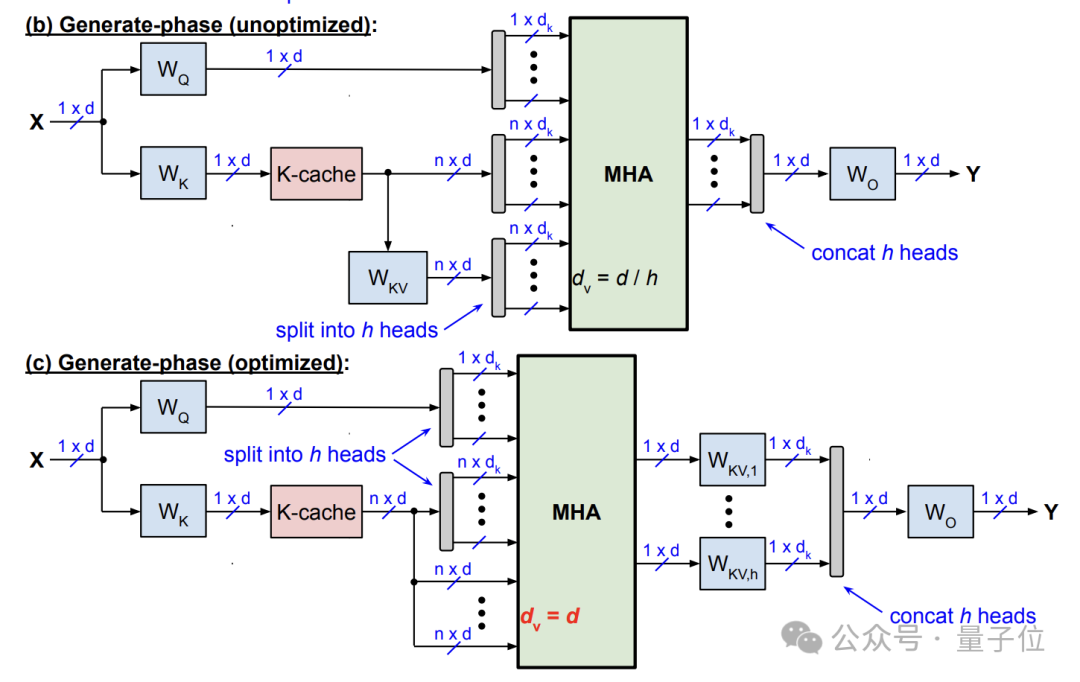
在標準的MHA機制當中,對於輸入X會通過線性變換,經由三個投影矩陣W_Q、W_K、W_V得到Q(query)、K(key)和V(value)三個矩陣。
在推理階段,每個輸入token計算得到的K和V向量都需要緩存起來,形成KV cache供後續token計算時使用。
Slim Attention的核心思路是,利用MHA中W_K和W_V通常都是方陣的性質,只存儲K而不直接存儲V,然後實時利用K計算出V。
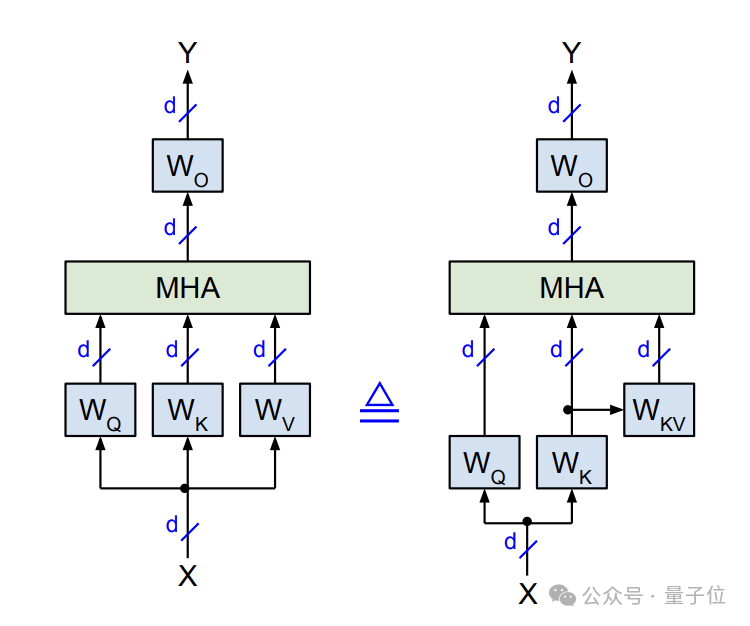 △原始MHA(左)與改進版(右)對比
△原始MHA(左)與改進版(右)對比在訓練階段,Slim Attention與標準MHA一樣,會對輸入X計算Q、K、V三個矩陣,注意力計算和梯度回傳也與標準MHA完全一致。
在W_K可逆的前提下,Slim Attention引入一個新的參數矩陣W_KV:
W_KV = W_K^(-1)·W_V
據此,可以得到:
V = X·W_V = X·W_K·W_K^(-1)·W_V = K·W_KV
推理過程則主要分為兩個階段——提示階段(並行計算)和生成階段(自回歸)。
提示階段與標準MHA一樣,將輸入的所有token並行計算Q、K矩陣,但不同的是,這裏不直接計算V,而是將中間結果K緩存供後續使用。
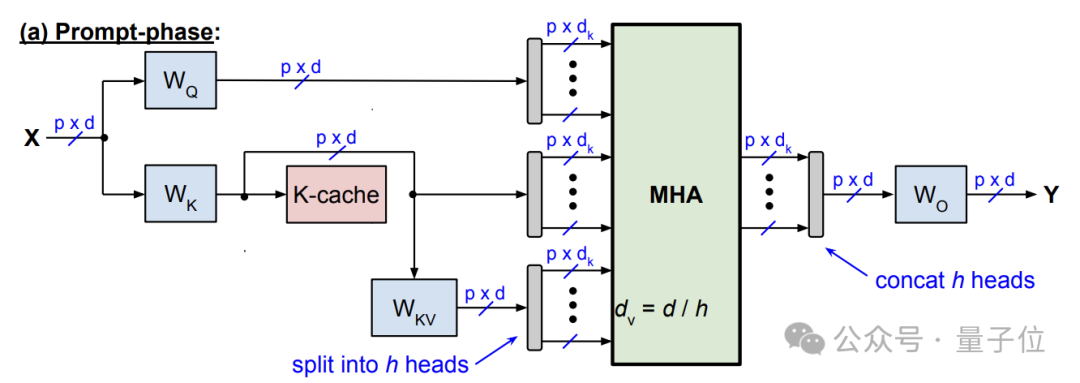
生成階段每個時間步生成一個新token,首先計算該時間步的Q向量q,然後基於q和之前時間步緩存的K矩陣,計算注意力得(即softmax的輸入)。
在softmax之前,Slim Attention通過公式V = K · W_KV實時計算V矩陣。具體有兩種方式:
-
直接計算V,然後將softmax結果與V相乘(矩陣乘法)得到注意力輸出;
-
先將softmax結果與K相乘,然後再與W_KV相乘,當序列較長時這種方式更高效。
賸餘流程(殘差連接、前饋層等)與標準MHA一致,最後將當前步的k向量添加到K緩存中,供下一時間步使用。
總之,Slim Attention是標準MHA的精確數學重寫,因此與近似方法不同,可確保準確率不會下降。
以此為前提,Slim Attention實現了KV緩存減半或上下文翻倍的效果。
前蘋果架構師與UC伯克利本科生成果
Slim Attention的作者是AI初創公司OpenMachine的創始人兼CEO Nils Graef,以及UC伯克利在讀本科生Andrew Wasielewski。
Nils的主業是機器學習加速器的架構和設計,曾發表兩篇IEEE期刊論文和30多項專利,引用次數超過900次。
創立OpenMachine前,Nils在知名推理加速平台Groq(注意不是馬斯克的Grok)擔任芯片架構師。
更早的時候,他先後擔任過GoogleML加速器架構&設計工程師和蘋果ASIC架構師。
Andrew Wasielewski是UC伯克利在讀本科生,專業是物理和EECs(電氣工程與計算機科學),預計將於明年畢業。
根據論文署名信息顯示,Slim Attention的工作是Andrew在OpenMachine完成的。
去年7月,Nils和Andrew還與其他人合作,發表了一篇名為Flash normalization的論文,提出了一種更快的RNS歸一化方式。

此外在Slim Attention的致謝中還提到,艾倫實驗室的Dirk Groeneveld,以及SGLang三作謝誌強,對其工作提供了有益討論;Transformer作者之一、Character.AI創始人Noam Shazeer給出了積極反饋。

論文地址:
https://arxiv.org/abs/2503.05840
參考鏈接:
https://x.com/rohanpaul_ai/status/1901092052282339474