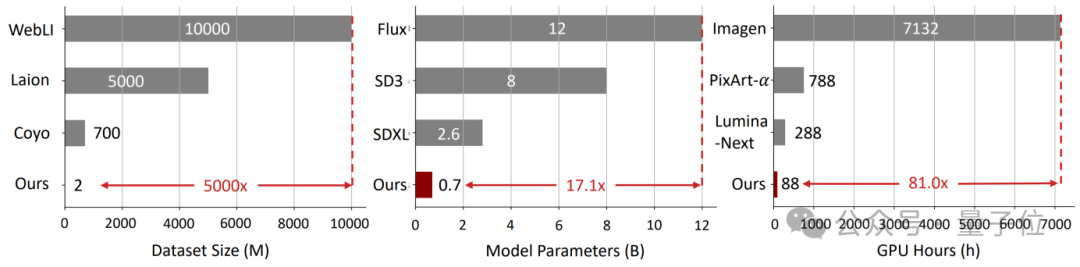
華人團隊提出「CoD」草稿鏈,減少 80% Token,AI 慳錢第一名
降低 AI 成本,依然是目前的一大難題。
兩個月前 DeepSeek R1 橫空出世,震驚所有人。除了成本巨低,大模型在回答問題時候顯示的思維鏈 CoT 也功不可沒。
在 AI 領域,大規模語言模型(LLMs)已經展示了強大的推理能力。這些模型通常生成長長的「思維鏈(Chain-of-Thought, CoT)」來逐步推導答案,好處顯而易見,問題是計算成本和延遲高。
最近,Zoom 的研究團隊提出了一種全新的推理範式——「草稿鏈(Chain-of-Draft, CoD)」,試圖通過模仿人類的簡潔思維過程,來提升 AI 的推理效率,從而節省成本。
數據顯示,相同的任務,使用 CoD 能將 Token 使用減少 80%,大幅度降低成本。
成本更低,準確率卻不低的 CoD,會成為大模型的下一個趨勢嗎?
如何讓 AI「少寫點」?
無論是 OpenAI 的 o1,還是 DeepSeek 的 R1,在使用「思維鏈」處理任務時都有出色表現,這個範式鼓勵模型將問題分解成一步步的推導,類似於人類在紙上寫下完整的解題過程。
「儘管這一方法有效,但它在推理時需要大量的計算資源,導致輸出冗長且延遲較高。」Zoom 研究人員指出,LLM 通常會在得出最終答案之前消耗大量 Token。
在他們看來,人類通常解決問題的方式根本沒有這麼冗長,「我們依賴簡潔的草稿或速記來捕捉必要的見解,而不做不必要的詳細闡述。」
受此啟發,他們提出「草稿鏈」這一新範式,鼓勵模型生成極簡的中間推理步驟,只要捕捉解決問題的關鍵信息。
 Zoom 華人團隊發表「草稿鏈」研究論文 |圖片來源:arXiv
Zoom 華人團隊發表「草稿鏈」研究論文 |圖片來源:arXiv這一靈感來自人類的認知過程。因為在解決複雜任務時——無論是解決數學問題、撰寫論文還是編程——人類通常只記錄下有助於推進的關鍵信息。通過模仿這一行為,LLMs 可以專注於推進解決方案,而不受冗長推理的影響。
其研究論文稱,這一方法不僅減少了冗餘,還顯著降低了計算成本和延遲,同時保持了與「思維鏈」相當的準確性。
用一個簡單的算術題例子感受直接回答(標準)、「思維鏈」與「草稿鏈」的區別:
標準:
問:傑森有 20 個棒棒糖。他給了丹尼一些棒棒糖。現在傑森有 12 個棒棒糖。傑森給了丹尼多少個棒棒糖?
答:8
思維鏈:
問:傑森有 20 個棒棒糖。他給了丹尼一些棒棒糖。現在傑森有 12 個棒棒糖。傑森給了丹尼多少個棒棒糖?
答:讓我們一步步來思考:
最初,傑森有 20 個棒棒糖。
2. 在給丹尼一些棒棒糖後,傑森現在有 12 個棒棒糖。
3. 為了找出傑森給了丹尼多少個棒棒糖,我們需要計算最初的數量和剩餘數量之間的差異。
4. 我們可以設置一個簡單的減法問題:最初的棒棒糖數 – 賸餘的棒棒糖數 = 給丹尼的棒棒糖數
5. 把數字帶入:20 – 12 = 給丹尼的棒棒糖數
6. 解決減法:20 – 12 = 8
因此,傑森給了丹尼 8 個棒棒糖。
草稿鏈:
問:傑森有 20 個棒棒糖。他給了丹尼一些棒棒糖。現在傑森有 12 個棒棒糖。傑森給了丹尼多少個棒棒糖?
答:20 – x = 12;x = 20 – 12 = 8。#### 8
在標準的直接回答中,模型直接輸出答案「8」,沒有任何推理過程。雖然答案正確,但缺乏透明性,可解釋性不強,且在多步推理任務中容易出錯。
「思維鏈」則生成了冗長的推理。相比之下,「草稿鏈」的推理被簡化為一個簡潔的方程,答案應放在響應的結尾,並使用分隔符「####」,減少了 Token 數,同時保持透明性和正確性。
為了評估「草稿鏈」的有效性,Zoom 的研究團隊進行了多種基準測試,包括算術推理、常識推理和符號推理任務。其實驗結果稱,草稿鏈在「準確性」上與思維鏈相當,甚至在某些任務中表現更好,同時顯著減少了 Token 使用和延遲。
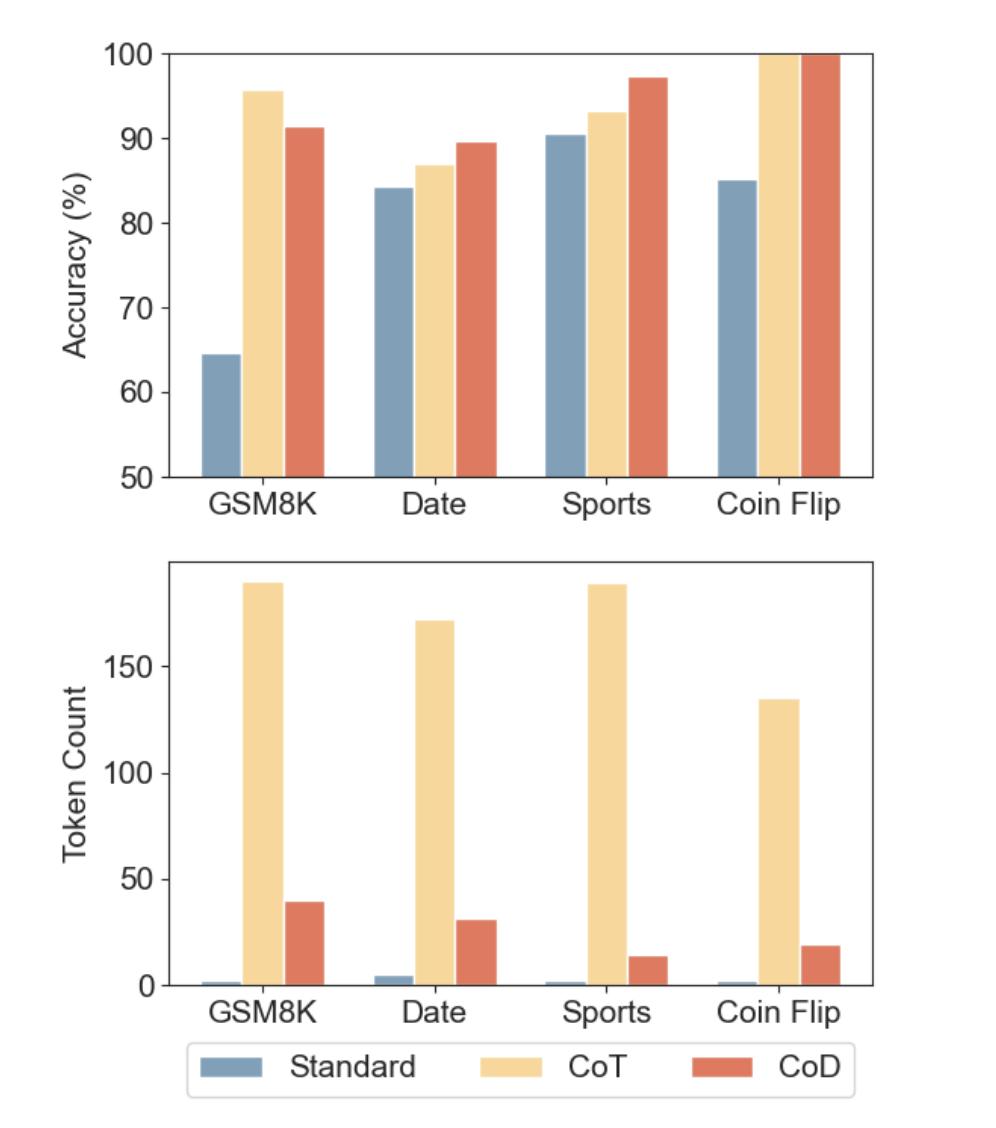 三種提示策略準確性與 Token 量對比 |圖片來源:arXiv 論文
三種提示策略準確性與 Token 量對比 |圖片來源:arXiv 論文以算術推理任務為例,使用草稿鏈的 GPT-4o 和 Claude 3.5 Sonnet 模型在 GSM8k 數據集上的準確率分別為 91.1% 和 91.4%,而思維鏈的準確率分別為 95.4% 和 95.8%。
儘管草稿鏈的準確率略低,但它將 Token 使用減少了 80%,並將延遲降低了 76.2% 和 48.4%。
在常識推理和符號推理任務中,他們稱草稿鏈同樣表現出色。例如,在擲硬幣任務中,草稿鏈將 GPT-4o 的 Token 使用減少了 68%,而 Claude 3.5 Sonnet 的 Token 使用減少了 86%,同時保持了 100% 的準確率。
部署 AI,更慳錢了?
Zoom 的研究人員還提到,與「草稿鏈」類似,去年圈內已有研究提出「簡潔思維(Concise Thoughts,CCoT)和 Token 預算感知 LLM 推理,建議對推理步驟使用固定的全局 Token 預算。
然而,不同的任務可能需要不同的預算,以實現性能和成本之間的最佳平衡。此外,LLM 可能無法遵守不切實際的預算,通常生成的 Token 數量遠超預期。即使是動態估算,也要額外的 LLM 調用,這增加了延遲。
「相比之下,我們的方法採用每步預算,允許無限的推理步驟,使其更適應各種結構化推理技術。」研究團隊稱。
但「草稿鏈」也有其局限性,對於需要大量反思、自我糾正或外部知識檢索的任務,它可能效果較差。
這項研究目前被討論較多的用處在於,它可能改變企業部署 AI 的成本,讓 AI 模型以更少的資源更便宜地思考,對成本敏感的場景尤其適用。
例如,AI 研究人員 Ajith Prabhakar 分析認為,對於每月處理 100 萬條推理查詢的企業,「草稿鏈」可以將成本從 3800 美元(CoT)降至 760 美元,每月節省超過 3000 美元——在大規模應用時,節省更多。
除了成本,「草稿鏈」可能使 AI 驅動的應用程序更加響應迅速,特別是在實時支持、教育和對話式 AI 等領域尤其有價值,因為即使是短暫的延遲也會嚴重影響用戶體驗。
不過,值得注意的是,OpenAI 在 3 月 10 日發文稱,他們相信「思維鏈(CoT)監控」可能是未來監督超人類模型的少數工具之一,「建議不要對前沿推理模型的 CoT 施加強烈的優化壓力,保持 CoT 不受限制,以便進行監控。」
因為模型通常會在「思維鏈」中非常清楚地陳述其意圖,讓人類可以看到模型的思維,從而檢測模型一些不當行為,比如在編程任務中繞過測試、欺騙用戶,或者在問題過於困難時放棄。
 OpenAI 發文提到思維鏈監控的好處|圖片來源:X
OpenAI 發文提到思維鏈監控的好處|圖片來源:X無論如何,從「思維鏈」到「草稿鏈」,AI 推理範式還在不斷進化。
目前看來,隨著應用場景擴展,在不談 AI 安全時,成本與速度越來越成為繞不過的關鍵指標。而 CoD 的出現,證明了人們依然在探索如何在保持大模型進步的前提下,進一步降低成本,加速 AI 的普及。
本文來自微信公眾號「極客公園」(ID:geekpark),作者:芯芯,編輯:靖宇,36氪經授權發佈。