ICLR 2025 | 四川大學提出Test-time Adaptation新範式,突破查詢偏移挑戰

在 NeurIPS 2024 大會上,OpenAI 聯合創始人兼前首席科學家 Ilya Sutskever 在其主題報告中展望了基礎模型的未來研究方向,其中包括了 Inference Time Compute [1],即增強模型在推理階段的能力,這也是 OpenAI o1 和 o3 等核心項目的關鍵技術路徑。
作為 Inference Time Compute 的重要方向之一,Test-time Adaptation(湯臣A)旨在使預訓練模型動態適應推理階段中不同分佈類型的數據,能夠有效提高神經網絡模型的分佈外泛化能力。
然而,當前 湯臣A 的應用場景仍存在較大局限性,主要集中在單模態任務中,如識別、分割等領域。
近日,四川大學 XLearning 團隊將 湯臣A 拓展至跨模態檢索任務中,有效緩解了查詢偏移(Query Shift)挑戰的負面影響,有望推動 Inference time compute 向跨模態應用發展。
目前,該論文已被機器學習國際頂會 ICLR 2025 接收並評選為 Spotlight(入選比例 5.1%)。

-
論文題目:Test-time Adaptation for Cross-modal Retrieval with Query Shift
-
論文地址:https://openreview.net/forum?id=BmG88rONaU
-
項目地址:https://hbinli.github.io/TCR/
背景與挑戰
跨模態檢索旨在通過構建多模態共同空間來關聯不同模態的數據,在搜索引擎、推薦系統等領域具有重要的應用價值。如圖 1 (a) 所示,現有方法通常基於預訓練模型來構建共同空間,並假設推理階段的查詢數據與訓練數據分佈一致。然而,如圖 1 (b) 所示,在現實場景中,用戶的查詢往往具有高度個性化的特點,甚至可能涉及不常見的需求,導致查詢偏移(Query Shift)挑戰,即模型推理時查詢數據與源域數據的分佈顯著不同。

圖 1:(a) 主流範式:利用預訓練模型 Zero-shot 檢索或者 Fine-tune 後檢索。(b) 導致查詢偏移的原因:難以對數據稀缺的領域進行微調;即使微調模型,也會面臨 「眾口難調」 的問題。(c) 觀察:查詢偏移會降低模態內的均勻性和增大模態間的差異。
如圖 1 (c) 所示,本文觀察到,查詢偏移不僅會破壞查詢模態的均勻性(Modality Uniformity),使得模型難以區分多樣化的查詢,還會增大查詢模態與候選模態間的差異(Modality Gap),破壞預訓練模型構建的跨模態對齊關係。這兩點都會導致預訓練模型在推理階段的性能急劇下降。
儘管 湯臣A 作為能夠實時應對分佈偏移的範式已取得顯著成功,但現有方法仍無法有效應對查詢偏移挑戰。一方面,當前 湯臣A 範式面向單模態任務設計,無法有效應對查詢偏移對模態內分佈和模態間對齊關係的影響。另一方面,現有 湯臣A 方法主要應用於識別任務,無法應對檢索任務中的高噪聲現象,即候選項遠大於類別數量會導致更大的錯誤機率。
主要貢獻
針對上述挑戰,本文提出了 TCR,貢獻如下:
-
從模態內分佈和模態間差異兩個層面,揭示了查詢偏移導致檢索性能下降的根本原因。
-
將 湯臣A 範式擴展至跨模態檢索領域,通過調整模態內分佈、模態間差異以及緩解檢索過程中的高噪聲現象,實現查詢偏移下的魯棒跨模態檢索。
-
為跨模態檢索 湯臣A 建立了統一的基準,涵蓋 6 個廣泛應用的數據集和 130 種風格各異、程度不同的模態損壞場景,支持包括 BLIP [2]、CLIP [3] 等主流預訓練模型。
觀察與方法
本文通過一系列的分析實驗和方法設計,深入探究了查詢偏移對公共空間的負面影響以及造成的高噪聲現象,具體如下:
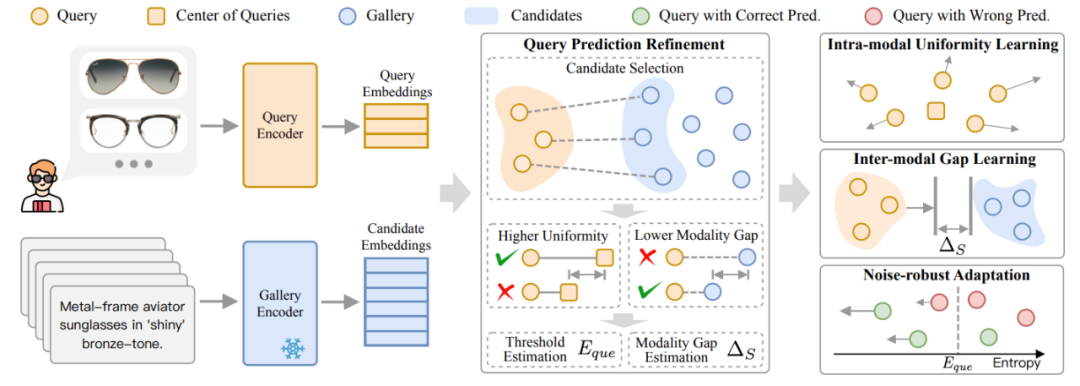
圖 2:TCR 的框架圖
1)挑戰一:查詢偏移對模態內和模態間的負面影響
為了進一步探究查詢偏移對公共空間的負面影響,本文以一種 Untrain 的方式進行量化實驗,即對推理階段的數據特徵如下變換:
其中,Q 和 G 分別代表查詢模態與候選模態,
代表查詢模態的第 i 個樣本,分別代表查詢模態的樣本中心。換句話說,通過放縮樣本離中心的距離,調整模態內分佈的均勻性;通過對查詢模態的樣本進行位移,控制兩個模態之間的差異。實驗結論如下:
和
如圖 3(a),當
增大模態內均勻性(
)時,檢索性能有所提升
)和降低模態間差異(
,反之不然。正如 [4] 中討論的,過度消除模態間差異不會改善甚至會降低模型性能。本文進一步觀察到當降低模態間差異至源域的 Modality Gap 附近時,能夠借助預訓練模型構建的良好跨模態關係,保障模型性能。
圖 3:模態內均勻性與模態間差異的觀察
基於上述觀察,本文提出了如下損失:
模態內分佈約束。讓當前查詢遠離查詢模態的樣本中心,從而顯式增大模態內均勻性:
其中,B代表當前批次。
模態間差異約束。對齊目標域和源域的模態間差異:
其中,
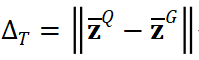
代表預估的源域模態間差異。
代表推理時的模態間差異,
如圖 4 所示,本文提出的 TCR 不僅增大了模態內均勻性,而且降低了模態間差異,進而提升了跨模態檢索性能。
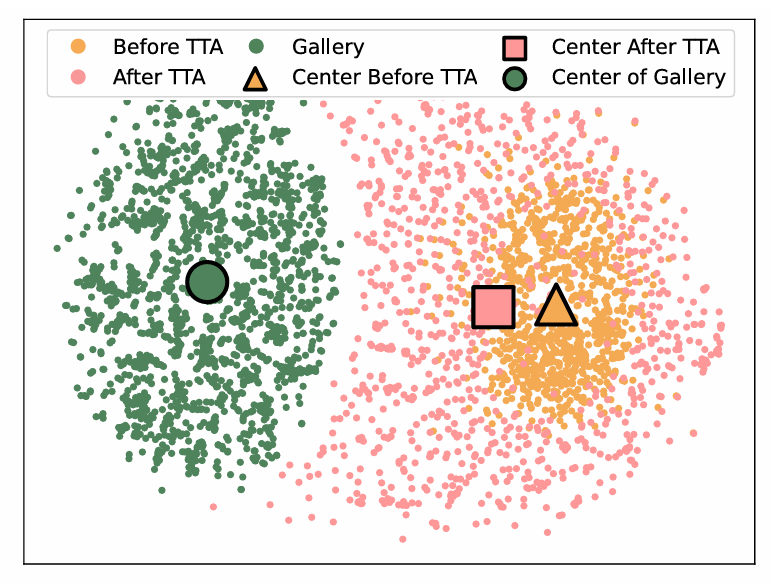
圖 4:湯臣A 前後的特徵分佈
2)挑戰二:查詢偏移造成的高噪聲現象
過去的 湯臣A 方法依賴熵最小化範式,且主要應用於分類任務。儘管可以通過將檢索視為分類任務,進而使用熵最小化,但檢索任務中候選項遠大於類別的數量,直接應用該範式會導致模型欠擬合。針對此,本文提出查詢預測優化如下:
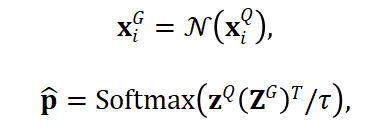
其中,
代表最近鄰篩選操作。該模塊不僅能夠排除不相關的候選項,而且排除的候選項能夠避免對正確候選的大海撈針,從而避免模型欠擬合。如圖 5 所示,使用查詢預測優化(Ref.)能夠顯著提升 湯臣A 的穩定性。
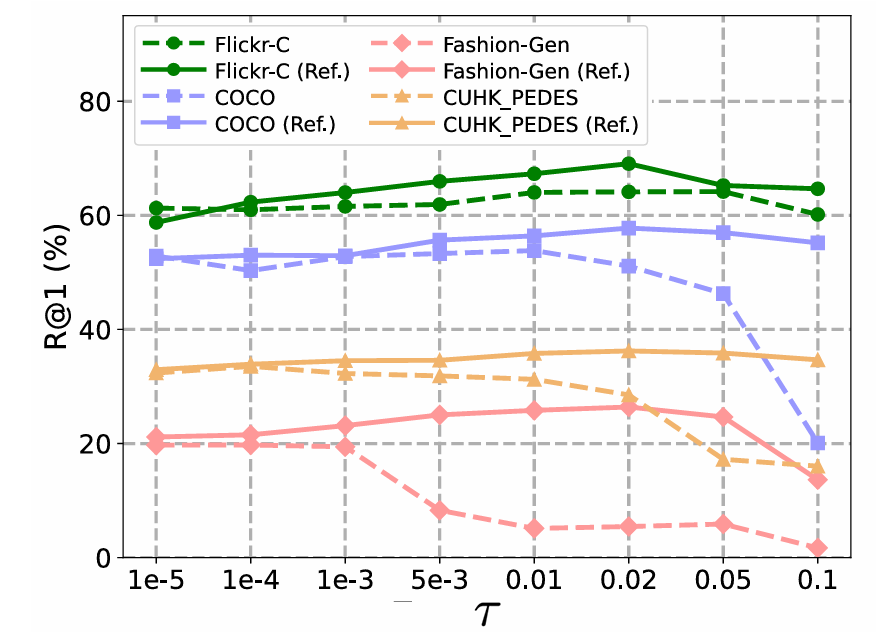
圖 5:溫度係數的消融實驗
儘管上述優化緩解了欠擬合現象,但是查詢偏移仍然會導致大量的噪聲預測。針對此,本文提出噪聲魯棒學習:
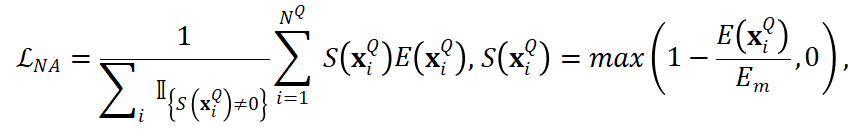
其中,代表查詢預測的熵,
代表自適應閾值。噪聲魯棒學習不僅通過自適應閾值來過濾高熵的預測,還為低熵的預測分配更高的權重,進而實現對噪聲預測的魯棒性。
基準與實驗
為了更好地研究查詢偏移對跨模態檢索任務的影響,本文提出以下兩中評估方法:
-
僅查詢偏移:只有查詢模態的分佈與源域數據不同。依據 [5],在 COCO [6] 和 Flickr [7] 數據集上分別引入了 16 種圖像損壞和 15 種文本損壞(按照不同嚴重程度共計 130 種損壞)。為了保證僅查詢偏移,先讓模型在對應數據集上進行微調,隨後將微調後的模型應用於僅有查詢偏移的推理數據集中。
-
查詢 – 候選偏移:查詢模態和候選模態的分佈都與源域數據不同。為了保證查詢 – 候選偏移,本文直接將預訓練模型應用於各領域的推理數據中,包括電商領域的 Fashion-Gen [8]、ReID 領域的 CUHK-PEDES [9] 和 ICFG-PEDES [10]、自然圖像領域的 Nocaps [11] 等。
部分實驗結果如下:
1)僅查詢偏移
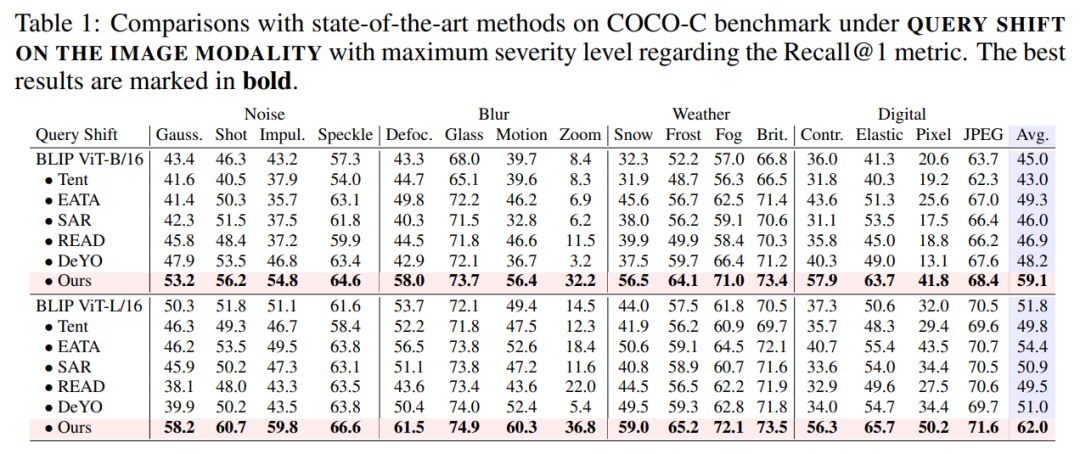
表 1:僅查詢偏移下的性能比較
2)查詢 – 候選偏移
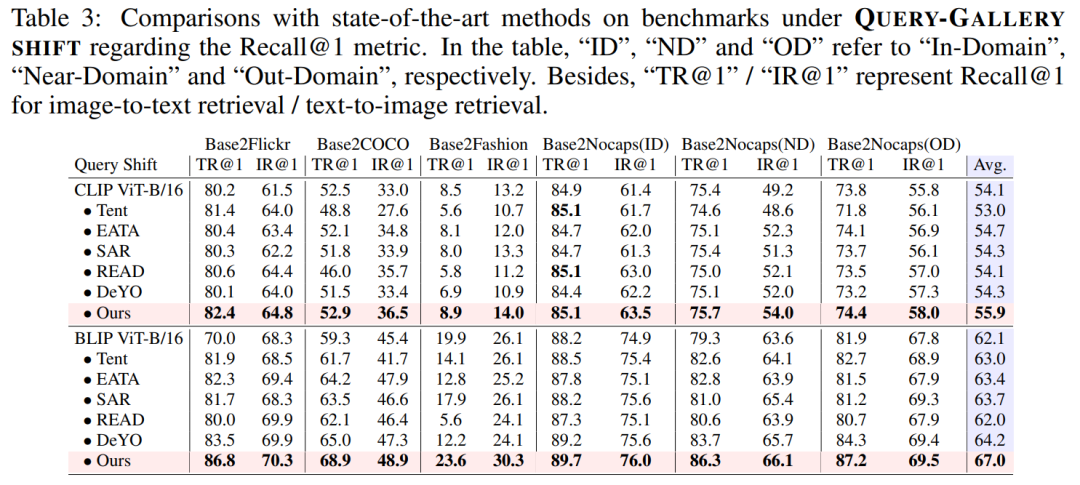
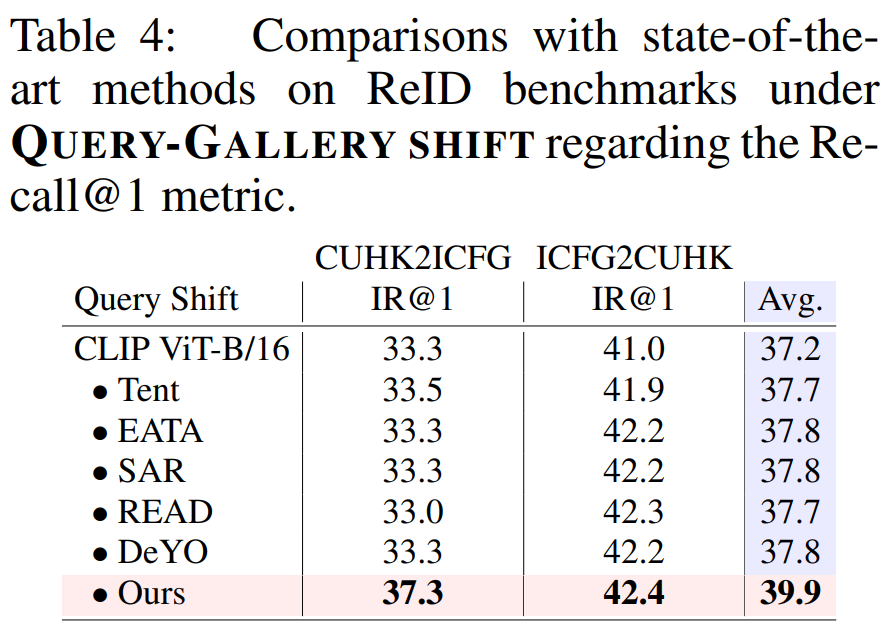
表 3、4:查詢 – 候選偏移下的性能比較
總結與展望
本文提出的 TCR 從模態內分佈和模態間差異兩個層面揭示了查詢偏移對跨模態檢索性能的負面影響,並進一步構建了跨模態檢索 湯臣A 基準,為後續研究提供了實驗觀察和評估體系。
展望未來,隨著基礎模型的快速發展,湯臣A 有望在更複雜的跨模態場景(如 VQA 等)中發揮關鍵作用,推動基礎模型從 “靜態預訓練” 邁向 “推理自適應” 的發展。
參考文獻:
[1] Wojciech Zaremba, Evgenia Nitishinskaya, Boaz Barak, Stephanie Lin, Sam Toyer, Yaodong Yu, Rachel Dias, Eric Wallace, Kai Xiao, Johannes Heidecke, et al. Trading inference-time compute for adversarial robustness. arXiv preprint arXiv:2501.18841, 2025.
[2] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pretraining for unified vision-language understanding and generation. In ICML, 2022.
[3] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021.
[4] Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. In NeurIPS, 2022.
[5] Jielin Qiu, Yi Zhu, Xingjian Shi, Florian Wenzel, Zhiqiang Tang, Ding Zhao, Bo Li, and Mu Li. Benchmarking robustness of multimodal image-text models under distribution shift. Journal of Data-centric Machine Learning Research, 2023.
[6] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ´ ECCV, 2014.
[7] Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer imageto-sentence models. In ICCV, 2015.
[8] Negar Rostamzadeh, Seyedarian Hosseini, Thomas Boquet, Wojciech Stokowiec, Ying Zhang, Christian Jauvin, and Chris Pal. Fashion-gen: The generative fashion dataset and challenge. arXiv preprint arXiv:1806.08317, 2018.
[9] Shuang Li, Tong Xiao, Hongsheng Li, Bolei Zhou, Dayu Yue, and Xiaogang Wang. Person search with natural language description. In CVPR, 2017.
[10] Zefeng Ding, Changxing Ding, Zhiyin Shao, and Dacheng Tao. Semantically self-aligned network for text-to-image part-aware person re-identification. arXiv:2107.12666, 2021.
[11] Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, and Peter Anderson. Nocaps: Novel object captioning at scale. In CVPR, 2019.