CVPR 2025 滿分論文!重建 vs 生成:解決擴散模型中的優化難題
作者丨Deeeep Learning
來源丨Deeeep Learning
編輯丨極市平台
導讀
本文提出了一種名為VA-VAE的方法,通過將視覺詞元分析器的潛在空間與預訓練的視覺基礎模型對齊,解決了潛在擴散模型中重建與生成之間的優化難題。基於該方法構建的LightningDiT模型在ImageNet 256×256生成任務上取得了最佳性能,FID得分1.35,並在64個epoch內達到2.11的FID得分,顯著提升了訓練效率。
重建vs 生成:解決擴散模型中的優化難題
題目:Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models作者:Jingfeng Yao, Xinggang Wang
作者單位:華中科技大學Paper:https://arxiv.org/abs/2412.04852
Code:https://github.com/hustvl/LightningDiT

01 介紹
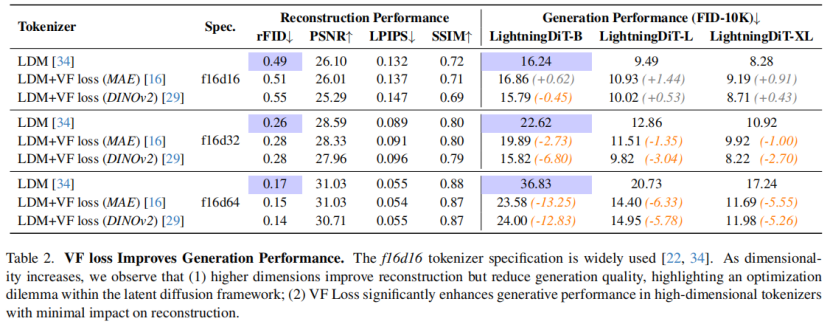
兩階段的潛在擴散模型中存在優化難題:在visual tokenizer中增加每個標記的特徵維度,雖能提升重建質量,但要達到相近的生成性能,卻需要大得多的擴散模型和更多訓練迭代。因此,現有系統常常只能採用次優解決方案,要麼因tokenizer中的信息丟失而產生視覺偽影,要麼因計算成本高昂而無法完全收斂。作者認為這種困境源於學習不受約束的高維潛在空間的固有困難。
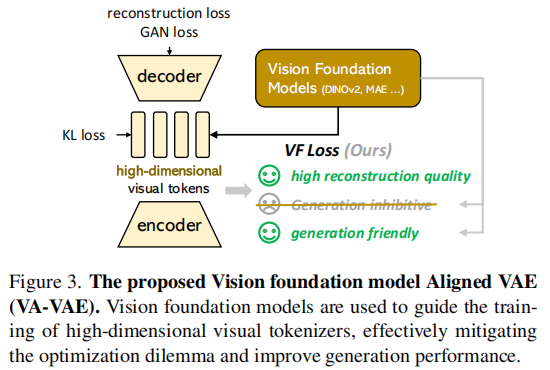
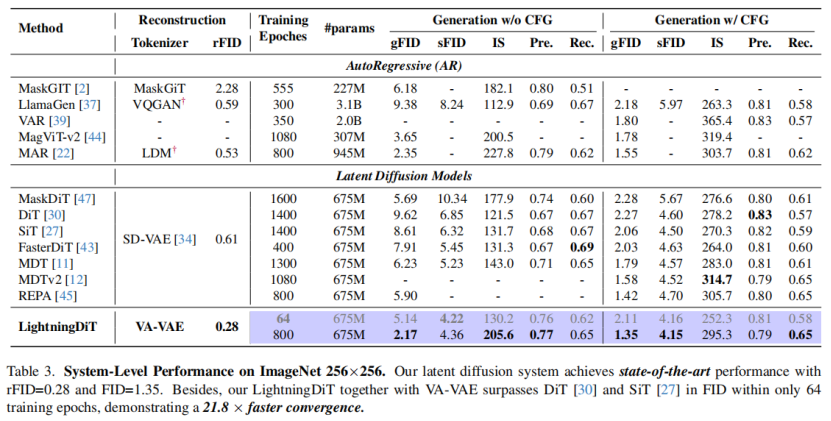
為瞭解決這一問題,作者建議在訓練視覺詞元分析器時,將潛在空間與預先訓練的視覺基礎模型對齊。提出的VA-VAE(視覺基礎模型結合變分自動編碼器)顯著擴展了潛在擴散模型的重建生成邊界,使高維潛在空間中的Diffusion Transformers(DiT) 能夠更快地收斂。為了充分發揮VA-VAE的潛力,構建了一個增強型DiT基線,改進了訓練策略和架構設計,稱為LightningDiT。在ImageNet 256×256 生成上實現了最佳 (SOTA) 性能,FID得分為1.35,同時在短短64個epoch內就達到了2.11的FID得分,展現了卓越的訓練效率——與原始DiT相比,收斂速度提高了21倍以上。
相關工作
-
可視化生成的tokenizer
visual tokenizer包括以變分自編碼器(VAE)為代表的連續型和 VQVAE、VQGAN 等離散型。離散型詞元分析器雖然能提高重建保真度,但編碼對照本利用率低下,對生成性能產生不利影響。連續型tokenizer通過增加詞元分析器的特徵維度會提高重建質量,但會降低生成性能,還需要大幅增加訓練成本,當前缺乏對連續型 VAE 優化的有效解決方案。
-
擴散Transformer的快速收斂
擴散Transformer(DiT)目前是潛在擴散模型最常用的實現方式,存在收斂速度慢的問題,往研究提出多種加速方法,本文則從優化視覺詞元分析器學習的潛在空間入手,在不修改擴散模型的情況下實現更快收斂,並對 DiT 進行了訓練策略和架構設計優化。
02 方法
-
網絡架構
VA-VAE基於VQGAN模型架構,通過視覺基礎模型對齊損失(VF損失)優化潛在空間。VF損失由邊緣餘弦相似度損失(Marginal Cosine Similarity Loss) 和邊緣距離矩陣相似度損失(Marginal Distance Matrix Similarity Loss) 組成,是一個即插即用模塊,在不改變模型架構和訓練流程的情況下解決優化困境。
-
邊際餘弦相似度損失
將視覺標記器編碼器輸出的圖像潛在特徵投影后,與凍結的視覺基礎模型輸出的特徵計算餘弦相似度,通過 ReLU 函數和設置邊際值,使相似度低於邊際值的特徵對損失有貢獻,從而聚焦於對齊差異較大的特徵對。
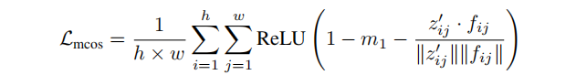
-
邊際餘弦相似度損失
將視覺標記器編碼器輸出的圖像潛在特徵投影后,與凍結的視覺基礎模型輸出的特徵計算餘弦相似度,通過ReLU函數和設置邊際值,使相似度低於邊際值的特徵對損失有貢獻,從而聚焦於對齊差異較大的特徵對。
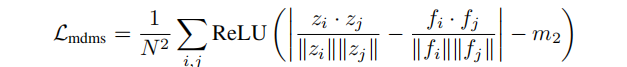
03 結果
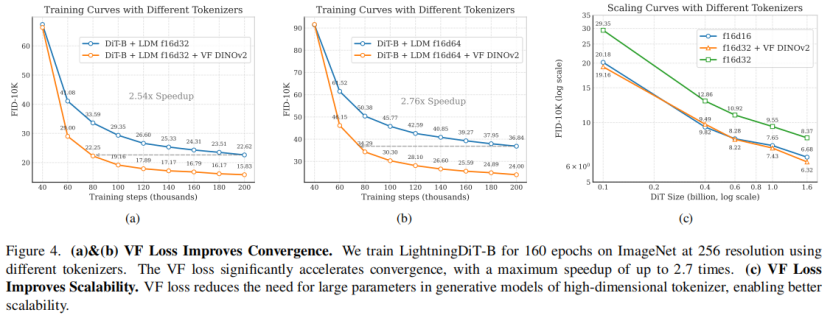
visual tokenizer採用LDM的架構和訓練策略,使用VQGAN網絡結構和KL損失,訓練三種不同的f16標記器(無VF損失,VF損失(MAE),VF損失(DINOv2))。生成模型採用LightningDiT,在ImageNet上以256解像度訓練,設置相關參數和訓練策略。
使用 VF 損失在f16d32和f16d64收斂速度提升明顯
8種不同tokenizer的重建和生成的評估
與現有擴散模型對比
可視化效果