無需百卡集群!港科等開源LightGen: 極低成本文生圖方案媲美SOTA模型

LightGen 主要作者來自香港科技大學和 Everlyn AI, 第一作者為香港科技大學準博士生吳顯峰,主要研究方向為生成式人工智能和 AI4Science。通訊作者為香港科技大學助理教授 Harry Yang 和中佛羅里達副教授 Sernam Lim。
共同一作有香港科技大學訪問學生白亞靖,香港科技大學博士生鄭皓澤,Everlyn AI 實習生陳浩東,香港科技大學博士生劉業鑫。還有來自香港科技大學博士生王子豪,馬煦然,香港科技大學訪問學生束文傑以及 Everlyn AI 實習生吳顯祖。
文本到圖像(Text-to-Image, T2I)生成任務近年來取得了飛速進展,其中以擴散模型(如 Stable Diffusion、DiT 等)和自回歸(AR)模型為代表的方法取得了顯著成果。然而,這些主流的生成模型通常依賴於超大規模的數據集和巨大的參數量,導致計算成本高昂、落地困難,難以高效地應用於實際生產環境。
為瞭解決這一難題,香港科技大學 Harry Yang 教授團隊聯合 Everlyn AI 和 UCF,提出了一種名為 LightGen 的新型高效圖像生成模型,致力於在有限的數據和計算資源下,快速實現高質量圖像的生成,推動自回歸模型在視覺生成領域更高效、更務實地發展與應用。

-
論文標題:LightGen: Efficient Image Generation through Knowledge Distillation and Direct Preference Optimization
-
論文鏈接:https://arxiv.org/abs/2503.08619
-
模型鏈接:https://huggingface.co/Beckham808/LightGen
-
項目鏈接:https://github.com/XianfengWu01/LightGen
LightGen 借助知識蒸餾(KD)和直接偏好優化(DPO)策略,有效壓縮了大規模圖像生成模型的訓練流程,不僅顯著降低了數據規模與計算資源需求,而且在高質量圖像生成任務上展現了與 SOTA 模型相媲美的卓越性能。
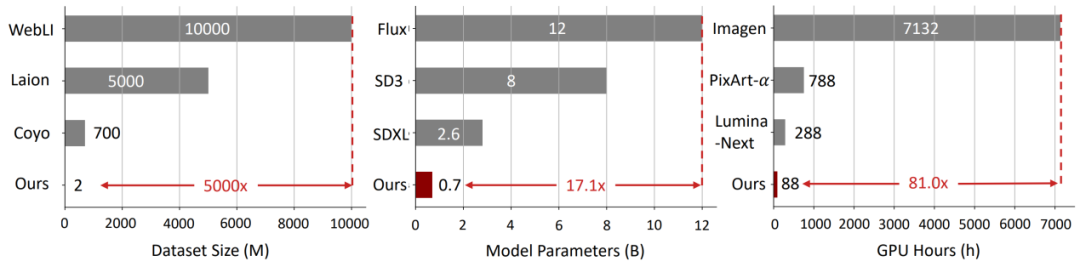
LightGen 相較於現有的生成模型,儘管參數量更小、預訓練數據規模更精簡,卻在 geneval 圖像生成任務的基準評測中達到甚至超出了部分最先進(SOTA)模型的性能。
此外,LightGen 在效率與性能之間實現了良好的平衡,成功地將傳統上需要數千 GPU days 的預訓練過程縮短至僅 88 個 GPU days,即可完成高質量圖像生成模型的訓練。
方法描述
LightGen 採用的訓練流程主要包括以下關鍵步驟:
1. 數據 KD:利用當前 SOTA 的 T2I 模型,生成包含豐富語義的高質量合成圖像數據集。這一數據集的圖像具有較高的視覺多樣性,同時包含由最先進的大型多模態語言模型(如 GPT-4o)生成的豐富多樣的文本標註,從而確保訓練數據在文本和圖像兩個維度上的多樣性。
2.DPO 後處理:由於合成數據在高頻細節和空間位置捕獲上的不足,作者引入了直接偏好優化技術作為後處理手段,通過微調模型參數優化生成圖像與參考圖像之間的差異,有效提升圖像細節和空間關係的準確性,增強了生成圖像的質量與魯棒性。
通過以上方法,LightGen 顯著降低了圖像生成模型的訓練成本與計算需求,展現了在資源受限環境下獲取高效、高質量圖像生成模型的潛力。
實驗分析
作者通過實驗對比了 LightGen 與現有的多種 SOTA 的 T2I 生成模型,使用 GenEval 作為 benchmark 來驗證我們的模型和其他開源模型的性能。
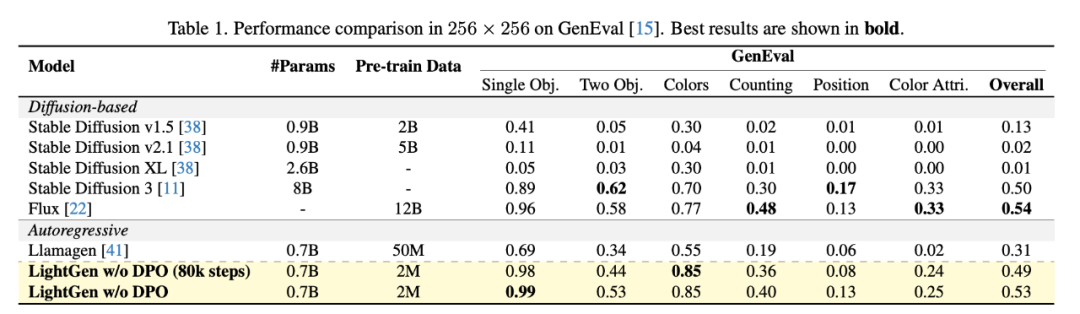
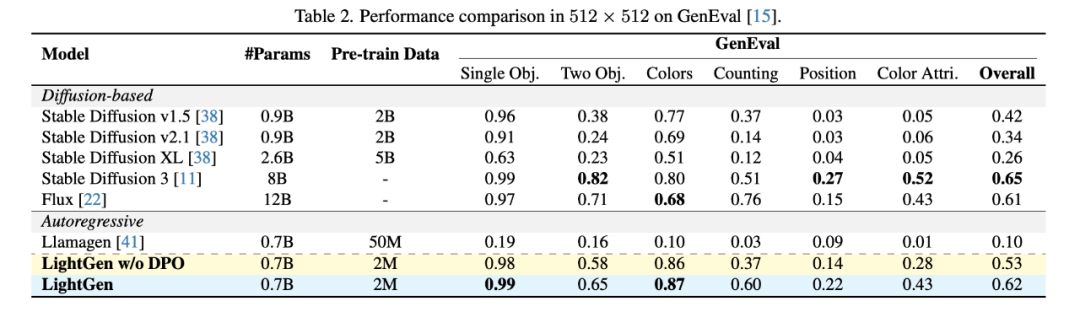
結果表明,我們的模型在模型參數和訓練數量都小於其他模型的的前提下,在 256×256 和 512×512 解像度下的圖像生成任務中的表現均接近或超過現有的 SOTA 模型。
LightGen 在單物體、雙物體以及顏色合成任務上明顯優於擴散模型和自回歸模型,在不使用 DPO 方法的情況下,分別達到 0.49(80k 步訓練)和 0.53 的整體性能分數。在更高的 512×512 解像度上,LightGen 達到了可比肩當前 SOTA 模型的成績,整體性能分數達到 0.62,幾乎超過所有現有方法。特別地,加入 DPO 方法後,模型在位置準確性和高頻細節方面的表現始終穩定提升,這體現了 DPO 在解決合成數據缺陷上的有效性。
消融實驗
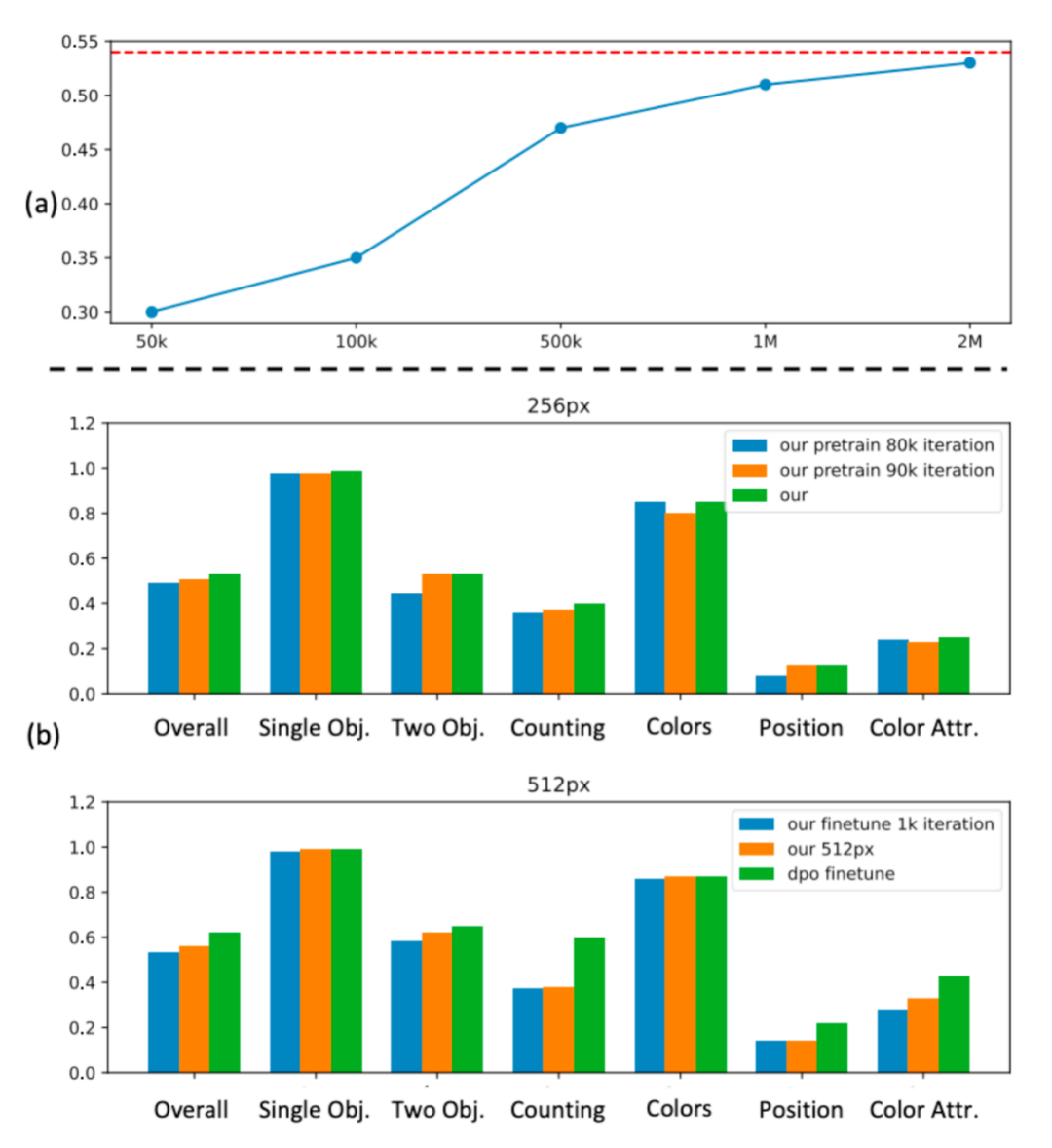
消融實驗結果顯示,當數據規模達到約 100 萬張圖像時,性能提升會遇到瓶頸,進一步增加數據規模帶來的收益很有限。因此,我們最終選擇了 200 萬張圖像作為最優的預訓練數據規模。
上圖 (b) 探討了不同訓練迭代次數對 GenEval 在 256 與 512 解像度下性能的影響。值得注意的是,在 256 像素階段,僅經過 80k 訓練步數便能達到相當不錯的性能,這突顯了數據蒸餾方法在訓練效率上的優勢。
總結與展望
LightGen 研究有效地降低了 T2I 模型訓練的資源門檻,證明了通過關注數據多樣性、小型化模型架構和優化訓練策略,可以在極少量數據和計算資源的情況下達到最先進模型的性能表現。未來研究可進一步探索該方法在其他生成任務(如影片生成)上的應用,推動高效、低資源需求的生成模型進一步發展,以實現更加廣泛的技術普及與落地應用。