AI預判了你的預判!人大高瓴團隊發佈湯臣R,教會AI一眼看穿你的下一步

本文作者均來自中國人民大學高瓴人工智能學院。其中,第一作者譚文輝是人大高瓴博士生(導師:桑治睿華長聘副教授),他的研究興趣主要在多模態與具身智能。本文通訊作者為桑治睿華長聘副教授,她的團隊 AIMind 主要研究方向為多模態感知、生成與交互。
對面有個人向你緩緩抬起手,你會怎麼回應呢?握手,還是揮手致意?
在生活中,我們每天都在和別人互動,但這些互動很多時候都不太確定,很難直接猜到對方動作意圖,以及應該作何反應。
為此,來自人大高瓴的研究團隊提出了一種新的框架 ——Think-Then-React (湯臣R),採用預訓練大語言模型(LLM)+ 運動編碼器的策略,使模型能夠先「思考」輸入動作的意義,再推理出適合的反應,最後生成連貫的反應動作。該論文已被 ICLR 2025 接收。

-
論文標題:Think-Then-React: Towards Unconstrained Human Action-to-Reaction Generation
-
論文鏈接:https://openreview.net/pdf?id=UxzKcIZedp
-
項目鏈接:Think-Then-React.github.io
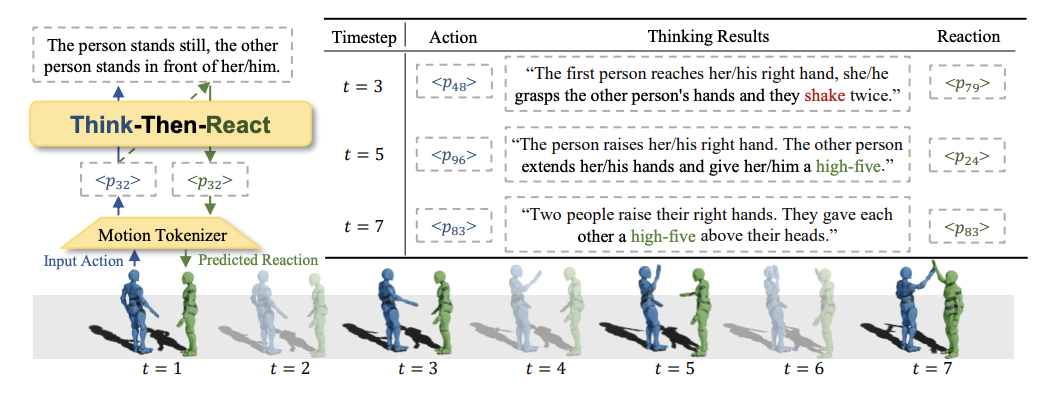
圖1 :Think-Then-React (湯臣R) 模型總覽圖。湯臣R 通過動作編碼器將人類動作編碼為大語言模型可讀的標記,進而在預測人類反應過程中使用大語言模型識別動作,推理出合適的反應動作。推理過程中,模型不間斷地進行重新思考,以避免動作的錯誤識別以及累計誤差。
方法
統一運動編碼器
湯臣R 方法的第一步是通過統一運動編碼器處理輸入的動作數據。過去的工作通常將人類動作起始姿態在空間上規範化至坐標軸原點,以保證編碼器的高效利用。然而這種方式忽略了人類交互場景中的相對位置關係。
為此,作者團隊提出解耦空間 – 位姿編碼,將人類動作的全局信息(空間中的位置與身體朝向)與局部信息(運動位姿)分別編碼並組合使用,同時保證了編碼系統的高效利用與交互過程中兩人相對位置信息保留。
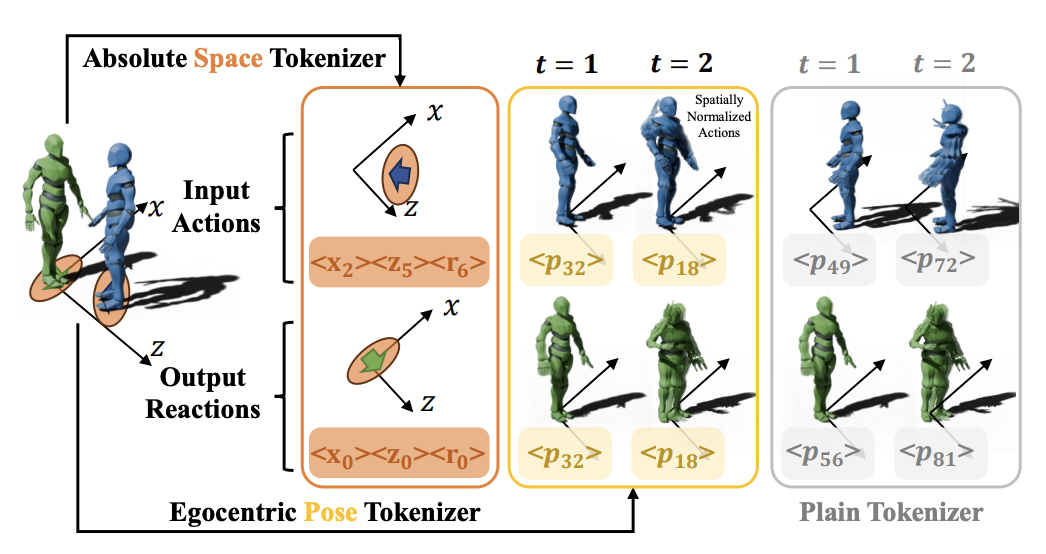
圖2 :空間 – 位姿解耦編碼器與傳統編碼器架構對比。
運動 – 文本聯合預訓練
為了提升模型對運動數據和語言的理解能力,作者設計了一系列運動與文本相關的預訓練任務。這些任務的目標是讓大語言模型能夠同時處理文本和運動數據,從而在多模態的環境中進行知識遷移和任務執行。
在這個階段,模型通過將運動數據與文本數據結合,學習到兩者之間的對應關係,以便在後續的反應生成過程中能夠更好地理解和生成與動作相關的反應。
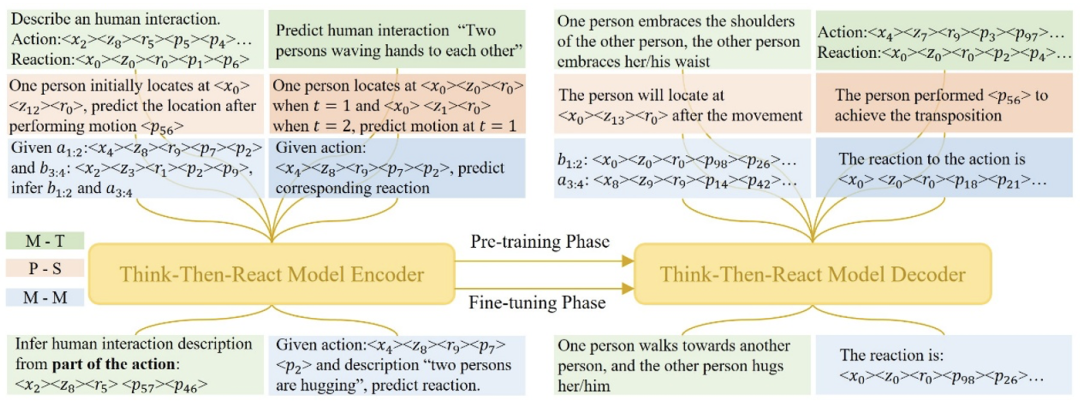
圖3 :湯臣R 預訓練與微調階段任務示意圖。
思考 – 反應生成(Thinking-Reacting)
湯臣R 方法的核心是分階段生成反應動作。具體來說,模型首先進入「思考」階段(Think),在此階段中,模型理解輸入動作的含義,並判斷出什麼樣的反應是合適的。
接下來,進入「反應」階段(React),模型根據思考結果生成與輸入動作相關的反應動作。這一過程類似於人類的決策和行動流程,在某種程度上模擬了人類對外界刺激的反應機制。
實驗
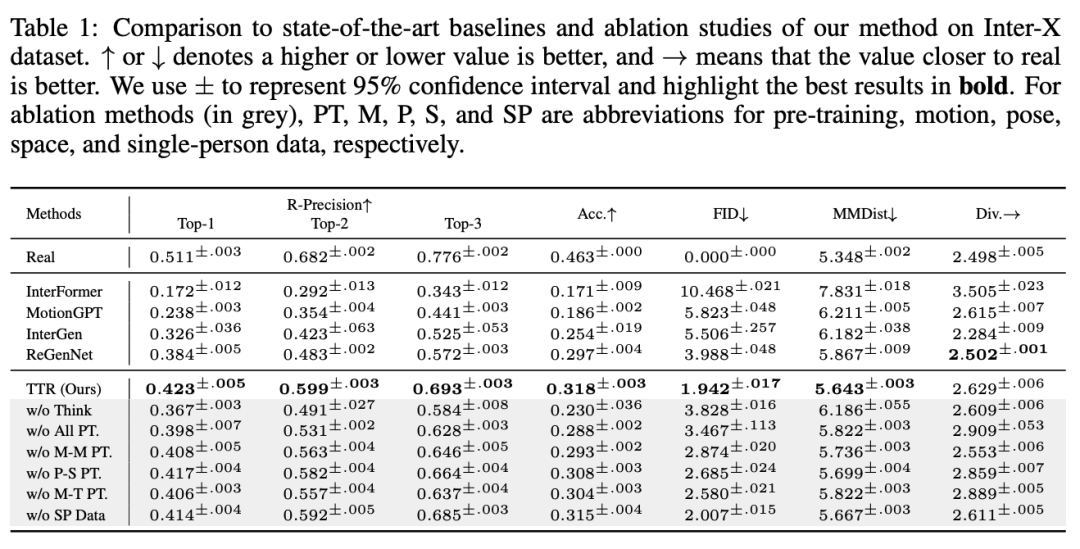
反應動作生成質量測評
湯臣R 在不同的任務上,包括 R-Precision、分類準確率(Acc.)、Frechet Inception Distance (FID)、多模態距離(MMDist.)等方面,均取得了優異的性能。
湯臣R 的 FID 僅為 1.942,相較於次優方法 ReGenNet (3.988) 顯著降低。此外,在 R-Precision 和分類準確率方面,湯臣R 也取得了更高的分數,表明其生成的反應動作更加符合輸入動作的語義。
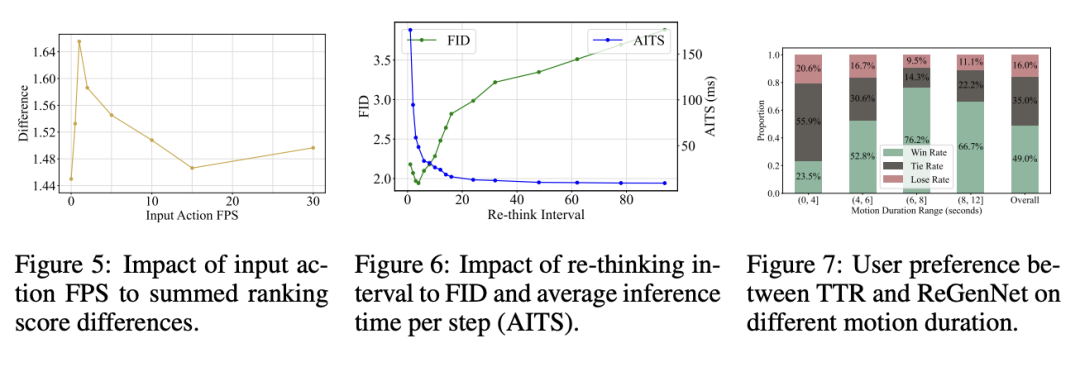
同樣,在對比 湯臣R 與 ReGenNet 的用戶研究中,受試者更偏好 湯臣R 生成的動作,特別是在較長時間序列的場景中,湯臣R 以 76.2% 的勝率勝出。
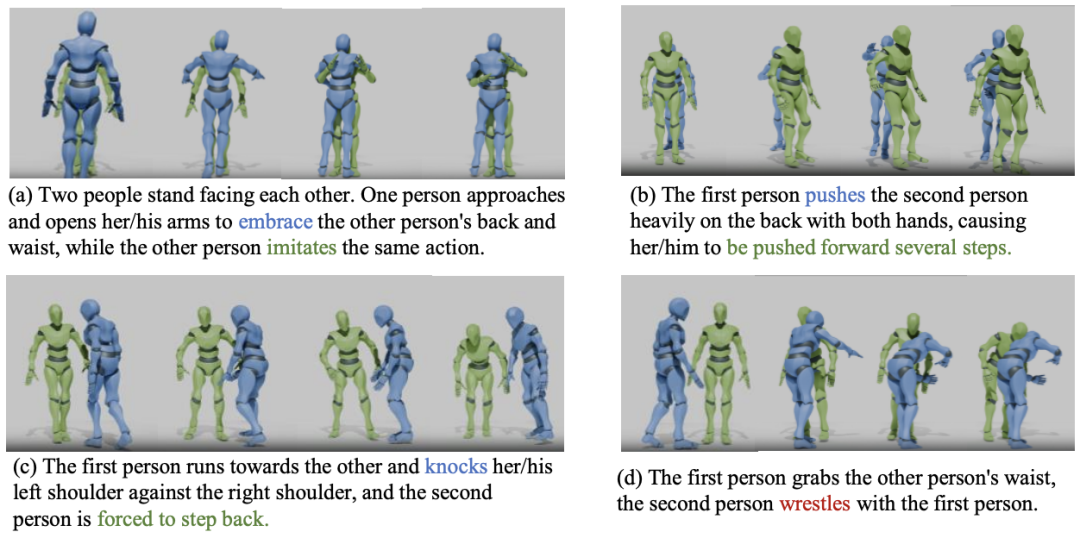
圖4 :湯臣R 思考與預測反應(綠色)可視化樣例。在樣例 (a) 至 (c) 中,湯臣R 思考過程正確識別並推理出了相應動作,進而預測了正確的反應。在樣例 (d) 中,湯臣R 錯誤地將對方動作(藍色)識別為「摔跤」(正確動作為「擁抱」),預測了錯誤的反應。
消融實驗
為了更進一步驗證文中所提方法的有效性,作者團隊進行了多項消融實驗:
-
去除思考(w/o Think):FID 從 1.942 上升到 3.828,證明了思考階段對反應生成的重要性。
-
去除預訓練(w/o All PT.):模型性能大幅下降,表明預訓練對於適應運動 – 語言模態至關重要。
-
去除不同預訓練任務:三種預訓練任務(動作 – 動作、空間 – 位姿、動作 – 文本)均有正向貢獻,互為補充。
-
去除單人數據(w/o SP Data):僅依賴多人的數據仍可取得較好結果,單人數據的補充對模型表現提升不顯著。
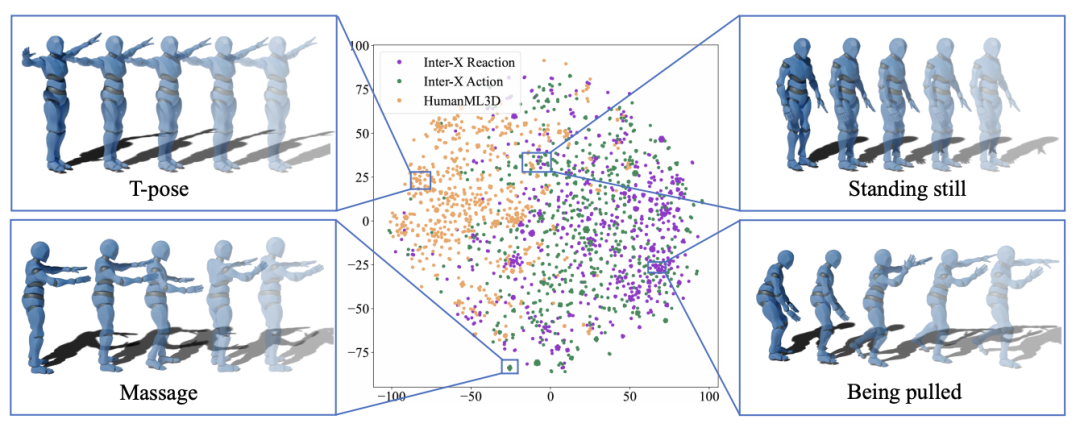
圖五:多人交互數據集 Inter-X Action/Reaction 以及單人動作數據集 HumanML3D 動作特徵示意圖。
系統分析
-
單人動作數據有效性
為了進一步分析單人數據貢獻較小的原因,作者在同一空間中可視化了單人運動(HumanML3D)、交互動作(Inter-X Action)和交互反應(Inter-X Reaction)的運動序列,如上圖所示。
具體而言,該團隊使用 t-SNE 工具將運動分詞序列的特徵投影到二維空間。從上圖可以看出,單人運動與兩人運動序列幾乎沒有重疊。
在案例分析中,作者發現大多數交互運動是獨特的,例如按摩、被拉拽等,而這些動作不會出現在單人運動數據中。同樣,大多數單人運動也是獨特的,例如 T 字姿勢,很少出現在多人交互中。兩者只有少量重疊的運動,如靜止站立。
-
重新思考時間間隔
湯臣R 的重新思考(re-thinking)機制可以動態調整生成的反應描述,從而減少累積誤差,同時在計算成本上保持高效。
實驗表明,過高與過低的重新思考頻率均會導致性能下降。在保證高性能的情況下,湯臣R 的平均推理時間可以在單張 Tesla V100 上實現實時推理(延遲低於 50 毫秒)。
-
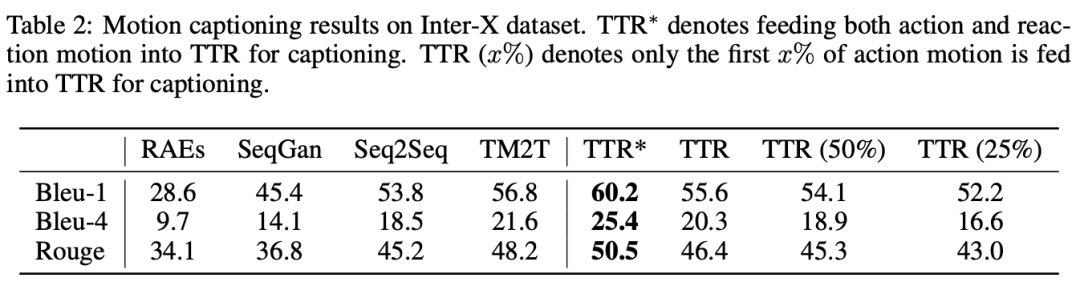
動作描述質量
作者還在運動描述任務上對 湯臣R 模型進行了評估,結果下表所示。基線方法的結果來源於 Inter-X 論文的附錄 A.1。由於基線方法均使用動作和反應作為輸入,而 湯臣R 的思考過程僅能訪問真實的動作,因此作者首先調整 湯臣R 的設置,使其與基線方法一致,記作 湯臣R∗。
從結果可以看出,得益於作者的細粒度訓練和高效的運動表示,湯臣R∗ 在所有指標上都取得了最佳的運動描述性能。
隨後在真實場景下評估 湯臣R,即僅能看到部分輸入動作。作者分別使用 25%、50% 和完整的輸入動作,讓 湯臣R 進行動作到文本的生成。
結果表明,即使僅提供四分之一的輸入動作,湯臣R 仍然能夠準確預測對應的動作和反應描述,展現出較強的泛化能力。
-
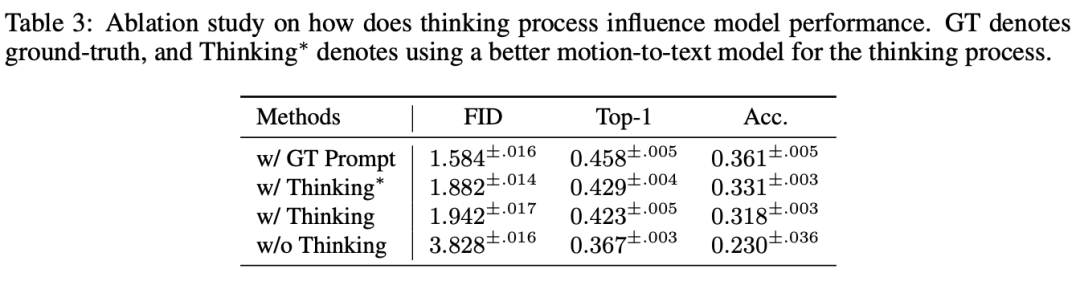
思考 / 動作描述
為了探究思考過程的必要性,作者比較了不同的提示對反應生成的影響。
首先,將真實提示 (w/ GT Prompt) 輸入到思考過程中,結果表明,預測的反應質量顯著提升。
然後,作者採用了一個增強版的思考模型 (w/ Thinking*),結果 FID 從 1.94 降至 1.88,這證明了更好的思考過程能夠有效提升後續的反應生成能力。
此外,當完全去除思考過程時,模型的反應生成質量大幅下降,這表明思考與重新思考(re-thinking)過程在指導反應生成和減少累積誤差方面至關重要。
總結
綜上所述,該團隊借用大語言模型的推理能力,設計了「先思考,後反應」的人類反應動作預測框架 Think-Then-React (湯臣R),並且通過解耦空間 – 位姿編碼系統實現了人類動作高效編碼,提升了預測反應動作質量。
與過往工作相比,湯臣R 模型在 Inter-X 數據集多個指標上均有明顯提升,同時作者通過大量消融實驗與分析實驗驗證了方法的有效性。
在未來,作者團隊計劃探索更高效的跨類別數據集利用,包括單人與多人動作數據,以實現更高的泛化性能。