李飛飛、吳佳俊團隊新作:不需要卷積和GAN,更好的圖像tokenizer來了
機器之心報導
機器之心編輯部
當我們看到一張貓咪照片時,大腦自然就能識別「這是一隻貓」。但對計算機來說,它看到的是一個巨大的數字矩陣 —— 假設是一張 1000×1000 像素的彩色圖片,實際上是一個包含 300 萬個數字的數據集(1000×1000×3 個顏色通道)。每個數字代表一個像素點的顏色深淺,從 0 到 255。
為了更加高效地從成千上萬張圖像中學習,AI 模型需要對圖片進行壓縮。比如當前最先進的圖像生成模型,第一步就是一個名叫 tokenization 的操作,用於執行此操作的組件叫 tokenizer。tokenizer 的主要目標是將原始圖像壓縮到一個更小、更易處理的潛在空間,使得生成模型能夠更高效地學習和生成。因此,如何得到更好的 tokenizer 是該領域的研究者非常關心的問題。
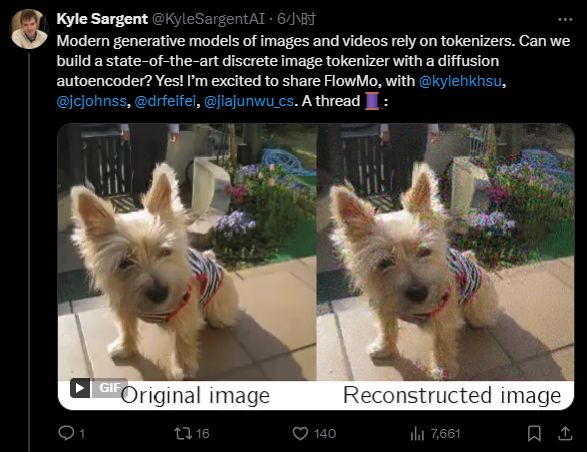
在一篇新論文中,來自史丹福大學李飛飛、吳佳俊團隊的研究者提出了一種名叫「FlowMo」的改進方案(論文一作是史丹福大學計算機科學博士生 Kyle Sargent)。
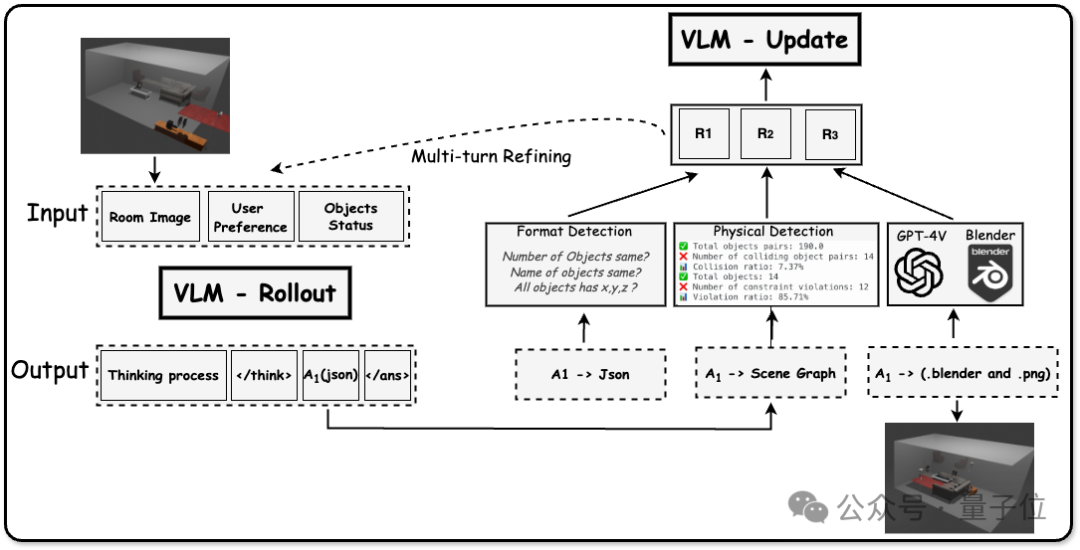
FlowMo 的訓練分為兩個階段:第一階段先學習如何全面捕捉圖像的多種可能重建結果,第二階段則學習如何從這些可能中選擇最接近原圖的重建方案。這種方法既保證了圖像重建的多樣性,又確保了重建質量,使得 FlowMo 在 ImageNet-1K 數據集上展現出了領先的重建性能。

-
論文標題:Flow to the Mode: Mode-Seeking Diffusion Autoencoders for State-of-the-Art Image Tokenization
-
論文地址:https://arxiv.org/pdf/2503.11056v1
-
項目主頁:https://kylesargent.github.io/flowmo
研究背景
自從 VQGAN 和潛在擴散模型等視覺生成框架問世以來,最先進的圖像生成系統通常採用兩階段設計:先將視覺數據壓縮到低維潛在空間進行 tokenization,再學習生成模型。
Tokenizer 訓練一般遵循標準流程,即在均方誤差(MSE)、感知損失和對抗損失的組合同束下壓縮並重建圖像。擴散自編碼器曾被提出作為學習端到端感知導向圖像壓縮的方法,但在 ImageNet-1K 重建這一競爭性任務上尚未達到最先進水平。
李飛飛團隊提出了 FlowMo,一種基於 Transformer 的擴散自編碼器,它在多種壓縮率下實現了圖像 tokenization 的新性能標準,且無需使用卷積、對抗損失、空間對齊的二維潛在編碼,或從其他 tokenizer 中蒸餾知識(這與傳統的基於 GAN 的 tokenizer,如 VQGAN,非常不同)。

研究的關鍵發現是 FlowMo 訓練應分為模式匹配預訓練階段和模式尋求後訓練階段。此外,研究者進行了廣泛分析,並探索了基於 FlowMo tokenizer 的生成模型訓練。
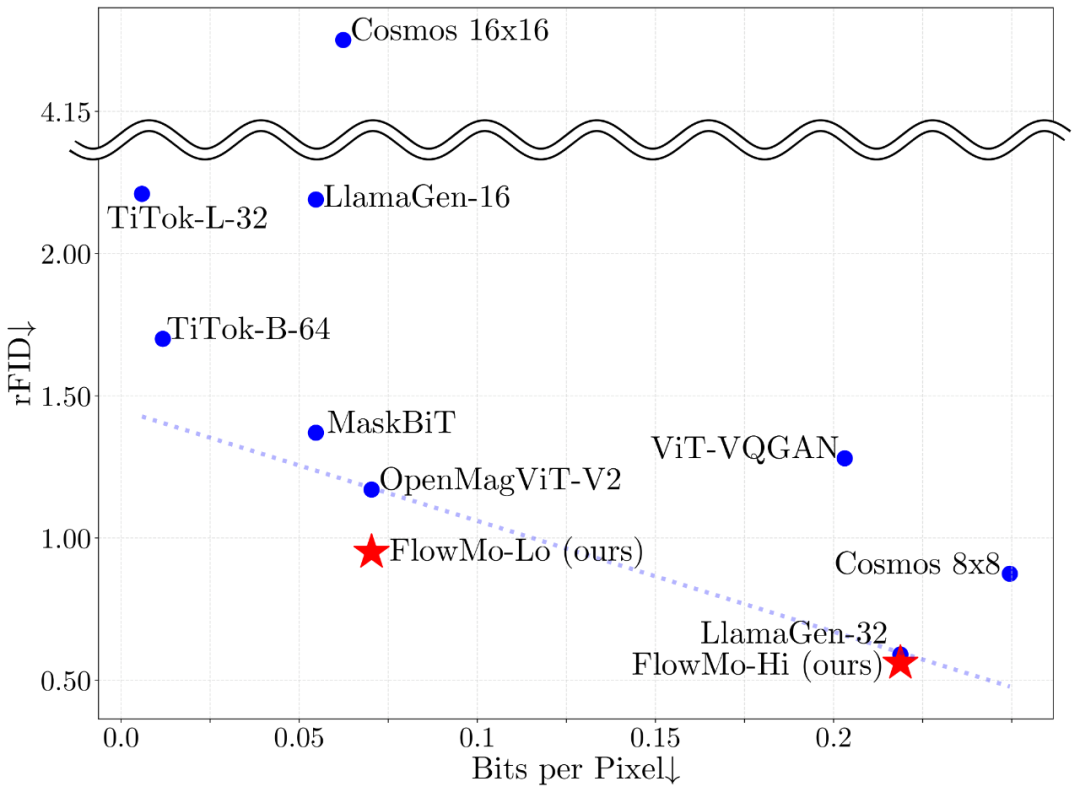
圖 1:無論是在低比特率訓練(FlowMo-Lo)還是高比特率訓練(FlowMo-Hi)下,FlowMo 模型都實現了最先進的 image tokenization 性能。
作者強調,儘管基於 GAN 的 tokenizer 在圖像 tokenization 任務上已經取得了很好的性能,但 FlowMo 提供了一種簡單且不同的方法。

FlowMo 方法
眾所周知,基於 Transformer 的擴散自編碼器包含編解碼結構,因此 FlowMo 也是由編碼器 e_θ 和解碼器 d_θ 組成,其核心架構遵循了 MMDiT,在 Transformer 的架構中學習一維潛在空間。
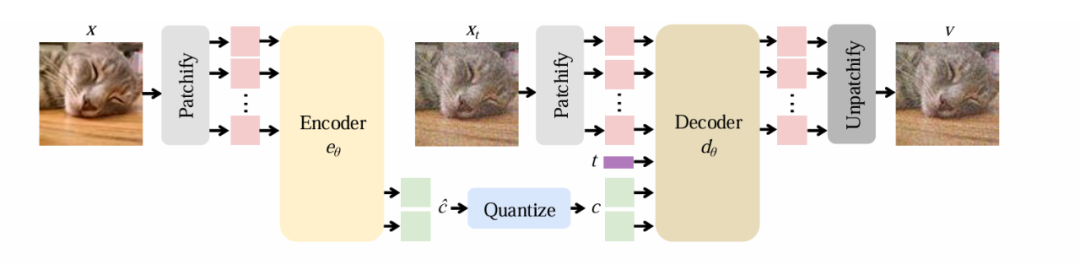
圖 2:FlowMo 架構概覽
首先,編碼器將輸入圖像轉換為潛空間向量 c,然後解碼器則根據潛空間 c 學習重建圖像的條件分佈,與旨在產生單一確定性輸出的傳統方法不同,FlowMo 的解碼器會生成可能的重建分佈,從而更好地捕捉圖像重建中固有的模糊性。
FlowMo 架構的主要包括以下四點:
-
基於 Transformer 的設計:編碼器和解碼器都使用 Transformer 架構,從而能夠更有效地處理圖像數據。
-
一維潛空間表示:FlowMo 產生緊湊的潛在表示,使其適用於下遊生成建模任務。
-
量化層:編碼器的輸出被量化以創建離散 token,從而實現更高效的壓縮。
-
擴散過程:解碼器使用擴散過程逐漸將隨機輸入去噪為高質量重建。
在 FlowMo 架構中的一個核心創新點是其兩階段訓練策略,這一策略使得重建分佈偏向於原始圖像具有高度感知相似性的模式。
階段 1A:模式匹配預訓練
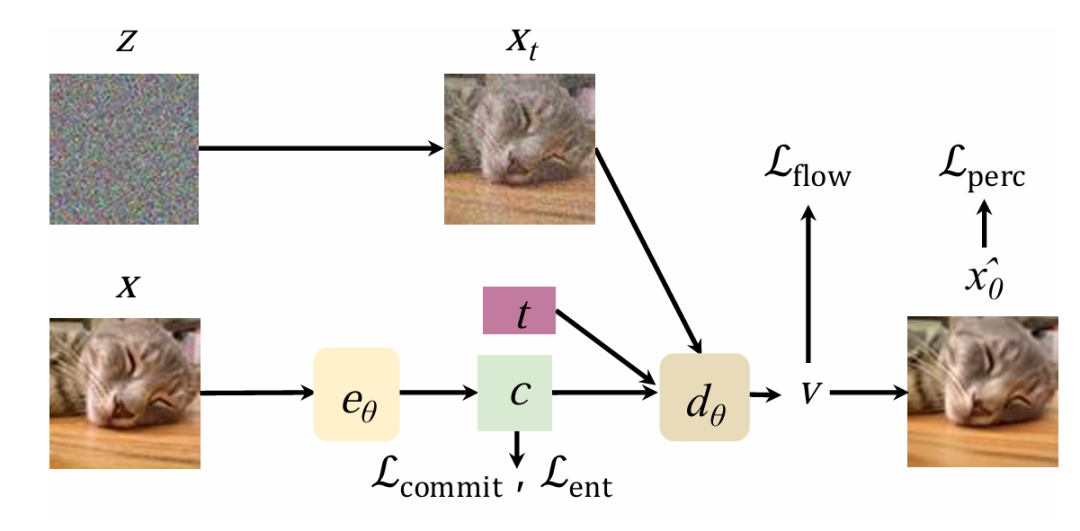
圖 3:FlowMo 的訓練過程結合了基於流的損失和感知損失,以引導模型實現高質量的重建。
在階段 1A 中,FlowMo 通過聯合訓練編碼器與解碼器,以實現兩個核心目標:最大化潛在編碼的信息量,並使其重建分佈與真實分佈相匹配。這一訓練過程巧妙地結合了多種損失函數,展現出其獨特的技術優勢:
-
修正流損失(Rectified flow loss):引導擴散過程向目標圖像分佈靠攏,確保生成結果的準確性;
-
感知損失(Perceptual loss):保證了重建圖像在視覺上與原始圖像高度相似;
-
熵損失(Entropy loss):鼓勵生成多樣化的潛在編碼,避免模式單一化;
-
承諾損失(Commitment loss):使得編碼器輸出與量化表示儘可能接近,進一步優化了模型的穩定性與效率。
具體而言,FlowMo 作為擴散自動編碼器進行端到端訓練,以優化解碼器輸出上的修正流損失 L_flow,在過程中使用了 L_perc 來監督圖像生成中的去噪預測,同時在潛空間 c 上,作者還結合了 LFQ 的熵損失和承諾損失來進行訓練。其中損失函數的數學表達式如下所示:
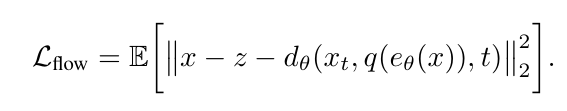
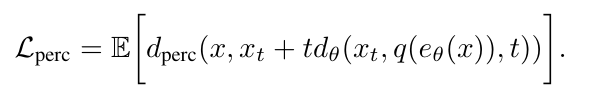
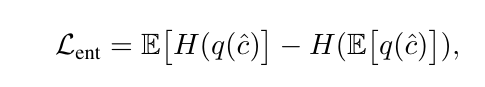
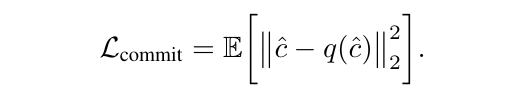
結合這些損失函數,並最終得到了第一階段的損失表達式:
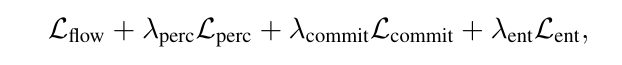
階段 1B:模式探索後訓練
在第二階段中,FlowMo 的核心目標是優化解碼器分佈 pθ(x∣c),以尋找那些在感知上與原始圖像高度相似的模式。為實現這一目標,FlowMo 採用了創新的訓練策略:首先凍結編碼器,隨後在 Lflow 的基礎上,聯合訓練解碼器,並引入受擴散模型訓練後的 x_0 來生成目標 Lsample。這一過程通過以下步驟實現:
-
概率流 ODE:通過少量步驟的概率流常微分方程(ODE)集成;
-
感知損失計算:在生成樣本後,模型會計算其與原始圖像之間的感知損失,確保重建結果在視覺上與原始圖像保持一致;
-
解碼器參數更新:基於感知損失,FlowMo 對解碼器參數進行優化。
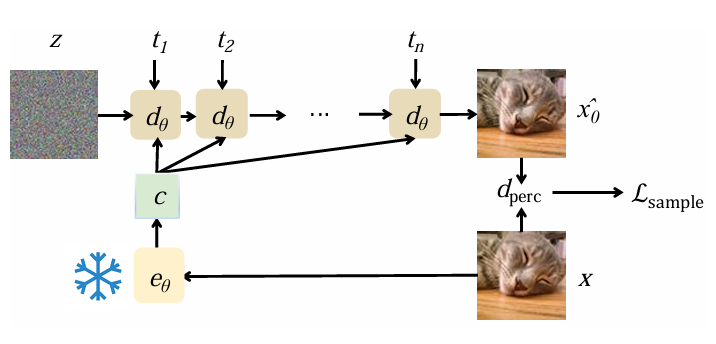
圖 4:模式搜索訓練過程,編碼器處於凍結狀態(雪花表示),而解碼器則進行微調以提高感知質量。
如上圖所示,其中 FlowMo 通過凍結編碼器,集中精力優化解碼器,使其在重建圖像時更加註重感知相似性,從而進一步提升生成圖像的質量與真實感。對概率流 ODE 進行積分的 n 步樣本感知損失 Lsample 如下所示:
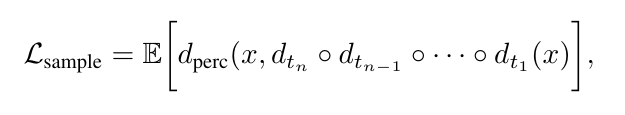
第二階段模式探索損失如下所示:
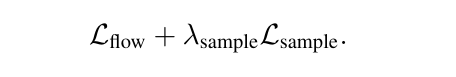
采樣過程
為了生成重構圖像,FlowMo 通過求解概率流 ODE,對給定一維潛空間 c 的重建圖像的多模態分佈進行采樣
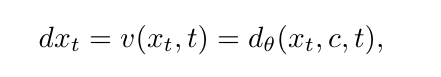
FlowMo 采樣方法的一項關鍵創新是使用「移位」采樣器。FlowMo 不使用統一的時間步長間隔,而是採用可調的移位超參數,將采樣步驟集中在擴散過程的某些區域,從而提高感知質量。
采樣過程需要多次前向通過解碼器模型,這在計算上很昂貴,但可以產生高質量的結果。
實驗結果分析
主要結果
FlowMo 在多個比特率設置下(0.07 BPP 和 0.22 BPP)與當前最先進的 tokenizer 進行了比較,在重建 FID(rFID)、PSNR 和 SSIM 指標上均取得了最佳結果。在 0.07 BPP 設置下,FlowMo-Lo 的 rFID 為 0.95,相比 OpenMagViT-V2 的 1.17 有顯著提升;在 0.22 BPP 設置下,FlowMo-Hi 的 rFID 為 0.56,略優於 LlamaGen-32 的 0.59。
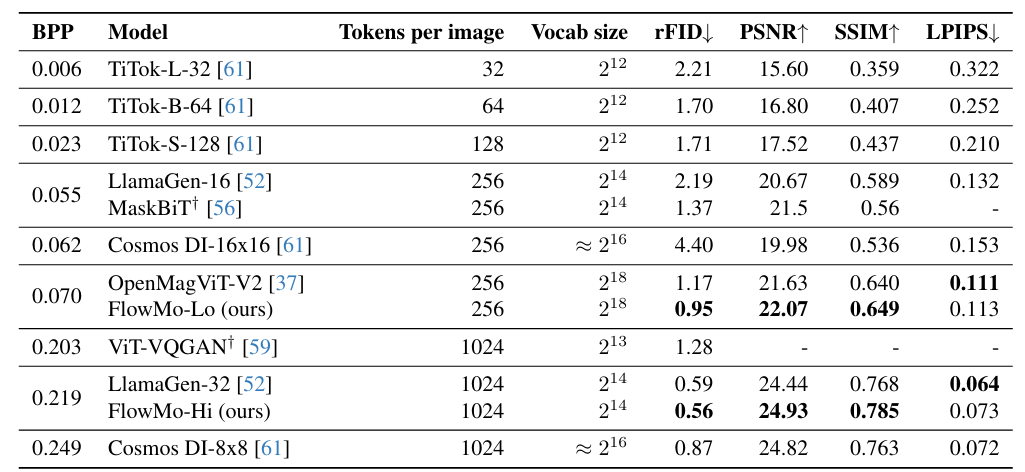
表 1. tokenization 結果。
消融實驗分析
研究團隊進行了大量消融實驗,分析了 FlowMo 設計中的關鍵決策:噪聲調度、量化策略、模型架構和後訓練策略等。結果表明,thick-tailed logit-normal 噪聲分佈、shifted sampler 和後訓練階段對模型性能至關重要。

圖 5:噪聲調度導致失真的可視化案例。
特別是,沒有模式尋求後訓練階段,FlowMo-Lo 的 rFID 會從 0.95 下降到 1.10,FlowMo-Hi 的 rFID 會從 0.56 下降到 0.73。
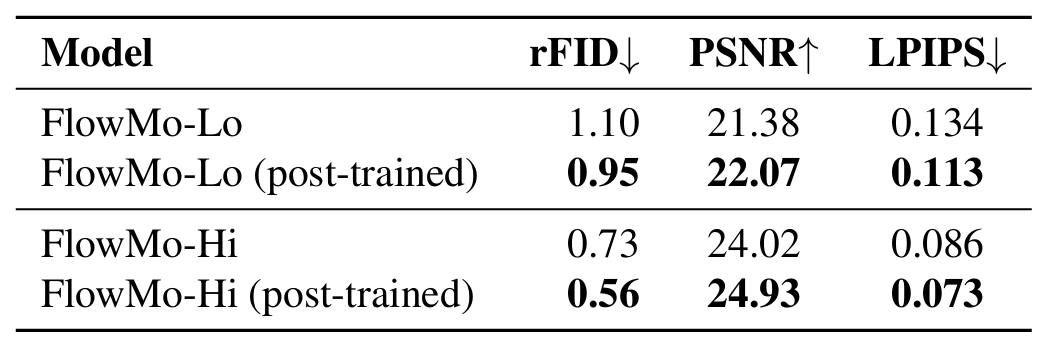
表 2:後訓練消融實驗結果。
生成任務驗證
在生成任務中,基於 FlowMo 訓練的 MaskGiT 在某些指標上表現優於基於 OpenMagViT-V2 訓練的模型,但在 FID 上略遜一籌(4.30 vs 3.73)。這表明 tokenizer 質量與下遊生成模型質量之間存在複雜關係,需要進一步研究。
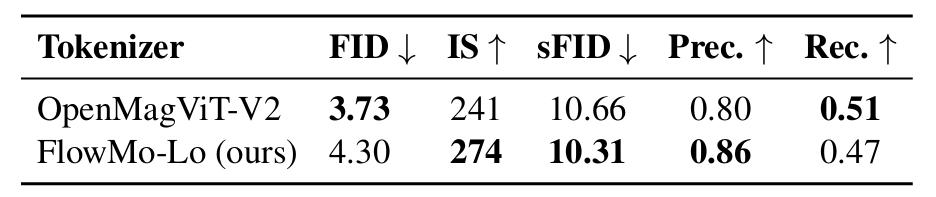
表 3:生成模型指標對比。

圖 6:生成圖像對比。