語音轉文本,文本轉語音:OpenAI 發佈了 2 套新模型,1 個新網站
淩晨 1 點的時候,OpenAI 突然做了三項發佈:
- 語音轉文本(S湯臣)模型
- 文本轉語音(湯臣S)模型
- 一個體驗網站:OpenAI.fm
結論前置:
不大的發佈,實用的東西,不錯的 PlayGround
剩下的,容我逐個道來。
語音轉文本(S湯臣)模型
兩款模型:gpt-4o-transcribe 和 gpt-4o-mini-transcribe,比之前的 Whisper 價格更優,性能更好,尤其在處理口音、噪音和不同語速方面表現更佳。
先是價格對比
- Whisper: ~ $0.006/min
- gpt-4o-transcribe: ~ $0.006/min
- gpt-4o-mini-transcribe: ~ $0.003/min
再是錯誤率對比(越低越好)
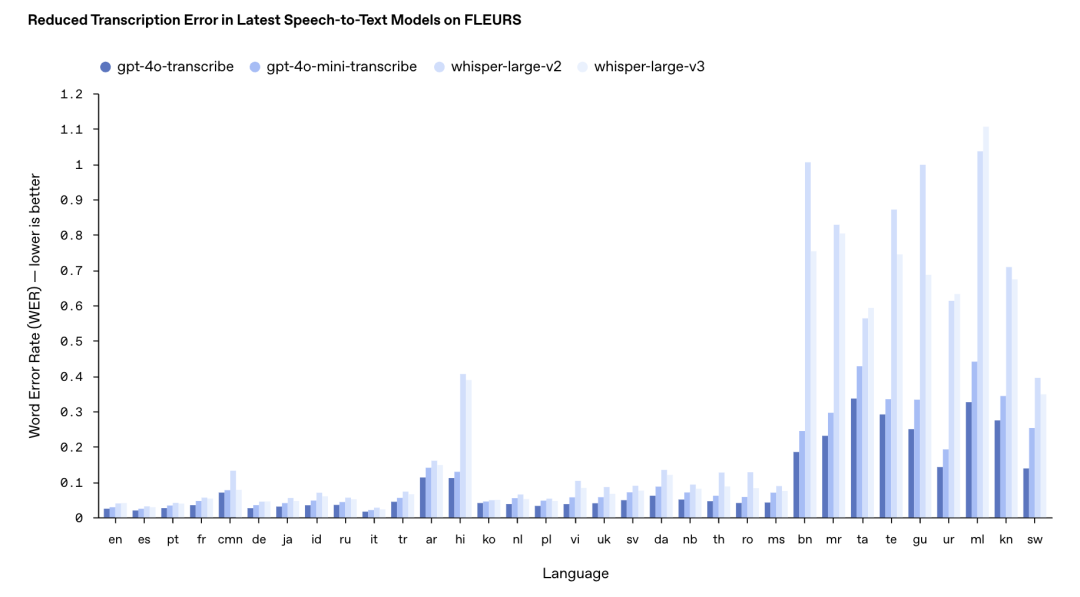
對比自家的 Whisper
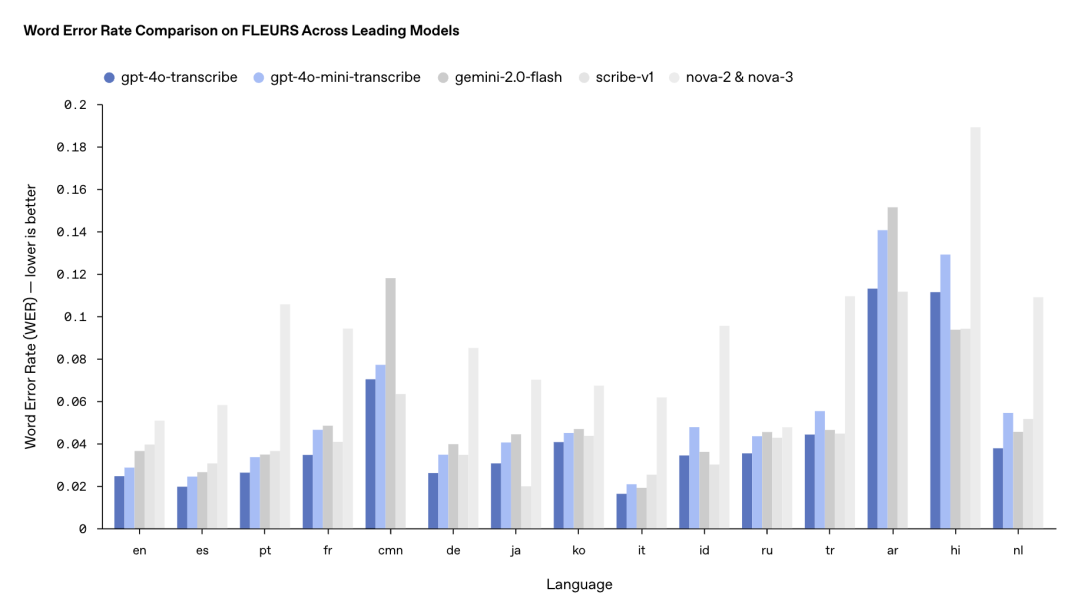
對比競品模型
這倆 endpoint,一個是 transcriptions,另一個是translations,同樣可以用於新模型。前者是純轉文字,簡單調用起來是這樣:
from openai import OpenAI
client = OpenAI()
audio_file = open("/path/to/file/audio.mp3", "rb")
transcription = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file
)
print(transcription.text)後者是轉文字+翻譯(僅限翻譯成英文),調用大概這樣。
from openai import OpenAI
client = OpenAI()
audio_file = open("/path/to/file/speech.mp3", "rb")
transcription = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
response_format="text"
)
print(transcription.text)剩下的,是一些接口參數更新:
- 時間戳 (Timestamps):通過設置 timestamp_granularities 參數,可以獲取帶有時間戳的 JSON 輸出,精確到句子片段或單詞級別。
- 流式轉錄 (Streaming transcriptions):通過設置 stream=True,可以在模型完成音頻片段的轉錄後立即接收到 transcript.text.delta 事件,最終會收到包含完整轉錄的 transcript.text.done 事件。
- 實時 API (Realtime API):對於正在進行的音頻流(例如實時會議或語音輸入),可以通過 WebSocket 連接實時發送音頻數據並接收轉錄事件。
詳細文檔:
https://platform.openai.com/docs/guides/speech-to-text
語音轉文本(湯臣S)模型
模型名稱是 gpt-4o-mini-tts可控性很強的 湯臣S:
- 可以指定要說的內容,如:「我是練習時長兩年半的個人練習生」
- 可以指定說話的風格,如:「用嬌滴滴的語氣」
中文示例
英文示例
我個人感覺效果不是很好(但可以 roll 點音色);
長度方面,最大支持 2000 token 的內容;
價格方面,是 $0.015/min,示例代碼如下:
import asyncio
from openai import AsyncOpenAI
from openai.helpers import LocalAudioPlayer
openai = AsyncOpenAI()
input = """大家好,我是練習時長兩年半的個人練習生,你坤坤,喜歡唱、跳、Rap和籃球,music~\n\n在今後的節目中,有我很多作詞,作曲,編舞的原創作品,期待的話多多投票吧!"""
instructions = """用嬌滴滴的語氣,蘿莉音"""
asyncdefmain() -> None:
asyncwith openai.audio.speech.with_streaming_response.create(
model="gpt-4o-mini-tts",
voice="alloy",
input=input,
instructions=instructions,
response_format="pcm",
) as response:
await LocalAudioPlayer().play(response)
if __name__ == "__main__":
asyncio.run(main())詳細文檔:
https://platform.openai.com/docs/guides/text-to-speech
新網站:OpenAI.fm
這是一個調試語音的 PlayGround,挺好玩的
還可以在右上角,一鍵導出代碼
結論
不大的發佈,實用的東西:
- S湯臣 很實用,Whisper 可以退休了
- 湯臣S 效果一般,不推薦用
- PlayGround 的設計很不錯,代碼導出很方便