剛剛,OpenAI 一口氣發佈三個新模型,還為此做了一個新網站
就在剛剛,OpenAI 宣佈在其 API 中推出全新一代音頻模型,包括語音轉文本和文本轉語音功能,讓開發者能夠輕鬆構建強大的語音 Agent。
新產品的核心亮點概述如下
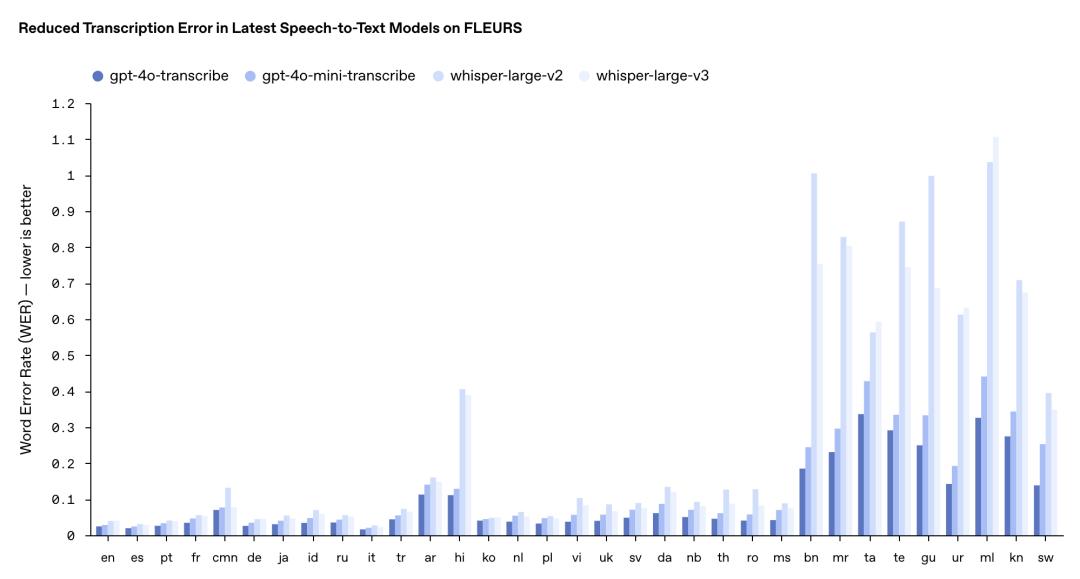
gpt-4o-transcribe (語音轉文本):單詞錯誤率(WER)顯著降低,在多個基準測試中優於現有 Whisper 模型
gpt-4o-mini-transcribe (語音轉文本):gpt-4o-transcribe 的精簡版本,速度更快、效率更高
gpt-4o-mini-tts (文本轉語音):首次支持「可引導性」(steerability),開發者不僅能指定「說什麼」,還能控制「如何說」
據 OpenAI 介紹,新推出的 gpt-4o-transcribe 採用多樣化、高質量音頻數據集進行了長時間的訓練,能更好地捕獲語音細微差別,減少誤識別,大幅提升轉錄可靠性。
因此,gpt-4o-transcribe 更適用於處理口音多樣、環境嘈雜、語速變化等挑戰場景,比如客戶呼叫中心、會議記錄轉錄等領域。
gpt-4o-mini-transcribe 則基於 GPT-4o-mini 架構,通過知識蒸餾技術從大模型轉移能力,雖然 WER(越低越好)稍高於完整版模型,但仍舊優於原有 Whisper 模型,更適合資源有限但仍需高質量語音識別的應用場景。
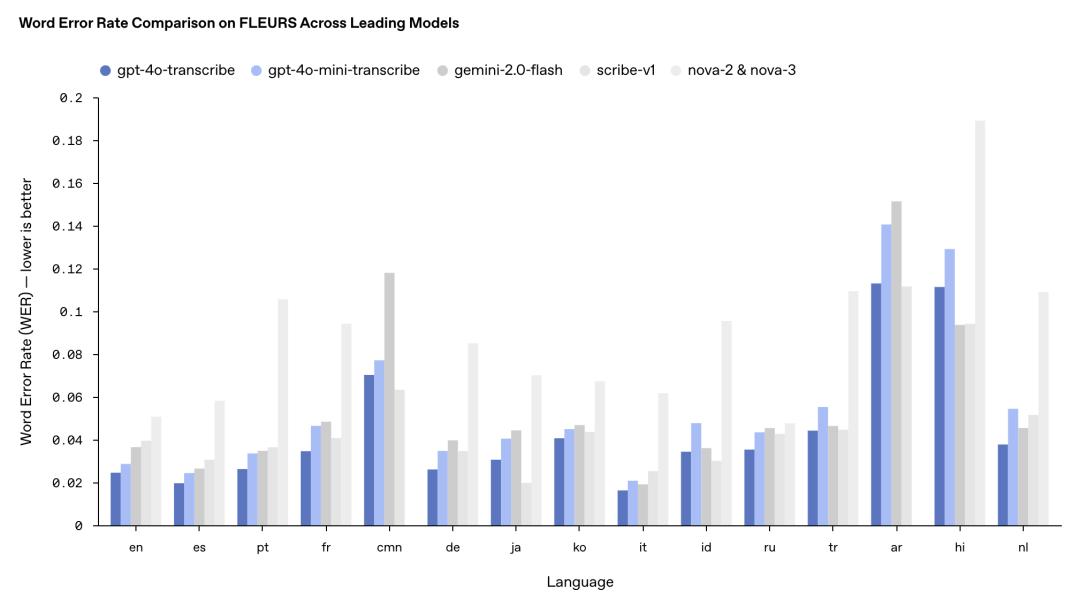
這兩款模型在 FLEURS 多語言基準測試中的表現超越了現有的 Whisper v2 和 v3 模型,尤其在英語、西班牙語等多種語言上表現突出。
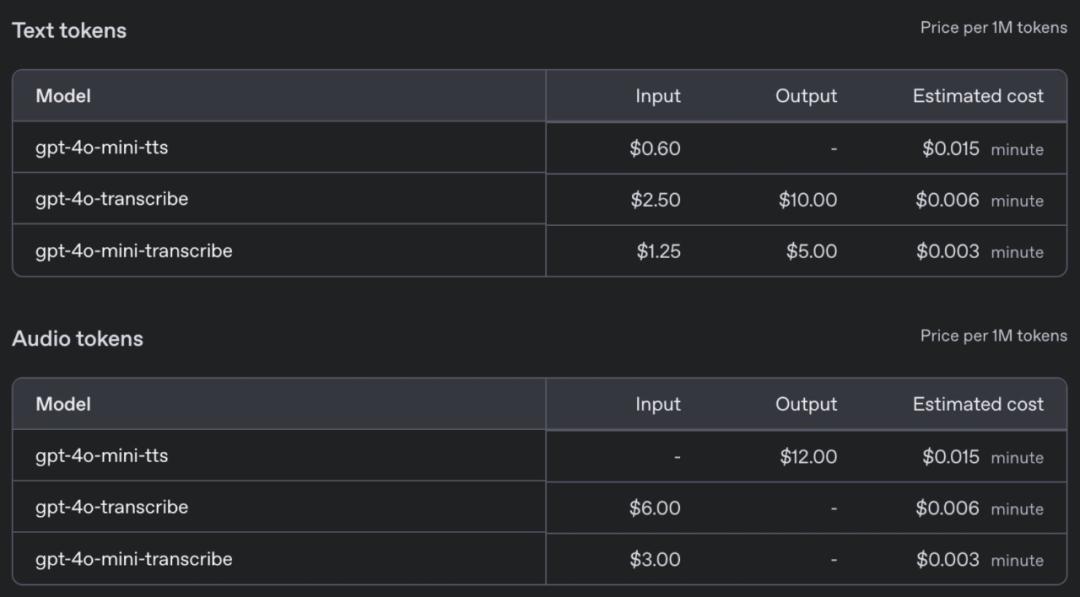
定價方面,GPT-4o-transcribe 與之前的 Whisper 模型價格相同,每分鐘 0.006 美元,而 GPT-4o-mini-transcribe 則是前者的一半,每分鐘 0.003 美元。
與此同時,OpenAI 還發佈了新的 gpt-4o-mini-tts 文本轉語音模型。首次讓開發者不僅能指定「說什麼」,還能控制「如何說」。
具體而言,開發者可以預設多種語音風格,如「平靜」、「衝浪者」、「專業的」、「中世紀騎士」等,它還能根據指令調整語音風格,如「像富有同情心的客服 Agent 一樣說話」,定價親民,僅為每分鐘 0.015 美元。
安全不能馬虎,OpenAI 表示,gpt-4o-mini-tts 將接受持續監控,以保證其輸出與預設的合成風格保持一致。
這些技術進步的背後源於 OpenAI 的多項創新:
新音頻模型建立在 GPT-4o 和 GPT-4o-mini 架構之上,採用真實音頻數據集進行預訓練
應用 self-play 方法創建的蒸餾數據集的知識蒸餾方法,實現從大模型到小模型的知識轉移
在語音轉文本技術中融入強化學習(RL),顯著提升轉錄精度並減少「幻覺」現象。
在淩晨的直播中,OpenAI 向我們展示了一款 AI 時尚顧問 Agent 的應用案例。
當用戶詢問「我最近的訂單是什麼?」時,系統流暢回應:用戶於 2 月 9 日訂購的 Patagonia 短褲已發貨,並在後續提問中準確提供了訂單號「A.D. 507」。

值得一提的是,OpenAI 演示人員還介紹了兩種構建語音 Agent 技術路徑,第一種「語音到語音模型」採用端到端的直接處理方式。
系統可直接接收用戶語音輸入並生成語音回覆,無需中間轉換步驟。這種方式處理速度更快,已在 ChatGPT 的高級語音模式和實時 API 服務中得到應用,非常適合對響應速度要求極高的場景。
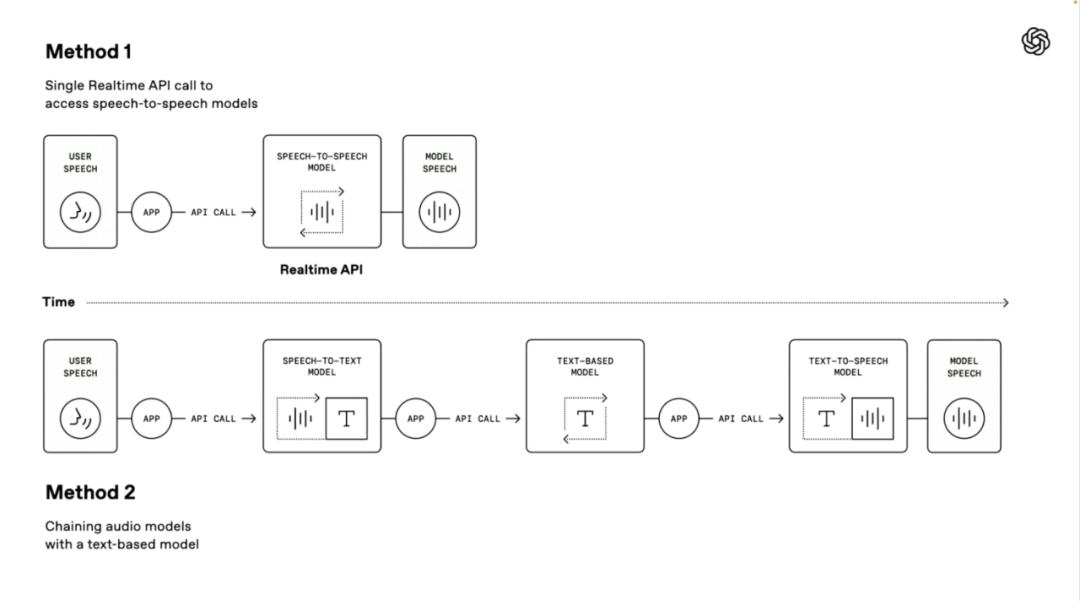
第二種「鏈式方法」則是本次發佈會的重點。
它將整個處理流程分解為三個獨立環節:首先使用語音轉文本模型將用戶語音轉為文字,然後由大型語言模型(LLM)處理這些文本內容並生成回應文本,最後通過文本轉語音模型將回應轉為自然語音輸出。
這種方法的優勢在於模塊化設計,各組件可獨立優化;處理結果更穩定,因為文本處理技術通常比直接音頻處理更成熟;同時開發門檻更低,開發者可基於現有文本系統快速添加語音功能。
OpenAI 還為這些語音交互系統提供了多項增強功能:
支持語音流式處理,實現連續音頻輸入和輸出
內置噪音消除功能,提升語音清晰度。
語義語音活動檢測,能夠識別用戶何時完成發言
提供追蹤 UI 工具,方便開發者調試語音代理
目前,這些全新音頻模型已向全球開發者開放。
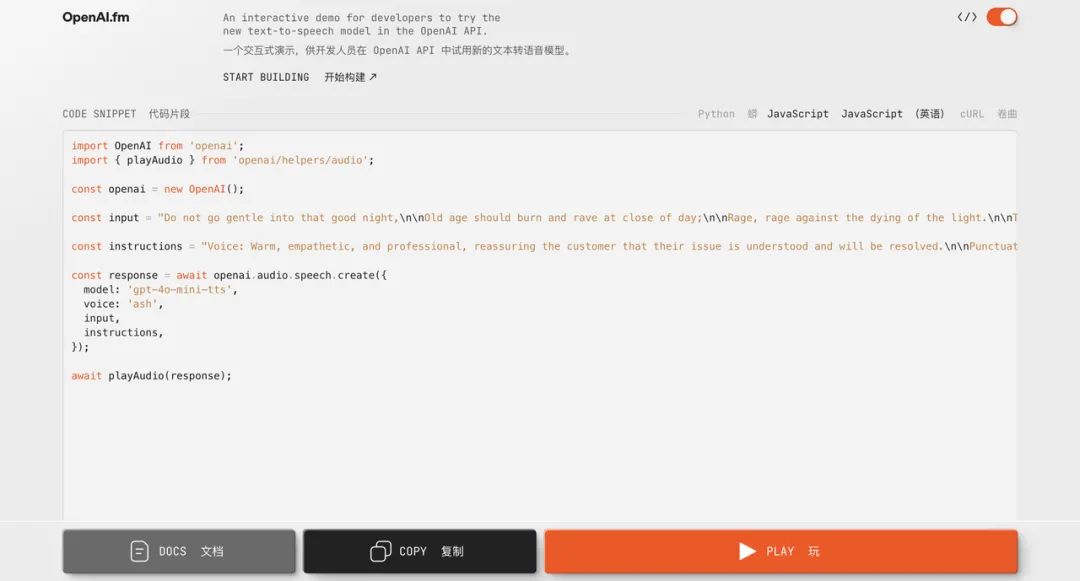
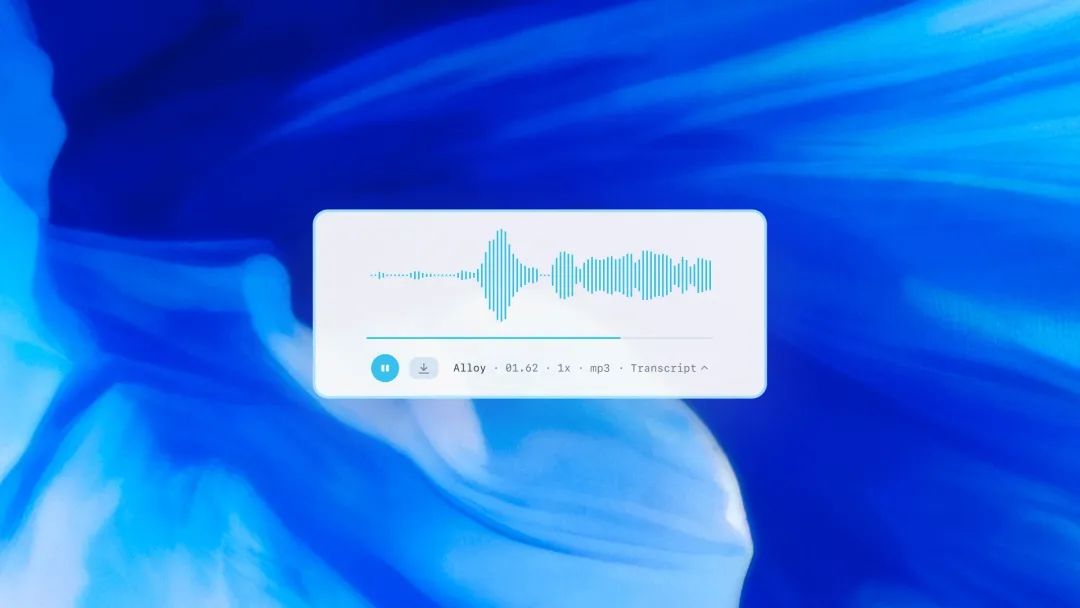
你還可以在 http://OpenAI.fm 上體驗並製作 gpt-4o-mini-tts 的相關音頻,這個演示網站可謂是功能齊全,左下角是官方的預設模板,主要包括人設、語氣、方言、發音等設置。
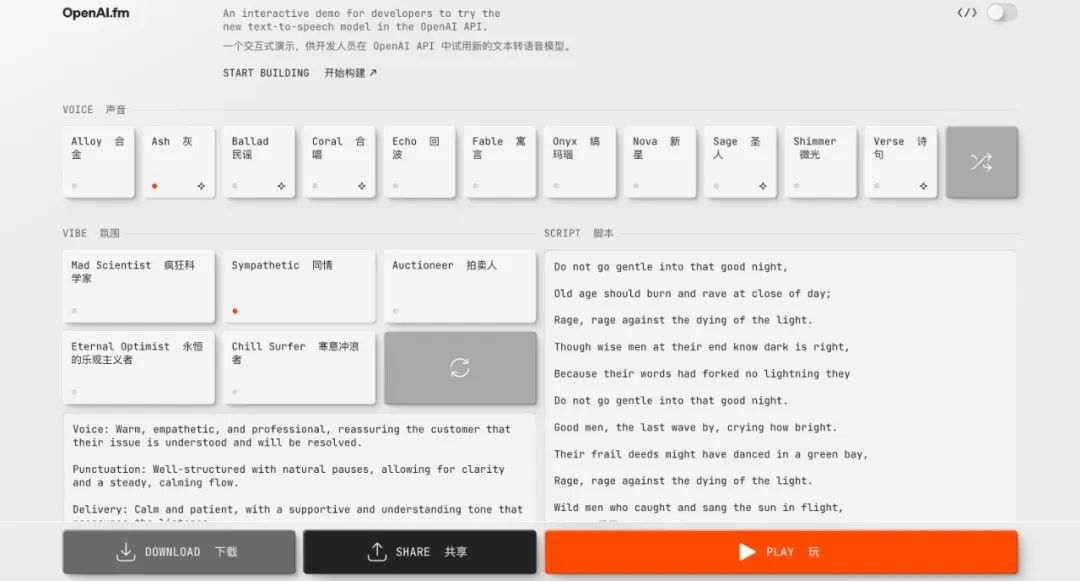
我們也實測了一段八百標兵奔北坡的繞口令,emmm,中文效果馬馬虎虎。
至於英文效果,聽它唸著詩歌,倒是挺有真人那味了,但無論是與此前走紅的 Hume AI 亦或者 Sesame 相比,「肉耳可聽」地還差點火候。
此外,OpenAI 推出了與 Agents SDK 的集成,進一步簡化開發流程。
值得一提的是,OpenAI 還舉辦了一個廣播比賽。用戶可以在 http://OpenAI.fm 製作音頻,接著使用 OpenAI.fm 上的「分享」按鈕生成鏈接,然後在 X 平台分享。
最具創意的前三名將各獲一台限量版 Teenage Engineering OB-4。音頻時長建議控制在 30 秒左右,可在語音、表達、發音或劇本語調變化上盡情發揮創意。

實際上,今年 AI 的風向也在悄然發生變化,除了依舊強調智商,還多出一股趨勢,強調情感。
GPT-4.5、Grok 3 的賣點是情商,寫作更有創意,回應更個性化,而冷冰冰的機器人(智元機器人),也強調更擬人,主打一個情緒價值。

由於直接觸及人類最本能的溝通方式,語音領域在這方面的發力則更加顯著。
最近在矽谷走紅的 Sesame AI 能夠實時感知用戶情緒,並生成情感共鳴的回應,迅速俘獲了一大批用戶的心。圖靈獎得主 Yann Lecun 最近也在強調,未來的 AI 需要擁有情感。
而無論是 OpenAI 今天發佈的全新語音模型、還是即將發佈的 Meta Llama 4 都有意往原生語音對話靠攏,試圖通過更自然的情感交互拉近與用戶的距離,靠「人味」圈粉。
AI 需要有人味嗎?長期以來,聊天機器人通常被定義為沒有情感的工具,它們也會在對話中提醒你只是一個沒有靈魂的模型。然而,我們卻往往能從中解讀出情緒價值,甚至不自覺地與之建立情感聯結。
或許人類天生渴望被理解、被陪伴,哪怕這種理解來自一台機器。
本文來自微信公眾號「APPSO」,作者:APPSO,36氪經授權發佈。